您现在的位置是:首页 >其他 >Flink+Kafka、Pulsar实现端到端的exactly-once语义网站首页其他
Flink+Kafka、Pulsar实现端到端的exactly-once语义
End-to-End Exactly-Once Processing in Apache Flink with Apache Kafka
2017年12月Apache Flink社区发布了1.4版本。该版本正式引入了一个里程碑式的功能:两阶段提交Sink,即TwoPhaseCommitSinkFunction。该SinkFunction提取并封装了两阶段提交协议中的公共逻辑,自此Flink搭配特定source和sink(特别是0.11版本Kafka)搭建仅一次处理语义( exactly-once semantics)应用成为了可能。作为一个抽象类TwoPhaseCommitSinkFunction提供了一个抽象层供用户自行实现特定方法来支持 exactly-once semantics。
本文将深入讨论一下Flink 仅一次处理的设计思想。在本文中我们将:
1. 描述Flink应用中的checkpoint如何帮助确保exactly-once semantics
2. 展示Flink如何通过两阶段提交协议与source和sink交互以实现端到端的 exactly-once semantics交付保障
3. 给出一个使用TwoPhaseCommitSinkFunction实现 exactly-once semantics的文件Sink实例
Flink应用的仅一次处理
当谈及仅一次处理时,我们真正想表达的是每条输入消息只会影响最终结果一次!【译者:影响应用状态一次,而非被处理一次】即使出现机器故障或软件崩溃,Flink也要保证不会有数据被重复处理或压根就没有被处理,从而影响状态。长久以来Flink一直宣称支持 exactly-once semantics是指在一个Flink应用内部。在过去的几年间,Flink开发出了checkpointing机制,而它则是提供这种应用内仅一次处理的基石。
