您现在的位置是:首页 >学无止境 >软件流程DevOps,版本管理工具Git,测试知识等网站首页学无止境
软件流程DevOps,版本管理工具Git,测试知识等
DevOps
1.软件危机背景:
落后的软件生产方式无法满足迅速增长的计算机软件需求,导致软件开发和维护过程中一系列的问题。于是诞生了软件工程的方法去解决软件危机。
2.软件工程的核心思想:
把其他行业和领域里的工程化经验借鉴过来,以系统性的、规范化的、可定量的工程化方法来开发和维护软件。包括相应的流程、工具、方法论等。
3.敏捷核心思想:
由于软件开发难以准确预测,工程化的思想和方法并不完全适用于软件开发,于是诞生了敏捷思想对软件工程进行纠偏。
敏捷软件开发宣言指出,个体和互动高于流程和工具,工作的软件高于详尽的文档,客户合作高于合同谈判,响应变化高于遵循计划。总之,右项有价值,但更偏于左项。
4.精益核心思想:
更关注流动效率而不是资源效率。不停地消除任何不增加价值的工作。
5.持续集成核心思想:
是一种软件开发实践,即团队成员经常集成他们的工作,每次集成通过自动化的构建(包括测试)来验证从而尽快检测出集成错误。例如一个软件开发6个月,然后集成测试2个月就一定不是持续集成。持续表示均匀、频繁;集成表示汇聚、测试。
6.持续交付核心思想:
是一种软件开发实践,令软件可以随时发布上线。为此需要持续地集成软件开发成果,构建可执行程序,并运行自动测试以发现问题,进而把可执行程序逐步推送到越来越像生产环境的各个测试环境中(并测试),以保证它最终可以在生产环境中运行。是持续集成的延伸(延伸到各类测试直到发布,中间就会牵扯到测试环境和生产环境如何管理、配置、部署,回滚,人工测还是自动化测等问题)。频繁程度小于持续集成。
7.DevOps起源和演化:
7.1.瀑布
是典型的预见性方法,严格遵循预先计划的需求、分析、设计、编码、测试的步骤顺序进行,上一阶段的输出作为下一阶段的输入。大体分为需求分析、设计、编码、测试、维护几个阶段。缺点是只有在项目生命周期后期才能看到结果,尤其是不适应用户需求变化。
7.2.敏捷
由于软件开发难以准确预测,工程化的思想和方法并不完全适用于软件开发,于是诞生了敏捷思想对软件工程进行纠偏。
敏捷是强调轻量的过程方法论,强调拥抱变化而不是与之对抗。与客户亲密合作取代合同约定。多数都采用迭代/增量开发的过程模型。
敏捷软件开发宣言指出,个体和互动高于流程和工具,工作的软件高于详尽的文档,客户合作高于合同谈判,响应变化高于遵循计划。总之,右项有价值,但更偏于左项。
7.3.DevOps
软件交付模式发生变化是诞生背景。Dev(开发)团队关注把新功能实现并上线,Ops(运维包括测试)团队关注上线后运行的稳定性,两个团队需要协作。devops促进软件开发、技术运营和质量保障等部门间的沟通和协作。特点有:
- “大系统小做”,服务/微服务架构师快速创新的技术基础
- 小批量/小粒度频繁的发布和部署,平滑集中部署的风险
- 运营驱动开发,小步快跑,唯快不破,运营中持续开发,用开发构筑运营竞争力
- 自营+合营的运作模式,变“卖产品”为“卖服务”
- 打破研发和运营团队之间的界限。“自己开发,自己运营”
- 传统交付方式交付整系统测试整系统。devops模式交付以微服务为主,微服务独立发布。支持微服务独立开发、验证与上线。
8.devops三步工作法:
快速流动(持续交付流水线等)、快速反馈、持续学习与实验。
9.devops与软件技术的演进是相互促进的:
- 开发过程从:瀑布--敏捷--devops,
- 应用架构从:单体--分层--微服务,
- 部署与打包从:物理机--虚拟机--容器,
- 应用基础设施从:数据中心--托管服务--云
10.软件交付的效能度量指标
- 部署频率(越高越好)
- 变更前置时间(越小越好)
- 服务恢复时间(越快越好)
- 变更失败率(越低越好)
11.DevOps的追求目标:
- 效率要兼顾需求吞吐量和需求响应时长
- 质量不是越高越好,而是要适合业务
- 质量由问题出现量和问题修复时长共同决定
- 兼顾短期和长期
12.总结DevOps和CI/CD的定义:
- DevOps:Development & Operations,开发和运维。DevOps更偏向于一种对于文化氛围的构建。DevOps也即是促使开发人员与运维人员之间相互协作的文化。
