您现在的位置是:首页 >其他 >自动驾驶BEV感知系列算法整理总结网站首页其他
自动驾驶BEV感知系列算法整理总结
序论
之前一直做的lidar感知,现在感觉大趋势是多传感器融合,所以博主也在向BEV下的融合框架学习,希望大家后面可以多多交流,下面会分为两类进行介绍,后期的文章会在下面两类中以小标题的形式出现,BEV下的两类检测算法主要区分点在于img2bev模块,一类是显示转换,以lss为基础,一类是以transformer为基础的隐式转换。
一、显示转换的BEV感知
1.LSS
论文链接:https://arxiv.org/pdf/2008.05711.pdf
lss目前应该是显示转换的鼻祖,大部分都是基于它进行优化的,所以这个部分会进行详细介绍。
优点:实现了相机特征到BEV特征的转换
缺点:极度的依赖depth预测的准确性,同时矩阵外积过于耗时,要想在depth维度有较高的精度,HWD计算量特别大。
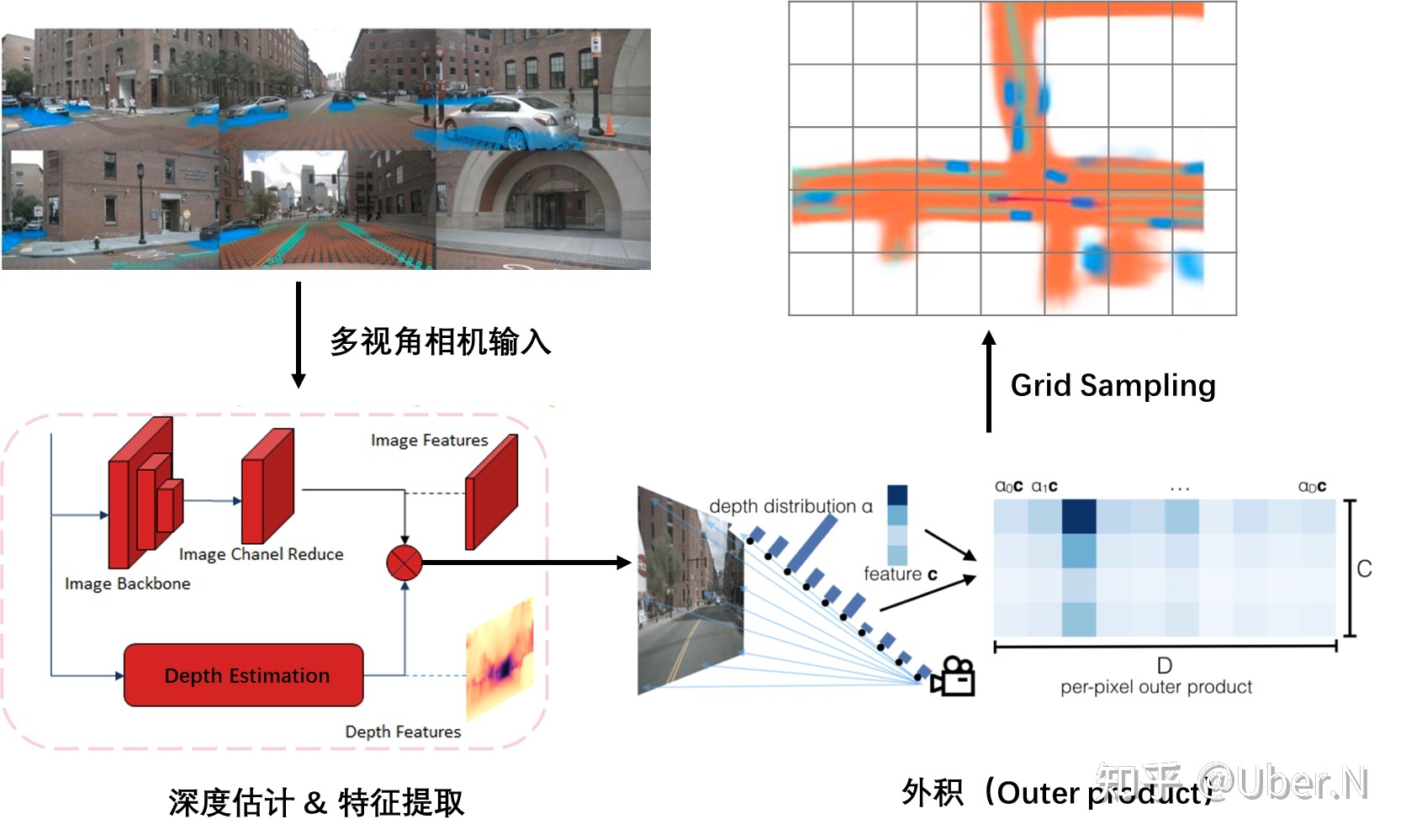
A:Lift操作
LSS中的L表示lift,升维的意思,表示把H*W*C的图像特征升维到H*W*D*C,D表示在每个像素点都预测了一个D维的深度信息,比如D是50维,相当于这个像素点在0-50m里出现的概率。D的一个维度表示在这一米出现的概率。
第一步:get_geometry(得到特征图与3D空间的索引对应)
torch.arange生成D的列表,view加expand变成(D,H,W)的维度
torch.linespace生成特征图长宽HW的列表分布,里面的值是像素坐标,同样view+expand变为(D,H,W),然后用torch.stack将这三个在-1维度拼接。得到(D,H,W,3)的矩阵,相当于给定一个D,H,W的特征点,我们可以得到三维的像素坐标表示,这个像素坐标需要转换到真实车身坐标系。
将图像数据增强进行抵消,同时根据相机内外参矩阵与上面的相乘,得到(D,H,W,3)这个3表示的就是车身坐标系的3D位置。此时我们就可以根据一个D,H,W索引的特征点,得到其在真实空间的位置。这一步是接下来投影的关键。
第二步:get_cam_feats(得到相机的D,H,W型feature)
