您现在的位置是:首页 >技术教程 >TCP 与 bufferbloat网站首页技术教程
TCP 与 bufferbloat
说到既能降低成本,又能降低时延,总觉得这在 pr,兜售自己或卖东西。毕竟哪有这么好的事,鱼与熊掌兼得。可事实上是人们对 buffer 的理解错了才导致了这种天上掉馅饼的事发生。
人们总觉得 buffer 越大越好,buffer 越大设备越贵,真实情况是 buffer 越大越糟糕,如果按这个思路,应该是 buffer 越小设备越贵,所以你若想获得低时延,就要花更多的钱买小 buffer 的设备,这依然是一笔需要权衡轻重的买卖。
可无奈 buffer 是一样东西,它是实实在在的实物,是一种普通非稀有容器,哪有越小越贵的道理,但其实不能将 buffer 理解成容器,而要理解成调节剂,比如盐,味精等调味品,放一点刚刚好,越多越糟糕:
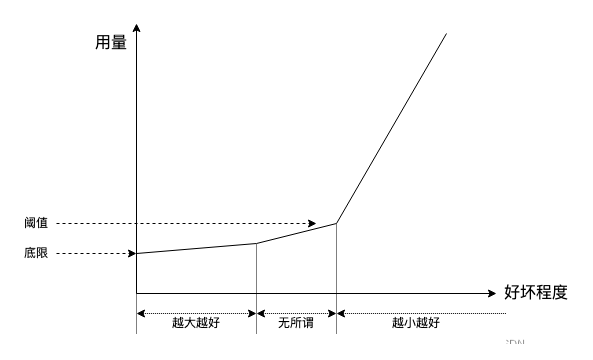
人们对好的东西支付,以上图为导向,携带 100GB buffer 的交换机肯定没有携带 100MB buffer 的交换机贵。
看个标准 TCP(std TCP) 的经典锯齿:
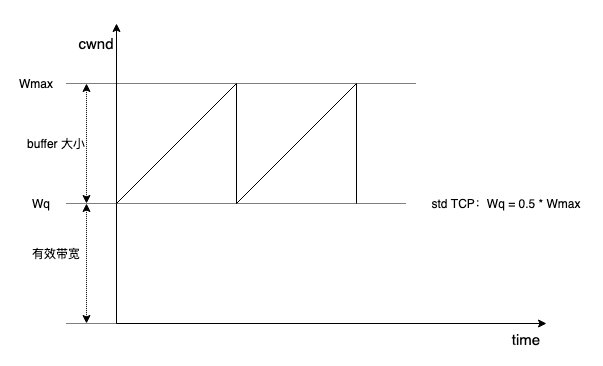
为 100% 利用有效带宽,std TCP 需要 “即使执行 MD(multiplicative-decrease) 将 cwnd 折半后依然恰好填满有效带宽”,即 Wmax = 2 * BDP,因此,buffer 的建议大小为 BDP。
如果 buffer 不足 BDP,就会出现带宽不能有效利用的情况:
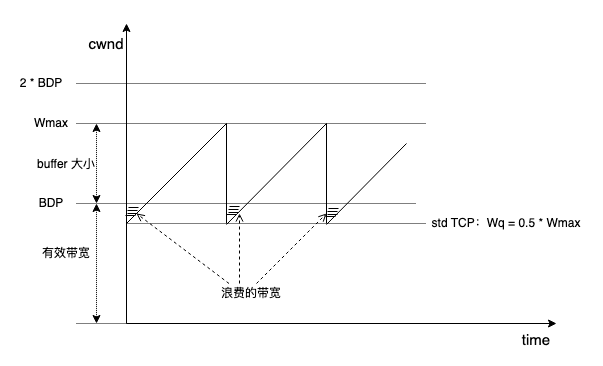
但如果有 2 条流,第 2 条流的 cwnd 就可以补上图示中的阴影,隐约可见,流数量越多,阴影越容易弥补。另一方面,随着弥补阴影变得容易,阴影更能容忍继续扩大,而阴影的扩大意味着 buffer 减小。
进一步,设流数量为 N,N 不需无穷大,只需数值上等于 BDP 并随机异步散列,buffer 可趋向 0 仍保证带宽 100% 利用。研究表明,实际需要的 buffer 与根号 N 成反比:Bsize = 2 * BDP / N^0.5。我曾经写过一篇分析:buffer 的平方反比律。
N 越大,所需 buffer 越小,虽有悖于直觉,但也可以理解,背后的动力学是 “交互的代价”or 收益。N 越大,总带宽利用率越不受单流行为影响,整体上趋于互补。
下面是一个例子。
设 BDP = 6,单流场景,cwnd 序列为:6,7,8,9,10,11,12,buffer 大小为 12。现考虑 2 条流公平收敛后的场景,每一条流的 cwnd 序列均为:3,4,5,6。
- 如果两条流同步,那么 cwnd1 + cwnd2 序列为:6,8,10,12,此时所需 buffer 仍然为 12。
- 如果两条流相位差 1,cwnd 和序列为:7,9,11,9,所需 buffer 为 11,但有 1 单位 buffer 无法清空。
- 如果两条流相位差 2,cwnd 和序列为:8,10,8,10,所需 buffer 为 10,有 2 单位 buffer 无法清空。
后面两种情况,均可既满足带宽被 100% 利用,又减少 buffer。若固定最大相差,在实数域上移动相位,就是一个抽样过程,按中心极限定理,N 越大,概率分布曲线会越高越瘦收敛于均值,瘦意味着方差小,无需照顾小概率事件,buffer 用量减少。
但填满带宽和单流吞吐是两回事。小 buffer 虽足以 N 条流一起填满总带宽,但 N 流交互的代价是单流丢包间隔缩短,丢包增加。
一般而言,交互即 capacity-seeking,所以代价来自 capacity-seeking,假设存在非 capacity-seeking 机制控制 sender 恰好分享 1 / N 带宽份额,便完美高效并完美公平,由于没有足够控制信息,这几乎不可能,因此 capacity-seeking 固有开销(这是普遍管理开销)必须接受。
当 N 很大时,要么选择高丢包高重传,要么选择大 buffer 但同时大排队时延。显然选择后者不高尚,如果频繁丢包,说明链路过载,AIMD 锯齿波只是以一种并不完美 capacity-seeking 方式保证收敛,但远非唯一方式,甚至 capacity-seeking 本身都不是唯一的带宽高效共享的方式。
