您现在的位置是:首页 >技术杂谈 >图像分割(Segmentation)网站首页技术杂谈
图像分割(Segmentation)
图像分割
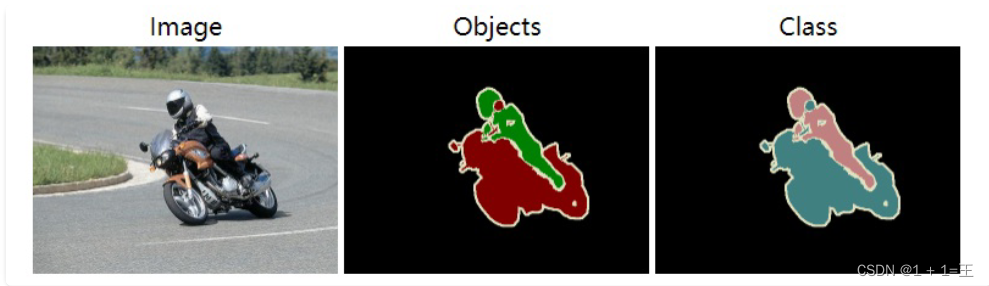
图像分割是预测图像中每一个像素所属的类别或者物体。基于深度学习的图像分割算法主要分为两类:
- 语义分割(Semantic Segmentation)
为图像中的每个像素分配一个类别。

- 实例分割(Instance Segmentation)
与语义分割不同,实例分割只对特定物体进行类别分配,这一点与目标检测有点相似,但目标检测输出的是边界框和类别,而实例分割输出的是掩膜和类别。

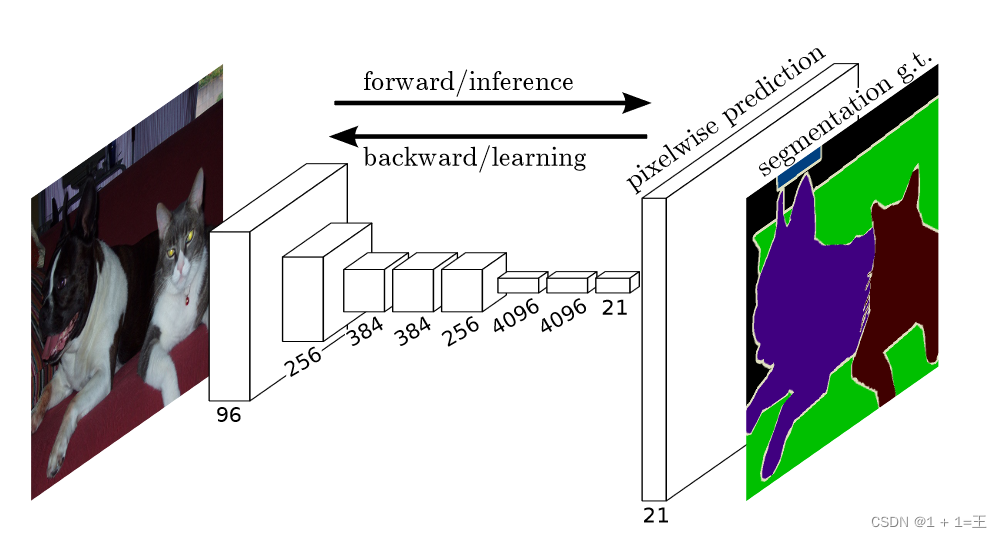
FCN
原文链接:Fully Convolutional Networks for Semantic Segmentation:https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_CVPR_paper.pdf

