您现在的位置是:首页 >技术教程 >深度学习 - 41.Word2vec、EGES 负采样实现 By Keras网站首页技术教程
深度学习 - 41.Word2vec、EGES 负采样实现 By Keras
目录
一.引言
前面介绍了基于 Gensim 的 Word2vec 实现以及 EGES 的理论与样本准备,由于 EGES 是在 Word2vec 的基础上为 (Target, Context) 中的 Target 增加 SideInfo 侧信息增加表达能力,所以这里先实现 Word2vec,再加入侧信息实现 EGES,二者实现思路相近。
Tips:
本文实现方式为 Skip-Gram,CBOW 同学们可以基于下面思路自己实现。
二.实现思路
1.样本构建
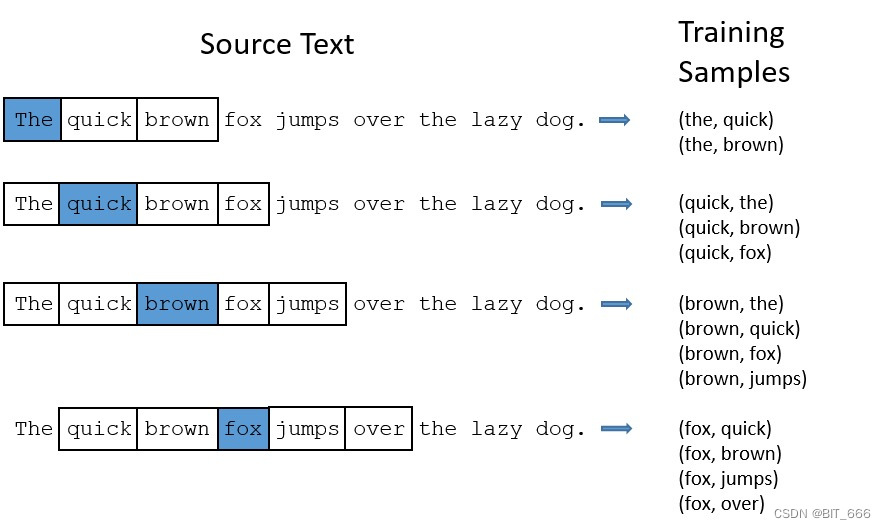
由于实现形式为 Skip-Gram,所以是 (Target, Context) 即 (中心词, 上下文) 的形式,通过 window_size 可以控制我们从序列 Seq 样本中获取的样本对数量。
2.Word2vec 架构
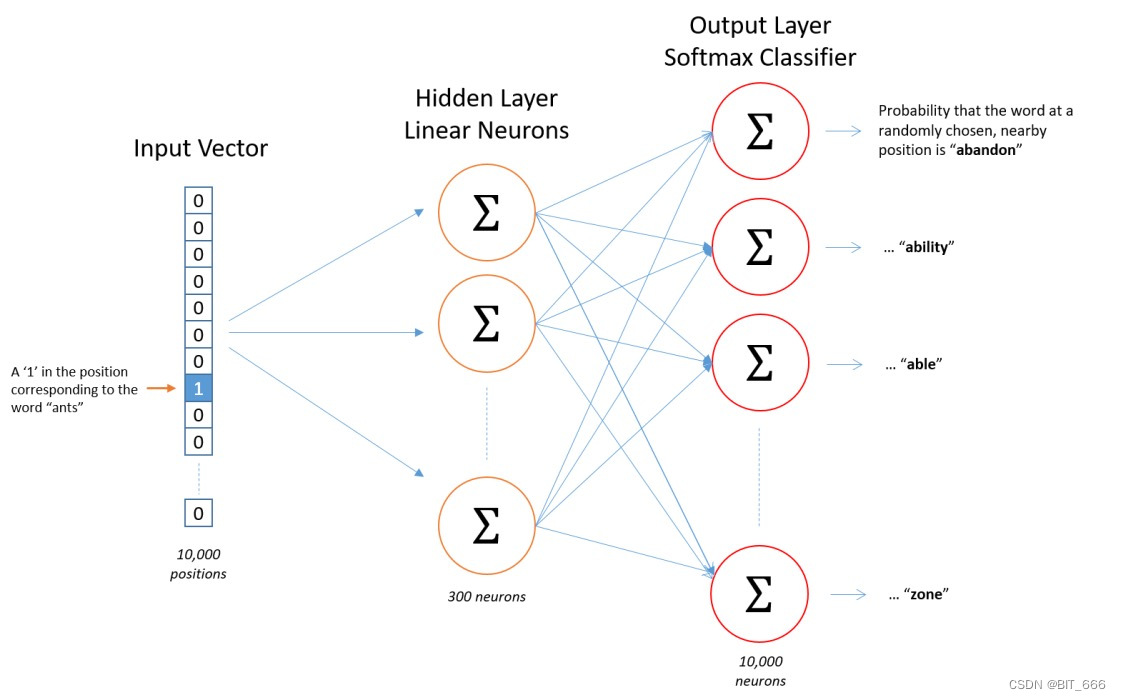
样本为 (Target, Context),输入为仅 Target 对应位置为 1 的 one-hot 向量,通过 Hidden-Layer 获取 Target 对应的 K 维向量,随后与 SoftMax 输出层的 KxN 的参数矩阵相乘的到 N 维向量,对 N 维向量取 Softmax 并与仅 Target 为 1 的 one-hot label 进行 Loss 的计算并梯度回传。
Tips:
由于 Target 中心词所在词库大小 N 通常很大,所以最后一步的 Softmax 计算相对比较耗时,论文中提出了两种优化方法:
• 层次 Softmax
层次 softmax 基于霍夫曼树生成的词库,优化了 dot 计算的数量与高频词的计算数量。
• 负采样
Negative Sample 这个方法非常简单粗暴但是好用,每次为 Target 生成 ns 个非 Context 的词作为负样本,这样计算量直接从 N 缩减至 ns,一般推荐 ns 为 5-20
由于层次 softmax 构造相对复杂,这里我们采用更好实现的 Negative Sample 即负采样。
3.EGES 架构
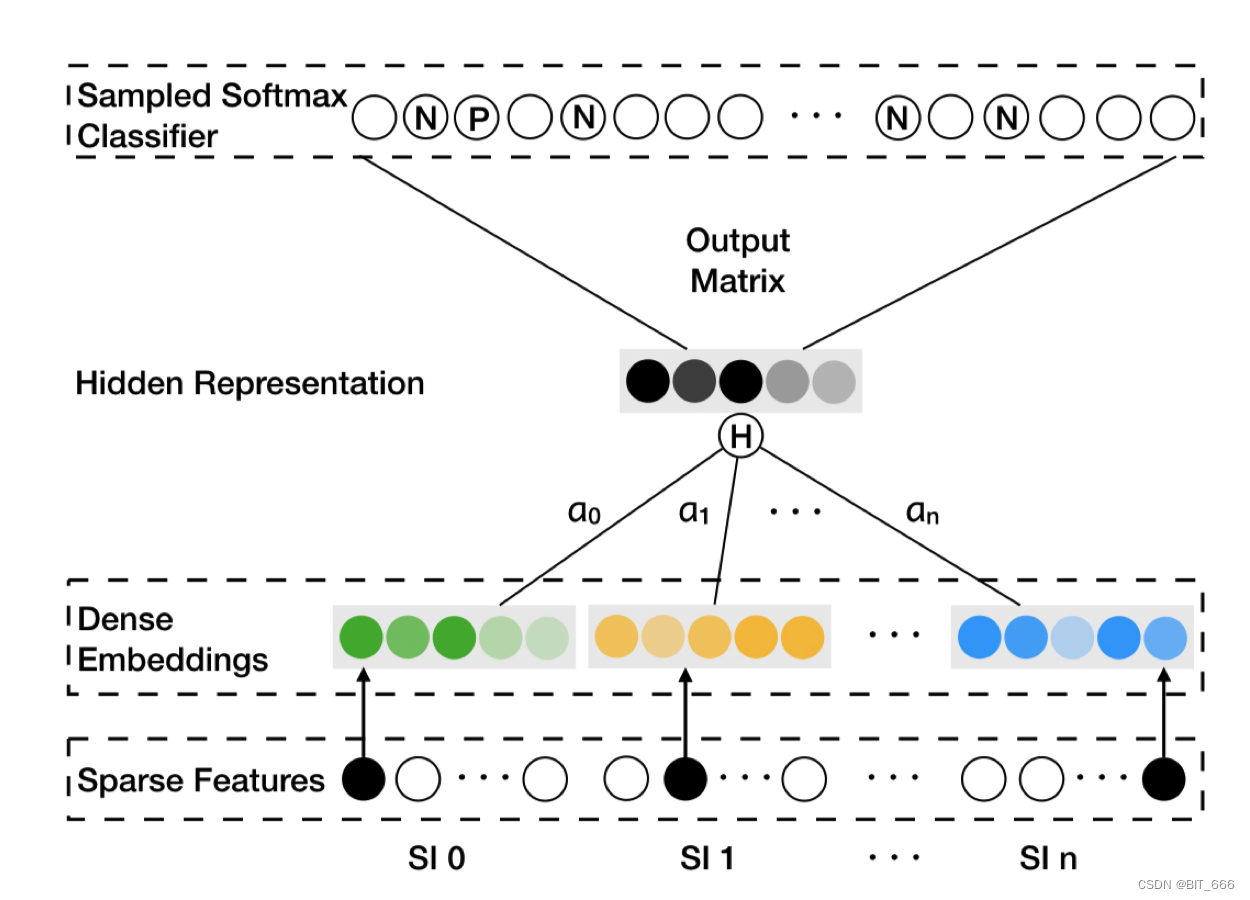
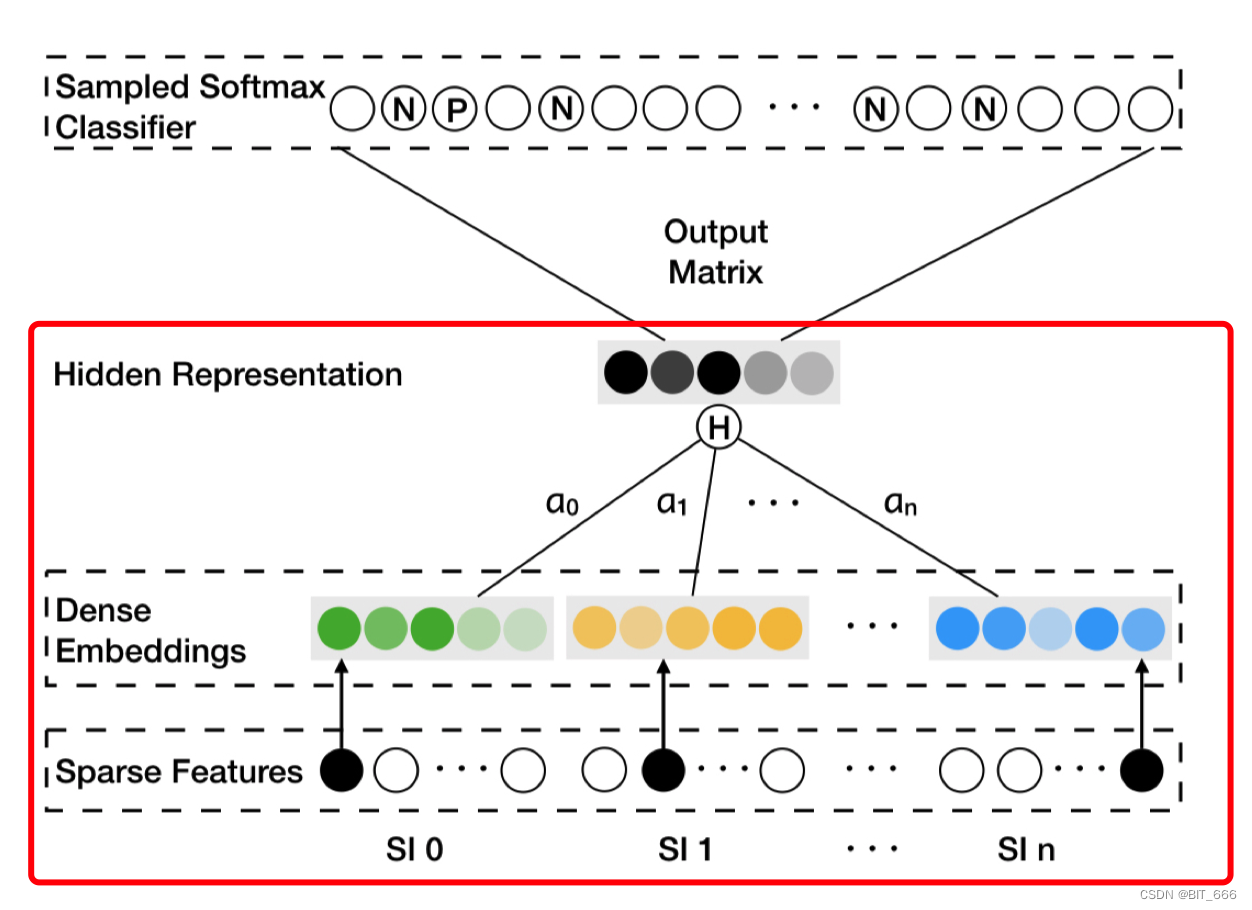
这里 SI 0 代表 Item 即 (Target, Context) 里的 Context,S1 1 - S1 n 为 n 类 SideInfo 侧信息,针对每一个 SI 0 都有一个 Alpha 权重向量,通过 ∑ α * Emb 的形式得到加权平均的 Embedding,后面的计算同 Word2vec 一致。 N 和 P 代表随机采样的 Negative Sample 和 Context 对应的 Positive Sample。
