您现在的位置是:首页 >技术交流 >【C++技能树】原来比C方便这么多 --引用、内联函数、Auto、NULL与nullptr网站首页技术交流
【C++技能树】原来比C方便这么多 --引用、内联函数、Auto、NULL与nullptr

Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法......感兴趣就关注我吧!你定不会失望。
🌈个人主页:主页链接
🌈算法专栏:专栏链接
我会一直往里填充内容哒!
🌈LeetCode专栏:专栏链接
目前在刷初级算法的LeetBook 。若每日一题当中有力所能及的题目,也会当天做完发出
🌈代码仓库:Gitee链接
🌈点击关注=收获更多优质内容🌈
目录

1.引用:
上一篇章已经介绍了一部分的引用内容,这一个部分我们再来完善一下我们的知识架构.
1.1引用的特性(使用规则):
引用必须在声明部分给出定义,不能单单申明.需要指定对象
int &b;这样就是错的
1.2使用场景:
1.21参数为引用对象:
我们之前写swap时,想要交换这两个值往往需要取其指针参数.之后通过改变指针指向的内容来交换
例如这样
void swap(int *pa,int *pb)
{
int tmp=0;
tmp=*pa;
*pa=*pb;
*pb=tmp;
}但学会引用后我们可以这样写.
void swap(int &pa,int &pb)
{
int tmp=0;
tmp=pa;
pa=pb;
pb=tmp;
}相当于对传入的参数取了一个别名,实际的操作仍然是对实参进行操作.
这就是引用的场景之一:做形参,这样可以减少程序运行时数据的拷贝.因为在函数中,形参是对实参的临时拷贝.若这个实参数据量很大,则会对程序的运行造成较大的印象.
1.22返回值为引用对象:
先说结论,这样做也可以减少程序运行时数据的拷贝,但还有更方便的操作!
先说使用方法:
int &add(int &a,int &b)
{
static int c=a+b;
return c;
}
int main()
{
int a=1,b=2;
int c=add(a,b);
cout<<c;
}接下来,我们来分析下这个程序.
返回的值为引用,所以在主函数中c的是对add函数中的c的一个别名.
为什么这里要加入static呢?可不可以这样写?
int &add(int &a,int &b)
{
int c=a+b;
return c;
}
int main()
{
int a=1,b=2;
int c=add(a,b);
cout<<c;
}答案显然是不行的,在深刻理解函数栈帧之后就可以轻松的明白为什么这样写不可以.
这是函数调用时的栈帧模型.
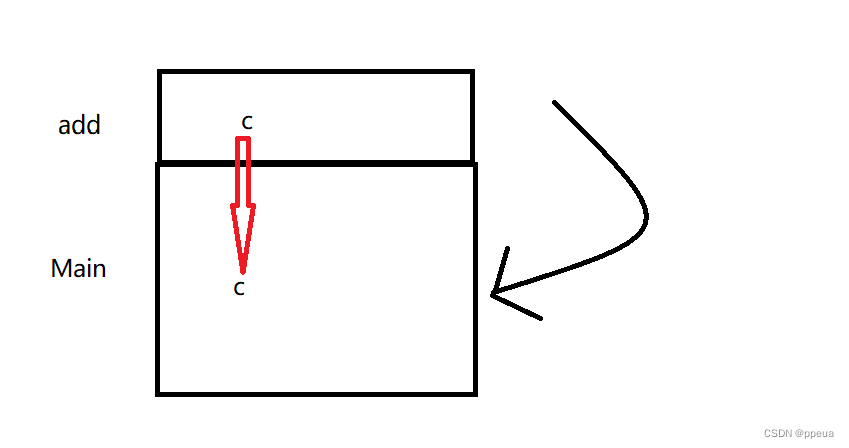
当函数调用结束.若该数据放在局部区域,则会被释放
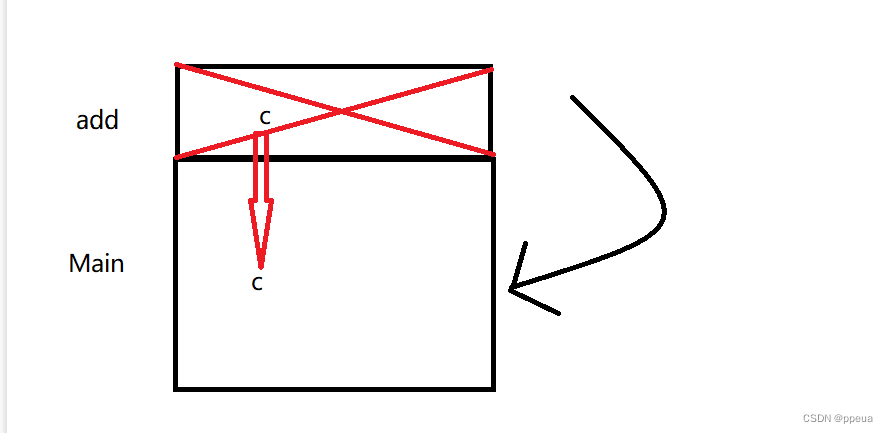
此时Main中的c仍然在对其进行引用,但其内容已经被释放.所以不可以这么写.
