您现在的位置是:首页 >其他 >Kubernetes那点事儿——调度策略网站首页其他
Kubernetes那点事儿——调度策略
Kubernetes那点事儿——调度策略
前言
Kubernetes的强大之处离不开它的调度系统,它为Pod调度到某个Node上提供了多种方式来满足不同的需求。
一、静态Pod
- Pod由特定节点上的kubelet管理
- 不能使用控制器
- Pod名称标识当前节点名称
在kubelet配置文件启用静态Pod:
vi /var/lib/kubelet/config.yaml
…
staticPodPath: /etc/kubernetes/manifests
…
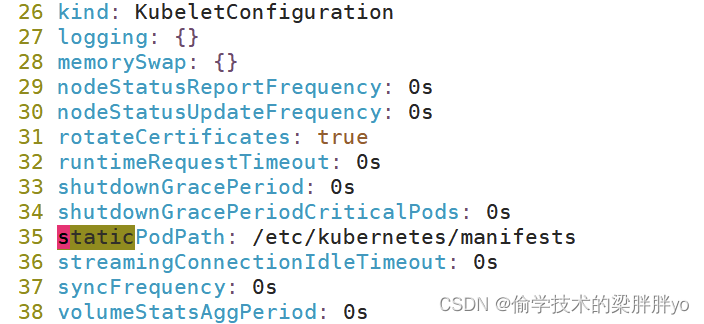
将部署的pod yaml放到该目录会由kubelet自动创建。
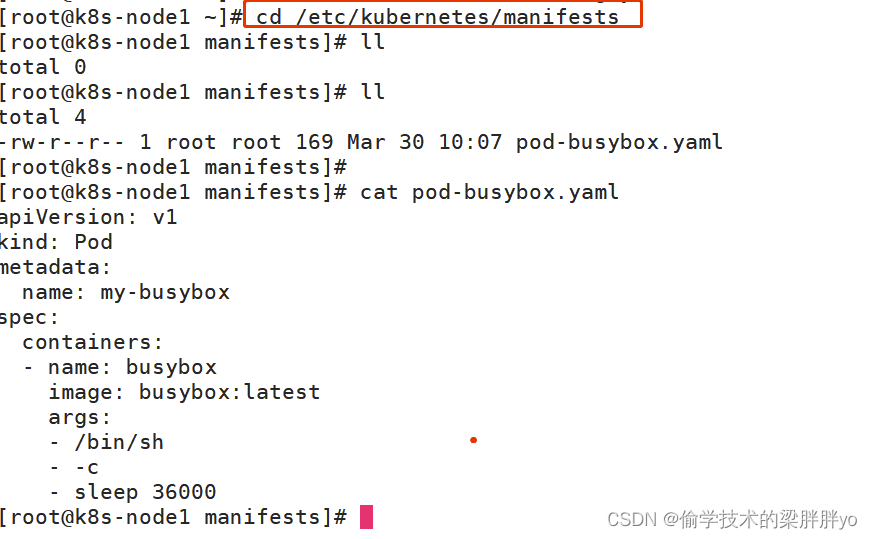
在master节点查看pod,以-命令

删除yaml文件后,pod也自动被删除。
二、nodeSelector 节点选择器
nodeSelector:用于将Pod调度到匹配Label的Node上,如果没有匹配的标签会调度失败。
- 完全匹配节点标签
- 固定Pod到特定节点
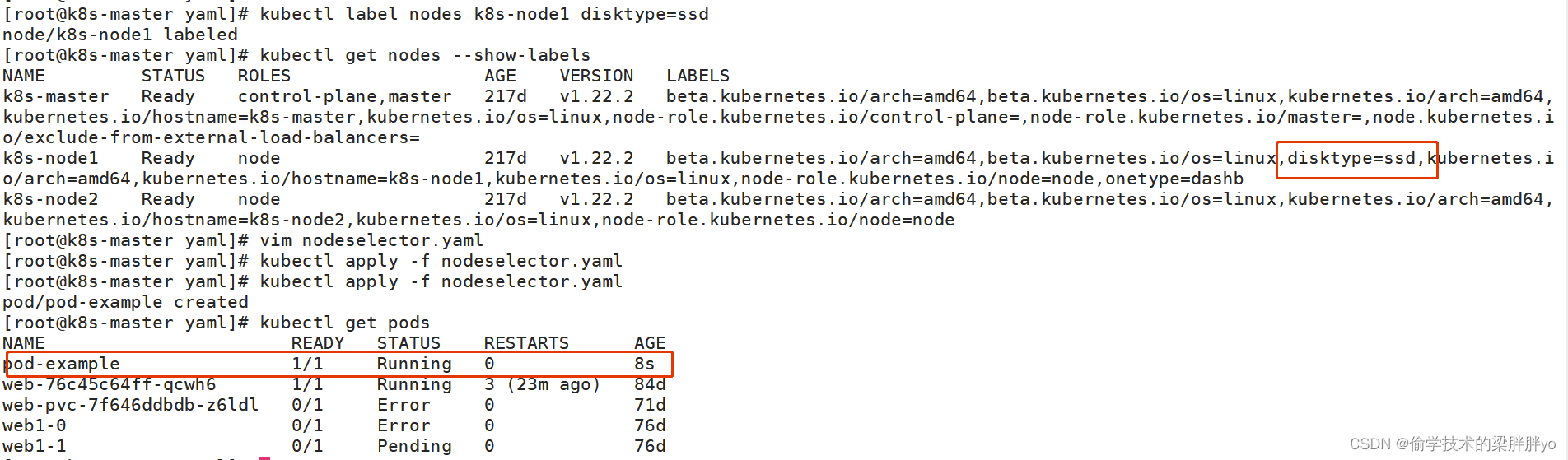
基于label匹配,所以要提前对节点进行标签规划并打好标签
kubectl label nodes [node] key=value
eg:kubectl label nodes k8s-node1 disktype=ssd
nodeSelector示例.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
nodeSelector:
disktype: "ssd"
containers:
- name: nginx
image: nginx:1.20
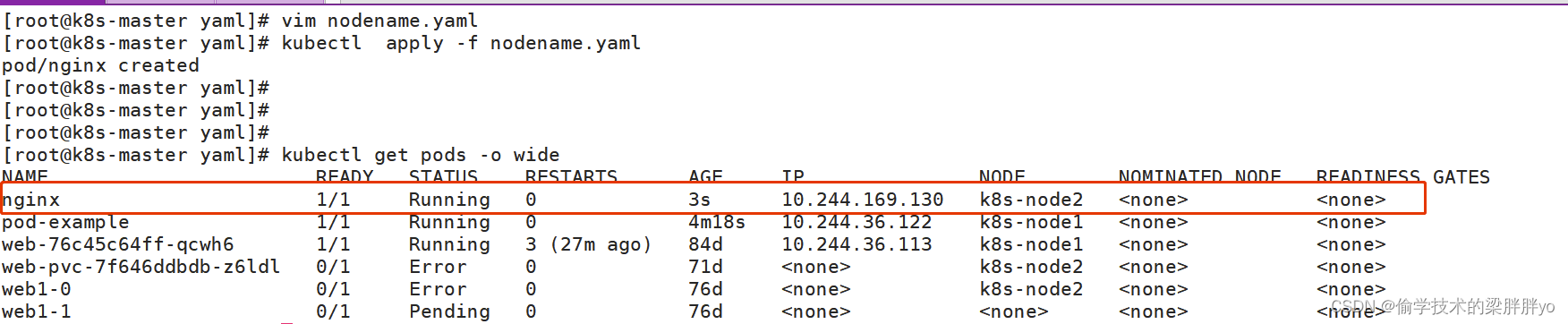
三、nodeName
nodeName 是 PodSpec 的一个字段。 如果它不为空,调度器将忽略 Pod,并且给定节点上运行的 kubelet 进程尝试执行该 Pod。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
nodeName: k8s-node2
containers:
- name: nginx
image: nginx
四、taint污点
taints:避免Pod调度到特定Node上
应用场景:
- 专用节点,例如配备了特殊硬件的节点
- 基于Taint的驱逐
设置污点:
kubectl taint node [node] key=value:[effect]
eg:kubectl taint nodes k8s-node1 key1=value1:NoSchedule
去除污点:
kubectl taint node [node] key:[effect]-
eg:kubectl taint nodes k8s-node1 key1:NoSchedule-
其中[effect] 可取值:
- NoSchedule :一定不能被调度
- PreferNoSchedule:尽量不要调度
- NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
五、tolerations污点容忍
