您现在的位置是:首页 >技术交流 >设计模式-原型模式网站首页技术交流
设计模式-原型模式
原型模式
什么是原型模式
如果对象的创建成本比较大,而同一个类的不同对象之间差别不大(大部分字段都相同),在这种情况下,我们可以利用对已有对象(原型)进行复制(或者叫拷贝)的方式来创建新对象,以达到节省创建时间的目的。这种基于原型来创建对象的方式就叫作原型设计模式(Prototype Design Pattern),简称原型模式。
为什么要用原型模式
实际上,创建对象包含的申请内存、给成员变量赋值这一过程,本身并不会花费太多时间,或者说对于大部分业务系统来说,这点时间完全是可以忽略的。应用一个复杂的模式,只得到一点点的性能提升,这就是所谓的过度设计,得不偿失。
但是,如果对象中的数据需要经过复杂的计算才能得到(比如排序、计算哈希值),或者需要从 RPC、网络、数据库、文件系统等非常慢速的 IO 中读取,这种情况下,我们就可以利用原型模式,从其他已有对象中直接拷贝得到,而不用每次在创建新对象的时候,都重复执行这些耗时的操作。
原型模式的实现方式
我们现在有一个OrganizationInfoMap(一个ConcurrentHashMap<String, Organization>),存储的是系统内所有组织机构id-组织机构信息的对应关系,每个组织机构都有最后修改时间(lastModifyTime),OrganizationInfoMap也有两个属性,一个是版本V一个是时间T,即某个版本对应的最新的组织机构最后修改时间。现在有一个需求,30万组织机构在这个OrganizationInfoMap中,要实现定时更新,如果每次定时都创建新的30万终端,那么耗时非常长。我们可以将OrganizationInfoMap复制一份,然后筛选最后修改时间大于T的组织机构更新到OrganizationInfoMap里。代码示例如下:
public class OrgRefreshService {
private HashMap<String, Organization> organizationInfoMap = new HashMap<>();
private long lastModifyTime = -1;
public void refresh() {
HashMap<String, Organization> organizationInfoMapTmp = (HashMap<String, Organization>) organizationInfoMap.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到currentKeywords中
List<Organization> toBeUpdatedOrganizations = getOrganization(lastModifyTime);
long maxNewUpdatedTime = lastModifyTime;
for (Organization organization : toBeUpdatedOrganizations) {
if (organization.getLastModifyTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = organization.getLastModifyTime();
}
if (organizationInfoMapTmp.containsKey(organization.getId())) {
Organization organizationOld = organizationInfoMapTmp.get(organization.getId());
organizationOld.setLastModifyTime(organization.getLastModifyTime());
} else {
organizationInfoMapTmp.put(organization.getId(), organization);
}
}
lastModifyTime = maxNewUpdatedTime;
organizationInfoMap = organizationInfoMapTmp;
}
private List<Organization> getOrganization(long lastModifyTime) {
// TODO: 从数据库中取出更新时间>lastModifyTime的数据
return null;
}
}
当我们有一个新的需求,organizationInfoMap中的数据要么全是新的,要是全是旧的,不能有混杂的数据(即toBeUpdatedOrganizations中的数据不能存在部分更新到organizationInfoMapTmp中的情况,要么全都更新过去,要么全都没更新)。
那么上面的代码肯定是不满足的,为什么呢?在讲解原因之前,我们先介绍下两个概念:浅拷贝和深拷贝。
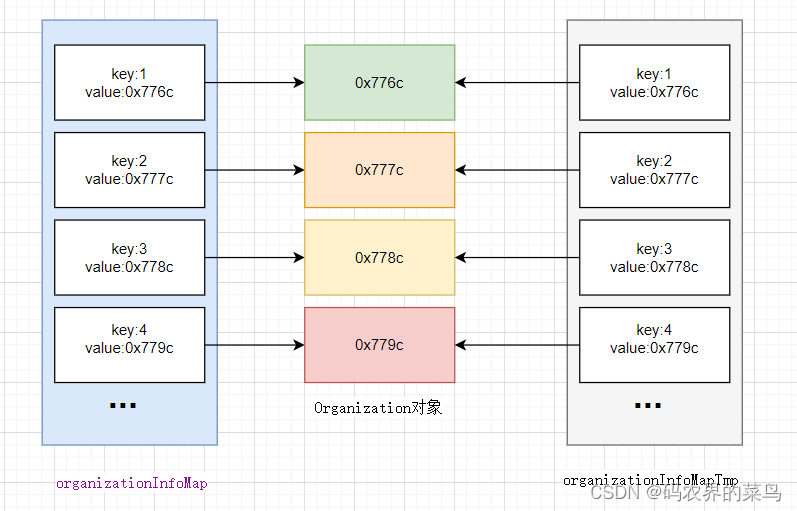
浅拷贝
浅拷贝只会拷贝对象地址的引用,不会在内存中开辟新的空间保存新的对象;图示如下:
深拷贝
深拷贝会在内存中开辟新的空间保存新的对象;图示如下:
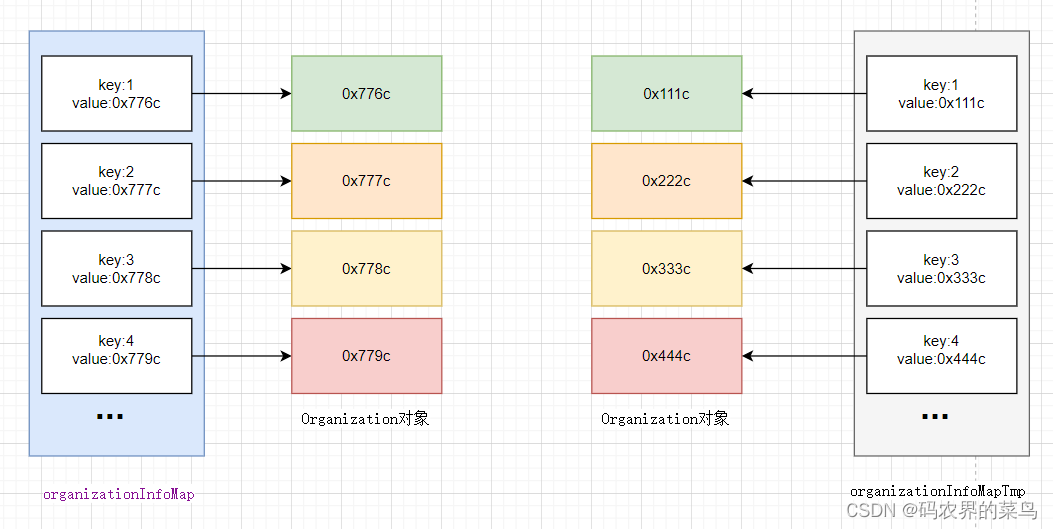
现在来看为什么上面的代码不能满足要么全都是最新的,要么全都是老的。因为在 Java 语言中,Object 类的 clone() 方法执行的就是我们刚刚说的浅拷贝。它只会拷贝对象中的基本数据类型的数据(比如,int、long),以及引用对象(Organization)的内存地址,不会递归地拷贝引用对象本身。
在上面的代码中,我们通过调用 HashMap 上的 clone() 浅拷贝方法来实现原型模式。当我们通过 organizationInfoMapTmp更新 Organization对象的时候,organizationInfoMapTmp和 organizationInfoMap因为指向相同的一组 Organization对象,就会导致 organizationInfoMap中指向的 Organization,有的是老版本的,有的是新版本的,就没法满足我们之前的需求:organizationInfoMap中的数据在任何时刻都是同一个版本的,不存在介于老版本与新版本之间的中间状态。
如何实现深拷贝
递归拷贝对象
递归拷贝对象、对象的引用对象以及引用对象的引用对象……直到要拷贝的对象只包含基本数据类型数据,没有引用对象为止。根据这个思路对之前的代码进行重构。重构之后的代码如下所示:
public class OrgRefreshService {
private HashMap<String, Organization> organizationInfoMap = new HashMap<>();