所以一定要创建一个全局变量来存储返回的值.
1.3引用的权限:
//权限平移
int a=10;
int &b=a;在这串代码中,b与引用对象a的权限都为int ,所以是正常的代码
//权限升级
const int c=10;
int &d=c;
const int &dc=c;
在这串代码中,引用对象为只读对象,可以读不可以写,而d想要写只读对象,显然出错了
//降级
int e=10;
const int &f=e;在这段代码中,引用对象为可读可写,而f只想读这个数据,显然是可以的
//权限降级
//临时变量创建临时空间的问题
double g=10;
int &h=g;
const int &i=g;在这段代码中,h为int类型 想去引用double的对象,任何不同类型间的相互转换都会先创建出一个临时变量
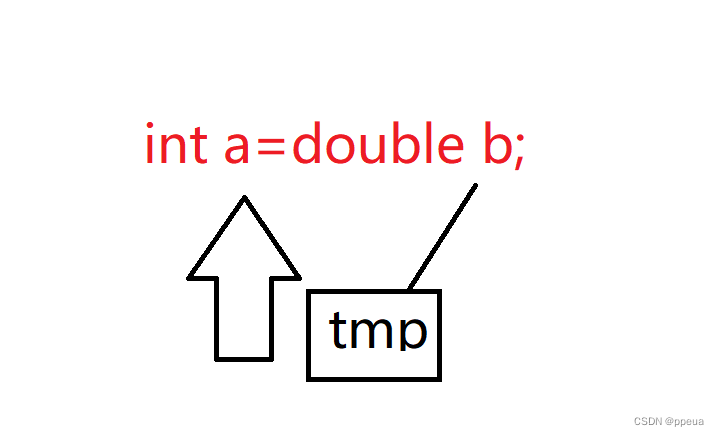
类似这样,所以a对b来说并没有权限去修改b里的值,因为即使是修改也只能修改到tmp里的值,所以要写成只读的引用方式.
1.4引用与指针的差别:
其实非常的简单,
引用是对这块区域取一个别名,也就像大熊猫和panda的区别,他们都代表同一种生物.
而指针就像是在动物园里有一个房子上面写着熊猫住址,这时候你可以通过这个房子去找到熊猫.但房子本身也是一种属性.
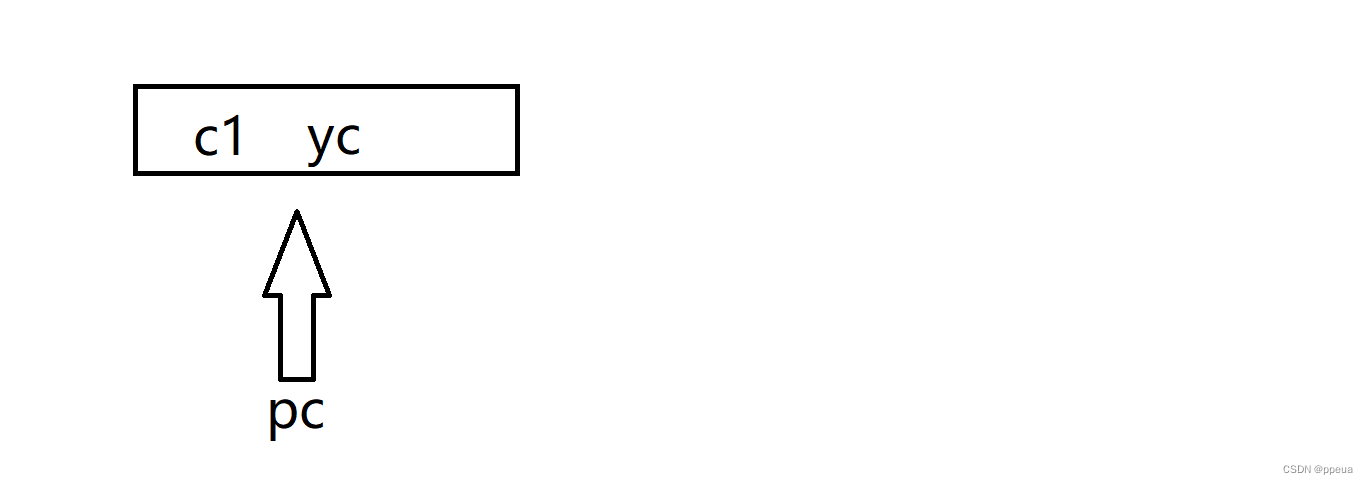
其yc与c1共用一块地址空间,而pc中存着他们的地址,且pc有一个自己的空间,
//引用和指针的区别
int c1=10;
int *pc=&c1;
int &yc=c1;
cout<<&yc<<endl;
cout<<&pc;输出结果为

他们概念上的差别:(凭理解记忆即可)
1. 引用概念上定义一个变量的别名,指针存储一个变量地址。
2. 引用在定义时必须初始化,指针没有要求
3. 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
4. 没有NULL引用,但有NULL指针
5. 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)
6. 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
7. 有多级指针,但是没有多级引用
8. 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
9. 引用比指针使用起来相对更安全
2.auto:
在c中要想声明一个函数,则只能通过写定义类型来声明.
