您现在的位置是:首页 >技术教程 >爬虫学习记录之Python 爬虫实战:某评分网站的Top250的书单详情网站首页技术教程
爬虫学习记录之Python 爬虫实战:某评分网站的Top250的书单详情
【简介】这里我们利用之前所学习的相关模块,爬取网站上top250的书单详情,最终我们将爬取出来的数据持久化存储为表格文件,使用sqlalchemy将持久化数据输入到postgresql数据库中
文章目录
1.爬取页面信息
1.1导入所需模块
在这份代码中,主要利用Python爬虫爬取豆瓣阅读书籍排行榜的前250名,并把每本书的详细信息、封面、网址和书名存储到一个CSV文件中。下面我们来逐步讲解一下代码。
导入需要的库
在代码开头导入了以下库,具体作用如下:
import csv
import os
import random
import re
import requests
from bs4 import BeautifulSoup
from main import user_agent_list, mkdir
csv:用于将数据存储到CSV文件中。
os:用于操作文件和目录。
random:用于随机选择用户代理。
re:用于正则表达式。
requests:用于获取网页内容。
BeautifulSoup:用于解析网页。
user_agent_list, mkdir:这里是我自己写的两个函数,第一个是UA伪装池,第二个是创建文件夹的函数。
1.2定义变量
在代码中,定义了一些必要的变量:
book_detail_list = []
book_img_list = []
book_name_list = []
book_url_list = []
book_all_list = []
book_auther_name = []
book_press_name = []
book_publication_time = []
book_price = []
book_detail_list:用于存储每种书籍的详细信息。
book_img_list:用于存储每种书籍的封面图片地址。
book_name_list:用于存储每种书籍的书名。
book_url_list:用于存储每种书籍的网址。
book_all_list:用于存储所有书籍的详细信息,这个变量将被写入CSV文件中。
book_auther_name:用于存储每种书籍的作者姓名。
book_press_name:用于存储每种书籍的出版社名称。
book_publication_time:用于存储每种书籍的出版时间。
book_price:用于存储每种书籍的价格。
1.3.爬取数据
这里写了一个函数用于处理,外文书籍,有翻译作者的情况,可能导致最后数据持久化存储时,格式不统一的情况。
将所有数据统一成一个格式,如下
"""以下代码:数据长度小于或等于4说无翻译作者
我们将索引为1的插入一个空白
"""
def pre_book_deatil(data):
# 无翻译作者
if len(data) <= 4:
data.insert(1, ' ')
return data
# 有翻译作者
else:
return data
构造URL,每次爬取25本书籍。
随机选择一个用户代理。
发送请求获取HTML文本。
用BeautifulSoup解析HTML文本。
具体实现细节见代码。
if __name__ == '__main__':
file = 'D:/Li Guochun/spider_book/douban_top250/'
mkdir(file)
for i in range(250):
if i % 25 == 0:
url = f'https://book.douban.com/top250?start={i}'
# 添加注释要注意 别添加到字典里面
headers = {
'User-Agent': random.choice(user_agent_list),
}
# text(字符串) content(二进制) json(对象)
html = requests.get(url, headers=headers)
html = html.text
soup = BeautifulSoup(html, 'lxml')
# 爬出书本的详细信息
book_all_detail = soup.find_all('p', {'class': 'pl'})
for book_datail in book_all_detail:
temp = book_datail.text
temp = temp.split('/')
temp = pre_book_deatil(temp)
book_detail_list.append(temp)
# 爬出每本书的封面
book_all_img = soup.find_all('img', {"src": re.compile("subject")})
for book_img in book_all_img:
temp_img = book_img['src']
book_img_list.append(temp_img)
# 爬取每本书的网址和书名
book_all_name_url = soup.find_all('a', href=re.compile('subject'))
for book_name_url in book_all_name_url[1::2]:
temp_name = book_name_url['title']
temp_url = book_name_url['href']
book_name_list.append(temp_name)
book_url_list.append(temp_url)