在继续之前我们简要总结一下checkpointing算法,这对于我们了解本文内容至关重要。简单来说,一个Flink checkpoint是一个一致性快照,它包含:
1. 应用的当前状态
2. 消费的输入流位置
Flink会定期地产生checkpoint并且把这些checkpoint写入到一个持久化存储上,比如S3或HDFS。这个写入过程是异步的,这就意味着Flink即使在checkpointing过程中也是不断处理输入数据的。
如果出现机器或软件故障,Flink应用重启后会从最新成功完成的checkpoint中恢复——重置应用状态并回滚状态到checkpoint中输入流的正确位置,之后再开始执行数据处理,就好像该故障或崩溃从未发生过一般。
在Flink 1.4版本之前,仅一次处理只限于Flink应用内。Flink处理完数据后需要将结果发送到外部系统,这个过程中Flink并不保证仅一次处理。即每条消息只会影响Flink内部状态有且只有一次,但无法保证输出到Sink中的数据不重复。
但是Flink应用通常都需要接入很多下游子系统,而开发人员很希望能在多个系统上维持仅一次处理语义,即维持端到端的仅一次处理语义。
为了提供端到端的仅一次处理语义,仅一次处理语义必须也要应用于Flink写入数据的外部系统——故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与Flink checkpoint能够协调使用。
在分布式系统中协调提交和回滚的一个常见方法就是使用两阶段提交协议。下节中我们将讨论下Flink的TwoPhaseCommitSinkFunction是如何利用两阶段提交协议来实现exactly-once semantics的。
Flink实现仅一次语义的应用