Tips:
这里把图歪过来,架构就很相似了,简单分下下 Word2vec 与 EGES 的区别:
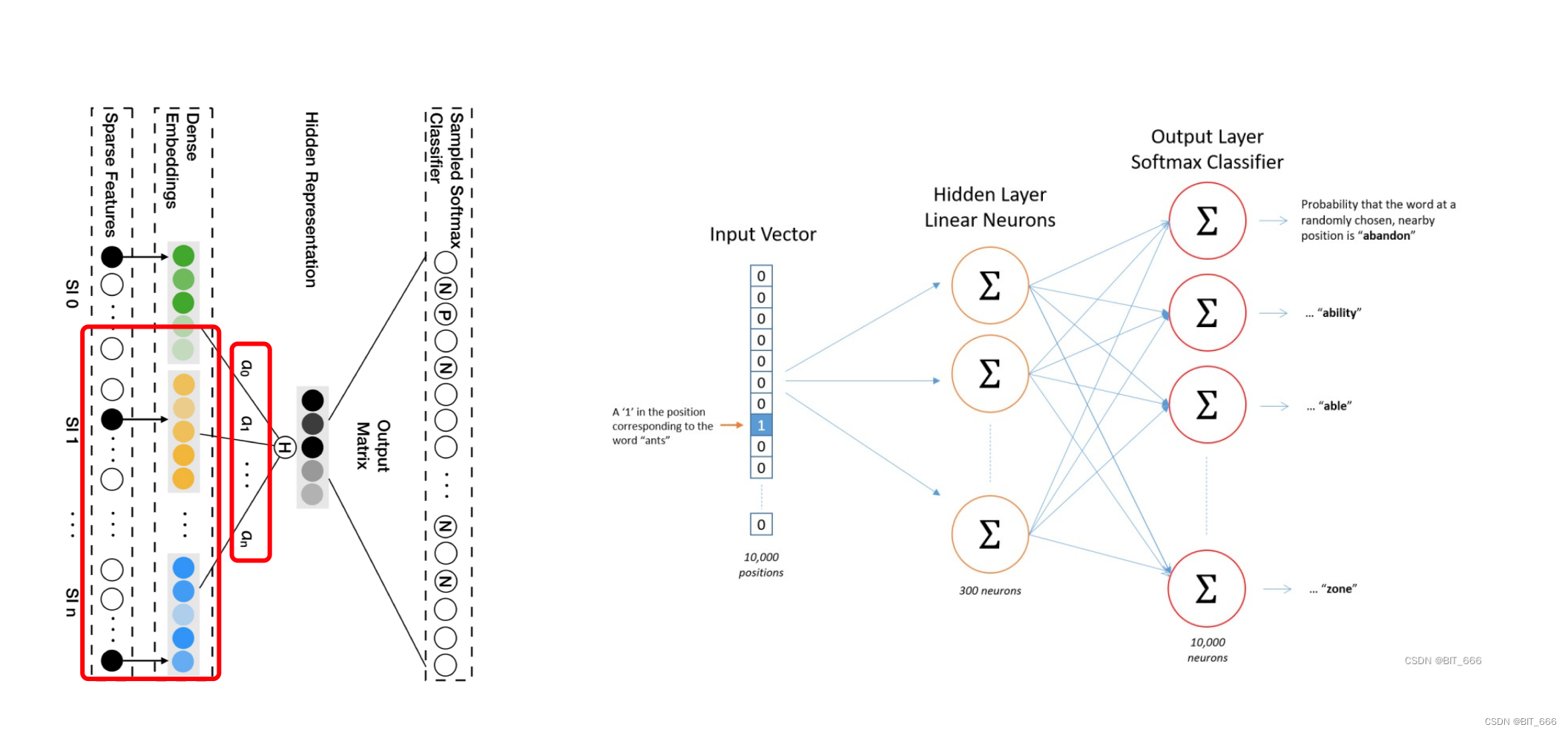
• 样本构造
EGES 采用 Session 截取用户历史行为,Word2vec 基于用户完整历史行为游走。
• Hidden 层输入
EGES 加入 SideInfo 加权得到隐层的输入,Word2vec 直接 lookup 得到 Target Embedding 输入隐层。
4.基于 NEG 的 Word2vec 架构
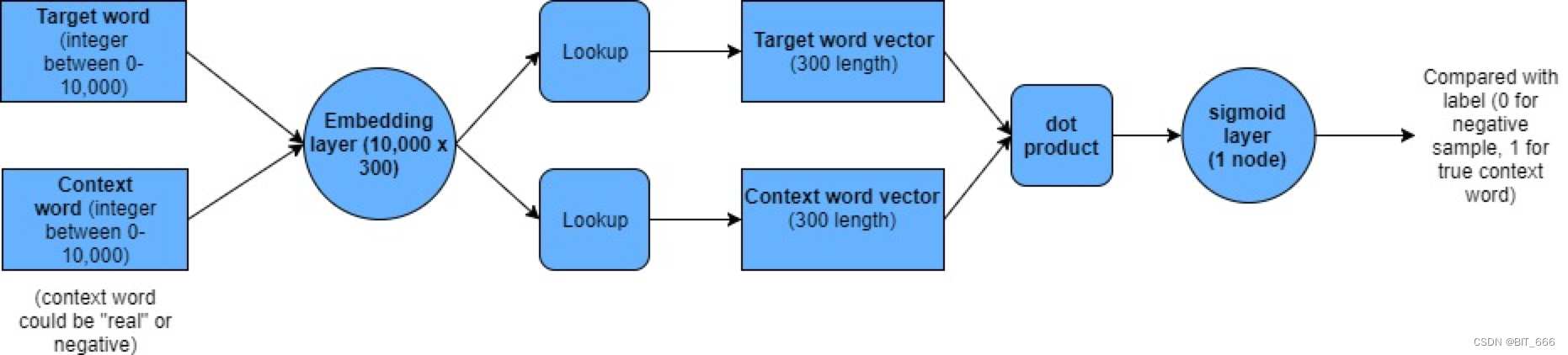
直接通过 Embedding 层 lookup 获取 (Target, Context) 对应的 K 维度 Embedding,随后执行 Dot 计算并通过 Sigmoid 得到 0-1 的值,将多分类的 Category_Crossentropy 转换为了二分类 Binary_Crossentropy 的问题。其样本构造也很简单,针对正样本 (Target, Context) 其 Label 为 1,再基于 Target 生成 ns 个 (Target, Negative Word) 的负样本,其 Label 为 0。最后获取 Embedding 的向量作为词向量即可,如果是 EGES 则是增加 Weight Merge 即加权求和操作即可。
三.Keras 实现 Word2vec
1.样本构建
word_target, word_context = zip(*all_pairs)
word_target = np.array(word_target, dtype="int32")
word_context = np.array(word_context, dtype="int32")
上篇数据预处理的文章中我们已经基于编码后的 sku 商品序列游走获取了如上图的样本形式,后续将基于该样本与 NEG 的架构实现 Word2vec 与 EGES。
Tips:
注意数据类型的 dtype,否则会报错,因为我们处理完的为字符类型,训练需要 int32 or int64。

2.模型构建
- Embedding 层
input_target = Input((1,))
input_context = Input((1,))
embedding = Embedding(sku_num, args.emb_dim, input_length=1, name="embedding")
# 获取 Emb
target = embedding(input_target)
target = Reshape((args.emb_dim, 1))(target)
context = embedding(input_context)
context = Reshape((args.emb_dim, 1))(context)直接构建 Embedding 层获取 (Target, Context) 的 K 维向量。