图像经过骨干网络处理之后,用一个1*1的卷积,将channel变为D+C,在channel维度选取前D维,进行softmax操作,相当于说这个H,W的特征点在D的深度上的分布概率。将(N,1,D)和(N,C,1)做乘法,相当于矩阵外积,得到(N,C,D)的张量,N表示的是H*W,所以我们就得到了(D,H,W,C)的图像特征。
B:Splat操作
splat表示拍平的意思,上一步我们得到了像素空间与真实3D空间的坐标索引,同时也得到了(D,H,W,C)的图像特征高维表示。这一步就是把特征转换到BEV空间中,并拍平为2D,相当于pointpillar的操作。
第一步:预处理操作
传进来的就是geom_feats维度为(D,H,W,3)和X图像高维特征(D,H,W,C),首先geom_feats里3这个维度,里面的值是车身坐标系的3D位置,有正有负,我们先把他变为从0开始的长整形分布,比如x是0-100m,y是0-60m,z是0-5m这样,全为正的表示,相当于做个平移。然后view成(Nprime,3),然后循环batch,用torch.cat以及torch.full生成一个(Nprime,1)的batch索引,再和geom_feats用torch.cat一下,得到新的geom_feats维度为(Nprime,4),里面是真实空间的xyzb,然后用xyz的范围进行过滤一下。
第二步:拍平操作
得到维度为(Nprime,4)的geom_feats,这里说的也不准确,因为过滤了范围外的,第一维度就不再是Nprime,大家理解就行。然后根据BEV分辨率对geom_feats进行排序,geom_feats[:,0]*Y*Z*B+geom_feats[:,1]*Z*B+geom_feats[:,2]*B+geom_feats[:,3],然后argsort排序,对X以及geom_feats进行排序。X维度为(Nprime,C),对其进行cumsum操作,也叫前缀和操作,然后找到网格变化的节点,用当前变化节点减去前面的变化节点,就是中间这个网格的和,起到了一个sum_pooling操作,最后根据geom_feats的索引,把X放入到(B,C,Z,X,Y)里面,再把Z用unbind和cat操作压缩即可。
2.BEVDet
论文:https://arxiv.org/pdf/2112.11790.pdf
代码:GitHub - HuangJunJie2017/BEVDet: Official code base of the BEVDet series .
