您现在的位置是:首页 >学无止境 >数据库底层运行原理之——事务管理器网站首页学无止境
数据库底层运行原理之——事务管理器
一般所有关系型数据库内部都有自己的事务机制,进程是如何保证每个查询在自己的事务内执行的,通过这篇文章来简单介绍一下。
我们可以理解为数据库是由多种相互交互的组件构成的,数据库一般可以用如下图形来理解:
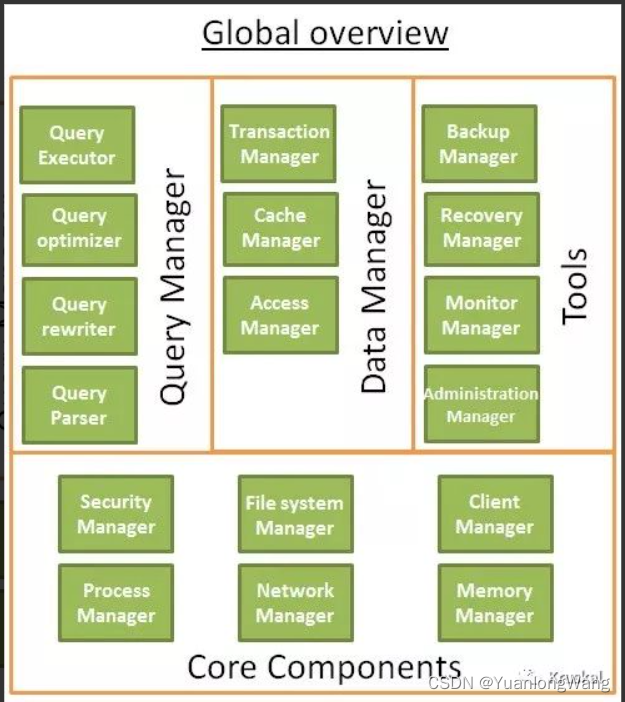
事务管理器就是今天要介绍的其中一个组件:Transaction manager
在讲事务之前,我们需要理解ACID事务的概念。
一个ACID事务是一个工作单元,它要保证4个属性:
- 原子性(Atomicity): 事务『要么全部完成,要么全部取消』,即使它持续运行10个小时。如果事务崩溃,状态回到事务之前(事务回滚)。
- 隔离性(Isolation): 如果2个事务 A 和 B 同时运行,事务 A 和 B 最终的结果是相同的,不管 A 是结束于 B 之前/之后/运行期间。
- 持久性(Durability): 一旦事务提交(也就是成功执行),不管发生什么(崩溃或者出错),数据要保存在数据库中。
- 一致性(Consistency): 只有合法的数据(依照关系约束和函数约束)能写入数据库,一致性与原子性和隔离性有关。
现代数据库不会使用纯粹的隔离作为默认模式,因为它会带来巨大的性能消耗。SQL一般定义4个隔离级别:
- 串行化(Serializable,SQLite默认模式):最高级别的隔离。两个同时发生的事务100%隔离,每个事务有自己的『世界』。
- 可重复读(Repeatable read,MySQL默认模式):每个事务有自己的『世界』,除了一种情况。如果一个事务成功执行并且添加了新数据,这些数据对其他正在执行的事务是可见的。但是如果事务成功修改了一条数据,修改结果对正在运行的事务不可见。所以,事务之间只是在新数据方面突破了隔离,对已存在的数据仍旧隔离。 举个例子,如果事务A运行”SELECT count(1) from TABLE_X” ,然后事务B在 TABLE_X 加入一条新数据并提交,当事务A再运行一次 count(1)结果不会是一样的。 这叫幻读(phantom read)。
- 读取已提交(Read committed,Oracle、PostgreSQL、SQL Server默认模式):可重复读+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(或删除)并提交,事务A再次读取数据D时数据的变化(或删除)是可见的。 这也叫不可重复读(non-repeatable read)。
- 读取未提交(Read uncommitted):最低级别的隔离,是读取已提交+新的隔离突破。如果事务A读取了数据D,然后数据D被事务B修改(但并未提交,事务B仍在运行中),事务A再次读取数据D时,数据修改是可见的。如果事务B回滚,那么事务A第二次读取的数据D是无意义的,因为那是事务B所做的从未发生的修改(已经回滚了嘛)。 这也叫脏读(dirty read)。
默认的隔离级别可以由用户/开发者在建立连接时指定,一般mysql默认的隔离级别是 可重复读 ,当然,隔离级别越高的话,对应的效率是越低的。
并发控制
确保隔离性、一致性和原子性的真正问题是对相同数据的写操作(增、更、删):
- 如果所有事务只是读取数据,它们可以同时工作,不会更改另一个事务的行为。
- 如果多个事务同时操作同一个数据,可能出现事务A的更改被事务B或者C所覆盖等等。