- Dot 层
# now perform the dot product operation to get a similarity measure
dot_product = Dot(axes=1)([target, context])
dot_product = Reshape((1,))(dot_product)
# add the sigmoid output layer
output = Dense(1, activation='sigmoid')(dot_product)直接 Dot 计算内积。
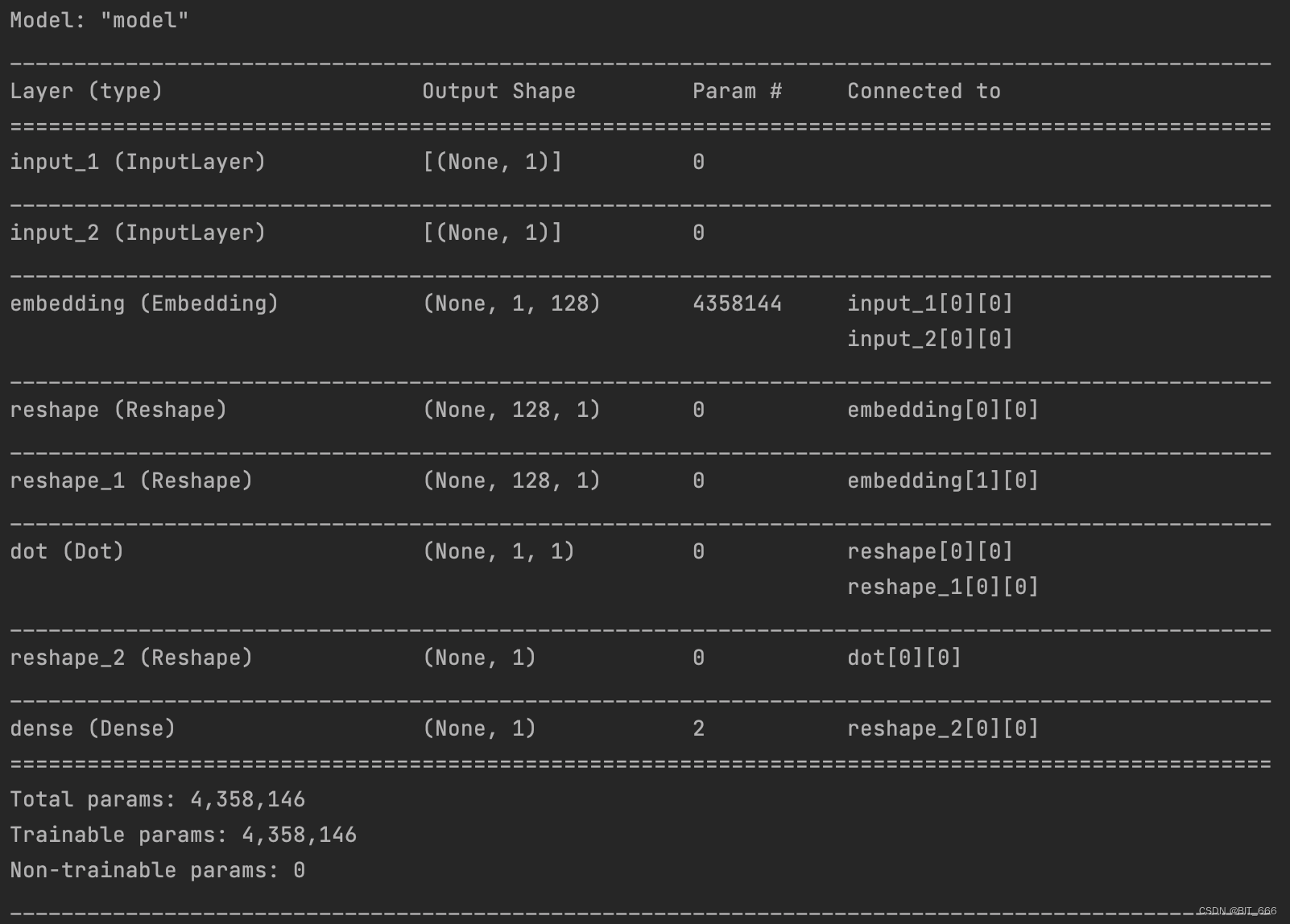
- Model 层
# create the primary training model
model = Model([input_target, input_context], output)
model.summary()
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])选择 binary_crossentroy 进行模型编译:
Tips:
同样需要注意把 labels 用 np.array 包装起来,否则训练无法进行。
3.向量获取
model.fit((word_target, word_context), np.array(labels), epochs=10, batch_size=128)
# 获取训练后的 Embedding
emb = np.array(embedding.get_weights()[0])
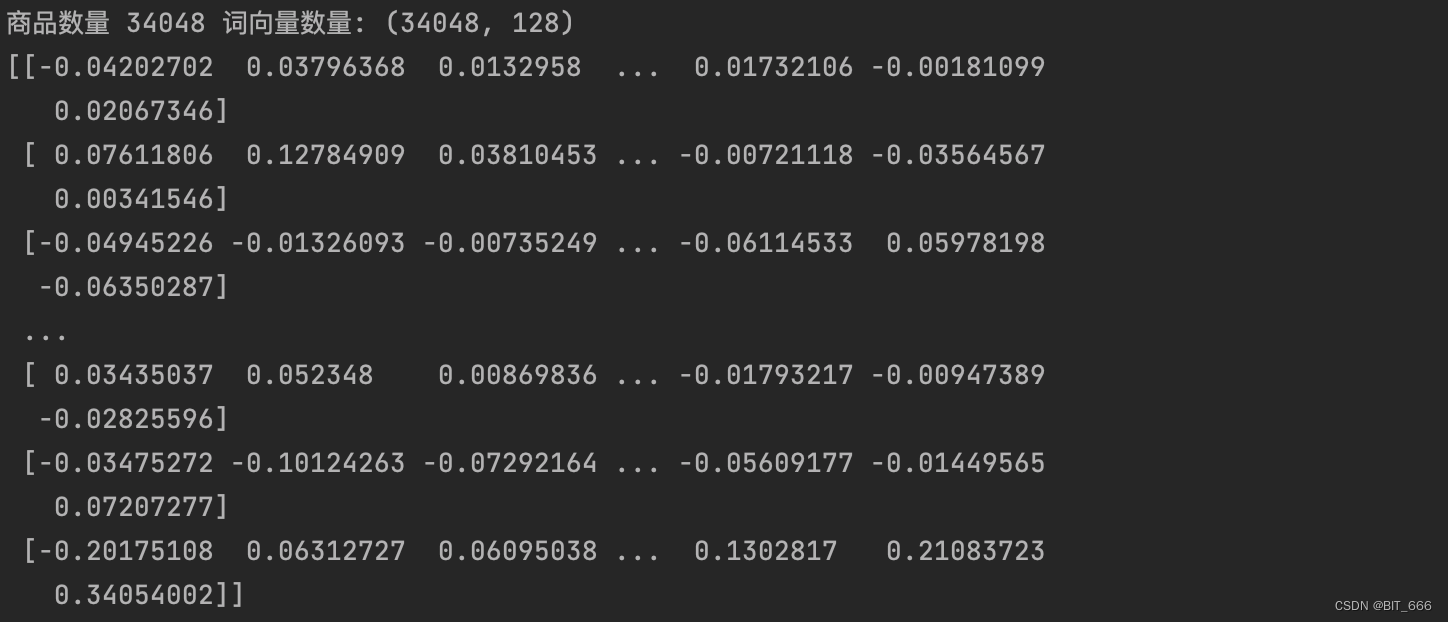
print("商品数量 %d 词向量数量: %s" % (sku_num, emb.shape))
print(emb[:10])跑 10 个 epoch 看看:
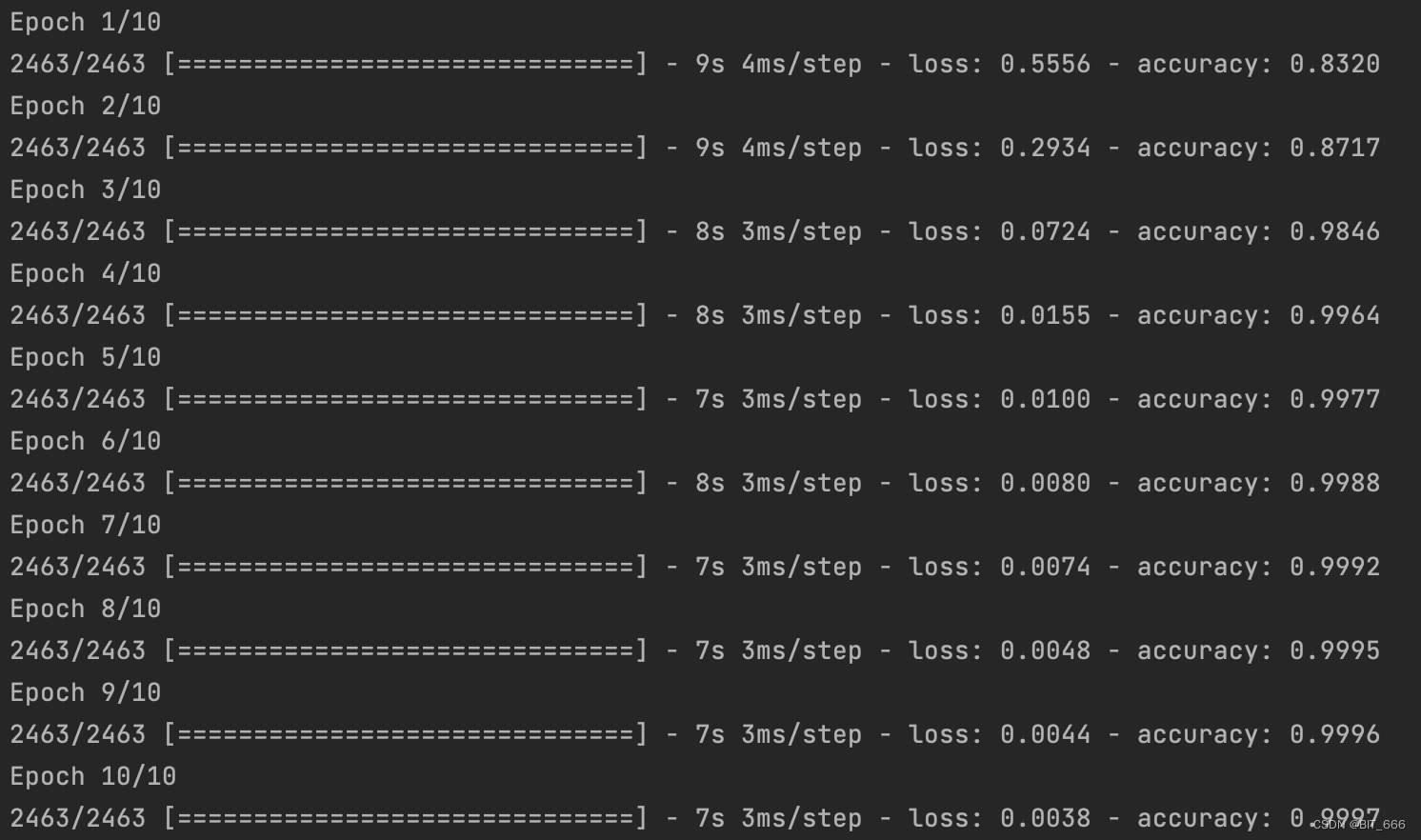
最后查看商品数量和 Emb 数量是否一致,随后将 Emb 按索引反映射到 word 即 sku 商品上,即实现了每个 sku 对应一个 Embedding:
四.keras 实现 EGES
1.样本构建
(Target, Context) 与上面 Word2vec 一致,这里需要给 Target 增加 SideInfo,将样本修改为 ([Target, SI 1, SI 2, SI N], Context) 的形式,其中 SI N 代表第 N 个 SideInfo。本例中 sku 商品共包含 3 个 SideInfo 分别为: brand-品牌、shop_id-店铺、cate-标签。
word_target = np.array(word_target, dtype="int32")
word_context = np.array(word_context, dtype="int32")
