您现在的位置是:首页 >学无止境 >计算机视觉的应用7-利用YOLOv5模型启动电脑摄像头进行目标检测网站首页学无止境
计算机视觉的应用7-利用YOLOv5模型启动电脑摄像头进行目标检测
大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用7-利用YOLOv5模型启动电脑摄像头进行目标检测,本文将详细介绍YOLOv5模型的原理,YOLOv5模型的结构,并展示如何利用电脑摄像头进行目标检测。文章将提供样例代码,以帮助读者更好地理解和实践YOLOv5模型。
目录
-
引言
-
YOLOv5模型简介
-
YOLOv5模型原理
3.1. 网络结构
3.2. 损失函数
3.3. 数学原理
-
利用电脑摄像头进行目标检测
4.1. 环境配置
4.2. 样例代码
4.3. 结果展示
-
总结
1. 引言
目标检测是计算机视觉领域的一个重要研究方向,它旨在识别图像中的物体并给出其位置信息。YOLO(You Only Look Once)是一种实时目标检测算法,自2016年提出以来,已经发展到第五代(YOLOv5)。本文将详细介绍YOLOv5模型的原理,并展示如何利用电脑摄像头进行目标检测。
2. YOLOv5模型简介
YOLOv5是YOLO系列的最新版本,相较于前几代,YOLOv5在速度和精度上都有显著提升。YOLOv5采用了一种端到端的深度学习方法,可以在单次前向传播中完成目标检测任务。
3. YOLOv5模型原理
3.1. 网络结构
YOLOv5的网络结构主要包括:CSPDarknet53作为骨干网络,PANet和SPP模块作为特征提取器,以及YOLOv5的检测头。
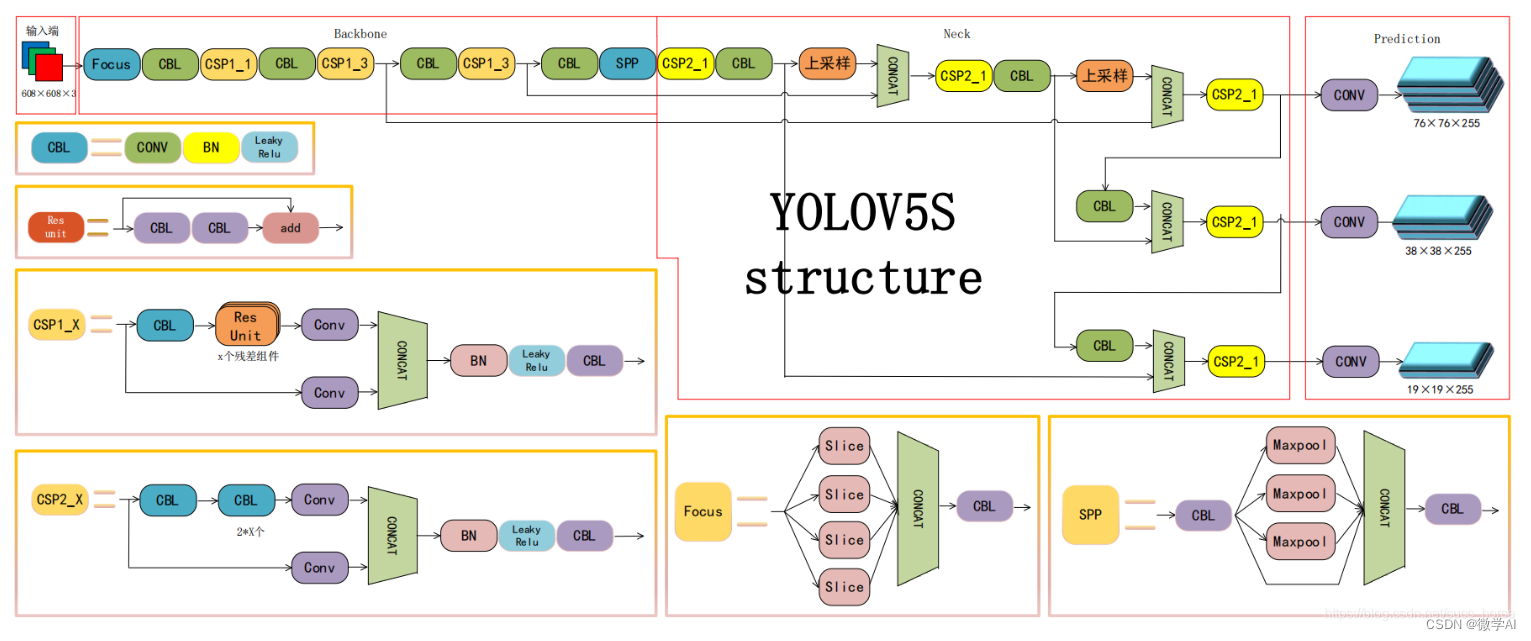
3.1.1. CSPDarknet53
CSPDarknet53是一种轻量级的骨干网络,它采用了CSP(Cross Stage Partial)结构,可以有效地减少参数数量和计算量。CSPDarknet53的网络结构如下:
CSPDarknet53由一系列卷积层、残差块和CSP模块组成。其中,CSP模块将输入特征图分成两部分,一部分进行卷积操作,另一部分直接输出。这种设计可以减少计算量,同时保持特征图的信息流动。
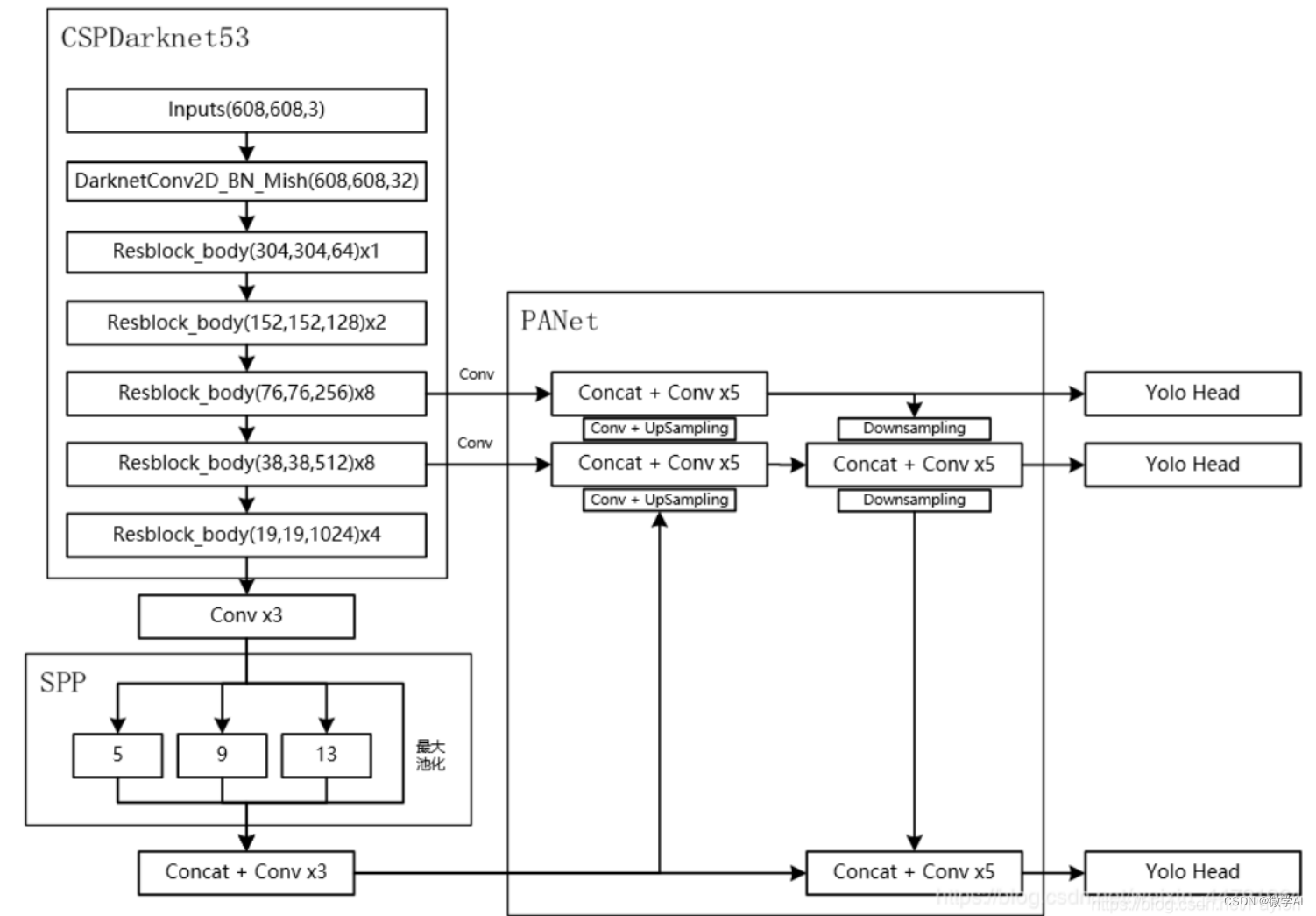
3.1.2. PANet
PANet(Path Aggregation Network)是一种特征金字塔网络,用于解决目标检测中的尺度变化问题。
PANet由一系列卷积层、上采样层和下采样层组成。其中,下采样层用于提取高层次的语义信息,上采样层用于恢复低层次的细节信息。PANet将不同尺度的特征图进行融合,可以有效地提高目标检测的精度。
3.1.3. SPP
SPP(Spatial Pyramid Pooling)是一种空间金字塔池化方法,用于解决目标检测中的尺度变化问题。
SPP由一系列池化层和卷积层组成。SPP将输入特征图分成多个尺度,每个尺度进行不同大小的池化操作,然后将池化结果拼接在一起。这种设计可以使网络对不同尺度的目标具有更好的适应性。
3.1.4. 检测头
YOLOv5的检测头由一系列卷积层和全连接层组成。检测头的输入是特征图,输出是目标的类别、置信度和位置信息。YOLOv5采用了三种不同大小的锚框,每个锚框对应一个预测框。检测头的输出经过解码和非极大值抑制(NMS)处理后,可以得到最终的目标检测结果。
3.2. 损失函数
YOLOv5的损失函数包括分类损失、位置损失和置信度损失。
