您现在的位置是:首页 >其他 >BEV(0)---Transformer网站首页其他
BEV(0)---Transformer
1 Transformer
Transformer是一个Sequence to Sequence model,特别之处在于它大量用到了self-attention,替代了RNN,既考虑了Sequence的全局信息也解决了并行计算的问题。
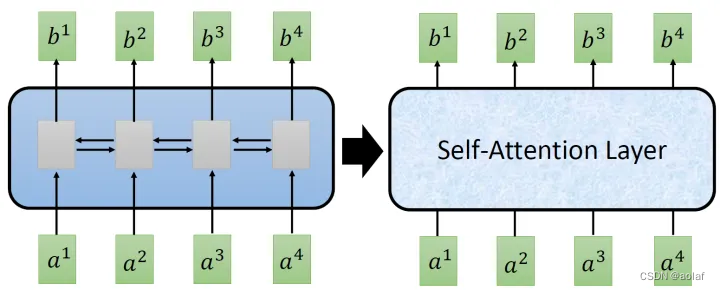
1.1 self-attention:
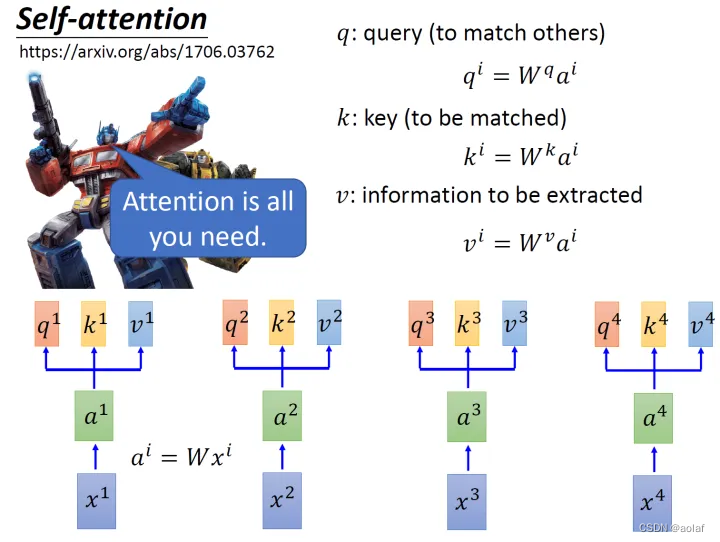
①. 输入x1 ~ x4为一个sequence,每一个input (vector)先乘上一个矩阵W得到embedding,即向量a1 ~ a4。将每个a1 ~ a4分别乘上3个不同的可学习参数矩阵,Wq, Wk,Wv,次时每个向量ai分别得到3个向量qi,ki,vi。
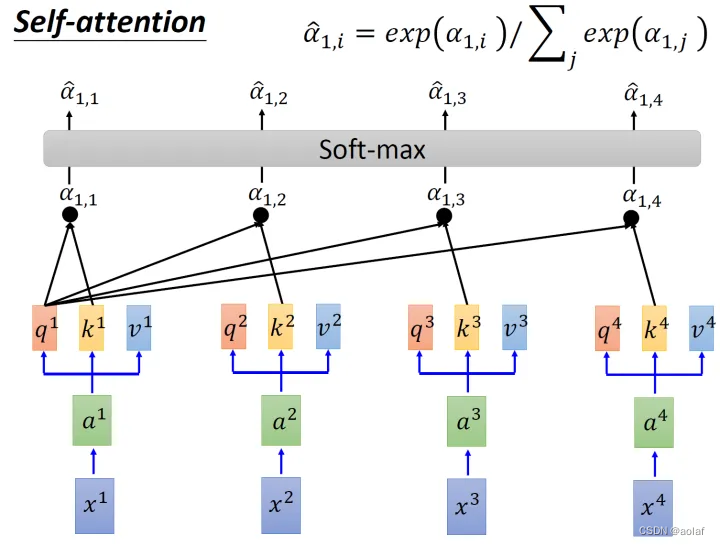
②. 拿每个query q 对每个key k做attention, 获得α:
d是q跟k的维度。因为q.k的数值会随着dimension的增大而增大,所以要除以dimension的开方,相当于归一化的效果。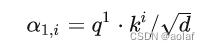
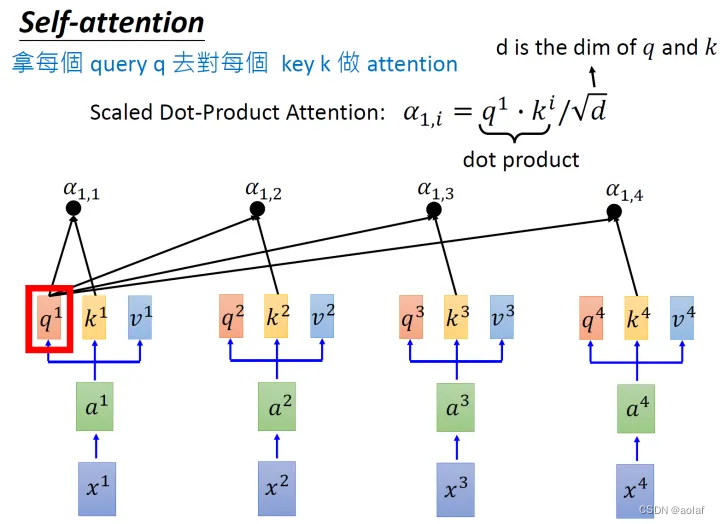
③. 将计算结果α1i分别进行softmax,同时与其对应的vi进行相乘,最终将他们结果相加,即可获得bi,此时bi中考虑到了整个sequence的信息。
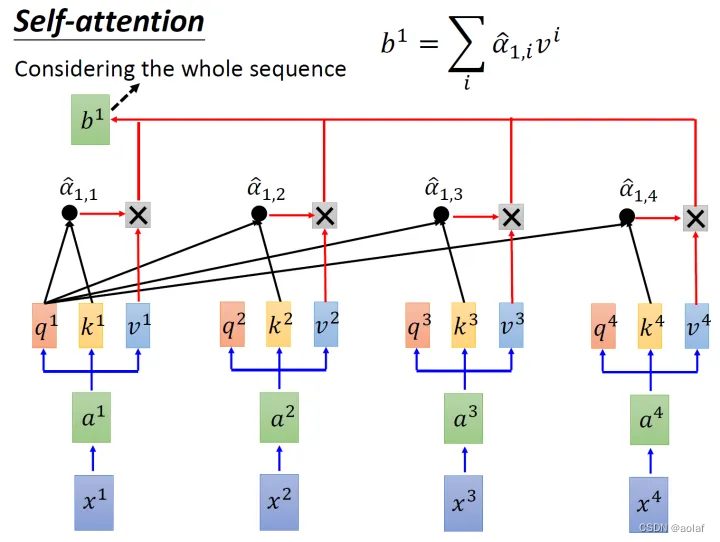
矩阵计算形式如下:
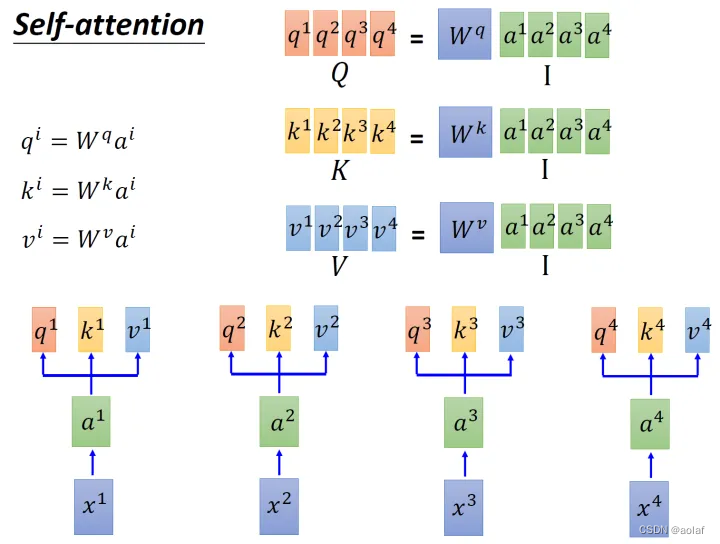
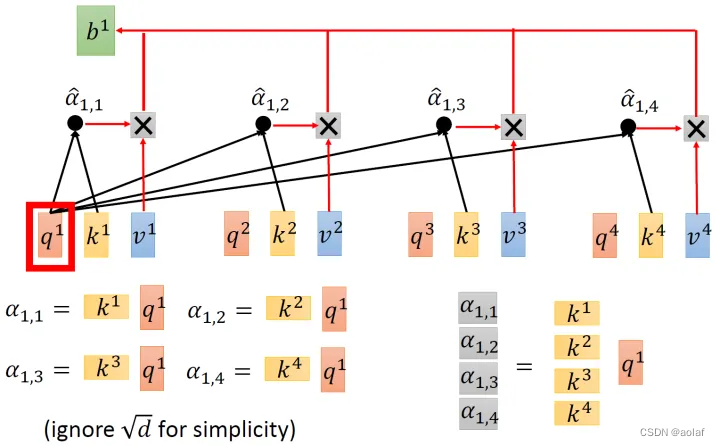

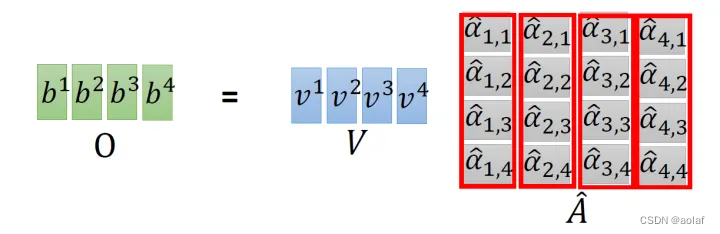
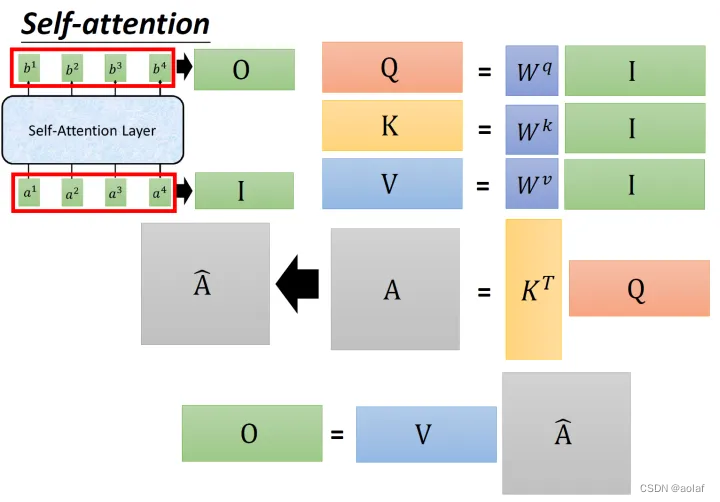
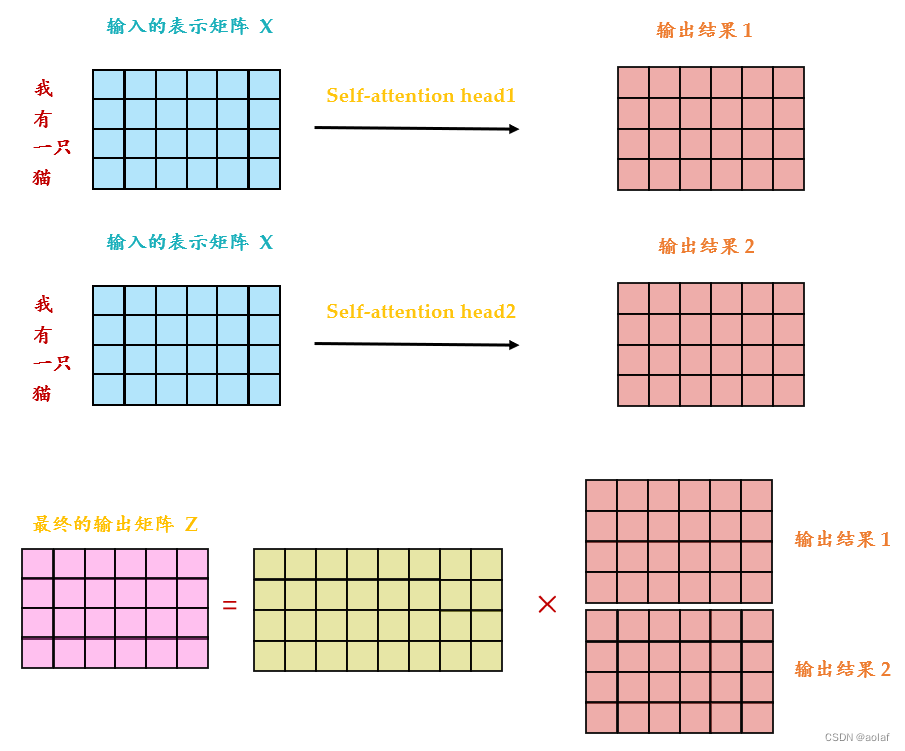
1.2 Multi-head self-attention:
还有一种multi-head的self-attention,以2个head的情况为例:
①. 由ai生成的qi进一步乘以2个转移矩阵变为qi1和qi2 ,同理由ai生成的ki 进一步乘以2个转移矩阵变为ki1和 ki2,由ai生成的vi进一步乘以2个转移矩阵变为vi1和vi2 。
②. 接下来qi1与ki1做attention后与vi1相乘,qi1与kj1做attention后与vj1相乘,两者相加获得bi1。同理得到bi2 。
③. 将bi1和bi2concat起来,再乘以一个转移矩阵调整维度,使之与bi1和bi2的维度一致。
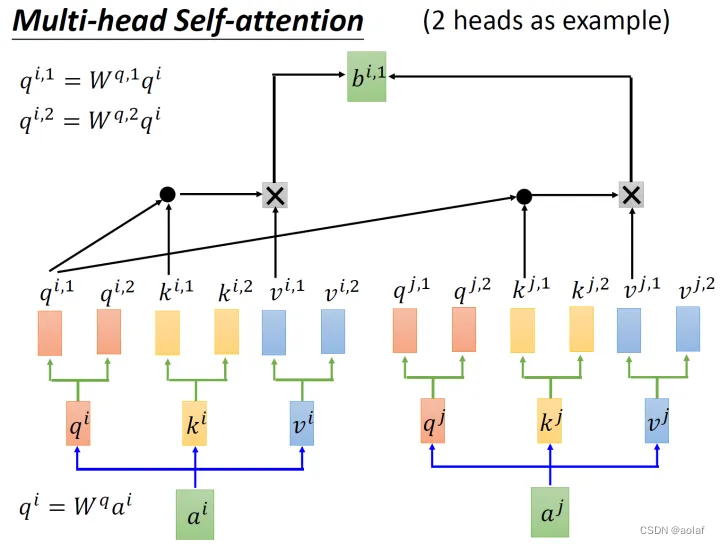
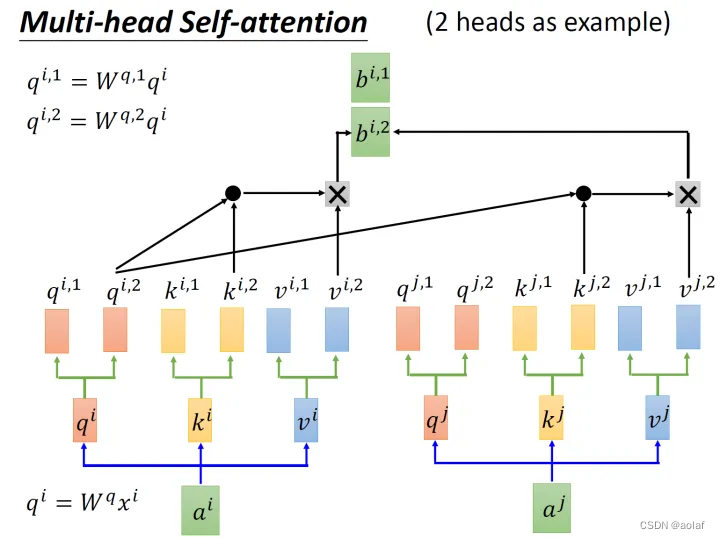
1.3 Positional Encoding:
1.3.1 Positional Encoding目的
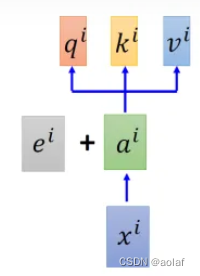
为了给self-attention添加位置信息,给每一个位置规定一个表示位置信息的向量 ei,让它与ai 加在一起之后作为新的ai参与后面的运算过程,但是这个向量ei是由人工设定的,而不是神经网络学习出来的。每一个位置都有一个不同的 ei。