word_target_with_side_info = []
for word in word_target:
# 获取侧信息并追加
side_info = sku_side_info[sku_side_info['sku_id'] == word].values[0]
word_target_with_side_info.append(np.array(side_info, dtype='int32'))
word_target_with_side_info = np.array(word_target_with_side_info, dtype='int32')sku_side_info 是上文数据预处理中生成的 Sku 信息的 DataFrame,这里获取 values 并添加到新的样本集合中:
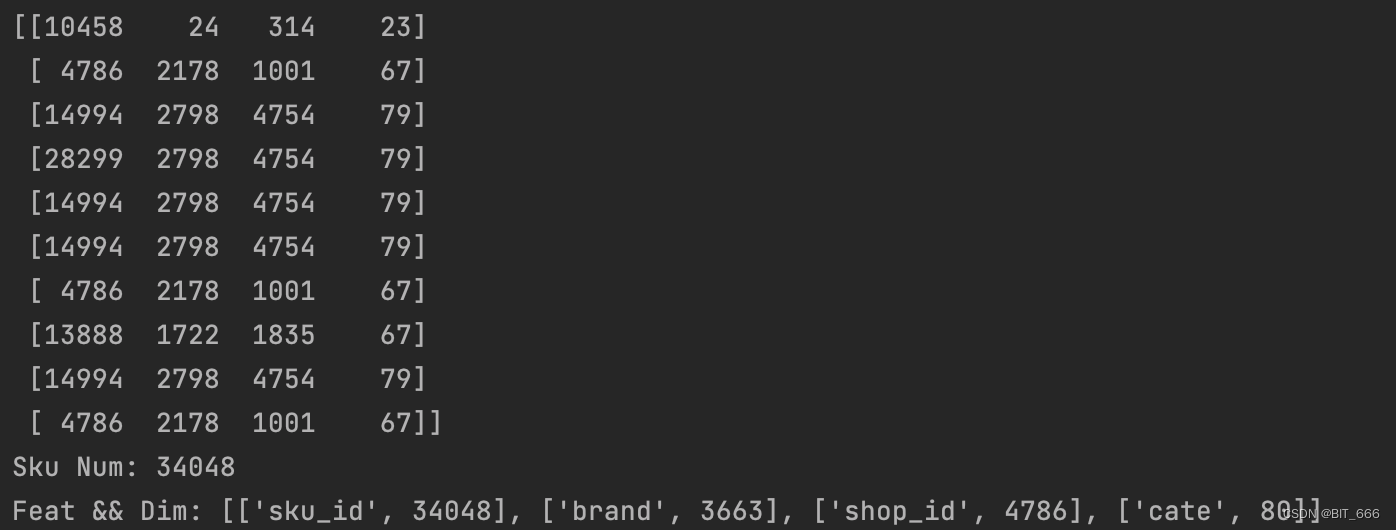
sku、brand、shop_id 与 cate 对应的 Dim 数为样本中对应特征 Unique 去重后的数量。
2.模型构建
- 输入层
# 添加 SideInfo: brand,shop_id,cate
input_target = Input((4,))
input_context = Input((1,))由于添加了 3 类 SideInfo,所以 Input 增加 3 维。
- Dot 层
dot_layer = EGES_model(feat_num_list, args.emb_dim)([input_target, input_context])这里 dot_layer 需要实现 EGES 加权求和获取 Merge 合并后 Embedding 的工作,篇幅较长,我们放在后面统一分析。
- Model 层
# add the sigmoid output layer
output = Dense(1, activation='sigmoid')(dot_layer)
# create the primary training model
model = Model([input_target, input_context], output)
model.summary()
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])3.Dot Layer 详解
dot_layer 实现继承 tensorflow.python.keras.models.Model 实现,主要包含 init 初始化与 call 调用两个方法的实现。其中 call 方法如下图红框所示,基本包含了 EGES 前置的全部逻辑。
3.1 init 方法
根据上图我们分析模型需要如下参数:
• SI 0 参数矩阵
SI 0 为 sku 对应的 Embedding 层,其维度为 len(unique(sku)) x K
• SI 1-N 参数矩阵
SI 1-N 为 Side Info 对应的 Embedding 层,其维度分别为 len(unique(SI I)) x K