# 书本信息 按顺序存入列表中
for i in range(len(book_name_list)):
temp = []
temp.append(book_name_list[i])
temp.append(book_url_list[i])
temp.append(book_img_list[i])
for x in book_detail_list[i]:
temp.append(x)
book_all_list.append(temp)
存储数据
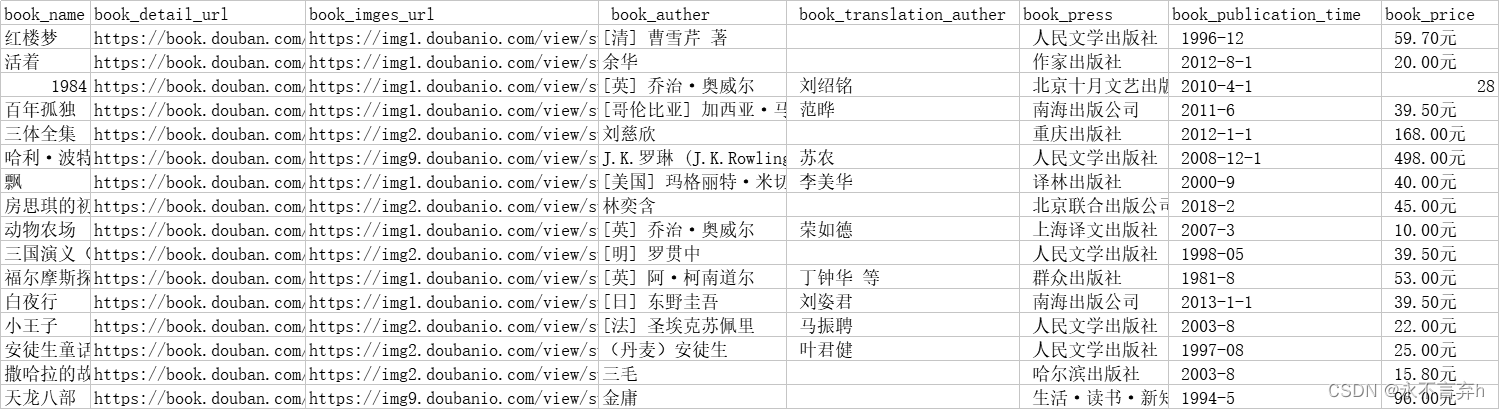
我们将所有数据存储为一个CSV文件,创建一个名为douban_top250.csv的文件。使用csv.writer将数据写入文件。将book_all_list中每个元素的内容存储为CSV文件的一行。
# 讲文本存入表格
# newline='' :结束行约定
with open(f"{file}douban_top250.csv", 'w', newline='', encoding='utf-8') as fp:
writer = csv.writer(fp)
for row in book_all_list:
writer.writerow(row)
1.4 完整代码如下
import csv
import os
import random
import re
import requests
from bs4 import BeautifulSoup
from main import user_agent_list, mkdir
book_detail_list = []
book_img_list = []
book_name_list = []
book_url_list = []
book_all_list = []
book_auther_name = []
book_press_name = []
book_publication_time = []
book_price = []
def pre_book_deatil(data):
# 无翻译作者
if len(data) <= 4:
data.insert(1, ' ')
return data
# 有翻译作者
else:
return data
if __name__ == '__main__':
file = 'D:/Li Guochun/spider_book/douban_top250/'
mkdir(file)
for i in range(250):
if i % 25 == 0:
url = f'https://book.douban.com/top250?start={i}'
# 添加注释要注意 别添加到字典里面
headers = {
'User-Agent': random.choice(user_agent_list),
}
# text(字符串) content(二进制) json(对象)
html = requests.get(url, headers=headers)
html = html.text
soup = BeautifulSoup(html, 'lxml')
# 爬出书本的详细信息
book_all_detail = soup.find_all('p', {'class': 'pl'})
for book_datail in book_all_detail:
temp = book_datail.text
temp = temp.split('/')
temp = pre_book_deatil(temp)
book_detail_list.append(temp)
# 爬出每本书的封面
book_all_img = soup.find_all('img', {"src": re.compile("subject")})
for book_img in book_all_img:
temp_img = book_img['src']
book_img_list.append(temp_img)
# 爬取每本书的网址和书名
book_all_name_url = soup.find_all('a', href=re.compile('subject'))
for book_name_url in book_all_name_url[1::2]:
temp_name = book_name_url['title']
temp_url = book_name_url['href']
book_name_list.append(temp_name)
book_url_list.append(temp_url)
# 书本信息 按顺序存入列表中
for i in range(len(book_name_list)):
temp = []
temp.append(book_name_list[i])
temp.append(book_url_list[i])
temp.append(book_img_list[i])
for x in book_detail_list[i]:
temp.append(x)
book_all_list.append(temp)
# 讲文本存入表格
# newline='' :结束行约定
with open(f"{file}douban_top250.csv", 'w', newline='', encoding='utf-8') as fp:
writer = csv.writer(fp)
for row in book_all_list:
writer.writerow(row)
2.爬取网页图片