但在c++中提供了一个auto关键字类型,它可以通过后文来推断这个变量是什么类型.在编译期间会被替换为对应的类型.
这样的代码是错误的,因为auto所有类型必须保持一致.
auto a=1,b=2,c=1.1;
因为其是通过后文来推断这个变量是什么类型的,所以用auto时一定要有后文,这样也同样是错的.
auto b;auto不能用来直接声明数组,也不能用来作为函数参数.
2.1 新式for循环:
在c中想要遍历一个数组只能通过以下方式
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)
array[i] *= 2;
for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)
cout << *p << endl;
}而在c++中可以直接使用auto来遍历.
void TestFor()
{
int array[] = { 1, 2, 3, 4, 5 };
for(auto& e : array)
e *= 2;
for(auto e : array)
cout << e << " ";
return 0;
}其中&表示引用,可以对array中的数组进行修改.
3.NULL与nullptr:
在c语言当中,所有指针都被定义为NULL,但是NULL的定义为0或者为(void*)0.
0的优先级更高,所以输出了以下的结果.
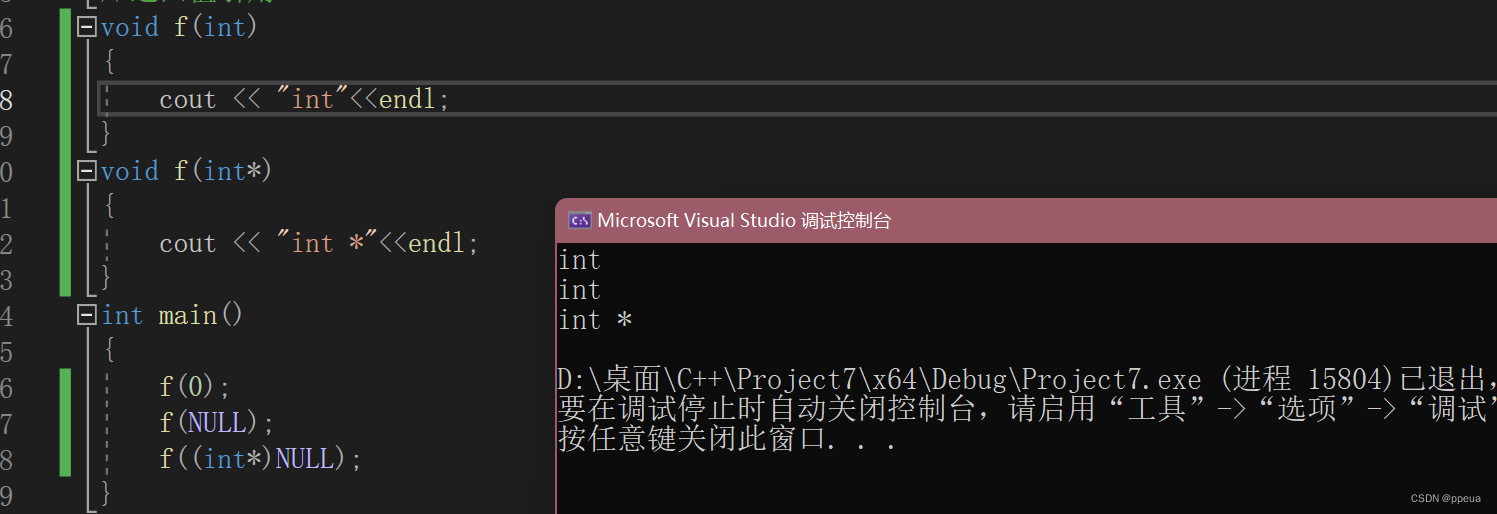