- CI:CONTINUOUS INTEGRATION,持续集成。指的是开发人员频繁的(一天多次的)将所有开发者的工作合并到主干上。这些新提交在最终合并到主线之前,都需要通过编译和自动化测试流进行验证,以保障所有的提交在合并主干之后的质量问题,对可能出现的一些问题进行预警。持续集成的核心在于确保新增的代码能够与原先代码正确的集成。
- CD:CONTINUOUS DELIVERY,持续交付。侧重点在于交付,其核心对象不在于代码,而在于可交付的产物。由于持续集成仅仅针对于新旧代码的集成过程执行了一定的测试,其变动到持续交付后还需要一些额外的流程。与持续集成相比较,持续交付添加了测试Test->模拟Staging->生产Production的流程,也就是为新增的代码添加了一个保证:确保新增的代码在生产环境中是可用的。
- 持续部署:(CONTINUOUS DEPLOYMENT)指的是通过自动化部署的手段将软件功能频繁的进行交付。与持续交付以及持续集成相比,持续部署强调了通过自动部署的手段,对新的软件功能进行集成。同持续交付相比持续集成的区别体现在对生产的自动化。从开发人员提交代码到编译、测试、部署的全流程不需要人工的干预,完全通过自动化的方式执行。这一策略加快了代码提交到功能上线的速度,保证新的功能能够第一时间部署到生产环境并被使用。
版本控制工具Git
1.什么是版本控制:
版本控制是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统,方便查看更改历史,备份以及恢复以前的版本,保证多人的协作不出问题。
2.版本控制的起源与历史:
- diff与patch是两个比较源码和补丁的工具,diff比较两个文件得出差异,patch是diff的反向操作,它通过一个文件和差异结果反推出另一个文件。
- diff的用法:diff -u left.c right.c
- patch的用法:patch left.c diff.txt 、 patch -R right.c diff.txt
- RCS是最早期的本地版本控制工具
- CVS&SVN是集中式版本控制工具
- Git是分布式版本控制工具
3.集中式CVS&SVN与分布式git的差异
- 集中式工具记录差异,Git是记录快照。
- 集中式只有脆弱的中央库,Git有强壮的分布库。
- SVN不适合跨地域的协同开发,Git不适合Word等二进制文档的版本控制(解决方法:版本库按照目录拆分)
4.linux下安装git
4.1.包管理器方式安装:
- sudo aptitude install git、sudo aptitude install git-doc git-svn git-email gitk(Ubuntu、Debian的)
- yum install git、yum install git-svn git-email gitk (RHEL、Fedora、CentOS 等)
4.2.从源代码安装:
- 访问Git的官方网站: http://git-scm.com/ 。下载Git源码包,例如:git-2.19.0.tar.gz。
- 解压后进入目录,tar -jxvf git-2.19.0.tar.bz2、cd git-2.19.0、
- 安装方法写在INSTALL文件当中,参照其中的指示完成安装。下面的命令将Git安装在 /usr/local/bin 中 make prefix=/usr/local all、sudo make prefix=/usr/local install
- 安装Git文档(可选)make prefix=/usr/local doc info、sudo make prefix=/usr/local install-doc install-html install-info
自动补齐(bash-completion软件包提供命令补齐功能)安装方法:
- 将Git源码包中的命令补齐脚本复制到bash-completion对应的目录中:cp contrib/completion/git-completion.bash /etc/bash_completion.d/
- 重新加载自动补齐脚本,使之在当前shell中生效: . /etc/bash_completion
- 为了能够在终端开启时自动加载bash_completion脚本,需要在本地配置文件 ~/.bash_profile 或全局文件/etc/bashrc 文件中添加下面的内容:
if [ -f /etc/bash_completion ]; then . /etc/bash_completion fi
5.Windows下安装git