这里爬取每本书的封面就比较简单了,上面我们将每本书的图片地址都持久化存储到了csv中,这里我们将表格中的数据读出来,将每个地址遍历一遍。再持久化存储到一个位置中就可以了,图片的本质就是二进制数据,所以我们做数据解析时要使用content 然后再保存,文件后缀为.jpg,即可完成图片的存储。
import random
import requests
from main import user_agent_list, mkdir, _read_book_data
# UA池
book_all_img=[]
if __name__ == '__main__':
file = 'D:/Li Guochun/spider_book/douban_top250/book_img/'
mkdir(file)
book_all_list=_read_book_data()
for book_list in book_all_list:
url = book_list[2]
# 添加注释要注意 别添加到字典里面
headers = {
'User-Agent': random.choice(user_agent_list),
}
html = requests.get(url, headers=headers)
html = html.content
image_name = url.split('/')[-1]
with open(f'{file}{image_name}','wb') as f:
f.write(html)
3.这里我们再将数据信息存储到postgres数据库当中
3.1创建Flask应用
我们首先需要创建一个Flask应用,并且使用SQLAlchemy作为ORM将数据存储到PostgreSQL数据库中。在这里我们需要定义一个Douban_top250类来映射与数据库中的表。具体代码如下:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from main import _read_book_data
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'postgresql://postgres:postgres@localhost:5432/douban_top250'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
class Base(db.Model):
__abstract__ = True
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
class Douban_top250(Base):
__tablename__='douban_top250'
book_name=db.Column(db.String(1024))
book_url=db.Column(db.String(1024))
book_img_url = db.Column(db.String(1024))
book_auther = db.Column(db.String(1024))
book_translation_auther = db.Column(db.String(1024))
book_press = db.Column(db.String(1024))
book_publication_time = db.Column(db.String(1024))
book_price = db.Column(db.String(1024))
3.2创建数据库表
我们在上面的代码中定义了Douban_top250类,来映射与数据库中的表。接着我们需要使用db.create_all()方法来创建这个表。由于我们使用PostgreSQL数据库,所以在创建数据库之前,请将数据库连接地址修改为对应的数据库连接地址。经过修改后执行这两行命令用于创建表:
db.drop_all()
db.create_all()
3.3将数据存储到数据库中
有了数据库表以后,我们就可以将我们获取到的数据存储到数据库中了。我们使用一个for循环遍历获取到的所有书籍信息,将其存储到Douban_top250的实例中,然后将这些实例添加到数据库中。具体的Python代码如下:
if __name__ == '__main__':
with app.app_context():
db.drop_all()
db.create_all()
book_all_list = _read_book_data()
for book_list in book_all_list:
try:
with app.app_context():
book = Douban_top250(book_name=book_list[0],
book_url=book_list[1],
book_img_url=book_list[2],
book_auther=book_list[3],
book_translation_auther=book_list[4],
book_press=book_list[5],
book_publication_time=book_list[6],
book_price=book_list[7])
db.session.add(book)
db.session.commit()
except IndexError:
print(f'{book_list[0]} list index out of range')






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结