在c++中引入了nullptr的概念,其定义就为(void*)0
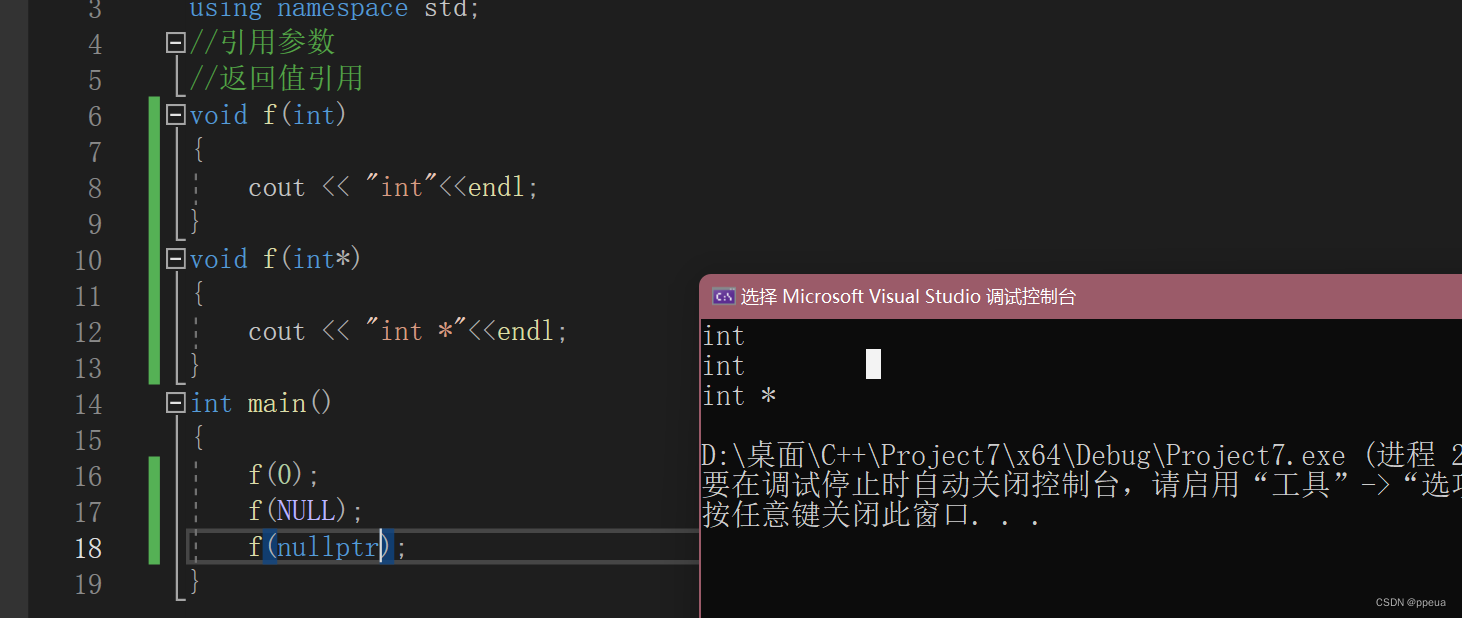
4.内联函数:
在讲内联函数之前,我们先来复习下写一个Max的宏函数怎么写.
#define MAX(a, b) ((a) > (b) ? (a) : (b))这段代码需要注意a,b之间的替换,因为define是在预编译阶段就进行了复制转换,可能会产生一些歧义.
在C++中,改进了这一个方法,引入了内联函数的机制.
在一个函数前加上inline即可
inline int max(int a, int b)
{
return a > b?a : b;
}
int main()
{
cout << max(3, 5);
}就能达到和宏同样的效果.其适用于短小且频繁调用的函数. 但是inline对编译器来说仅为建议,编译器会自己判断是否采用这种方式,若代码过长则会采用函数方式.
内联函数因为并不会产生地址,所以在头文件当中要声明与定义写在一起.
完结撒花:
🌈本篇博客的内容【原来比C方便这么多 --引用、内联函数、Auto、NULL与nullptr】已经结束。
🌈若对你有些许帮助,可以点赞、关注、评论支持下博主,你的支持将是我前进路上最大的动力。
🌈若以上内容有任何问题,欢迎在评论区指出。若对以上内容有任何不解,都可私信评论询问。
🌈诸君,山顶见!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结