private long lastModifyTime = -1;
public void refresh() {
HashMap<String, Organization> organizationInfoMapTmp = new HashMap<>();
for (HashMap.Entry e : organizationInfoMap.entrySet()) {
Organization organization = (Organization) e.getValue();
Organization newOrganization = new Organization(organization.getId(), organization.getLastModifyTime());
organizationInfoMapTmp.put(organization.getId(), newOrganization);
}
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到currentKeywords中
List<Organization> toBeUpdatedOrganizations = getOrganization(lastModifyTime);
long maxNewUpdatedTime = lastModifyTime;
for (Organization organization : toBeUpdatedOrganizations) {
if (organization.getLastModifyTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = organization.getLastModifyTime();
}
if (organizationInfoMapTmp.containsKey(organization.getId())) {
Organization organizationOld = organizationInfoMapTmp.get(organization.getId());
organizationOld.setLastModifyTime(organization.getLastModifyTime());
} else {
organizationInfoMapTmp.put(organization.getId(), organization);
}
}
lastModifyTime = maxNewUpdatedTime;
organizationInfoMap = organizationInfoMapTmp;
}
private List<Organization> getOrganization(long lastModifyTime) {
// TODO: 从数据库中取出更新时间>lastModifyTime的数据
return null;
}
}
序列化与反序列化
先将对象序列化,然后再反序列化成新的对象。具体的示例代码如下所示:
public Object deepCopy(Object object) {
ByteArrayOutputStream bo = new ByteArrayOutputStream();
ObjectOutputStream oo = new ObjectOutputStream(bo);
oo.writeObject(object);
ByteArrayInputStream bi = new ByteArrayInputStream(bo.toByteArray());
ObjectInputStream oi = new ObjectInputStream(bi);
return oi.readObject();
}
优化浅拷贝与深拷贝
刚刚的两种实现方法,不管采用哪种,深拷贝都要比浅拷贝耗时、耗内存空间。针对我们这个应用场景,有没有更快、更省内存的实现方式呢? 我们可以先采用浅拷贝与深拷贝混合的方式只对要更新的对象完成深拷贝,代码示例如下:
public class OrgRefreshService {
private HashMap<String, Organization> organizationInfoMap = new HashMap<>();
private long lastModifyTime = -1;
public void refresh() {
HashMap<String, Organization> organizationInfoMapTmp = (HashMap<String, Organization>) organizationInfoMap.clone();
// 从数据库中取出更新时间>lastUpdateTime的数据,放入到currentKeywords中
List<Organization> toBeUpdatedOrganizations = getOrganization(lastModifyTime);
long maxNewUpdatedTime = lastModifyTime;
for (Organization organization : toBeUpdatedOrganizations) {
if (organization.getLastModifyTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = organization.getLastModifyTime();
}
if (organizationInfoMapTmp.containsKey(organization.getId())) {
organizationInfoMapTmp.remove(organization.getId());
}
organizationInfoMapTmp.put(organization.getId(), organization);
}
lastModifyTime = maxNewUpdatedTime;
organizationInfoMap = organizationInfoMapTmp;
}
private List<Organization> getOrganization(long lastModifyTime) {
// TODO: 从数据库中取出更新时间>lastModifyTime的数据
return null;
}
}
总结
在实际开发工作中,原型模式的使用场景不多,但是要了解其原理,并且在有类似需求的时候能快速给出合适的方案。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结