L4S(Low Latency, Low Loss, and Scalable Throughput (L4S) Internet Service) 提供了一种新思路。在传统端到端视角,舍弃大 buffer 而开发更优的 cc 更智能地 capacity-seeking 相比部署大 buffer 更正确(buffer 就像盐,缺了不行,但稍微多一点就会出大问题),比如 CUBIC 和 BBR 相比 std TCP 就是很好的优化。
Internet 核心并没有选择大 buffer。如上所述,早期 Bsize = BDP 的结论被证明 在 N 很大时是不必要的,这大大降低了核心路由器对 buffer 的依赖,因为在 Internet 核心,N 一定很大。
以 100Gbps 带宽为例,早期核心路由器需覆盖 RTT 上界接近 200ms 的 BDP,需要部署大小为 2.5GB 的 buffer,但在新理论下,当 N = 10000(可能不止),只需要约 25MB 的 buffer 即可。
此外,在数据中心,另一番景象依然不允许部署大 buffer。
数据中心低时延是刚需,超高带宽是固有属性,超高带宽将灵敏响应的责任甩给了主机和交换机,100Gbps+ 带宽容不得半点抖动,留给 cc 以及 queue 的决策时间非常短,同时由于数据中心高频微突发,N 也不会小,综上,数据中心不能部署大 buffer(大概只有 3MB~10MB)。
Internet 核心和数据中心之外,还有网络边缘接入点这第三个场地,这也是最难搞的地方。经过这地方的流量没有足够大的 N,连选择的机会都没有,buffer 太小既高丢包又低带宽利用率,buffer 太大就会 bufferbloat。
要排除对 buffer 的侵占(有多少 buffer 会用多少),几乎所有的 AIMD capacity-seeking 这种对 buffer 强依赖的算法均不适合。
application-limited 流量无 capacity-seeking,但 application-limited 流量无法抗 burst:
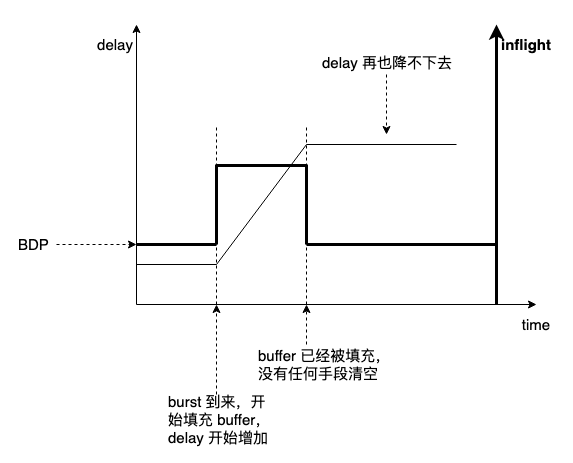
所以知道 BBR 为什么要在 ProbeRTT 维持 4 个 inflight 以清空 queue 了吧,很多以百分比或盲目增加个常数(显然是嫌 4 太小了)来魔改 ProbeRTT inflight 的,歪曲了本意,基本算扯淡,但 BBR2 为流共存已经做了很大修改,它其实算混合算法,并不是真的 BBR。
但 inflight = 4 确实会带来应用抖动,增加应用 buffer 可缓解,但既然增加应用层 buffer 可容忍时延换不抖动,转发节点 bufferbloat 带来的时延为何就不可原谅呢,总之很难搞。或许 CUBIC 停留在 Wmax 更久一点,并用 pacing 缓解 burst 更好一些。
电脑内存越大越好,但交换机 buffer 可不是这样。认为交换机 buffer 越大越好的肯定是接触电脑多于网络,接近微软 PC 时代的人,程序员居多。
buffer 作为调节剂,用来平滑统计突发(可能还有更基本的存储转发用途,但这依然需要少量 buffer),而不是像电脑里那样暂存计算中间结果或平滑快慢设备的。网络是通路,不需要停留,小 buffer 溢出说明过载了,要降载荷而不是加 buffer。
buffer 到底大了好还是小了好是一个与 “golang 和 rust 哪个更好” 截然不同的问题,即便 rust 再时兴,看不惯用不上的依然不会用,但 buffer 大了好还是小了好是一个很明确的问题,难点在于很难解释 “为什么 buffer 不能太大”,不管如何解释,都会被怀疑,“难道大 buffer 不丢包不好吗?”,很少人会去真心面对链路过载问题,很少人能接受 “慢点发送”,似乎每个人都希望将数据尽快发送出去,于是越大越好的 buffer 承载了所有希望。
浙江温州皮鞋湿,下雨进水不会胖。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结