下面将给出一个实例来帮助了解两阶段提交协议以及Flink如何使用它来实现仅一次处理语义。该实例从Kafka中读取数据,经处理之后再写回到Kafka。Kafka是非常受欢迎的消息队列,而Kafka 0.11.0.0版本正式发布了对于事务的支持——这是与Kafka交互的Flink应用要实现端到端仅一次语义的必要条件。
当然,Flink支持这种仅一次处理语义并不只是限于与Kafka的结合,可以使用任何source/sink,只要它们提供了必要的机制。举个例子,Pravega是Dell/EMC的一个开源流式存储系统,Flink搭配它也可以实现端到端的exactly-once semantics。
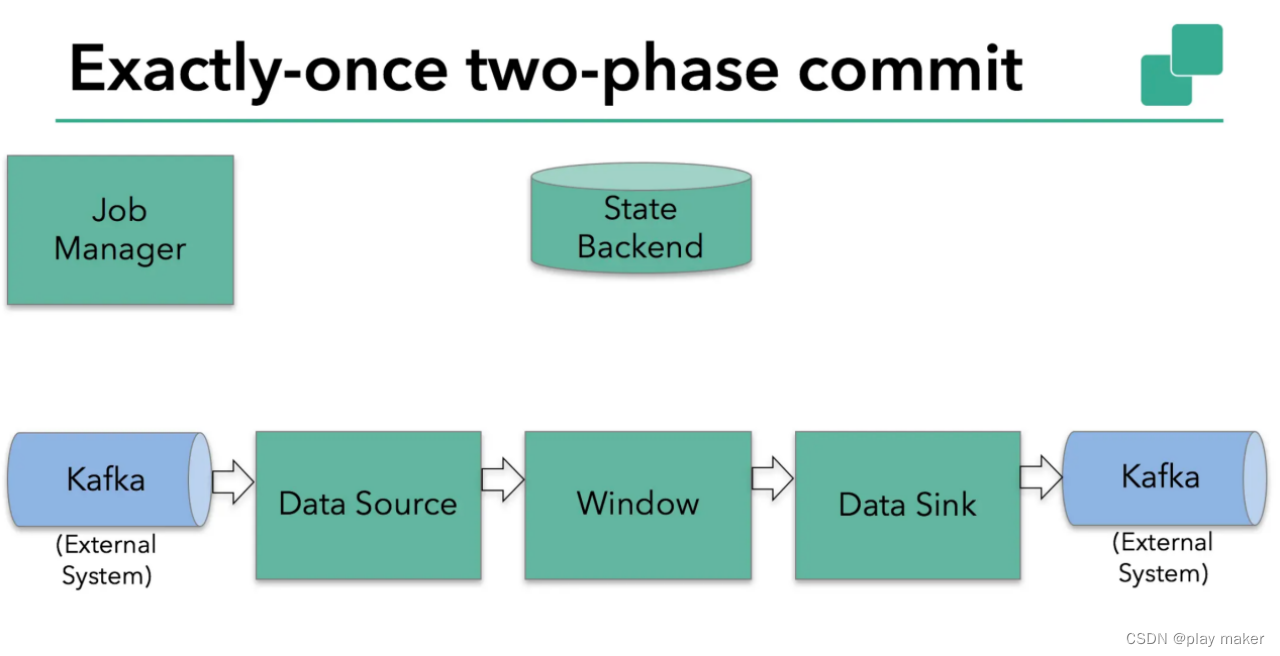
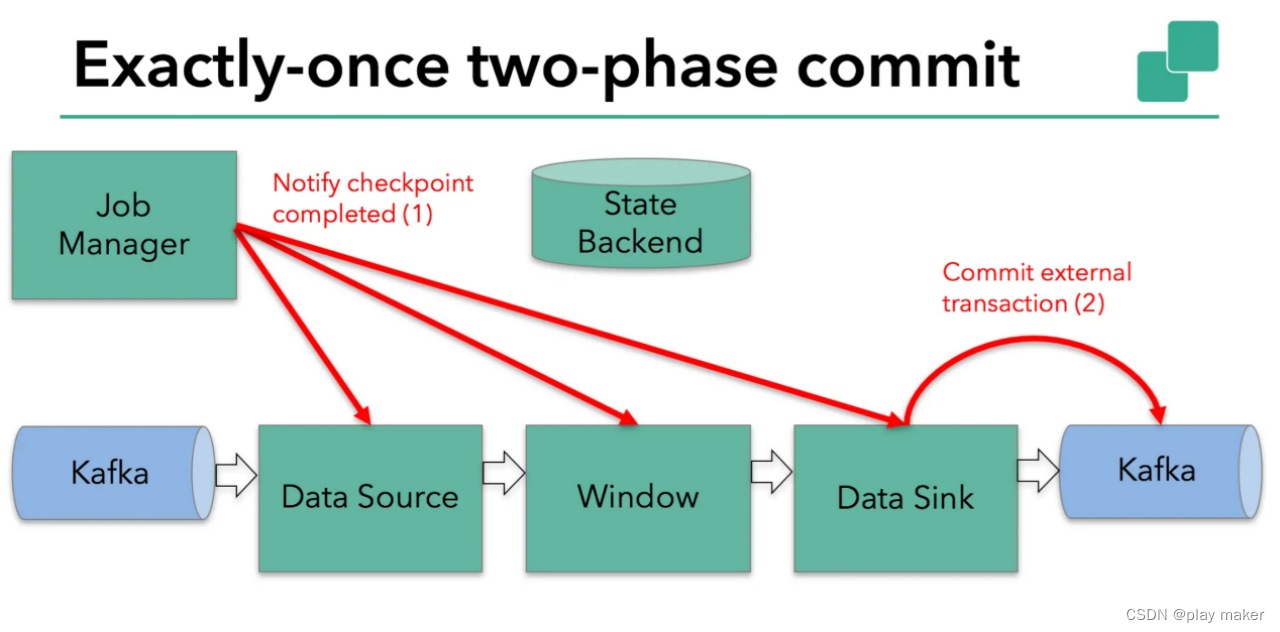
本例中的Flink应用包含以下组件,如上图所示:
1. 一个source,从Kafka中读取数据(即KafkaConsumer)
2. 一个时间窗口化的聚会操作
3. 一个sink,将结果写回到Kafka(即KafkaProducer)
若要sink支持 exactly-once semantics,它必须以事务的方式写数据到Kafka,这样当提交事务时两次checkpoint间的所有写入操作当作为一个事务被提交(因此,Kafka、Pulsar的事务超时时间都必须要大于做checkpoint的时间间隔)。这确保了出现故障或崩溃时这些写入操作能够被回滚。
当然了,在一个分布式且含有多个并发执行sink的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一个一致性的结果。Flink使用两阶段提交协议以及预提交(pre-commit)阶段来解决这个问题。