- 到 https://git-scm.com/download/win 下载 Windows 安装包,例如: Git-2.19.0-64-bit.exe
- 执行exe开始图形化安装,在安装过程中会询问是否修改环境变量。建议选择“Use Git Bash Only”,即只在 MinGW 提供的shell环境中使用Git,不修改 PATH 环境变量,避免 Git 自带的工具与 Windows 下已有的产生冲突。
- 安装完成后,我们可以在 Windows 任意目录下,右键单击选中 "Git Bash" 启动 Git Bash。git version 查看安装的 git 版本信息
- Windows下除了git,还有一个就是基于msysGit的图形界面工具——TortoiseGit,人称小乌龟。访问网站 http://code.google.com/p/tortoisegit/ ,下载安装包,然后根据提示完成安装。
6.总结git基本配置
Git有三种配置,分别以文件的形式存放在三个不同的地方。可以在命令行中使用git config工具查看这些变量:
- 系统配置(对所有用户都适用)存放在git的安装目录下:%Git%/etc/gitconfig;若使用 git config 时用 --system 选项,读写的就是这个文件:git config --system core.autocrlf
- 用户配置(只适用于该用户)存放在用户目录下。例如linux存放在:~/.gitconfig;若使用 git config 时用 --global 选项,读写的就是这个文件:git config --global user.name
- 仓库配置(只对当前项目有效)当前仓库的配置文件(也就是工作目录中的 .git/config 文件);若使用git config 时用 --local 选项,读写的就是这个文件:git config --local remote.origin.url
6.1.配置个人身份
- git config --global user.name “Zhang San” ----个人名称
- git config --global user.email zhangsan123@huawei.com ----个人邮箱
6.2.文本换行符配置
假如你正在和其他人合作,他们在Windows上编程,而你却在其他系统上,在这些情况下,你可能会遇到行尾 结束符问题。 这是因为Windows使用回车和换行两个字符来结束一行,而Mac和Linux只使用换行一个字符。 虽然这是小问题,但它会极大地扰乱跨平台协作
- git config --global core.autocrlf true 可以在你提交时自动地把行结束符CRLF转换成LF,而在签出代码时把LF转换成CRLF
- git config --global core.autocrlf input 把core.autocrlf设置成input来告诉Git在提交时把CRLF转换成LF,签出时不转换。这样会在Windows系统上的签出文件中保留CRLF,会在Mac和Linux系统上,包括仓库中保留LF
- git config --global core.autocrlf false 假如正在开发仅运行在Windows上的项目,可以设置false取消此功能
6.3文本编码支持
# 中文编码支持
- git config --global gui.encoding utf-8
- git config --global i18n.commitencoding utf-8 用来让git commit log存储时,采用的编码,默认UTF-8
- git config --global i18n.logoutputencoding utf-8 查看git log时,显示采用的编码,建议设置为UTF-8.
# 显示路径中的中文:
- git config --global core.quotepath false
6.4.与服务器的认证配置
http / https 协议认证:
- 设置口令缓存git config --global credential.helper store
- 添加 HTTPS 证书信任git config http.sslverify false
ssh 协议认证:(SSH协议是一种非常常用的Git仓库访问协议,使用公钥认证、无需输入密码,加密传输,操作便利又保证安全性)
- 生成公钥:ssh-keygen -t rsa –C zhangsan1123@huawei.com