论文创新点:
针对LSS在训练时特别容易过拟合,采取了两种数据增强,一种是在图像域,一种是在BEV下。
改进版的scale-NMS,因为在BEV下,有些物体特别小,后处理时没有交集,无法过滤重复预测,如锥桶和行人,在BEV上不到一个分辨率,这样冗余预测也不会有交集,我们就把其scale放大之后再进行iou去冗余。
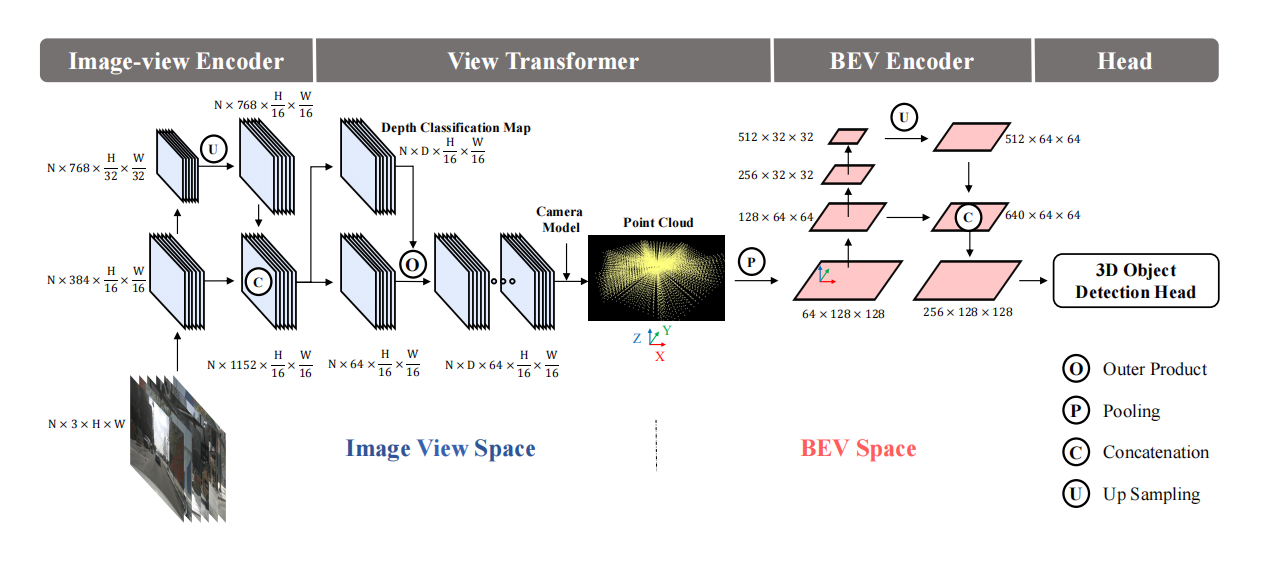
在图像上采用的数据增强如:翻转,缩放,旋转都可以表示为一个3*3的矩阵,在img2bev的时候再乘以该矩阵的逆,这样图像和BEV空间的位置还是一一对应的,就是相当于无论怎么数据增强,这个图片的BEV位置都是不变的,增强图像特征网络的泛化性能。当然,在BEV上也做了数据增强,这时对于GT也要做相应的处理。
3.BEVFusion
论文:https://arxiv.org/pdf/2205.13542.pdf
论文创新点:
开创性的BEV上的lidar和camer融合框架
针对LSS池化操作过慢,进行了优化处理,大大加快其推理速度。