3.2.1. 分类损失
分类损失采用交叉熵损失,用于衡量模型对目标类的分类准确度。假设有 C C C 个类别, p i p_i pi 表示模型对第 i i i 个类别的预测概率, t i t_i ti 表示第 i i i 个类别的真实标签,则分类损失可以表示为:
L c l s = − 1 N ∑ i = 1 N ∑ c = 1 C t i , c log ( p i , c ) L_{cls} = -frac{1}{N}sum_{i=1}^{N}sum_{c=1}^{C}t_{i,c}log(p_{i,c}) Lcls=−N1i=1∑Nc=1∑Cti,clog(pi,c)
其中, N N N 表示样本数量。
3.2.2. 位置损失
位置损失采用均方误差损失,用于衡量模型对目标位置的预测准确度。假设有 B B B 个锚框, t i , j t_{i,j} ti,j 表示第 i i i 个样本中第 j j j 个锚框的位置信息, p i , j p_{i,j} pi,j 表示模型对第 j j j 个锚框的位置信息的预测值,则位置损失可以表示为:
L l o c = 1 N B ∑ i = 1 N ∑ j = 1 B 1 , j o b j [ λ c o o r d ∑ n ∈ { x , y , w , h } ( t i , j n − p i , j n ) 2 ] L_{loc} = frac{1}{N_B}sum_{i=1}^{N}sum_{j=1}^{B}1_{,j}^{obj}left[lambda_{coord}sum_{nin{x,y,w,h}}(t_{i,j}^{n}-p_{i,j}^{n})^2 ight] Lloc=NB1i=1∑Nj=1∑B1,jobj λcoordn∈{x,y,w,h}∑(ti,jn−pi,jn)2
其中, N B N_B NB 表示样本中包含目标的锚框数量, 1 i , j o b j 1_{i,j}^{obj} 1i,jobj 表示第 i i i 个样本中第 j j j 个锚框包含目标, λ c o o r d lambda_{coord} λcoord 表示位置损失的权重系数。
3.2.3. 置信度损失
置信度损失采用二值交叉熵损失,用于衡量模型对目标存在性的预测准确度。假设有 B B B 个锚框, t i , j o b j t_{i,j}^{obj} ti,jobj 表示第 i i i 个样本中第 j j j 个锚框是否包含目标, t i , j n o o b j t_{i,j}^{noobj} ti,jnoobj 表示第 i i i 个样本中第 j j j 个锚框是否不包含目标, p i , j o b j p_{i,j}^{obj} pi,jobj 表示模型对第 j j j 个锚框是否包含目标的预测值,则置信度损失可以表示为:
L c o n f = 1 N B ∑ i = 1 N ∑ j = 1 B [ 1 i , j o b j ∑ n ∈ { c o n f } ( t i , j n − p i , j n ) 2 + λ n o o b j 1 i , j n o o b j ∑ n ∈ { c o n f } ( t i , j n − p i , j n ) 2 ] L_{conf} = frac{1}{N_B}sum_{i=1}^{N}sum_{j=1}^{B}left[1_{i,j}^{obj}sum_{nin{conf}}(t_{i,j}^{n}-p_{i,j}^{n})^2 + lambda_{noobj}1_{i,j}^{noobj}sum_{nin{conf}}(t_{i,j}^{n}-p_{i,j}^{n})^2 ight] Lconf=NB1i=1∑Nj=1∑B 1i,jobjn∈{conf}∑(ti,jn−pi,jn)2+λnoobj1i,jnoobjn∈{conf}∑(ti,jn−pi,jn)2