FCN对图像进行像素级的分类,从而解决了语义级别的图像分割问题。FCN可以接受任意尺寸的输入图
像,采用反卷积层对最后一个卷积层的f eat ure map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
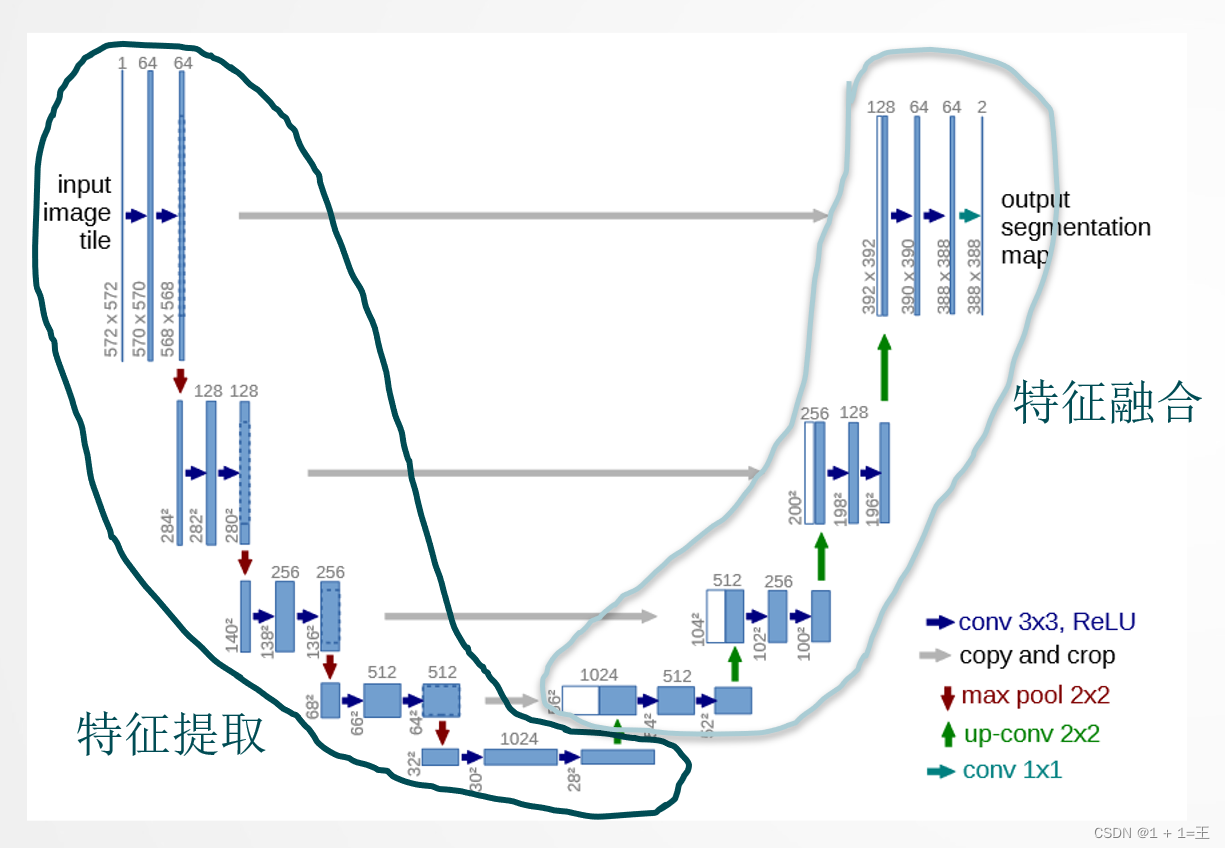
U-Net
原文链接:U-Net: Convolutional Networks for Biomedical Image Segmentation:https://arxiv.org/pdf/1505.04597.pdf

