您现在的位置是:首页 >学无止境 >达摩院开源工业级说话人识别模型CAM++网站首页学无止境
达摩院开源工业级说话人识别模型CAM++
近日,达摩院正式向公众开源工业级说话人识别通用模型CAM++,兼顾准确率和计算效率,训练labels类别达20万,每类含20~200条梅尔频谱特征。当前该模型已上线Modelscope魔搭社区,后续将陆续开源针对各场景优化的工业级模型。
模型下载地址👇:
https://www.modelscope.cn/models/damo/speech_campplus_sv_zh-cn_16k-common/summary
▎模型效果
CAM++在公开的英文数据集VoxCeleb和中文数据集CN-Celeb上通过实验验证,获得了0.73%和6.78%的EER,优于ECAPA-TDNN和ResNet34。使用20万类别训练的CAM++更是将CN-Celeb测试集EER刷新到4.32%。
同时我们比较了三者的参数量,计算量和推理实时率,结果显示CAM++在计算量和推理速度上有非常明显的优势,相比ECAPA-TDNN有着不到一半的计算量和RTF(实时率)。高准确率低实时率意味着实际应用中CAM++可以快速地提取准确的说话人特征,更加容易的应用于各种任务和实时场景下。

表1. 在单核CPU上推理时,CAM++的RTF显著优于ResNet34和ECAPA-TDNN

表2. 各模型在CN-Celeb上错误率(EER)对比

表3. 使用VoxCeleb训练集和相同的数据增广时,CAM++错误率(EER)依然低于ResNet34和ECAPA-TDNN
在说话人识别领域中,主流的说话人识别模型大多是基于时延神经网络或者二维卷积网络,比如ECAPA-TDNN和ResNet模型,这些模型获得理想性能的同时,通常伴随着较多的参数量和较大的计算量。如何兼具准确识别和高效计算,实现整体优解,是当前说话人识别领域的研究热点之一。
为此,达摩院提出说话人识别模型CAM++。该模型主干部分采用基于密集型连接的时延网络(D-TDNN),每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用和时延网络的一维卷积,可以显著提高网络的计算效率。
同时,D-TDNN的每一层都嵌入了一个轻量级的上下文相关的掩蔽(Context-aware Mask,CAM)模块。CAM模块通过全局和段级的池化操作,提取不同尺度的上下文信息,生成的mask可以去除掉特征中的无关噪声。TDNN-CAM形成了局部-段级-全局特征的统一建模,网络可以学习到特征中更加丰富的说话人信息。CAM++的前端模块是一个轻量的残差卷积网络,采用时频维度的二维卷积。相比一维卷积,二维卷积的感受野更小,可以捕获更加局部和精细的频域信息,同时,还对输入特征中可能存在的说话人特定频率模式偏移具有鲁棒性。
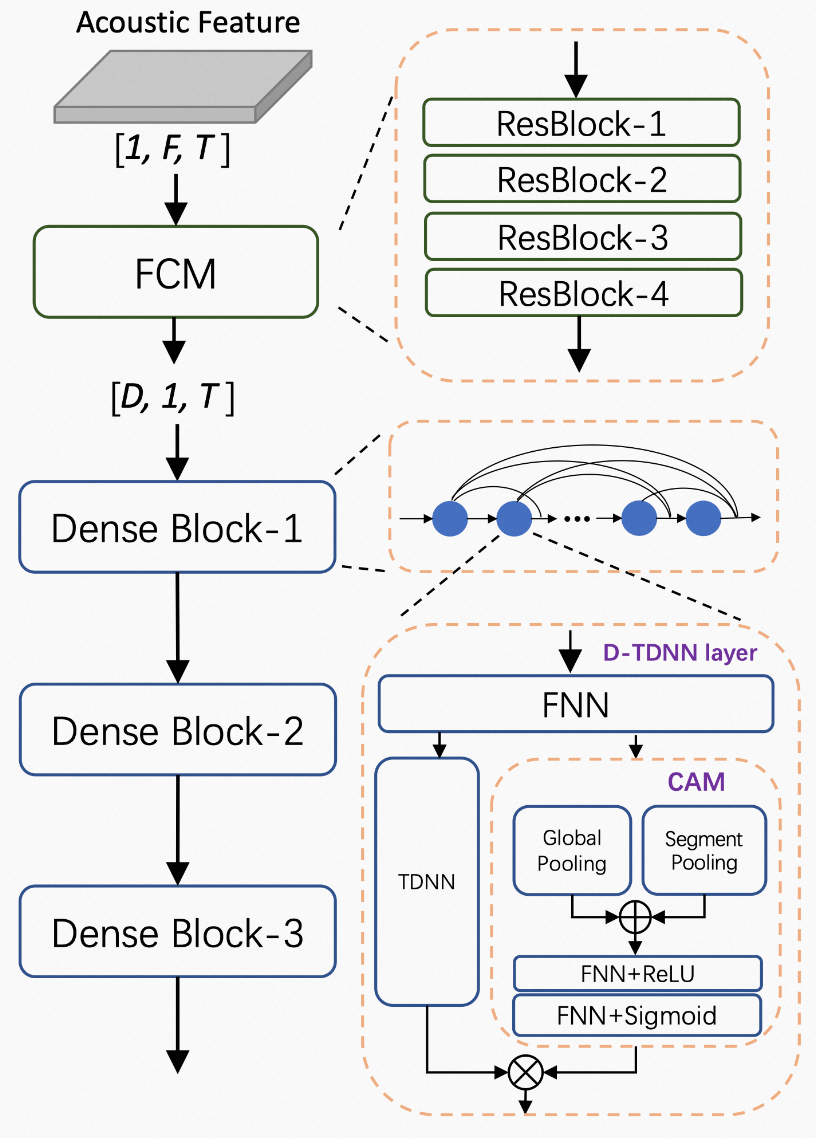
(CAM++模型结构图)
References:
[1]训练环境代码:
https://github.com/alibaba-damo-academy/3D-Speaker/tree/main/egs/sv-cam%2B%2B
[2]论文地址:https://arxiv.org/abs/2303.00332






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结