Flink checkpointing开始时便进入到pre-commit阶段。具体来说,一旦checkpoint开始,Flink的JobManager向输入流中写入一个checkpoint barrier将流中所有消息分割成属于本次checkpoint的消息以及属于下次checkpoint的。barrier也会在操作算子operator间流转。每个算子会对当前的状态做个快照,保存到StateBackend。
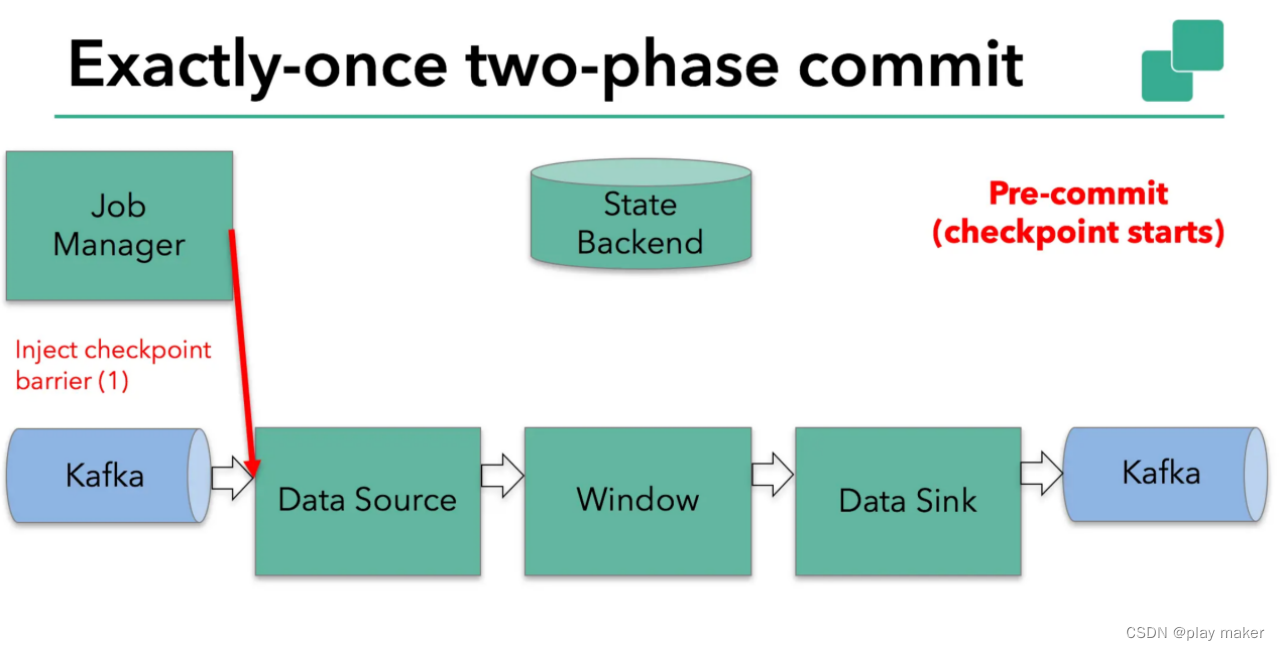
对于 source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 checkpoint 恢复时,source 任务可以从上次保存的位置开始重新消费数据。
flink kafka source保存Kafka消费offset,一旦完成offset保存,它会将checkpoint barrier传给下一个operator。每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。
这个方法对于opeartor只有内部状态的场景是可行的。所谓的内部状态就是完全由Flink状态保存并管理的——本例中的第二个opeartor:时间窗口上保存的求和数据就是这样的例子。当只有内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些已定义的状态变量即可。当chckpoint成功时Flink负责提交这些写入,否则就终止掉它们。
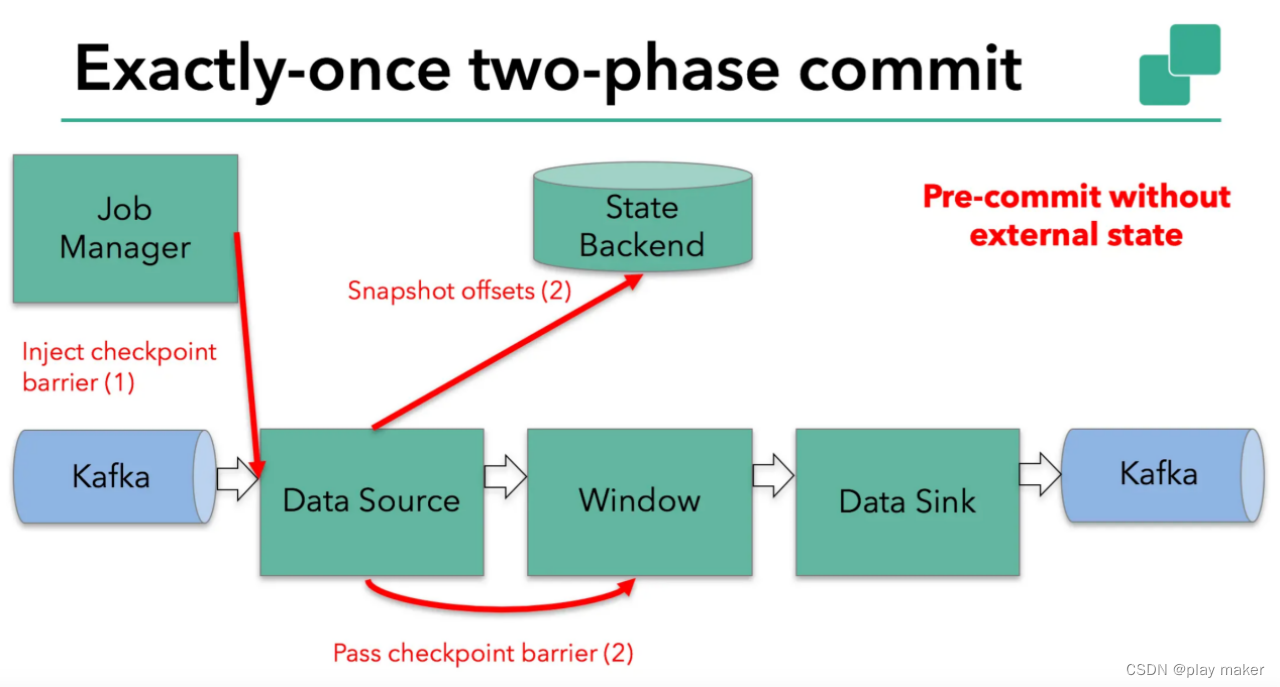
但是,一旦operator包含外部状态,事情就不一样了。我们不能像处理内部状态一样处理这些外部状态。因为外部状态通常都涉及到与外部系统的交互。如果是这样的话,外部系统必须要支持可与两阶段提交协议捆绑使用的事务才能确保实现整体的exactly-once semantics。
显然本例中的data sink是有外部状态的,因为它需要写入数据到Kafka。此时的pre-commit阶段下data sink在保存状态到状态存储的同时还必须预提交它的外部事务,如下图所示:
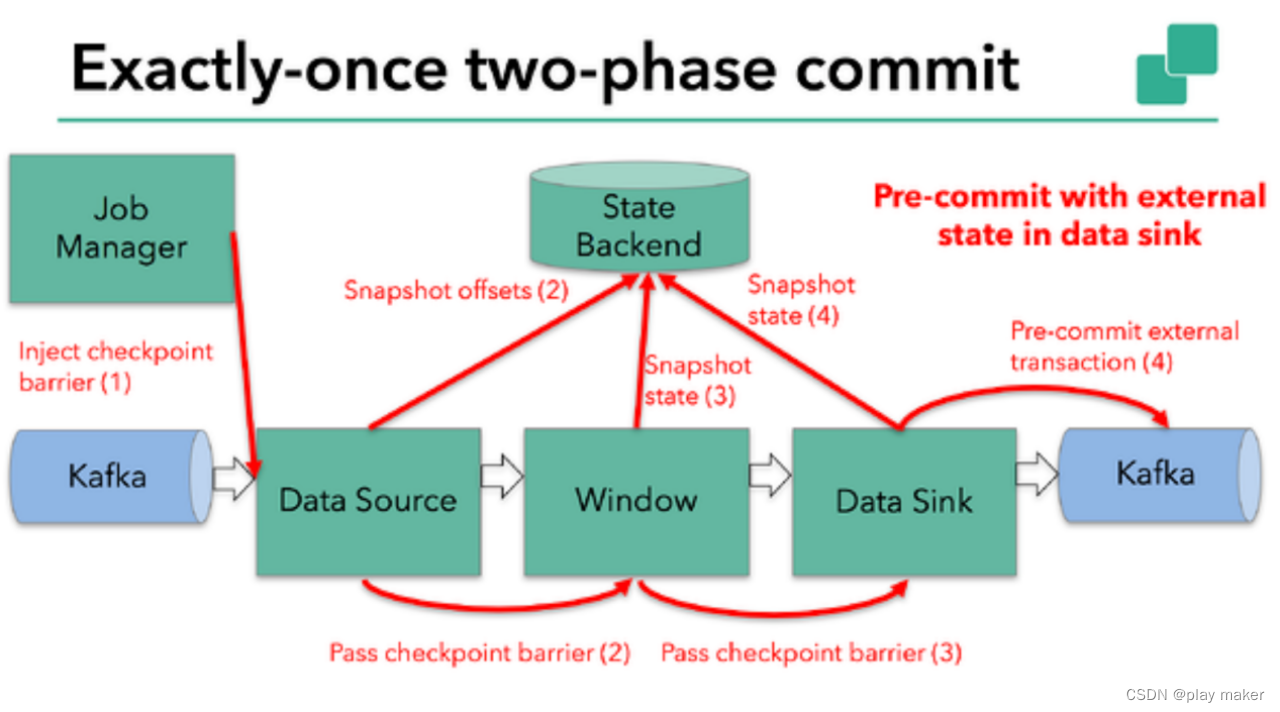
当checkpoint barrier在所有operator都传递了一遍且对应的快照也都成功完成之后,pre-commit阶段才算完成。该过程中所有创建的快照都被视为是checkpoint的一部分。其实,checkpoint就是整个应用的全局状态,当然也包含pre-commit阶段提交的外部状态。当出现崩溃时,我们可以回滚状态到最新已成功完成快照时的时间点。
下一步就是通知所有的operator,告诉它们checkpoint已成功完成。这便是两阶段提交协议的第二个阶段:commit阶段。该阶段中JobManager会为应用中每个operator发起checkpoint已完成的回调逻辑。
本例中的data source和窗口操作无外部状态,因此在该阶段,这两个opeartor无需执行任何逻辑,但是data sink是有外部状态的,因此此时我们必须提交外部事务,如下图所示:
汇总以上所有信息,总结一下:
1. 一旦所有operator完成各自的pre-commit,它们会发起一个commit操作
2. 倘若有一个pre-commit失败,所有其他的pre-commit必须被终止,并且Flink会回滚到最近成功完成的decheckpoint处。
3. 一旦pre-commit完成,必须要确保commit也要成功——operator和外部系统都需要对此进行保证。倘若commit失败(比如网络故障等),Flink应用就会挂掉,然后根据用户重启策略执行重启逻辑,之后再次重试commit。这个过程至关重要,因为倘若commit无法顺利执行,就可能出现数据丢失的情况。
因此,所有opeartor必须对checkpoint最终结果达成共识:即所有operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
