您现在的位置是:首页 >技术交流 >Hbase1.1:HBase官网、HBase定义、HBase结构、HBase依赖框架、HBase整合框架网站首页技术交流
Hbase1.1:HBase官网、HBase定义、HBase结构、HBase依赖框架、HBase整合框架
HBase官网
HBase是Hadoop database,一个分布式、可扩展的大数据存储。
当您需要对大数据进行随机、实时读/写访问时,请使用Apache HBase。这个项目的目标是在商用硬件集群上托管非常大的表——数十亿行X数百万列。Apache HBase是一个开源的、分布式的、版本化的、非关系数据库,模仿Google的Bigtable:结构化数据的分布式存储系统正如Bigtable利用Google文件系统提供的分布式数据存储一样,Apache HBase在Hadoop和HDFS的基础上提供了类似Bigtable的功能。
HBase特点:大

大。当你需要随机、随时的读取大数据时候,据可以用。
那么可以多大?
官网原话:数十亿行X数百万列(billions of rows X millions of columns)。
HBase定义
HBase是以hdfs为数据存储的,一种分布式、可扩展的NoSQL数据库(NoSQL数据库是以KV形式存储,根据key读取数据更快,同时没有关系型数据库中数据表行与列的关系,操作起来更加方便)。
HBase不是一个单词,而是合起来的简称,base指database,H可以理解为hadoop,或者是hdfs都可以。
HBase结构
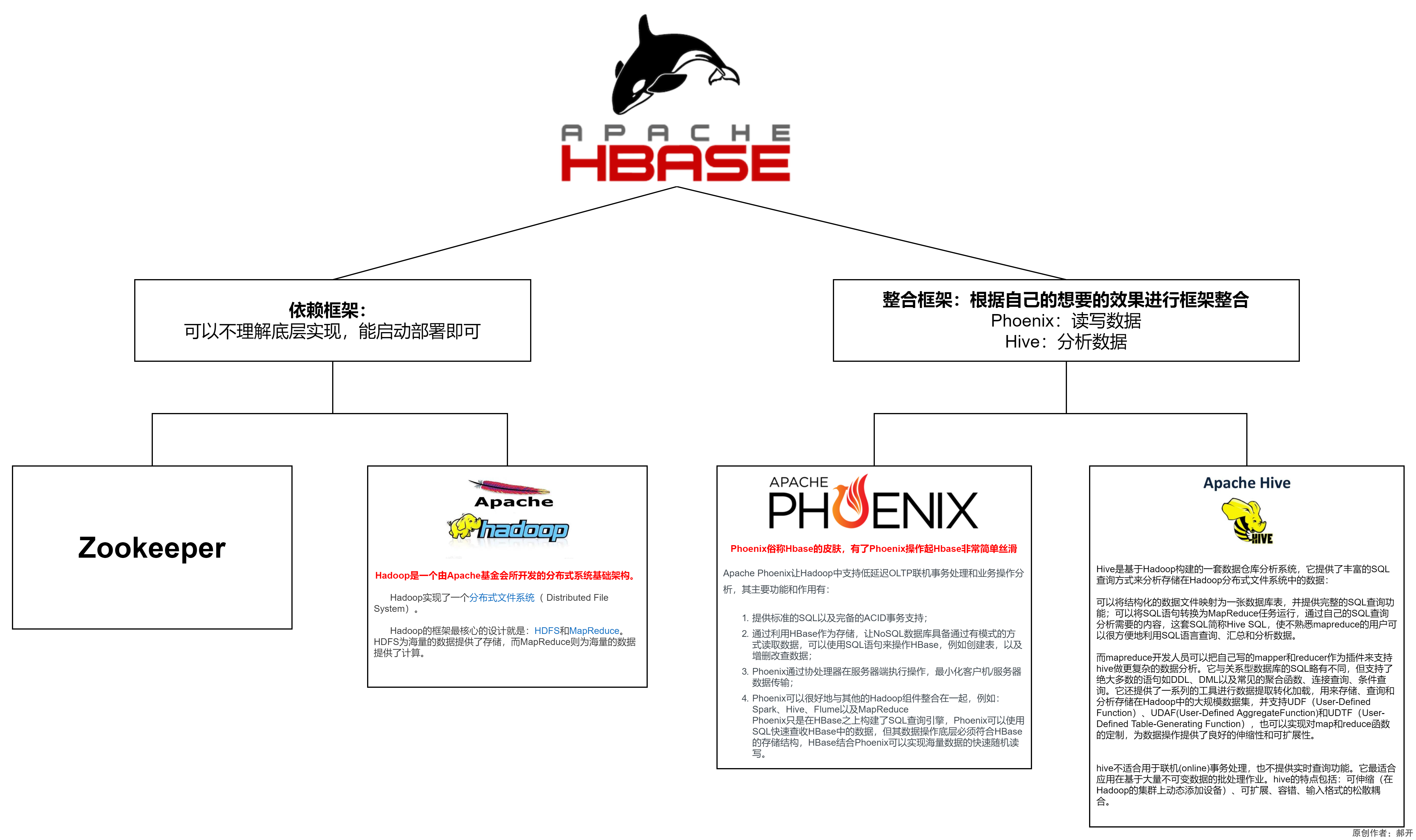
HBase依赖框架
可以不理解底层实现,能启动部署即可
hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
Hadoop实现了一个分布式文件系统( Distributed File System)。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
HBase整合框架
根据自己的想要的效果进行框架整合
Phoenix:读写数据
Hive:分析数据
Phoenix
Phoenix俗称Hbase的皮肤,有了Phoenix操作起Hbase非常简单丝滑
Apache Phoenix让Hadoop中支持低延迟OLTP联机事务处理和业务操作分析,其主要功能和作用有:
提供标准的SQL以及完备的ACID事务支持;
通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,可以使用SQL语句来操作HBase,例如创建表,以及增删改查数据;
Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输;
Phoenix可以很好地与其他的Hadoop组件整合在一起,例如:Spark、Hive、Flume以及MapReduce
Phoenix只是在HBase之上构建了SQL查询引擎,Phoenix可以使用SQL快速查收HBase中的数据,但其数据操作底层必须符合HBase的存储结构,HBase结合Phoenix可以实现海量数据的快速随机读写。
Hive
Hive是基于Hadoop构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop分布式文件系统中的数据:
可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL,使不熟悉mapreduce的用户可以很方便地利用SQL语言查询、汇总和分析数据。
而mapreduce开发人员可以把自己写的mapper和reducer作为插件来支持hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句如DDL、DML以及常见的聚合函数、连接查询、条件查询。它还提供了一系列的工具进行数据提取转化加载,用来存储、查询和分析存储在Hadoop中的大规模数据集,并支持UDF(User-Defined Function)、UDAF(User-Defined AggregateFunction)和UDTF(User-Defined Table-Generating Function),也可以实现对map和reduce函数的定制,为数据操作提供了良好的伸缩性和可扩展性。
hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。hive的特点包括:可伸缩(在Hadoop的集群上动态添加设备)、可扩展、容错、输入格式的松散耦合。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结