- 添加公钥到代码平台:登录代码平台、进入“Profile Settings”、点击左侧栏的“SSH Keys”、点击“Add SSH Key”,将刚生成的公钥文件的内容,复制到“Public Key”栏,保存即可
7.总结git命令
7.1.Git版本控制下有三种工程区域&文件状态
Git版本控制下的工程区域只有三种:
- 版本库( Repository ):在工作区中有一个隐藏目录.git,这个文件夹就是Git的版本库,里面存放了Git用来管理该工程的所有版本数据,也可以叫本地仓库
- 工作区( Working Directory ):日常工作的代码文件或者文档所在的文件夹
- 暂存区( stage ):一般存放在工程根目录 .git/index文件中,所以我们也可以把暂存区叫作索引(index)
Git版本控制下的文件状态只有三种:
- 已提交( committed ) 该文件已经被安全地保存在本地数据库中了
- 已修改(modified) 修改了某个文件,但还没有提交保存
- 已暂存(staged)把已修改的文件放在下次提交时要保存的清单中
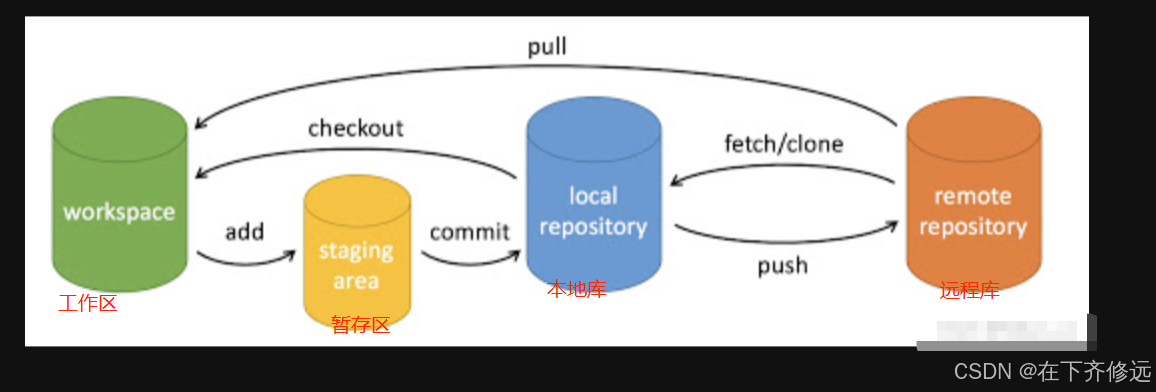
基本上库流程:
- pull(远端库更新到本地) --每次上库之前一定要先更新,避免上库后出现冲突
- add(新增文件添加到暂存区,只有新增的文件需要)
- commit(暂存区的文件改动提交到本地库)
- push(本地库推送到远端分支)
- merge(远端分支合并到远端master)
7.2.工程准备命令
git init 项目名称:用于在本地目录下新建git项目仓库。执行git init后,当前目录下自动生成一个名为.git的目录,这代表当前项目所在目录已纳入Git管理。.git目录下存放着本项目的Git版本库,在此强烈不建议初学者改动.git目录下的文件内容。Git仓库下的.git目录默认是不可见的,有一定程度上是出于防止用户误操作考虑。
但我们日常工作中几乎全部都是基于已有的git工程进行本地开发,不需要我们做新建git仓库,都是从远端服务器上克隆到本地,所以直接git clone
git clone用于克隆远端工程到本地磁盘。如果想从远端服务器获取某个工程,那么:
- 确定自己Git账号拥有访问、下载该工程的权限
- 获取该工程的Git仓库URL
- 本地命令行执行 git clone [URL]或 git lfs clone [URL] (如果你所在的项目git服务器已支持git-lfs,对二进制文件进行了区别管理,那么克隆工程的时候务必使用git lfs clone。否则克隆操作无法下载到工程中的二进制文件,工程内容不完整。)
7.2.3.新增/删除/移动文件到暂存区
- 在提交你修改的文件之前,需要git add把文件添加到暂存区。如果该文件是新创建,尚未被git跟踪的,需要先执行 git add 将该文件添加到暂存区,再执行提交。(如果文件已经被git追踪,即曾经提交过的 。在早期版本的git中,需要git add再提交;在较新版本的git中,不需要git add即可提交。)
- git rm 将指定文件彻底从当前分支的缓存区删除,因此它从当前分支的下一个提交快照中被删除。如果一个文件被git rm后进行了提交,那么它将脱离git跟踪,这个文件在之后的节点中不再受git工程的管理。执行git rm后,该文件会在缓存区消失。你也可以直接从硬盘上删除文件,然后对该文件执行 git commit,git会自动将删除的文件从索引中移除,效果一样。
- git mv 命令用于移动文件,也可以用于重命名文件。举例移动目录:git mv codehunter_nginx.conf config 举例重命名:git mv config/codehunter_nginx.conf config/new_nginx.conf
7.2.4.查看工作区、提交更改的文件、查看日志
- git diff用于比较项目中任意两个版本(分支)的差异,也可以用来比较当前的索引和上次提交间的差异。git diff aaa bbb(两个节点或分支) git diff --cached (当前的索引和上次提交间的差异) git diff aaa bbb --name-status(只看文件列表)
- git status 命令用于显示工作目录和暂存区的状态。使用此命令能看到修改的git文件是否已被暂存, 新增的文件是否纳入了git版本库的管理。
