您现在的位置是:首页 >学无止境 >ollama + qwen2.5:7b + vscode + 3060显卡部署本地大模型实现ai辅助代码编写网站首页学无止境
ollama + qwen2.5:7b + vscode + 3060显卡部署本地大模型实现ai辅助代码编写
一、部署环境
1.电脑品牌:联想拯救者y9000p 2022
2.操作系统:windows11
3.GPU:RTX 3060 6G显存
4.CPU:12th Gen Intel® Core™ i7-12700H
5.内存:32G
二、部署步骤
第一步:安装ollama
登陆官网,下载window版的exe安装包,下载后双击安装即可;

下载安装完成后,打开powershell,输入ollama -v 验证下是否安装成功,如下图,出现版本号说明安装成功。

第二步:下载大模型
因为我想在本地搭建用于代码编写辅助提示的大模型,所以选择了qwen2.5-coder:7b,先在ollama官网模型仓库查找需要下载的模型,然后在本地下载模型,操作如下:
点击访问ollama官网

进入模型仓库页面后,找到需要下载的模型,复制模型下载命令“ollama run qwen2.5-coder:7b”
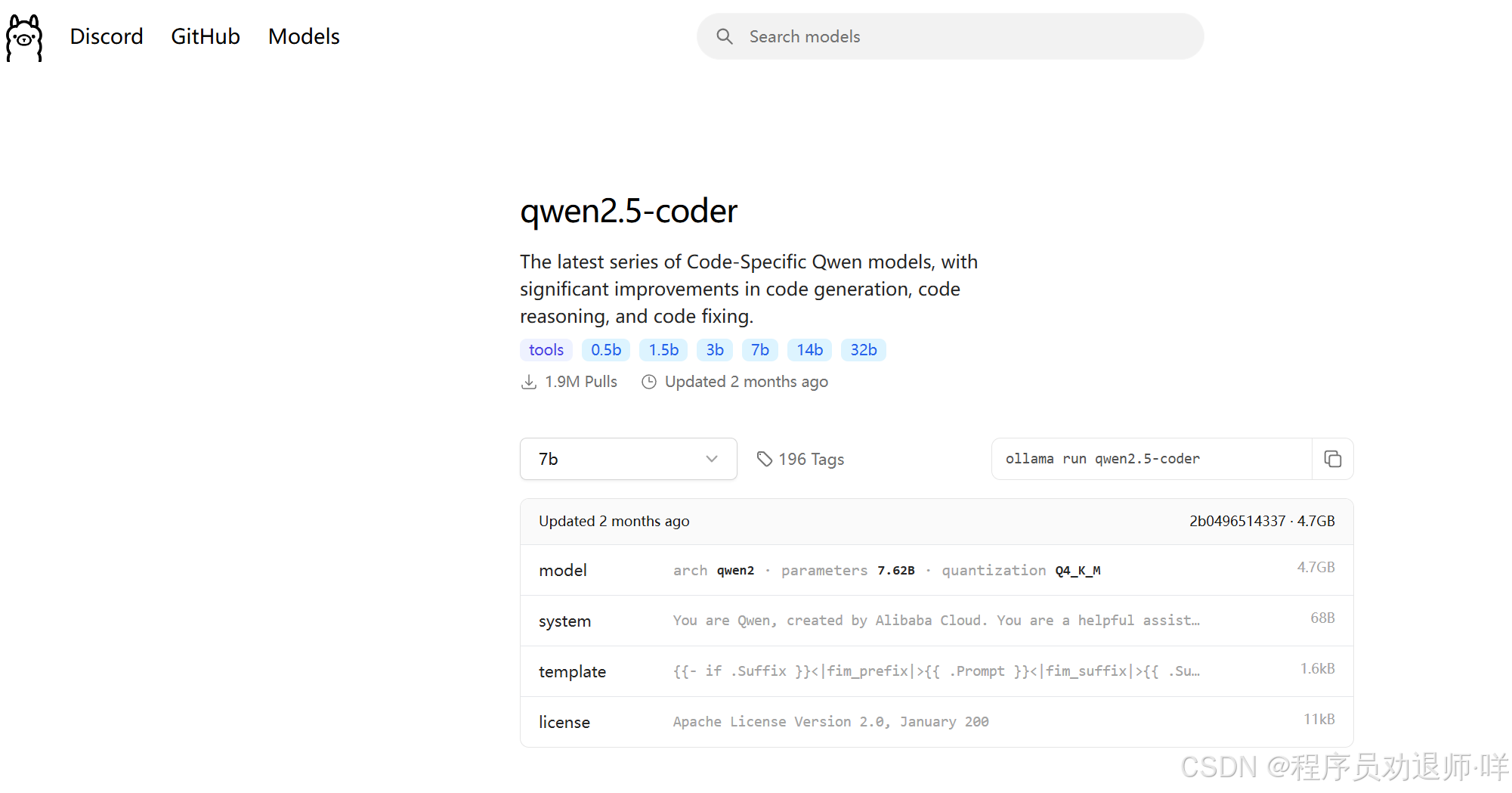
复制好的命令粘贴到powershell里面运行,最后面需要指明模型的参数量,我选择的是7b的,类似于docker下载镜像的时候需要指明版本号一样。下载完成后,便可进行对话了:

ollama常用命令:
1.查询下载了哪些模型:ollama list

2.运行模型:ollama run 模型名称
例如:ollama run qwen2.5-coder:7b

3.退出当前对话 /exit

三、集成vscode
部署ollama成功后,ollama的本地服务地址默认是http://localhost:11434(localhost可以换成本地网卡ip地址,服务器一样),vscode集成大模型需要借助应用市场的插件“Continue”,搜索并下载安装。
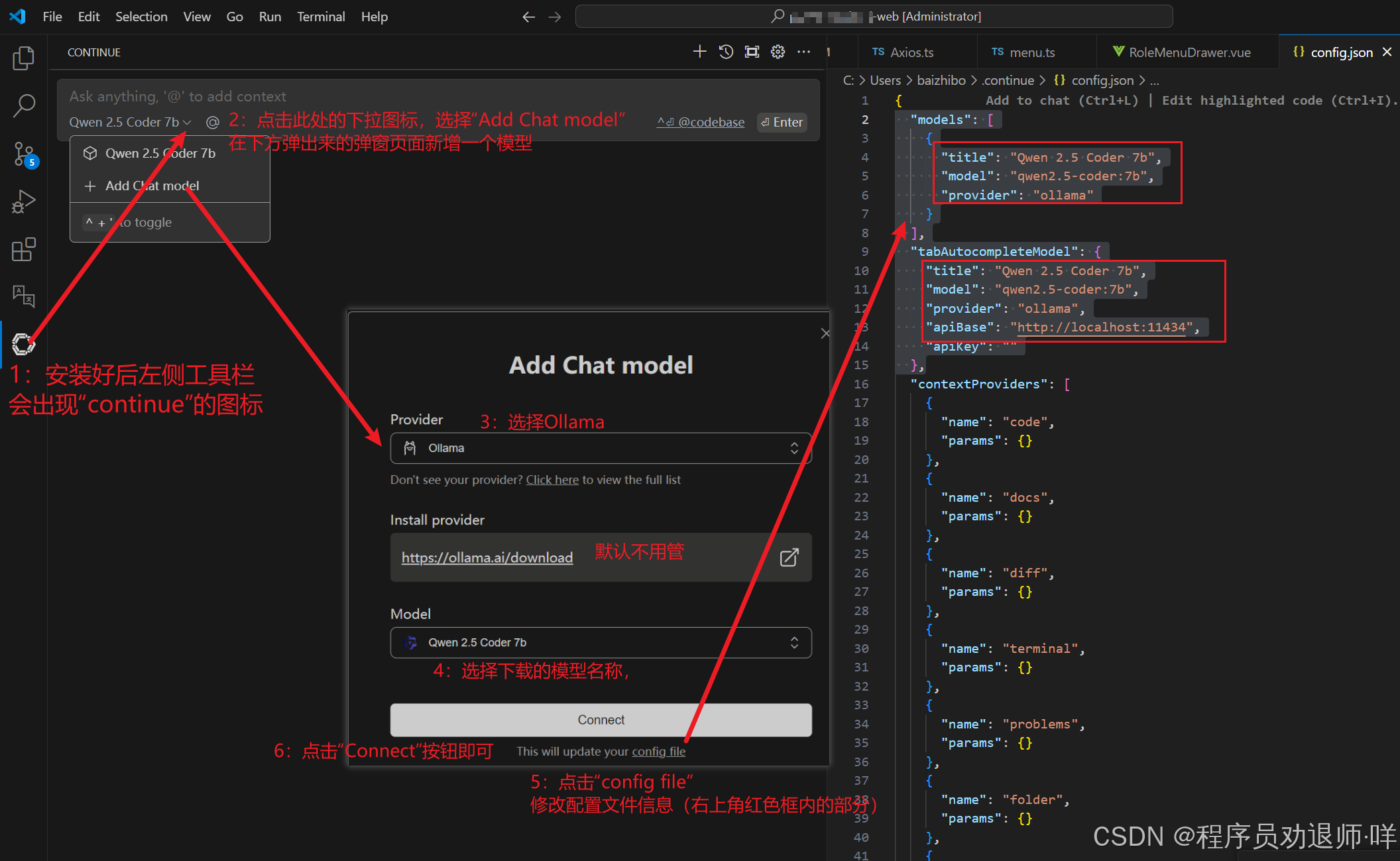
连接成功后,编可以开始对话了。
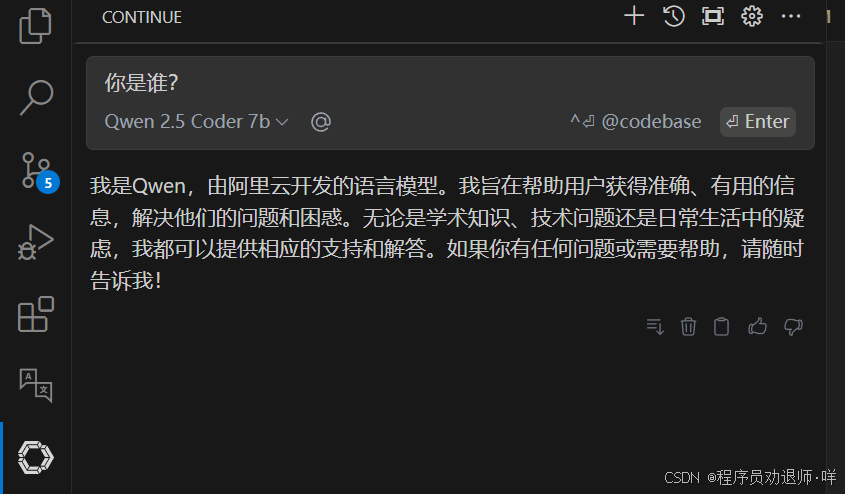
代码编写的时候会自动进行补填和提示。
如果需要更换模型,下载好以后根据上面的步骤添加就可以了,多个模型可以根据实际需要切换使用。
四、集成Chatbox
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用(源于官网解释)。点击前往官网下载