1.3.2 Positional Encoding公式
PE:位置编码结果
pos: 输入向量在sequence中的位置
2i、2i+1:Positional Encoding的维度,i的取值范围[0, 1, 2…, dmodel/2)。
示例:pos=1时:
PE(1) = [sin(1/100000/512), cos(1/100000/512), sin(1/100002/512), cos(1/100002/512), …, sin(1/10000512/512), cos(1/10000512/512)]
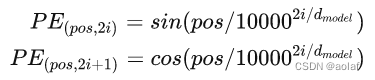
1.3.3 公式优势:
①. 保证了每个位置有唯一的positional encoding。
②. 使PE能够适应比训练集里面所有句子更长的句子,假设训练集里面最长的句子是有 20 个单词,突然来了一个长度为 21 的句子,则使用公式计算的方法可以计算出第 21 位的 Embedding。
③. 可以让模型容易地计算出相对位置,对于固定长度的间距 ,任意位置的PEpos+k 都可以被PEpos的线性函数表示
1.4 self-attention 与RNN、CNN的对比
1.4.1 self-attention与RNN
单向RNN只能获得前面输入的信息对于后面输入的信息是未知的,双向RNN改变了单向RNN的这一劣势,但仍然是串行运算,而self-attention不仅可以获得全局信息,同时可以并行运算。
1.4.2 self-attention与CNN
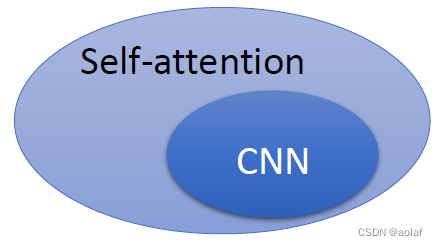
self-attention去处理一张图片时,使用的是某一个pixel产生的query与其余所有pixel产生的key进行相关度计算,这考虑到了全局信息,而CNN则只考虑到了卷积核内部的pixel之间的信息。所以CNN可以看作是一种简化版本的self-attention。
self-attention可以看作感受野自适应的CNN,因此其更flexible,因而需要的训练数据量也更多。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结