- git commit 主要是将暂存区里的文件改动提交到本地的版本库。在此强调,提交这个动作是本地动作,是往本地的版本库中记录改动,不影响远端服务器。git commit一般需要附带提交描述信息,所以常见用法是:git commit file_name –m “commit message”。如果要一次性提交所有在暂存区改动的文件到版本库,可以执行: git commit –am “commit message”
- git log用于查看提交历史。默认加其他参数的话,git log 会按提交时间由近到远列出所有的历史提交日志。每个日志基本包含提交节点、作者信息、提交时间、提交说明等。git log配合不同参数具有相当灵活强大的展示功能,常见的如—name-status/-p/--pretty/--graph等等,自行了解。
7.2.5.推送至远端库
在使用git commit命令将自己的修改从暂存区提交到本地版本库后,可以使用git push将本地版本库的分支推送到远程服务器上对应的分支。成功推动远端仓库后,其他开发人员可以获取到你新提交的内容。
常用的推送命令格式: git push origin branch_name
branch_name决定了你的本地分支推送成功后,在远端服务器上的分支名,其他人据此可以获取该分支上的改动内容。你的本地分支名可以与推送到远端的分支名不同 : git push origin branch_name:new_branch_name
7.2.6.分支管理
查看分支
- git branch:查看本地工程的所有git分支名称。(显示结果前面带*的绿色高亮的表示当前工作区所在分支)
- git branch –r:查看远端服务器上拥有哪些分支,返回的分支名带origin前缀,表示在远端;
- git branch –a:查看远端服务器和本地工程所有的分支。
创建分支、删除分支、更新分支:
- git branch new_branch_name:新建分支,不会切换到新分支
- git checkout –b branch_name:新建分支,并自动切换到新分支
- git branch –d branch_name:删除本地分支
- git branch –D branch_name:删除本地分支,强制删除
- git branch -d -r branch_name:删除服务器上的远程分支。其中branch_name为本地分支名。删除后,还要推送到服务器上才行,即git push origin : branch_name
- git checkout branch_name :git checkout除了创建分支,还用来切换分支,当然比较官方的叫法是“检出”。有时候,当前分支工作区存在修改而未提交的文件,与目的分支上的内容冲突,会导致checkout切换失败,这时候,可以使用git checkout –f进行强制切换。git checkout对象可以是分支,也可以是某个提交节点或者节点下的某个文件。
- git pull origin remote_branch:local_branch:从远端服务器中获取某个分支的更新,再与本地指定的分支进行自动合并。 (相当于 git fetch +git merge)。如果远程指定的分支与本地指定的分支相同,则可直接执行git pull origin remote_branch
- git fetch origin remote_branch:local_branch:从远端服务器中获取某个分支的更新到本地仓库。与git pull的区别是,并不会进行合并。如果远程指定的分支与本地指定的分支相同,则可直接执行git fetch origin remote_branch
- git merge branch_name:用于从指定的分支(节点)合并到当前分支的操作。分支合并,实际上是分支间差异提交节点的合并。
- git rebase branch_name:合并目标分支内容到当前分支。如果你要将其他分支的提交节点合并到当前分支,那么git rebase和git merge都可以达到目的。
- git rebase、git merge背后的实现机制和对合并后节点造成的影响有很大差异,有各自的风险存在,暂不在本课中展开。
7.2.7.撤销操作:
- git reset commit_id:撤销当前工作区中的某些git add/commit操作,可将工作区内容回退到历史提交节点。git reset –-mixed/hard/soft的三种参数模式涉及概念较多,需要去了解。