说明一下,我们本地部署了大模型后,因为跟Chatbox是基于服务接口进行的对接,所以下载客户端也可以,使用官网的Chatbox网页版也可以,配置方式都是一样的,长期用的话还是建议下载客户端。
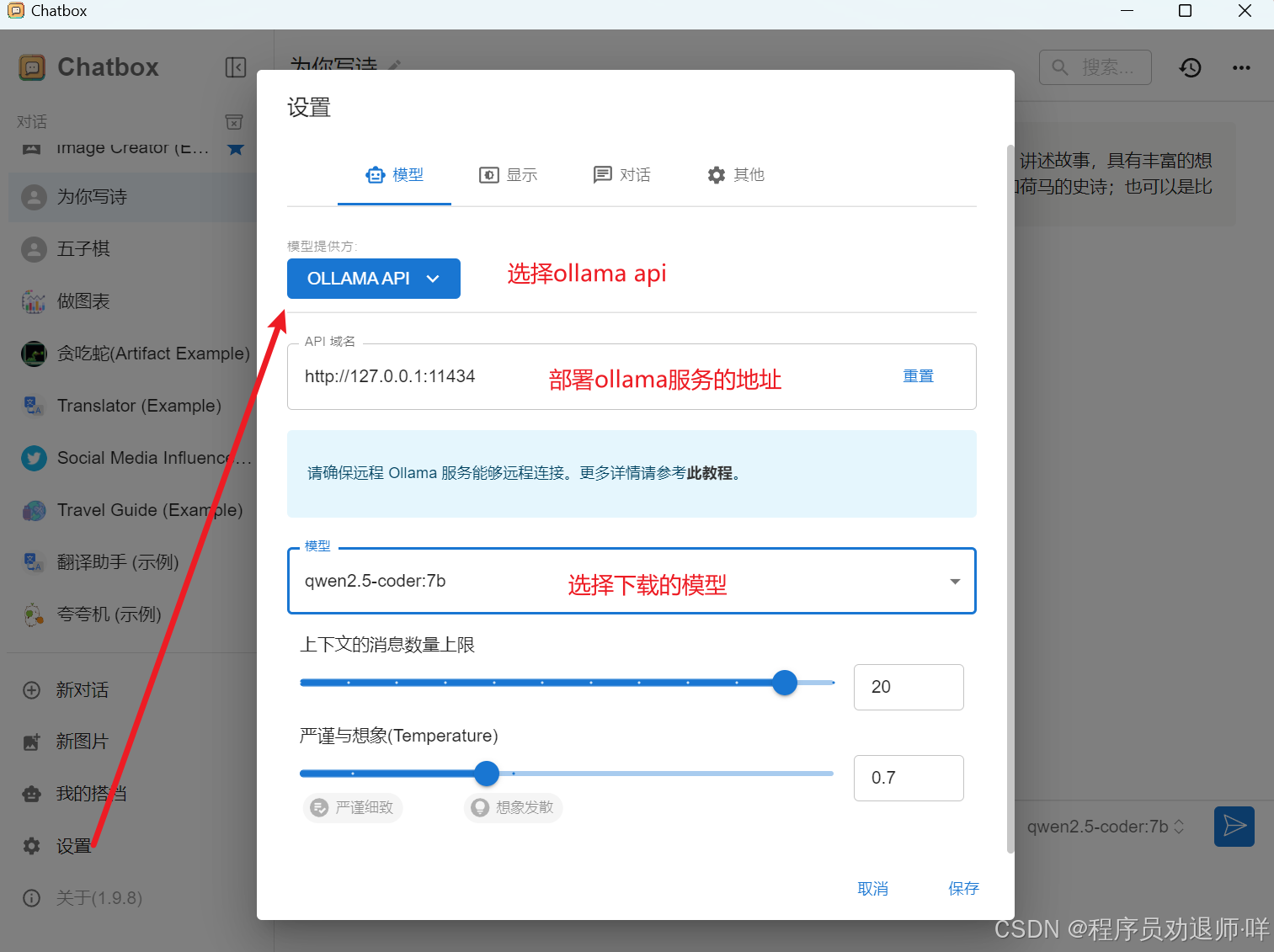
到此,Chatbox就配置完成了
题外话:
我在本地下载了两个模型,一个是qwen2.5-coder:7b,一个是deepseek-r1:14b,前者可以很流畅的运行,后者速度稍慢,但是也是可以接受的,毕竟参数在那里。下面针对两个模型写的同样需求的一首诗送给大家。