Flink中实现两阶段提交
这种operator的管理有些复杂,这也是为什么Flink提取了公共逻辑并封装进TwoPhaseCommitSinkFunction抽象类的原因。
下面讨论一下如何扩展TwoPhaseCommitSinkFunction类来实现一个简单的基于文件的sink。若要实现支持exactly-once semantics的文件sink,我们需要实现以下4个方法:
1. beginTransaction:开启一个事务,在临时目录下创建一个临时文件,之后,写入数据到该文件中
2. preCommit:在pre-commit阶段,flush缓存数据块到磁盘,然后关闭该文件,确保再不写入新数据到该文件。同时开启一个新事务执行属于下一个checkpoint的写入操作
3. commit:在commit阶段,我们以原子性的方式将上一阶段的文件写入真正的文件目录下。注意:这会增加输出数据可见性的延时。通俗说就是用户想要看到最终数据需要等会,不是实时的。
4. abort:一旦终止事务,我们删除临时文件。
当出现崩溃时,Flink会恢复最新已完成快照中应用状态。需要注意的是在某些极偶然的场景下,pre-commit阶段已成功完成而commit尚未开始(也就是operator尚未来得及被告知要开启commit),此时倘若发生崩溃Flink会将opeartor状态恢复到已完成pre-commit但尚未commit的状态。
在一个checkpoint状态中,对于已完成pre-commit阶段的事务状态,我们必须保存足够多的信息,这样才能确保在重启后重新发起commit或者abort掉事务。本例中这部分信息就是临时文件所在的路径以及目标目录(Kafka、Pulsar中则只需要保存事务ID号即可,因此checkpoint中会包含事务ID号)。