- git checkout .:用于回退本地所有修改而未提交的文件内容。这是条有风险的命令,因为它会取消本地工作区的修改(相对于暂存区),用暂存区的所有文件直接覆盖本地文件,达到回退内容的目的。但它不给用户任何确认机会,所以谨慎使用。
- git checkout –filename:仅仅想回退某个文件的未提交改动
- git checkout commit_id:想将工具区回退(检出)到某个提交版本
关于测试
1、测试的基础理论
1.1、为什么要做测试:
缺陷不可避免,软件未正确执行可能会导致很多问题,所以需要通过测试控制风险
1.2、什么是软件测试:
描述一种用来促进鉴定软件的正确性、完整性、安全性和质量的过程。是一个包含计划、准备和测量活动的过程。目的是确认被测系统的特性,并指出需求和实现之间的差异。
1.3、测试的目的:
发现缺陷、质量评估、预防缺陷、分享信息、消除风险、建立信心等
1.4、不同的测试阶段,测试目的有所不同:
- 单元、集成、系统测试:目的是尽可能发现失效,从而识别和修正尽可能多的缺陷
- 验收测试:目的是确认系统是否按预期工作,建立满足了需求的信心
- 有些情况下,目的是对软件质量进行评估,从而为利益相关人提供给定时间点发布系统版本可能存在的风险的信息。
- 回归测试:通常是为了验证开发过程中的软件变更是否引入了新缺陷
1.5、测试的依据是:
不仅仅依据产品业务的需求,还要看合同要求、法律标准、行业标准等
1.6、测试的开始与停止时间:
- 什么时候开始测试:越早越好。越晚修复bug,付出的代价就越大。
- 什么时候停止测试:要从多个维度评估,例如达到了必要信心级别风险可接受时、发现缺陷的代价高于缺陷本身带来的代价时、达到测试完成标准时
1.7、谁来测试:测试是研发团队所有人的职责,不只是测试人员的事情。
1.8、基本的测试过程:计划、控制、分析和设计、执行和评估、结束
1.9、测试的七项基本原则:
- 穷尽测试不可能:测试所有内容不可行,应使用风险分析和优先级来聚焦测试投入,本质上就是抽样检验。
- 缺陷集群性:二八法则无处不在。大部分缺陷集中于少部分模块
- 杀虫剂悖论:同一个用例反复测试,最后将不能发现新缺陷。所以用例需求经常性的评审修改,不断增加新的不同角度的用例。
- 测试指出缺陷的存在:测试能指出存在缺陷,但不能证明没有缺陷。测试降低软件有缺陷的可能,即使没发现缺陷也不能证明软件完全正确。
- absence-of-errors谬误:系统的发布不取决于是否有缺陷,而是取决于是否满足客户需求和期望。如果不满足用户需求,找再多bug修订也没用。
- 测试要尽早介入:要尽早在软件开发中启动测试活动,聚焦于测试目标,开发人员也应提前测试自己的代码
- 测试活动依赖于测试context:南橘北枳。测试的目标定义、策略指定、技术选择等都要充分考虑上下文(客户需求,技术难度,项目时间,人员能力,资源状态等)。测试人员要主动快速响应上下文的变化。没有最佳方案,不能一成不变,要随时改进。尤其要重视客户的反馈(现网问题、需求、抱怨和赞誉等)
1.10、测试人员应该具备的:
- 测试知识、领域知识、IT知识、批判性思维、自我教育等
- 要有好奇心,就是要验证一些奇怪场景。要有主观能动性。
- 开展测试活动必备:对常见错误进行判断的经验,敢于提出问题的勇气,探究根底的精神,多维度思考的能力,挑剔的眼睛,专业的怀疑态度。
- 测试活动需要良好沟通。
1.11、一些测试名词:错误(error)--缺陷(bug/defect/fault)--失效(failures)
1.12、软件测试的分类:
- 按是否运行程序:静态测试(评审和静态分析),动态测试(运行程序,检查结果。)其中动态分为白盒与黑盒。
- 按阶段划分:单元测试(测单个模块),集成测试(测多个模块的集成交互),系统测试(测整个系统),验收测试(以是否满足客户需求为目标)
- 按用例设计是否设计代码划分:黑盒测试(功能、性能、可靠性、易用性、可服务性、维护性等),白盒测试
- 按针对的质量目标划分:功能、适用性、性能、安全、可靠性
- 其他分类:资料、自动化、回归(代码修改后重新测试确认没有新错误引入)、精准测试(时间精力有限情况下,对于大量用例如何挑选出最合适的部分进行测试,最简单的依据是开发修改了哪些就测哪些)
2、测试设计
2.1、为什么要做测试设计:
- 保证测试质量:理清测试思路、通过用例评审避免遗漏、通过执行用例评估产品质量与需求满足度