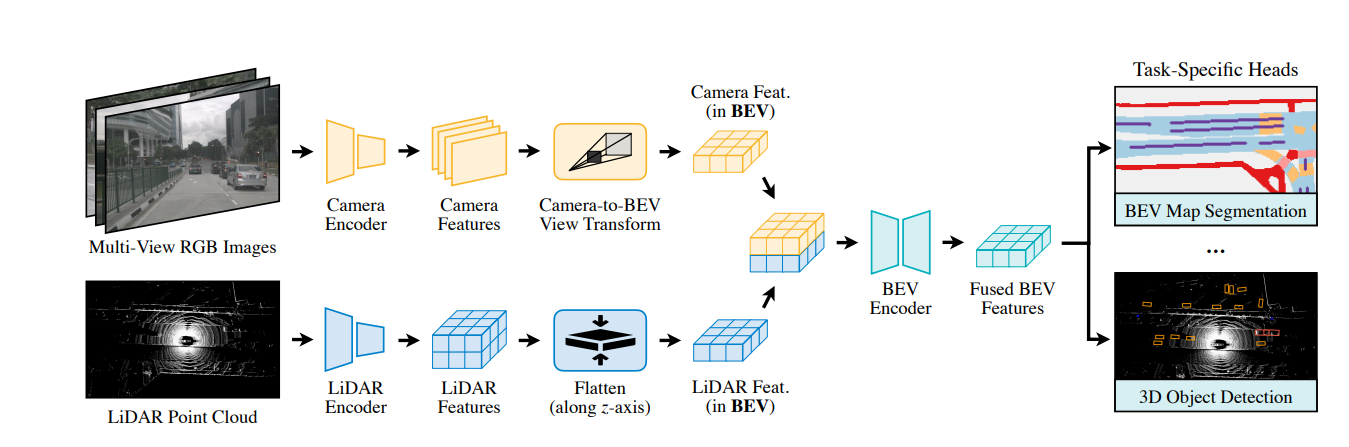
针对LSS池化操作的优化有两点:
1.预计算
LSS池化的第一步是将像素空间的3D点与BEV空间的伪点云建立关联,而像素空间的点云坐标位置是固定的,可以预先计算其编码,然后排序,记录下下标,推理时直接对像素空间3D点进行排序。从原先的17ms,优化到4ms
2.间歇降低
LSS池化是对网格里面的点求和聚集特征,用的cumsum操作,前缀和,所有的点都要求前缀和,然后用当前边界的前缀和减去前一个边界前缀和,来得到当前网格的特征sum,这种操作是低效的,而论文中自己编写了一个GPU内核,为每个网格分配了一个GPU的线程,来计算间歇和并返回结果。速度从500ms降到2ms。
4.BEVDepth
论文:https://arxiv.org/pdf/2206.10092.pdf
代码: GitHub - Megvii-BaseDetection/BEVDepth: Official code for BEVDepth.