• Alpha 权重矩阵
针对每个 sku 有 1+s 个 alpha 权重,所以共需要 len(unique(sku)) x (1+s) 个参数
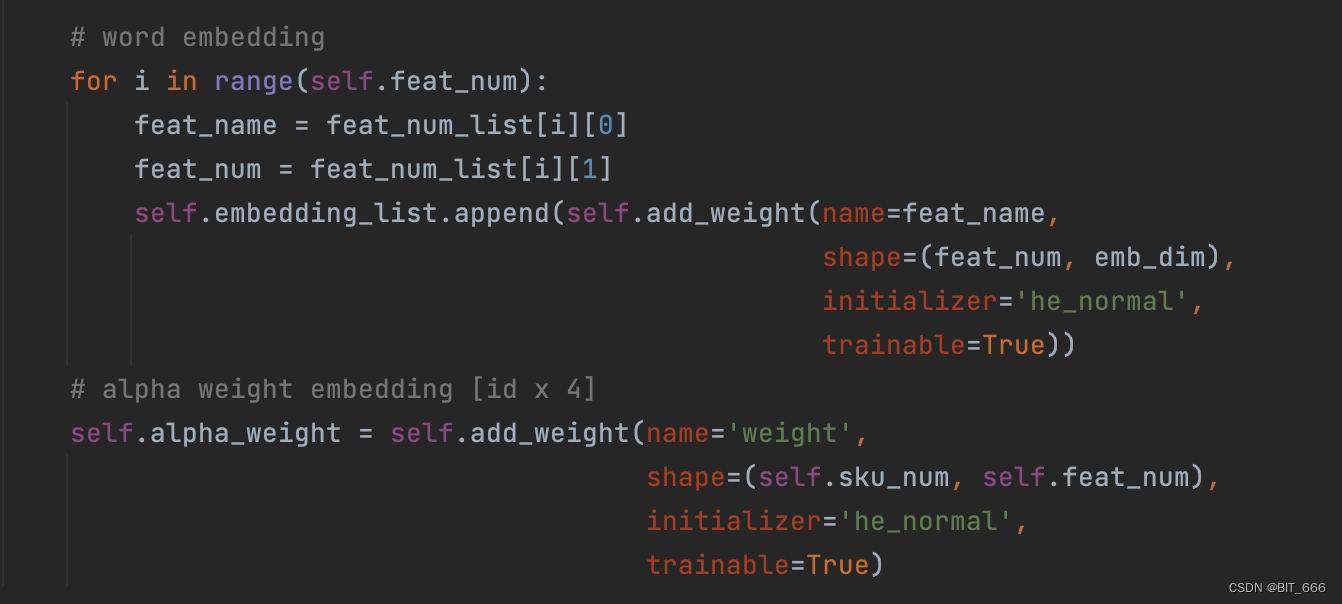
A.参数准备
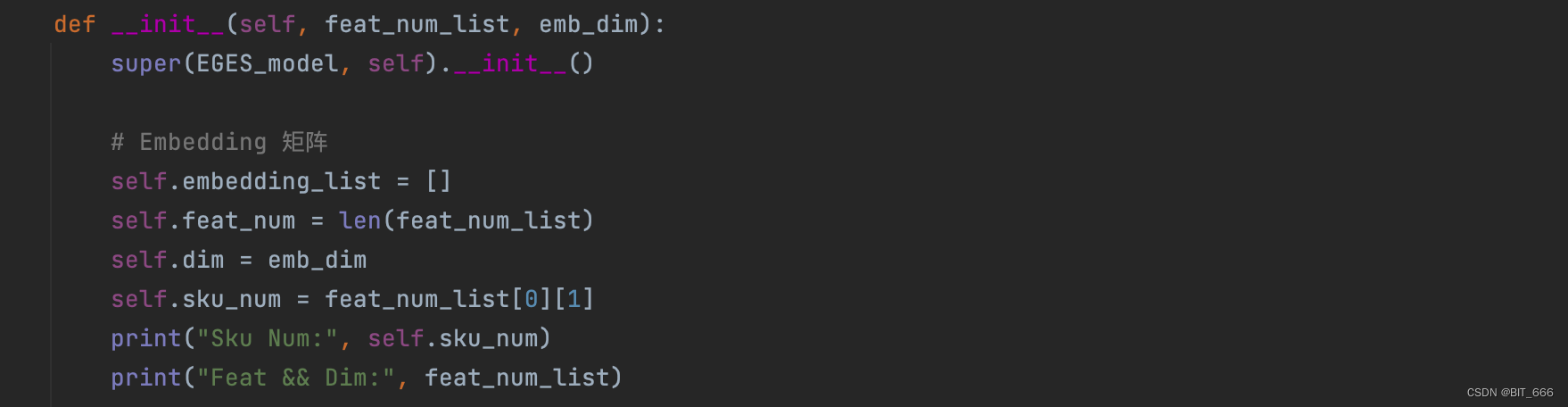
这里 embedding_list 存储 SI 0-N 的 Embedding 层参数,feat_num = 1 + s 即总特征数,dim = K 代表 Embedding 维度,sku_num = len(unique(sku_id)) 为全部商品的数量。
B.参数初始化
Sku Num: 34048
Feat && Dim: [['sku_id', 34048], ['brand', 3663], ['shop_id', 4786], ['cate', 80]]根据每个 Feat 的维度构建其 Embedding 层参数,最后构建 sku_num x feat_num 的 alpha 权重层参数。
3.2 call 方法
根据上图我们再分析下如何实现 call 方法:
• 依次获取 Embedding
按照样本书序从对应 embedding_list 中 lookup 即可获取对应向量
• 拼接 Embedding
tf.stack 直接将获取的向量拼接在一起
• 加权求和 Embedding
lookup 获取 alpha 向量,与 stack 拼接的向量对位相乘再 reduce_sum 求和即可
A.Target && Side 向量获取

原始样本为 None x 4,lookup 后 stack 在一起得到 None x 4 x 128。
B.Alpha 权重向量获取

获取对应 sku 的 1+s 维 Alpha 权重向量,为了保证每个权重的非负性,这里采用 exp 转正并通过 Softmax 的形式对每个权重参数进行了归一化。

C.reduce_sum 加权求和
直接对位相乘再除以求和后的 α 即可。

D.Dot 获取内积
加权求和 merge 后的 embedding 与 lookup 得到的 1xK 的 context 即目标词的 embedding 进行内积,最终得到 None x 1 输出到下一层。

3.3 完整代码
from abc import ABC
import tensorflow as tf
from tensorflow.python.keras.models import *
from tensorflow.python.keras.layers import *
class EGES_model(Model, ABC):
def __init__(self, feat_num_list, emb_dim):
super(EGES_model, self).__init__()
# Embedding 矩阵
self.embedding_list = []
self.feat_num = len(feat_num_list)