tolerations:允许Pod调度到持有Taints的Node上
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
此yaml可以将pod分匹配到k8s-node1上,其中tolerations有两种方式实现,取决于operator的值;
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "NoSchedule"
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoSchedule"
一个容忍度和一个污点相“匹配”是指它们有一样的键名和效果,并且:
如果 operator 是 Equal ,则它们的 value 应该相等
如果 operator 是 Exists ,此时容忍度不能指定 value
注意:存在两种特殊情况:
- 如果一个容忍度的 key 为空且 operator 为 Exists, 表示这个容忍度与任意的 key 、value 和 effect 都匹配,即这个容忍度能容忍任意 taint。
- 如果 effect 为空,则可以与所有键名 key 的效果相匹配。
六、容器资源限制
容器资源限制也决定了Pod调度到哪个或哪些Node上,K8s会根据Request的值去查找有足够资源的Node来调度此Pod
容器资源限制:
• resources.limits.cpu
• resources.limits.memory
容器使用的最小资源需求,作为容器调度时资源分配的依据:
• resources.requests.cpu
• resources.requests.memory
apiVersion: v1
kind: Pod
metadata:
name: web
spec:
containers:
- name: web
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
若多个Node节点内存少于64m,则Pod不会调度到这些Node上,若所有Node内存均小于64m,则该Pod调度失败。
七、nodeAffinity节点亲和性
nodeAffinity:节点亲和类似于nodeSelector,可以根据节点上的标签来约束Pod可以调度到哪些节点
相比nodeSelector:
- 匹配有更多的逻辑组合,不只是字符串的完全相等
- 调度分为软策略和硬策略,而不是硬性要求
- 硬需求(requiredDuringSchedulingIgnoredDuringExecution):必须满足
- 软需求(preferredDuringSchedulingIgnoredDuringExecution):尝试满足,但不保证
操作符:In、NotIn、Exists、DoesNotExist、Gt、Lt
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
此节点亲和性规则表示,Pod 只能放置在具有标签键 kubernetes.io/e2e-az-name且标签值为 e2e-az1 或 e2e-az2 的节点上。
另外,在满足这些标准的节点中,具有标签键为 another-node-label-key 且标签值为 another-node-label-value 的节点应该优先使用。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结