其中, λ n o o b j lambda_{noobj} λnoobj 表示不包含目标的锚框的置信度损失的权重系数。
综合上述三种损失,YOLOv5的总损失可以表示为:
L = L c l s + λ c o o r d L l o c + λ c o n f L c o n f L = L_{cls} + lambda_{coord}L_{loc} + lambda_{conf}L_{conf} L=Lcls+λcoordLloc+λconfLconf
其中, λ c o o r d lambda_{coord} λcoord 和 λ c o n f lambda_{conf} λconf 分别表示位置损失和置信度损失的权重系数。
3.3. 数学原理
YOLOv5的数学原理主要包括锚框生成、预测框解码和非极大值抑制(NMS)。
3.3.1. 锚框生成
假设有 k k k 个聚类中心,每个聚类中心对应一个锚框,锚框的宽度和高度分别为 w i w_i wi 和 h i h_i hi。对于一张输入图像,假设其宽度和高度分别为 W W W 和 H H H,则可以生成 W × H × k W imes H imes k W×H×k 个锚框。每个锚框的中心坐标为 ( x , y ) (x, y) (x,y),其中 x x x 和 y y y 的取值范围分别为 [ 0 , W ] [0, W] [0,W] 和 [ 0 , H ] [0, H] [0,H]。锚框的宽度和高度为 w i w_i wi 和 h i h_i hi。
3.3.2. 预测框解码
假设某个锚的中心坐标为 ( x a , y a ) (x_a, y_a) (xa,ya),宽度和高度为 w a w_a wa 和 h a h_a ha,预测框的中心坐为 ( x , y ) (x, y) (x,y),宽度和高度为 w w w 和 h h h。则预测框的坐标可以通过以下公式计算:
x = σ ( t x ) + x a y = σ ( t y ) + y a w = p w e t w h = p h e t h x = sigma(t_x) + x_a \ y = sigma(t_y) + y_a \ w = p_we^{t_w} \ h = p_he^{t_h} x=σ(tx)+xay=σ(ty)+yaw=pwetwh=pheth
其中, σ sigma σ 表示 sigmoid 函数, t x t_x tx、 t y t_y ty、 t w t_w tw 和 t h t_h th 分别表示预测框的偏移量, p w p_w pw 和 p h p_h ph 分别表示锚框的宽度和高度。
3.3.3. 非极大值抑制
非极大值抑制(NMS)是一种常用的目标检测后处理方法,用于去除重叠检测框。具体来说,NMS 的过程如下:
- 对于每个类别,按照置信度从高到低排序。
- 选择置信度最高的框,将其与所有其他框进行重叠度计算。
- 去除与置信度最高的框重叠度大于一定阈值的框。
- 重复上述步骤,直到所有框都被处理。
NMS 的数学原理可以表示为:
S i = { j ∣ j > i , I o U ( b i , b j ) > θ } B = { b i ∣ i ∈ { 1 , 2 , . . . , n } } B ^ = { b i ∣ i ∉ S j , j ∈ S i } S_i = {j | j > i, IoU(b_i, b_j) > heta} \ B = {b_i | i in {1, 2, ..., n}} \ hat{B} = {b_i | i otin S_j, j in S_i} Si={j∣j>i,IoU(bi,bj)>θ}B={bi∣i∈{1,2,...,n}}B^={bi∣i∈/Sj,j∈Si}
其中, S i S_i Si 表示与第 $i 个框重叠度大于阈值 θ heta θ 的所有框的集合, B B B 表示所有框的集合, B ^ hat{B} B^经过 NMS 处理后剩余的框的集合。 I o U ( b i , b j ) IoU(b_i, b_j) IoU(bi,bj) 表示第 i i i 个框和第 j j j 个框的重叠度。
4. 利用电脑摄像头进行目标检测
4.1. 环境配置
为了使用YOLOv5进行目标检测,首先需要配置环境。本文使用的环境为Python 3.7+,需要安装的库包括:torch、torchvision、opencv-python等。
4.2. 样例代码
import cv2
from yolov5 import YOLOv5
# 加载预训练的YOLOv5模型
model = YOLOv5("yolov5s.pt",device='cpu') # 选择模型
# 打开摄像头
cap = cv2.VideoCapture(0)
while True:
# 从摄像头读取帧
ret, frame = cap.read()
if not ret:
break
# 使用YOLOv5进行目标检测
results = model.predict(frame)
# 在帧上绘制检测结果
for *xyxy, conf, cls in results.xyxy[0]:
label = f'{model.model.names[int(cls)]} {conf:.2f}'
cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (0, 0, 255), 2)
cv2.putText(frame, label, (int(xyxy[0]), int(xyxy[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2)
# 显示帧
cv2.imshow('YOLOv5 Real-time Object Detection', frame)
# 按'q'键退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源并关闭窗口
cap.release()
cv2.destroyAllWindows()
4.3. 结果展示
运行上述代码,可以实时查看摄像头画面中的目标检测结果。YOLOv5能够准确识别出各种物体,并给出其位置信息。
5. 总结
本文到这里就结束了,其中主要详细介绍了YOLOv5模型的原理,并展示了如何利用电脑摄像头进行目标检测。YOLOv5在速度和精度上的优势使其在实时目标检测任务中具有广泛的应用前景。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结