TwoPhaseCommitSinkFunction考虑了这种场景,因此当应用从checkpoint恢复之后TwoPhaseCommitSinkFunction总是会发起一个抢占式的commit。我们在具体实现的时候需要保证commit必须是幂等性的,虽然大部分情况下这都不是问题。本例中对应的这种场景就是:临时文件不在临时目录下,而是已经被移动到目标目录下。
还有少数其他边缘案例TwoPhaseCommitSinkFunction也考虑到了。
TwoPhaseCommitSinkFunction (flink 1.4-SNAPSHOT API)
Flink中将两阶段提交做了一个抽象 TwoPhaseCommitSinkFunction,其实现了CheckpointedFunction与CheckpointListener这两个与checkpoint流程相关的两个接口,提供了以下几个主要的抽象方法:
·beginTransaction:开启事务
·preCommit:预提交
·commit:提交
·recoverAndCommit :恢复并且commit事务
·abort:取消事务
·recoverAndAbort:恢复并且abort事务
让使用者只需要实现这几个方法即可。
注记:对于FlinkKafkaProducer 的实现只需要继承TwoPhaseCommitSinkFunction 类,并且重写上面几个抽象方法即可。
下面介绍各个API的含义。
1. beginTransaction

意义很明显
2. preCommit

预提交前面创建的事务。预提交会执行所有必要的步骤,以准备接下来的commit操作。
预提交之后仍然可能会abort事务,但是底层实现必须保证对already precommitted的事务执行commit会成功(保证commit成功,但是可能不调用commit,而是调用abort)。
3. commit
 commit一个pre-committed事务,如果commit方法失败,Flink应用会重启并且对同一个事务调用recoverAndCommit(Object)方法。