self.dim = emb_dim
self.sku_num = feat_num_list[0][1]
print("Sku Num:", self.sku_num)
print("Feat && Dim:", feat_num_list)
# word embedding
for i in range(self.feat_num):
feat_name = feat_num_list[i][0]
feat_num = feat_num_list[i][1]
self.embedding_list.append(self.add_weight(name=feat_name,
shape=(feat_num, emb_dim),
initializer='he_normal',
trainable=True))
# alpha weight embedding [id x 4]
self.alpha_weight = self.add_weight(name='weight',
shape=(self.sku_num, self.feat_num),
initializer='he_normal',
trainable=True)
def call(self, pairs):
(word_with_side_info, context_info) = pairs
# 获取侧信息 Embedding 用户3个侧信息 None x 4 x 128
embed_list = []
for i in range(self.feat_num):
# [N x Emb] 10x128
index = tf.cast(word_with_side_info[:, i], dtype='int32')
emb_var = tf.nn.embedding_lookup(self.embedding_list[i], index)[:, :self.dim]
embed_list.append(emb_var)
# (None, 128, 4)
combine_emb = tf.stack(embed_list, axis=-1)
# (None, 4, 128)
combine_emb = tf.reshape(combine_emb, shape=(-1, self.feat_num, self.dim))
# 加权求和
# (None, ) (None, 4) (None, )
sku_index = tf.cast(word_with_side_info[:, 0], dtype='int32')
sku_alpha_emb = tf.nn.embedding_lookup(self.alpha_weight, sku_index)[:, :]
alpha_sum = tf.expand_dims(tf.reduce_sum(tf.exp(sku_alpha_emb), axis=-1), axis=1)