因此在高并发下要对可能出现的一些问题做 并发控制。
最简单的解决办法是依次执行每个事务(即顺序执行),但这样就完全没有伸缩性了,在一个多处理器/多核服务器上只有一个核心在工作,效率很低。
为了解决这个问题,多数数据库使用锁和/或数据版本控制。
悲观锁
原理是:
如果一个事务需要一条数据,它就把数据锁住,如果另一个事务也需要这条数据,它就必须要等第一个事务释放这条数据 这个锁叫排他锁。
但是对一个仅仅读取数据的事务使用排他锁非常昂贵,因为这会迫使其它只需要读取相同数据的事务等待。因此就有了另一种锁,共享锁。
共享锁是这样的:
如果一个事务只需要读取数据A,它会给数据A加上『共享锁』并读取,如果第二个事务也需要仅仅读取数据A,它会给数据A加上『共享锁』并读取,如果第三个事务需要修改数据A,它会给数据A加上『排他锁』,但是必须等待另外两个事务释放它们的共享锁。
同样的,如果一块数据被加上排他锁,一个只需要读取该数据的事务必须等待排他锁释放才能给该数据加上共享锁。
锁管理器是添加和释放锁的进程,在内部用一个哈希表保存锁信息(关键字是被锁的数据),并且了解每一块数据是:
- 被哪个事务加的锁
- 哪个事务在等待数据解锁
死锁
使用锁会导致一种情况,2个事务永远在等待一块数据
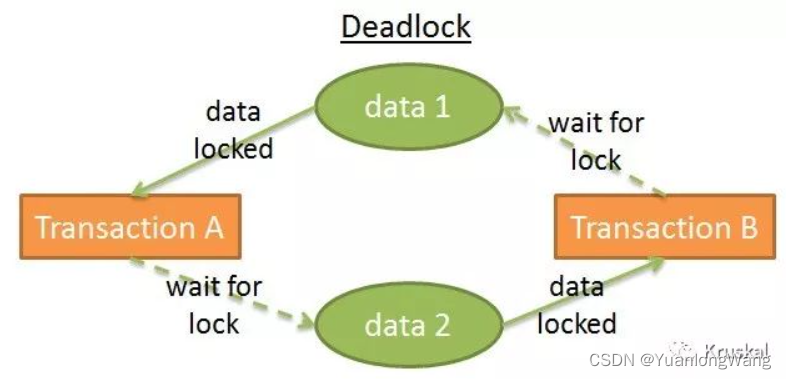
如上图所示:
- 事务A 给 数据1 加上排他锁并且等待获取数据2
- 事务B 给 数据2 加上排他锁并且等待获取数据1
这叫死锁。
在死锁发生时,锁管理器要选择取消(回滚)一个事务,以便消除死锁,这也是一个比较耗时的过程。
哈希表可以看作是个图表(见上文图),图中出现循环就说明有死锁。由于检查循环是昂贵的(所有锁组成的图表是很庞大的),经常会通过简单的途径解决:使用超时设定。如果一个锁在超时时间内没有加上,那事务就进入死锁状态。
事务开始时获取锁,结束时释放锁,这是可以实现纯粹的隔离,但是这种方法会等待所有的锁,大量的时间被浪费了。
更快的方法是两段锁协议(Two-Phase Locking Protocol,由 DB2 和 SQL Server使用),在这里,事务分为两个阶段:
- 成长阶段:事务可以获得锁,但不能释放锁。
- 收缩阶段:事务可以释放锁(对于已经处理完而且不会再次处理的数据),但不能获得新锁。
这两条简单规则背后的原理是:
- 释放不再使用的锁,来降低其它事务的等待时间
- 防止发生这类情况:事务最初获得的数据,在事务开始后被修改,当事务重新读取该数据时发生不一致。
这个规则可以很好地工作,但有个例外:如果修改了一条数据、释放了关联的锁后,事务被取消(回滚),而另一个事务读到了修改后的值,但最后这个值却被回滚。为了避免这个问题,所有独占锁必须在事务结束时释放。
数据版本控制是解决这个问题的另一个方法。
版本控制是这样的:
- 每个事务可以在相同时刻修改相同的数据
- 每个事务有自己的数据拷贝(或者叫版本)
- 如果2个事务修改相同的数据,只接受一个修改,另一个将被拒绝,相关的事务回滚(或重新运行)
这将提高性能,因为:
- 读事务不会阻塞写事务
- 写事务不会阻塞读
- 没有『臃肿缓慢』的锁管理器带来的额外开销
一些数据库,比如DB2(直到版本 9.7)和 SQL Server(不含快照隔离)仅使用锁机制。其他的像PostgreSQL, MySQL 和 Oracle 使用锁和鼠标版本控制混合机制。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结