- 提高测试效率:提前规划资源、准备人力、有效执行测试活动
- 是测试执行的依据:依据用例执行、证明用例确实执行了、记录问题支撑问题复现
- 跟进测试进度:用用例衡量测试进度
- 留下测试资产:给后续版本继承
2.2、测试设计目的:明确测试活动的范围和目标,明确测试方法,指导测试执行过程开展,规范测试行为
2.3、测试覆盖目的:基于测试的风险分析,定义被测对象覆盖的深度,保障高风险的规格能够更充分的覆盖,满足交付质量要求
2.4、测试设计交付件(测试方案和测试用例)是测试的核心资产,通过测试设计实现系统测试过程可定义、可重复、可改进。建议:借助思维导图来梳理需求,完成测试因子的分析与提取
2.5、测试方案的目的:指导用例设计、传递测试设计思路
2.6、测试方案内容:
- 被测对象分析:需求价值、应用场景、组网、被测边界&接口、约束、继承性
- 测试风险分析:分析主要风险点,识别测试重点关注点
- 测试类型分析:功能测试、性能测试、安全测试、可靠性测试……
- 测试技术分析:分析测试难点,考虑应对方案
- 自动化分析:考虑自动化策略、AW设计
- 测试环境与物料需求
- 功能点划分
2.7、三种测试设计方法:
- 处理周期:(亿图图示)画流程图,圆角矩形开始结束,直角矩形操作步骤,菱形是判定点。然后可覆盖不同的路径深度来设计用例
- 状态转换:(亿图图示)不同状态之间的转换,不同的转换次数0-switch、1-switch等
- 数据组合:(因子组合方法)
2.8、因子组合技术
选择哪种组合技术依赖于被测对象的风险(对于开发者测试,可以同时考虑实现成本和执行成本)。因子取值:等价类划分、分析边界值
- AC:将每个测试因子所有取值进行全组合。AC是覆盖最全面的覆盖方式。 缺点是对于复杂的对象,组合数量太庞大。组合个数=每个因子取值个数的乘积
- BC:以一个因子组合为基准,每次只改变一个因子的取值,直到所有取值都覆盖到。组合个数 = 所有因子取值个数 - 因子个数 + 1
- EC:每一个测试因子的每一个取值在所有测试因子组合中至少出现一次。组合个数 = 所有因子中取值最多的那个因子的取值个数
- N-Wise组合:每N个测试因子的取值进行AC全组合。其中用的最多的是pair-Wise(2-wise)组合。组合个数 = 最多因子取值个数 × 次多因子取值个数
- 举例:假如三个因子,分别有2/3/4种取值。那么AC组合有有 2*3*4种。BC组合有2+3+4-(3-1)种。EC组合有max(2,3,4)种,pair-wise有4*3种
2.9、做好测试设计的几个关键因素:
需求分析时更充分的理解需求、测试设计时系统化的思考、输出用例时科学的测试覆盖、充分利用测试因子库经验库等组织积累的经验、最后进行评审可以更容易发现问题
2.10、常用的测试设计工具:PICT、iCase、MTG等
3、测试流程
参看前面DevOps的章节
4、测试管理
4.1、看业界:类互联网速度为王,而类CT质量要求更高。所以类CT公司的测试人员占比远高于类互联网公司。类互联网的开发人员承担了更多的测试任务。
4.2、测试角色:
- 测试经理TM:通常指产品测试经理,负责一个产品的测试工作。规模小时测试经理就是测试组长,规模大时测试经理下有多名测试组长
- 测试组长owner:指定本测试小组活动计划并监控执行,组织开展测试活动
- 测试系统工程师TSE:在产品级测试技术方面引导测试组开展测试活动。需求分析、测试设计、策略制定等
- 测试工程师TE:测试设计、测试执行、结果分析报告等。
4.3、测试计划:是测试工作的主线,需要动态调整,受测试策略、范围、目标、风险、资源、可测试性等条件的制约。
4.4、测试估计:对象包括用例规模、工作量、进度、资源
4.5、常用的测试度量项:
- 测试执行阶段:用例执行率、通过率、缺陷密度、缺陷趋势、用例执行效率、回归不通过率、缺陷修改引入率、工作量分布(每个特性的投入比例、每个阶段的投入比例)
- 测试退出的评估:测试特性覆盖率、测试用例覆盖率、测试用例通过率、DI值、问题单解决率
4.6、测试报告:
- 把测试的过程和结果写成文档,对问题与缺陷进行分析,为纠正质量问题提供依据,同时为软件验收和交付打下基础。
- 可以是多个层次级别的,系统的、集成的、单元的等。
- 首先要给出明确结论和关键风险,关键风险要区分风险和限制,场景化描述影响
- 遗留问题:要场景量化数据,说清影响措施
4.7、风险:
就是目标与实际的差距,没有目标就没有差距。
- 风险=失效概率*失效影响