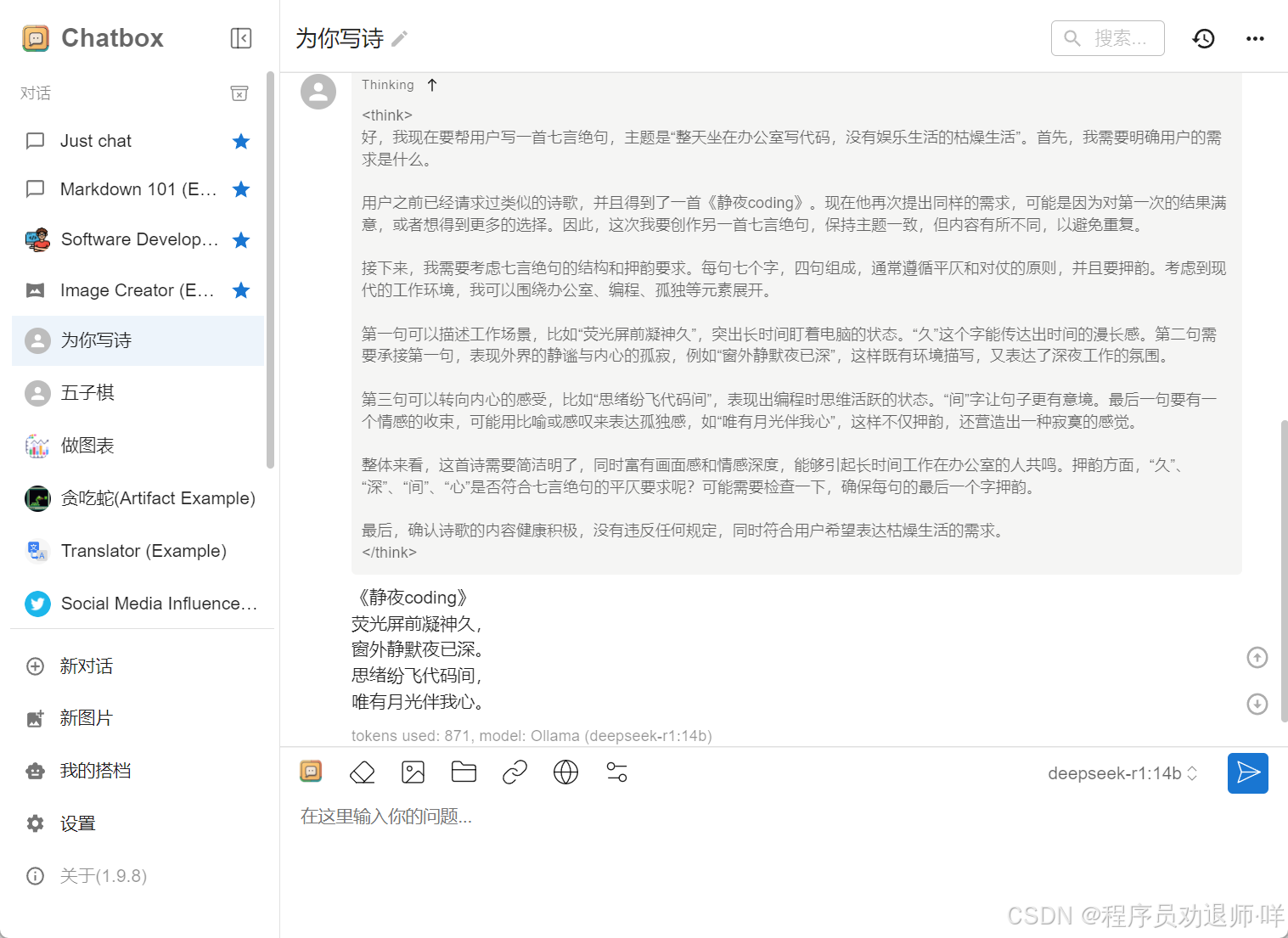
创作不易,转载请标注出处






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结