commit一个pre-committed事务,如果commit方法失败,Flink应用会重启并且对同一个事务调用recoverAndCommit(Object)方法。
4. recoverAndCommit

在failure后对一个recovered的事务执行该方法。
用户实现必须保证这个方法最终会成功。如果该方法失败,Flink应用会重启并且重新调用该方法。
如果最终都无法成功,则会导致数据丢失。
事务会以它们创建的顺序进行recover。
5. abort、recoverAndAbort


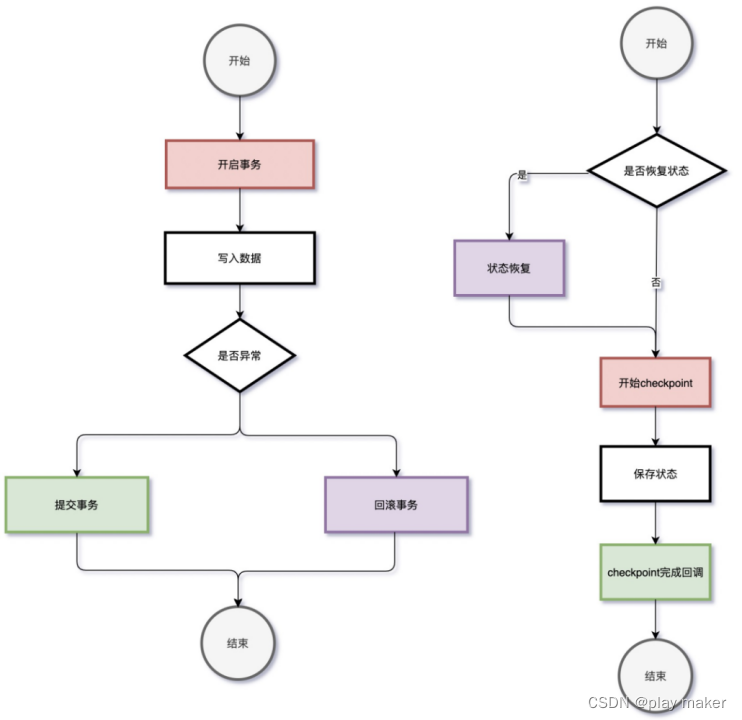
左侧为正常事务的提交(以客户端的视角)流程,右侧为checkpoint 略缩版流程, 那么现在需要将这两部分逻辑融合起来。
看看在flink 的执行流程去看是如何调用前面几个方法的:

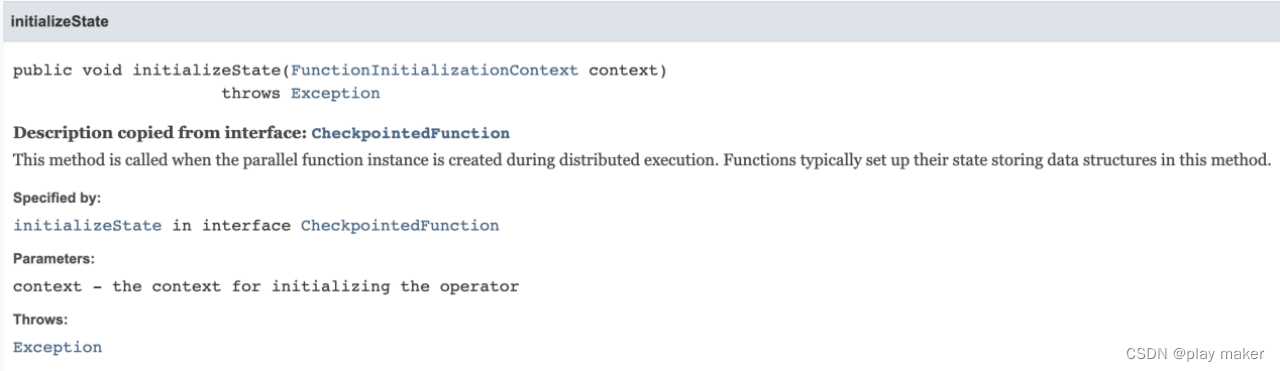
·initializeState
当在分布式执行过程中创建并行函数实例时,该方法被调用。函数通常在此方法中设置其状态存储数据结构。
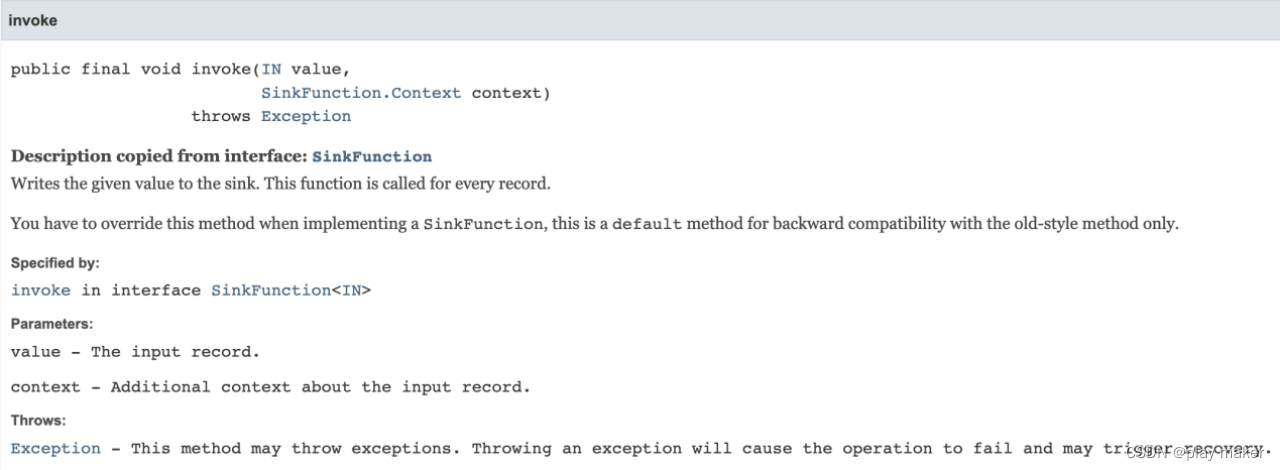
·invoke
invoke方法对每条record进行调用,并将结果写入sink。

·snapshot
当请求做checkpoint的快照时,该方法被调用。
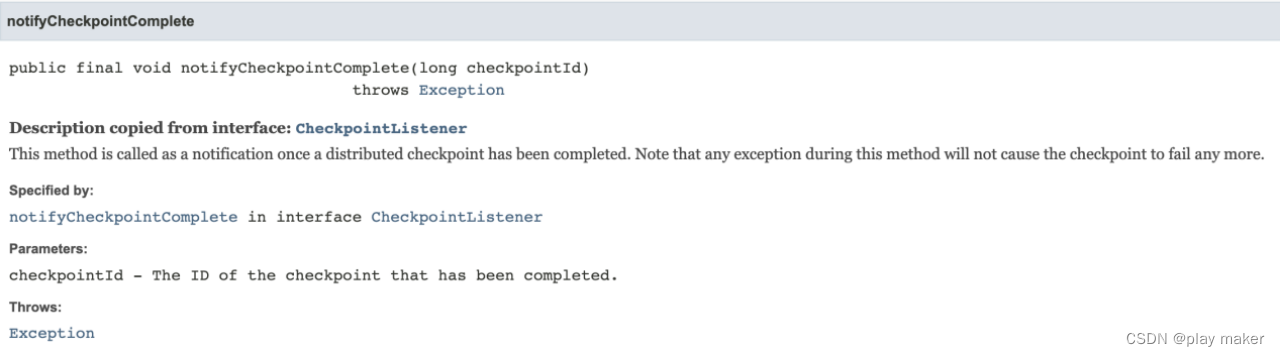
·notifyCheckpointComplete
一旦完成分布式checkpoint,该方法将被调用。请注意,此方法中的任何报错都不会导致checkpoint失败,因此这个方法必须要成功执行,否则就会导致不一致。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结