- 其中失效概率=使用频率*缺陷概率
穷尽测试是不可能的,所以测试就是基于风险的测试。
风险管理:物料、人员能力、测试周期、工程技术等。
4.8、缺陷管理:
- 测试的目的之一就是发现缺陷。需要从缺陷的发现、提交、分类、修改、解决方案验证等过程跟踪。要有一套完整的缺陷管理过程和规则。
- 缺陷管理作用:通过缺陷管理,控制测试进度,调整测试策略,促进质量改进。通过缺陷管理的各类数据,评价开发测试的工作质量,评价员工绩效,预测将来缺陷的趋势。
- 缺陷管理原则:问题单要遵循完整性、一致性、时效性、有效性、
5、自动化测试
5.1、自动化价值:
- 提升测试深度--完成手工不可能完成的任务。
- 提升测试效率--执行速度比人快还能持续执行不休息。
- 凸显工程师态度--重复的事情和讨厌的事情都自动化
5.2、自动化的误区:完全代替手工、发现大量新缺陷、用好自动化工具就可以做好自动化测试、初期对自动化报以高期望、自动化覆盖率越高越好、自动化用例只是对手工用例的翻译。----以上都是错误观点。
5.3、手工和自动化怎么选择
- 手工更适合:探索性、一次性、依赖智力判断的。自动化更适合:机械重复的、大量快速的、基于规则穷尽的
- 自动化:第一代简单的捕捉回放(QTP、Winrunner、QRun等),第二代以脚本为核心(TCL),第三代以AW为核心,第四代进行测试建模
5.4、自动化技术的发展过程是用例脚本的“可维护性、可读性、可重用性”不断提升、脚本编写维护成本不断下降的过程;核心思想和软件开发思想的演变类似:分层、封装、结构化、以及面向对象。
5.5、自动化分类:
按开发阶段:单元、接口、集成
按测试活动:功能、DFX、场景
按OM类型:WEB、APP、CLI、MIB
按设计方法:录制回放、面向对象、模型生成
按架构思想:线性测试、模块驱动、数据驱动、关键字驱动
5.6、自动化测试元素:
- AW(常用的通用测试动作的封装)、
- 脚本(一个脚本对应一个用例)、
- 测试套(一组按场景组织到一起的用例集合)、
- 测试框架(定义组织整个自动化的系统)、
- 执行引擎(自动化框架的一部分,驱动用例执行并输出报告)
5.7、自动化调度方式:
- 自动化流水线(反馈快、轻量、人工干预少、适用测试前移和CICD)DevOps模式和CICD这一套用的就是流水线。
- 自动化工厂(覆盖全面、时间长人工分析量大、适用版本过点全量验证)。
5.8、脚本工程的双解耦理念:测试数据和脚本解耦(AW封装),测试脚本和环境解耦(环境标准化)
5.9、脚本工程设计目标:使一套脚本工程,可自动适应不同的环境实例、测试数据、软件版本等;
5.10、脚本框架组成:
- 测试套:是一个集合,包括测试逻辑组网、测试数据, pytest中对应conftest.py;
- 测试数据:测试的输入数据,包括环境数据与用例样本点数据;
- 逻辑组网: 是物理组网的描述,里面有环境数据;
- 测试脚本:根据测试用例实现的自动化代码文件;
5.11、测试套由数据(环境数据+测试公共数据)和操作(公共配置+清除公共配置)两部分组成:
- 环境数据:从逻辑组网中获取,使于将被测对象的数据传递到测试脚本中
- 测试公共数据:如测试规格、硬件规格等,被测试脚本反复调用的数据
- 公共配置: 脚本中进行的公共操作,建议放到测试套中
- 清除公共配置:所有脚本执行结束之后,对公共配置进行删除
5.12、测试脚本组成:
- 测试数据:对应手工用例中的样本点数据
- 执行前准备:对应用例中的预置条件,脚本框架中对应方法:setup_class
- 测试执行: 对应TMSS上的测试执行字段,脚本框架中对应方法:test_procedure
- 清除配置:对过程中产生的配置进行清除,脚本框架中对应方法:teardown_class
5.13、脚本的执行顺序:
- 测试套: setup ---->
- 脚本1的setup_class、test_procedure 、 teardown_class---->
- 脚本2的setup_class、test_procedure、 teardown_class----> ......---->
- 脚本n的setup_class、test_procedure、 teardown_class
- 脚本套: teardown
5.14、自动化代码上库:代码配置管理包含变更管理和版本控制,工具Git






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结