- 特征提取部分:它是一个收缩网络,通过四个下采样,使图片尺寸减小,在这不断下采样的过程中,特征提取到的是浅层信息。
- 拼接
- 上采样部分,也叫扩张网络,图片尺寸变大,提取的是深层信息,使用了四个上采样,在上采样的过程中,图片的通道数是减半的,与左部分的特征提取通道数的变化相反。
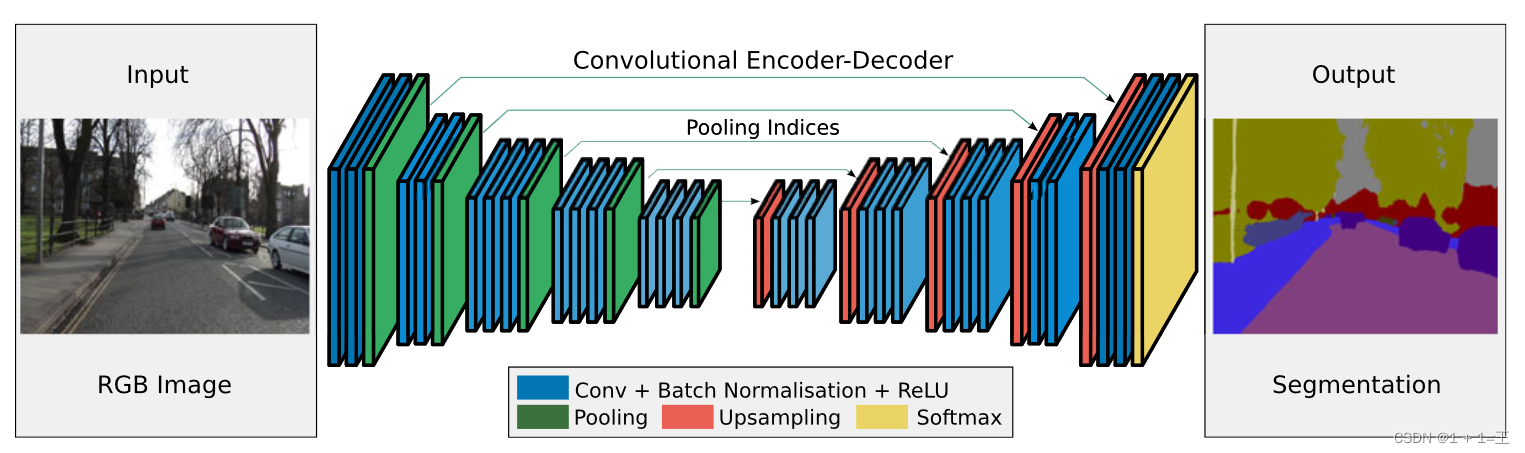
SegNet
原文链接:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7803544

SegNet架构包括编码器、解码器、编码-解码结构和反卷积-上采样-下采样结构。编码器使用VGG16的前13层卷积网络,每个编码器层都对应一个解码器层。在解码器处,执行上采样和卷积。最终解码器的输出被送入softmax分类器以独立的为每个像素产生类概率。
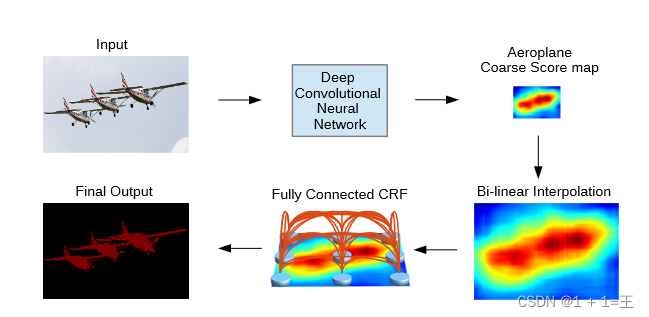
DeepLab
论文原文:SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS:https://arxiv.org/pdf/1412.7062.pdf

DeepLab 是结合了深度卷积神经网络(DCNNs)和概率图模型的方法。针对信号下采样或池化降低分辨率,DeepLab 是采用的 atrous(带孔)算法扩展感受野,获取更多的上下文信息。
DeepLab 采用完全连接的条件随机场提高模型捕获细节的能力。
图像分割常用数据集
-
PASCAL VOC
VOC 数据集分为20类,包括背景为21类。
-
MS COCO
MS COCO 是最大图像分割数据集,提供的类别有 80 类,有超过 33 万张图片,其中 20 万张有标注,整个数据集中个体的数目超过 150 万个。

-
Cityscapes
Cit yscapes 是驾驶领域进行效果和性能测试的图像分割数据集,它包含了5000张精细标注的图像和20000张粗略标注的图像,这些图像包含50个城市的不同场景、不同背景、不同街景,以及30类涵盖地面、建筑、交通标志、自然、天空、人和车辆等的物体标注。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结