您现在的位置是:首页 >其他 >【黑马2023大数据实战教程】VMWare虚拟机部署HDFS集群详细过程网站首页其他
【黑马2023大数据实战教程】VMWare虚拟机部署HDFS集群详细过程
文章目录
视频:黑马2023 VMWare虚拟机部署HDFS集群
注意!这些操作的前提是完成了前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作!!!
操作在这里 大数据集群环境准备过程记录(3台虚拟机)
部署HDFS集群
1.上传Hadoop安装包到node1节点中
rz -bey
2.解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
3构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
4.进入hadoop安装包内
cd hadoop
ls -l查看文件夹内部结构:
各个文件夹含义如下:
bin ,存放Hadoop的各类程序 (命令 etc,存放Hadoop的配置文件
include,C语言的一些头文件lib,存放Linux系统的动态链接库 (.so文件)libexec,存放配置Hadoop系统的脚本文件
(.sh和.cmd licenses-binary,存放许可证文件 sbin,管理员程序 (super bin)
share,存放二进制源码 (Javajar包)
主要配置的是etc中的一些文件:!!!
cd /export/server/hadoop/etc/hadoop
这里要注意,我一开始把配置全写在/export/server/hadoop 文件中,最后启动时无法启动节点,排查了好久>_<!!
1.配置workers:
vim workers
先删掉内置的localhost
输入:
node1
node2
node3
2.配置hadoop-env.sh文件
vim hadoop-env.sh
填入如下内容
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
JAVA HOME,指明JDK环境的位置在哪
HADOOP_HOME,指明Hadoop安装位置
HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
HADOOP_LOG DIR,指明Hadoop运行日志目录位置
通过记录这些环境变量,来指明上述运行时的重要信息
3.配置core-site.xml文件
vim core-site.xml
在文件内部填入如下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
key: fs.defaultFS 含义:HDFS文件系统的网络通讯路径 值:hdfs://nodel:8020
协议为hdfs:// namenode为node1 namenode通讯端口为8020 key:
jo.file.buffer.size 含义: io操作文件缓冲区大小 值:131072bithdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs:// (Hadoop内置协议)
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
此配置固定了node1必须启动NameNode进程
4.配置hdfs-site.xml文件
在文件内部填入如下内容
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>node1,node2,node3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
这里我出现了HDFS部署成功但是网页端打不开的情况,通过显示指定端口解决了 ,即加入了:
详细问题记录在这篇博客:HDFS集群部署成功但网页无法打开如何解决中。
准备数据目录
namenode数据存放node1的/data/nn
datanode数据存放node1、node2、node3的/data/dn所以应该
在node1节点:
mkdir -p /data/nn
mkdir /data/dn
在node2和node3节点
mkdir -p /data/dn
分发Hadoop文件夹
分发
在node1执行如下命令
cd /export/server (或者当前步骤cd… 就回到server目录)
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
在node2执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
在node3执行,为hadoop配置软链接
ln -s /export/server/hadoop-3.3.4 /export/server/hadoop
配置环境变量
vim /etc/profile
在/etc/profile文件底部追加如下内容:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注:PATH是追加的,不会和之前的冲突
环境变量生效 source /etc/profile
授权为hadoop用户
hadoop部署的准备工作基本完成
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务所以,现在需要对文件权限进行授权。
以root身份,在node1、node2、node3三台服务器上均执行如下命令
su - root
cd /data/
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
ll 查看已经授权给hadoop了

格式化文件系统
前期准备全部完成,现在对整个文件系统执行初始化
1.格式化namenode
确保以hadoop用户执行
su - hadoop
格式化namenode
hadoop namenode -format
2.启动
一键启动hdfs集群
start-dfs.sh
一键关闭hdfs集群
stop-dfs.sh
如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
export/server/hadoop/sbin/start-dfs.sh
export/server/hadoop/sbin/stop-dfs.sh
jps
查看正在运行的java程序·
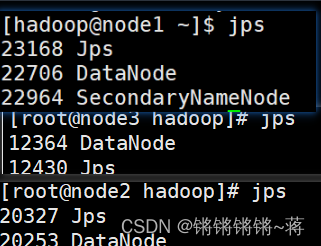
错误排查方法!!
理解start-dfs.ah执行:
在当前机器去启动SecondaryNameNode,并根据core-site.xml的记录启动NameNode
根据workers文件的记录,启动各个机器的datanode
执行脚本不报错,但是进程不存在:
查看日志:
cd /export/server/hadoop/logs
ll--查看有哪些log可以排查
tail -100 hadoop-hadoop-namenode-node3.log--这里是你要检查的日志
清理:
rm -rf /export/server/hadoop/logs/*
rm -rf /data/nn/;rm -rf /data/dn/
出现权限问题时:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
返回上一级 cd …






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结