# (None, 4, 128)
add_weight_emb = combine_emb * tf.exp(tf.expand_dims(sku_alpha_emb, axis=-1))
# (None, 128)
merge_emb = tf.reduce_sum(add_weight_emb, axis=1) / alpha_sum
# 上下文变量
# (None, 1, 128)
context_emb = tf.nn.embedding_lookup(self.embedding_list[0], tf.cast(context_info, dtype='int32'))[:, :self.dim]
# (None, 128)
context_emb = tf.reshape(context_emb, shape=(-1, self.dim))
# None x 1
dot_product = Dot(axes=1)([merge_emb, context_emb])
return dot_product4.向量获取
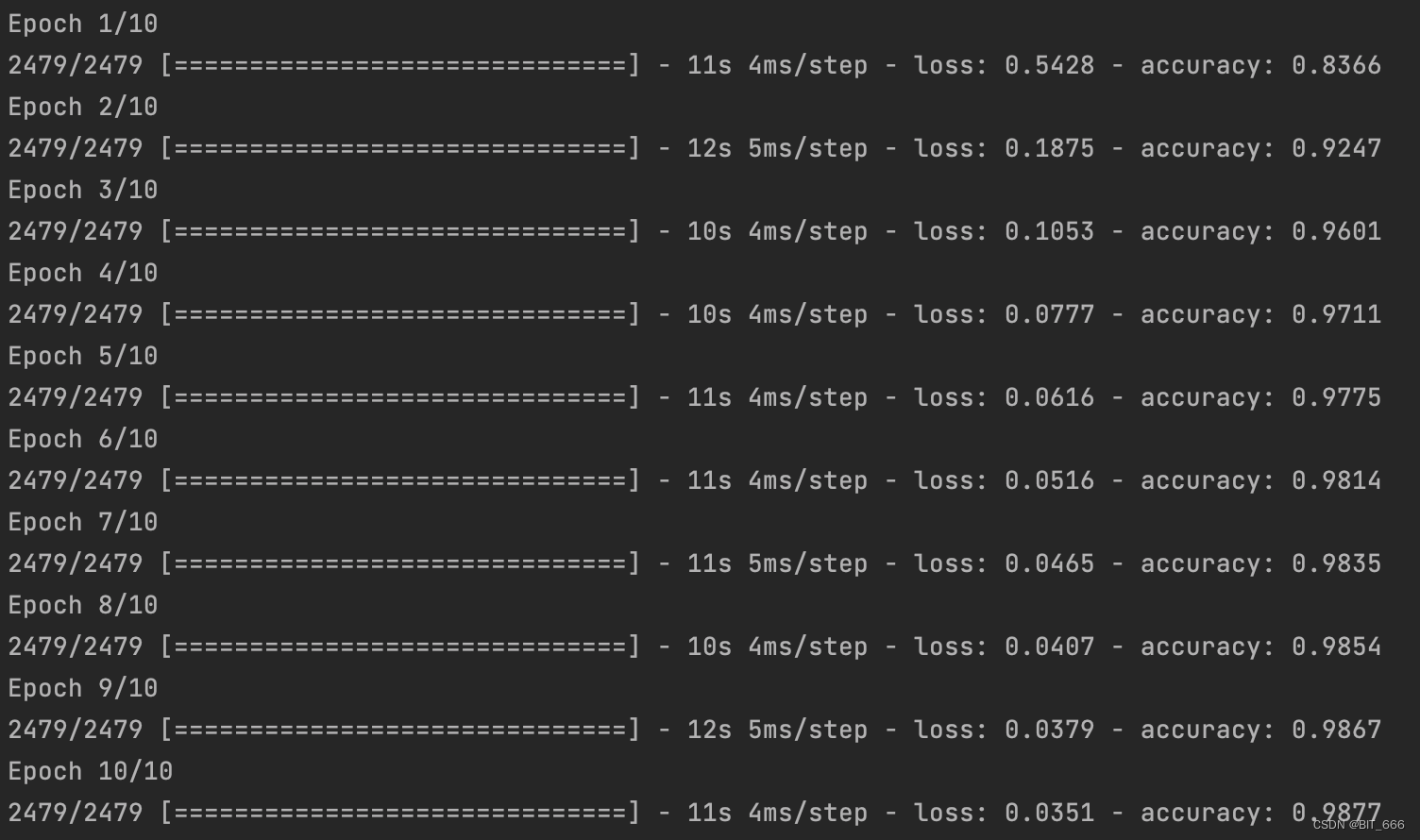
model.fit([word_target_with_side_info, word_context], np.array(labels), epochs=10, batch_size=128)
跑 10 个 epoch,同样注意把 labels 用 np.array 包起来:
训练完我们从 EGES_model 对应的 dot 层获取向量即可:
# 获取训练后的 Embedding
weight_list = model.layers[2].get_weights()
weight_map = {}
for i in range(len(feat_num_list)):
feat_name = feat_num_list[i][0]
feat_emb = weight_list[i]
weight_map[feat_name] = feat_emb针对 SI 0 - sku 和 SI 1-3 三个侧信息,我们可以获取 4 个向量矩阵,根据后续任务的不同,我们可以做如下事情:
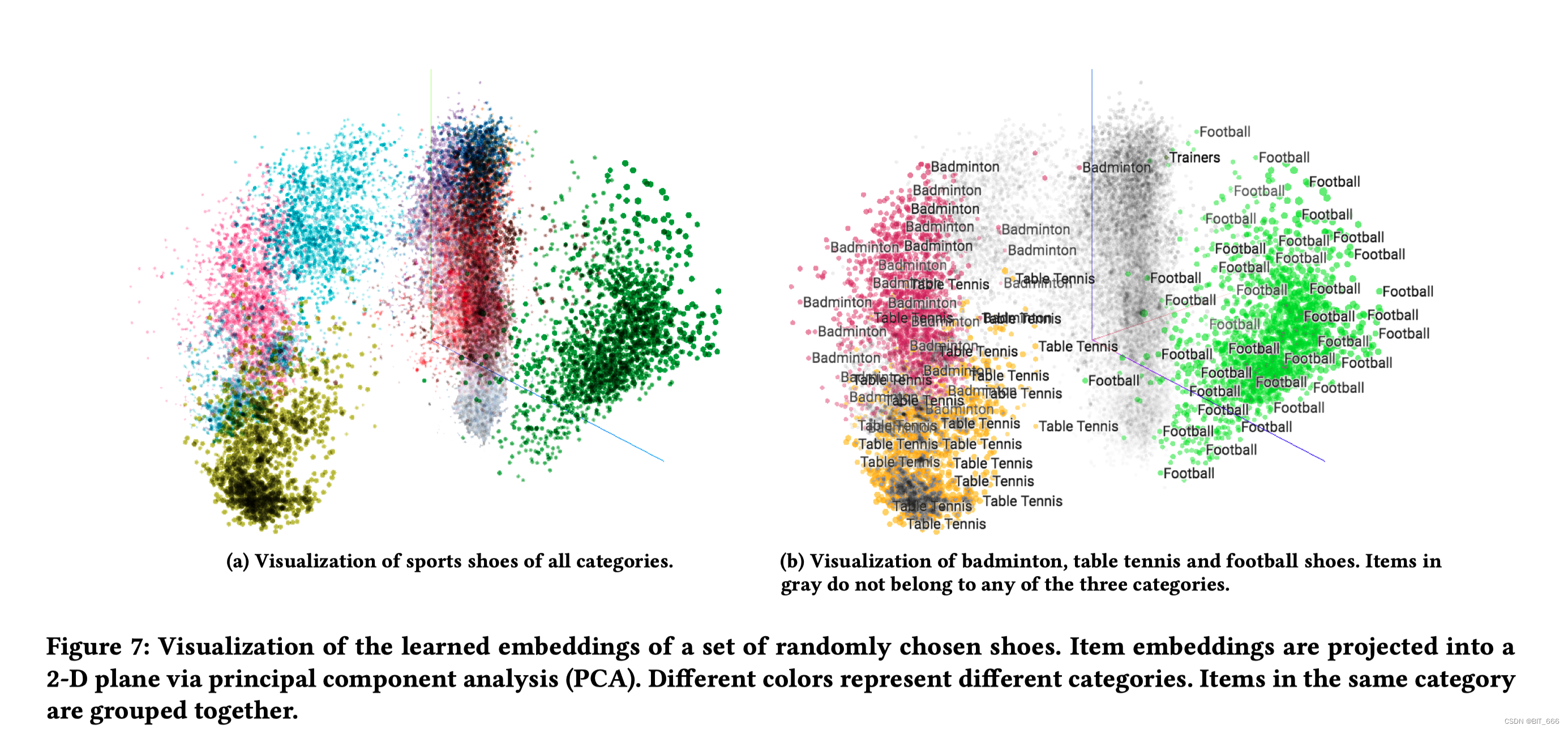
4.1 计算 sku 相似度
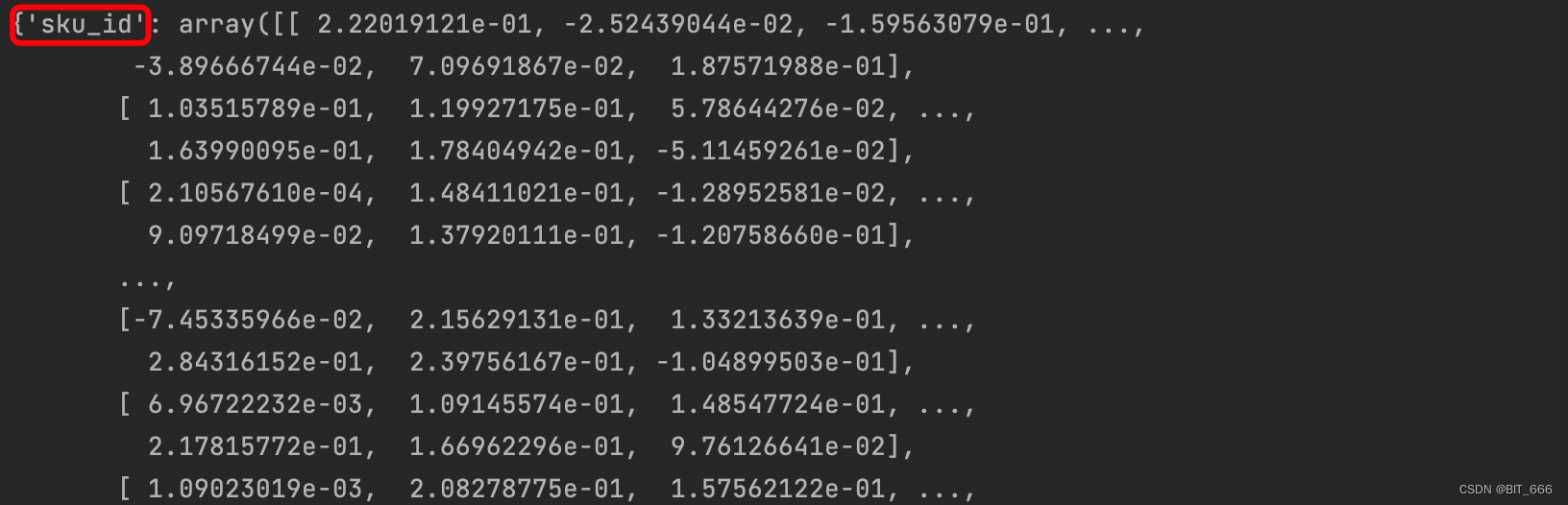
使用 sku Embedding 计算内积寻找不同 sku 的相似度,也可以降维观察不同 sku 的分布
4.2 商品 sku 冷启动
在冷启动时引入商品对应侧信息优化冷启动商品的初始 Embedding
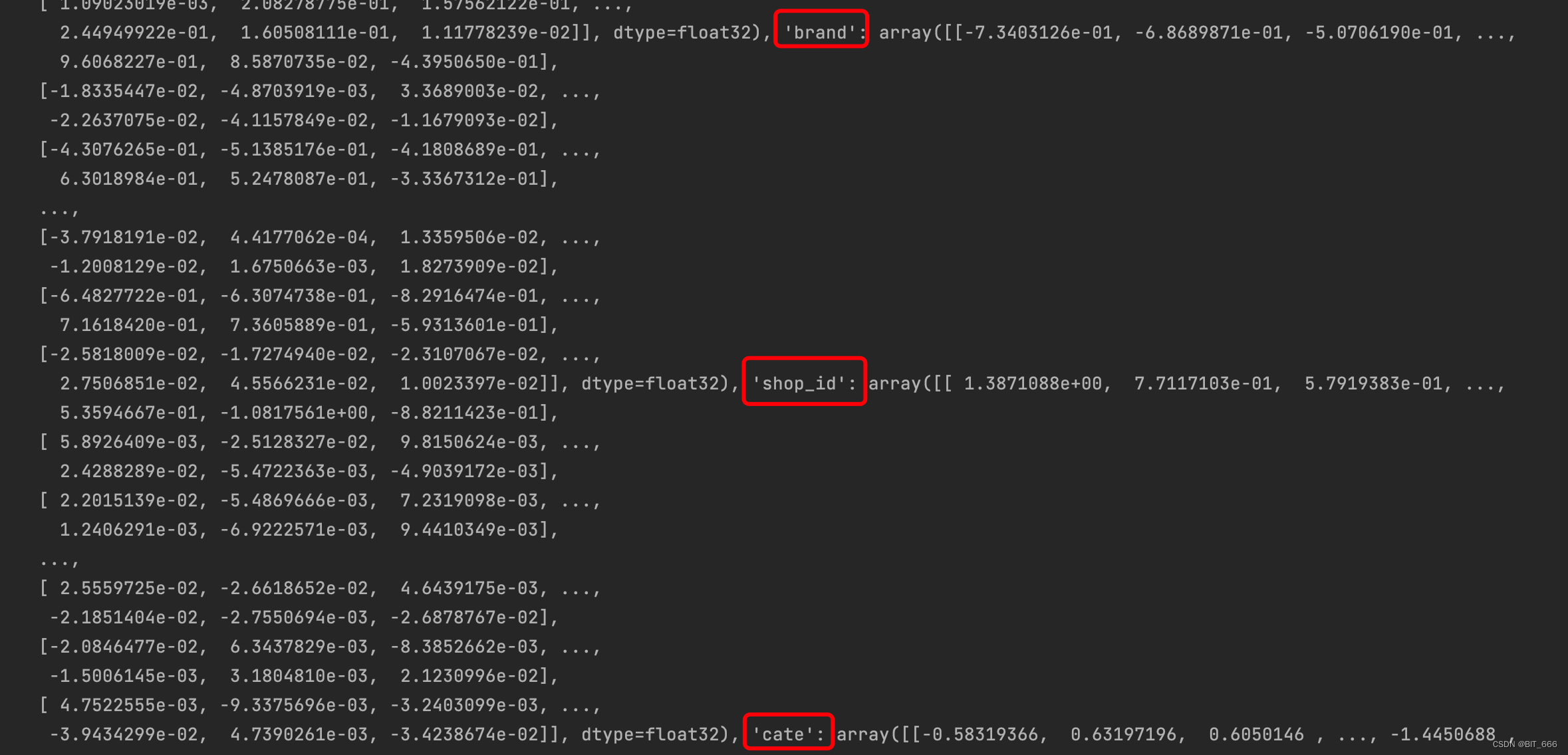

4.3 侧信息重要性分析
print(np.array(weight_list[-1]))
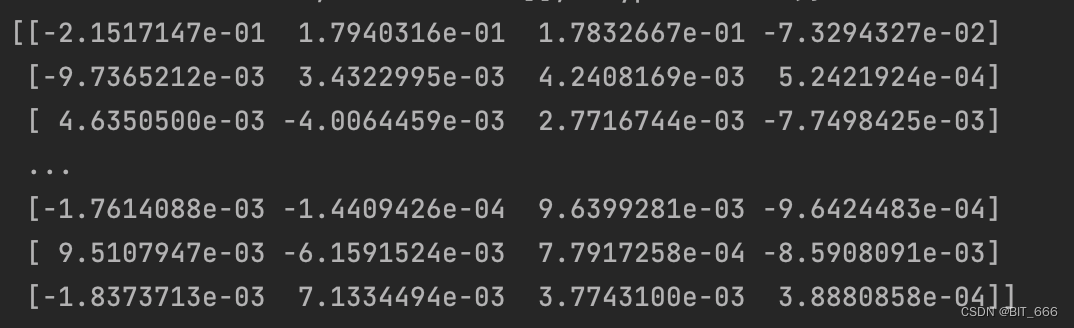