论文认为LSS对于深度估计的准确度不够高,导致指标不高
论文创新点:
1.使用lidar作为精确的深度监督
2.将相机内外参作为输入传入DepthNet
3.使用深度细化模块对预测的深度进行细化
4.使用更高效的体素池化
5.多帧融合(代码里只是单纯的将不同帧之间的BEV特征沿着维度方向cat)
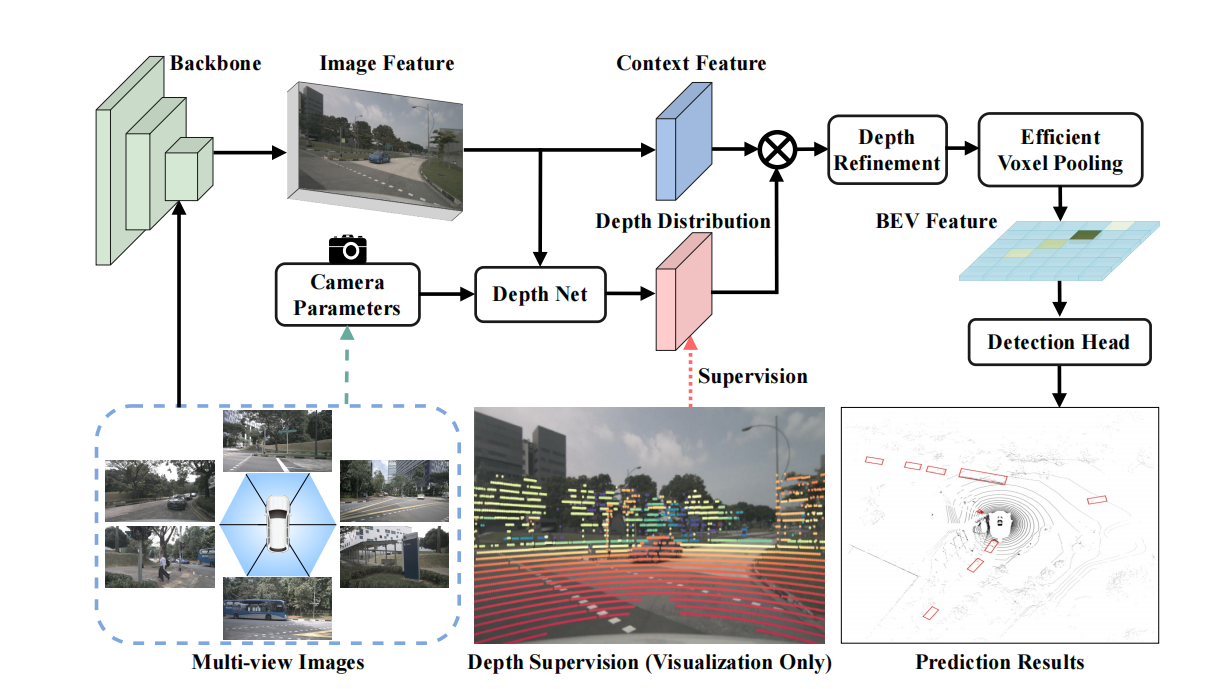
1.lidar作为精确的深度监督
首先将点云从lidar坐标系转到camer坐标系,获取其Z的深度信息,然后再转到像素坐标系,得到每个点在像素平面的u,v坐标,同时去掉不在图像范围里的以及深度太小的,然后将图像的数据增强矩阵也乘上,让他们同步,把u,v整形化,把N个点放入[H,W]的图像平面上,值为深度信息。监督的时候,把其缩放到特征图大小,每一块都采用最小值池化,把不在范围里面的点赋0,现在的维度是[B*N,H,W],然后根据深度值生成独热向量,去掉D为0的,得到[B*N,H,W,D],然后计算二值交叉熵损失。
2.相机深度预测DepthNet
将相机的内外参以及IDA和BDA(数据增强矩阵)组成27维的特征,经过MLP升到和图像特征X一样的维度,得到两个SE(一个深度注意力,一个特征注意力),然后sigmoid,与图像特征相乘,对于深度模块,出来之后还要再经过空洞特征金字塔网络(ASPP)和DCN可变形卷积来增大深度模块的感受野,从而使深度预测的更加精确。然后对深度softmax,与特征外积得到[C,D,H,W].
3.深度细化模块
对于出来的[C,D,H,W]特征,我们沿着W,D维度进行二维卷积,不断地聚集沿着深度方向的信息,即使我们一开始深度预测的不是很精确,但是随着在深度方向的特征聚集以及感受野的扩大,深度预测精度可以得到一个很好的优化。
二、隐式转换的BEV感知
三、Reference






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结