通过 alpha 参数矩阵,我们使用 exp 归一化可以分析不同 sku 的向量偏好,根据色阶图看以分析不同特征对结果的重要程度

4.4 引入预训练模型
可以将不同特征的 Embedding 用于后续 Deep 任务的参数初始化,例如 FNN 使用 FM 预训练的向量一样
五.总结
当年还未深度接触 DeepLearning 时,总觉得 word2vec 很复杂,但是通过前面的分析、再到框架最后到具体实现,我们发现其思路清晰实现也很简洁,如果把 dot 层的计算更换为其他相似度计算例如 Cos 余弦相似度,那上面的架构就和 DSSM 很类似。
word2vec 是 Google 于 2013 年开源的获取 word vector 的算法包,距今已经10年、EGES 是 2018 年由阿里巴巴算法团队提出,距今也已经5年,在算法日新月异的今天,已经算的是很"古老"的知识了,但是其 Embedding 的思想一直影响着后面深度学习的发展,因此把它搞清楚对于很多 DeepLearning 的知识理解也很有帮助。
上面利用负采样的方法实现了 Skip-gram,除了负采样的优化方法外,源码中还有很多实现的细节:
• σ(x) 的近似计算
sigmoid 函数在 x < -6 或者 x > -6 时变化已经微乎其微,实际计算中,除了 Softmax 计算量巨大外,sigmoid 函数计算也很多,可以通过细分区间缓存 σ(x) 的近似值,从而将计算切换为查表,优化计算速度。
• 向量相似度检索
由于词库的大小 N 通常很大,每次计算都匹配所有向量并内积计算相似度会非常耗时,线上无法接受,可以通过缓存 item-item 之间的相似度做的快速查找,常用的方法有 LSH(局部敏感哈希)算法。
• 低频词与高频词
利用语料构建词库时,开发者可以通过 min_count 控制每个词出现过多少次才能收到到词库中。低频词出现次数较少,但其独一无二的性质有时可以精准描述某些特定场景,而高频词虽然出现很多但却意义不大,例如 '的'、'是' 这些,因此实际场景中,除了过滤停用词外,还需要分析低频词的代表性以及高频词的实际意义。可以通过 SubSampleing 的技巧对高频词做处理,其思想是有一定概率不计算当前高频词从而优化计算速度,就像是 Dropout 一样。当然使用层次 Softmax 也可以很好地解决高频词的效率问题。
• 窗口与上下文
根于 Target 与 window_size ,我们会生成 [-window_size,window_size] -1 个样本,源码中采取先对 [1, window_size] 随机一个整数 c,然后再生成 [-c,c] -1 个样本,相当于 window_size 其实也是随机变化的。
参考:
Word2vec 的一些思考:word2vec的一些遗留思考
Word2vec 的一些理论:word2vec 中的数学原理详解
Word2cec 的一些代码:基于keras实现word2vec






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结