您现在的位置是:首页 >技术杂谈 >基于 Flink CDC 的现代数据栈实践网站首页技术杂谈
基于 Flink CDC 的现代数据栈实践
摘要:本文整理自阿里云技术专家,Apache Flink PMC Member & Committer, Flink CDC Maintainer 徐榜江和阿里云高级研发工程师,Apache Flink Contributor & Flink CDC Maintainer 阮航,在 Flink Forward Asia 2022 数据集成专场的分享。本篇内容主要分为四个部分:
- 深入解读 Flink CDC 2.3 版本
- 基于 Flink CDC 构建现代数据栈
- 阿里云内部实践和改进
- Demo & 未来规划
一、深入解读 Flink CDC 2.3 版本
1.1 Flink CDC

首先介绍一下 Flink CDC 技术。Flink CDC 是基于数据库的日志 CDC 技术,实现了全增量一体化读取的数据集成框架。配合 Flink 优秀的管道能力和丰富的上下游生态,Flink CDC 可以高效实现海量数据的实时集成。
如上图所示,在数据库中,我们有历史的全量数据,也有实时的增量数据。比如上游有业务系统在源源不断实时写入数据,Flink CDC 技术的能力就是将全量数据和增量数据无缝集成到 Flink 引擎中,为下游应用提供实时的一致性快照。
1.2 Flink CDC 2.3 基本介绍

2022 年 11 月 10 日,Flink CDC 社区发布了 2.3 版本。 此版本的贡献者共有 49 位,解决了 126 个 issue,合并的 PR 达到 133 个;合并的 commits 达到 173 个。
在 Flink CDC 2.3 版本中,我们按代码的贡献模块进行了划分。其中 MySQL 占比最高达到了 24%,Oracle 占 15%,MongoDB 占 7%,TiDB 占 7%,包含全量框架的 Base 模块占比 11%。此外文档的贡献也占有 22%的比例,其中包括新增了很多中文文档和视频教程,这些文档的目的就是为了帮助用户特别是中文用户更好地使用 Flink CDC。
1.3 Flink CDC 2.3 技术改进

以下是 Flink CDC 2.3 版本中主要新特性和改进,包括:
- 支持了 Db2 数据源。
- Oracle CDC 支持增量快照。
- MongoDB CDC 支持增量快照。
- MySQL CDC 支持指定位点。
- MySQL CDC 性能优化。
- OceanBase CDC 支持了 OceanBase 的全部数据类型。
- 兼容 Flink 1.15 & 1.16 两个大版本。
- 提供中文文档及视频教程支持。
1.4 Flink CDC 2.3 核心特性解读

在 Flink CDC 2.3 版本中,有四大核心特性值得深入介绍:
- 新增 Db2 数据源支持。
- MySQL CDC 稳定性提升。
- Oracle CDC 支持增量快照读取。
- MongoDB CDC 支持增量快照读取。
下面将为大家进行详细讲解。
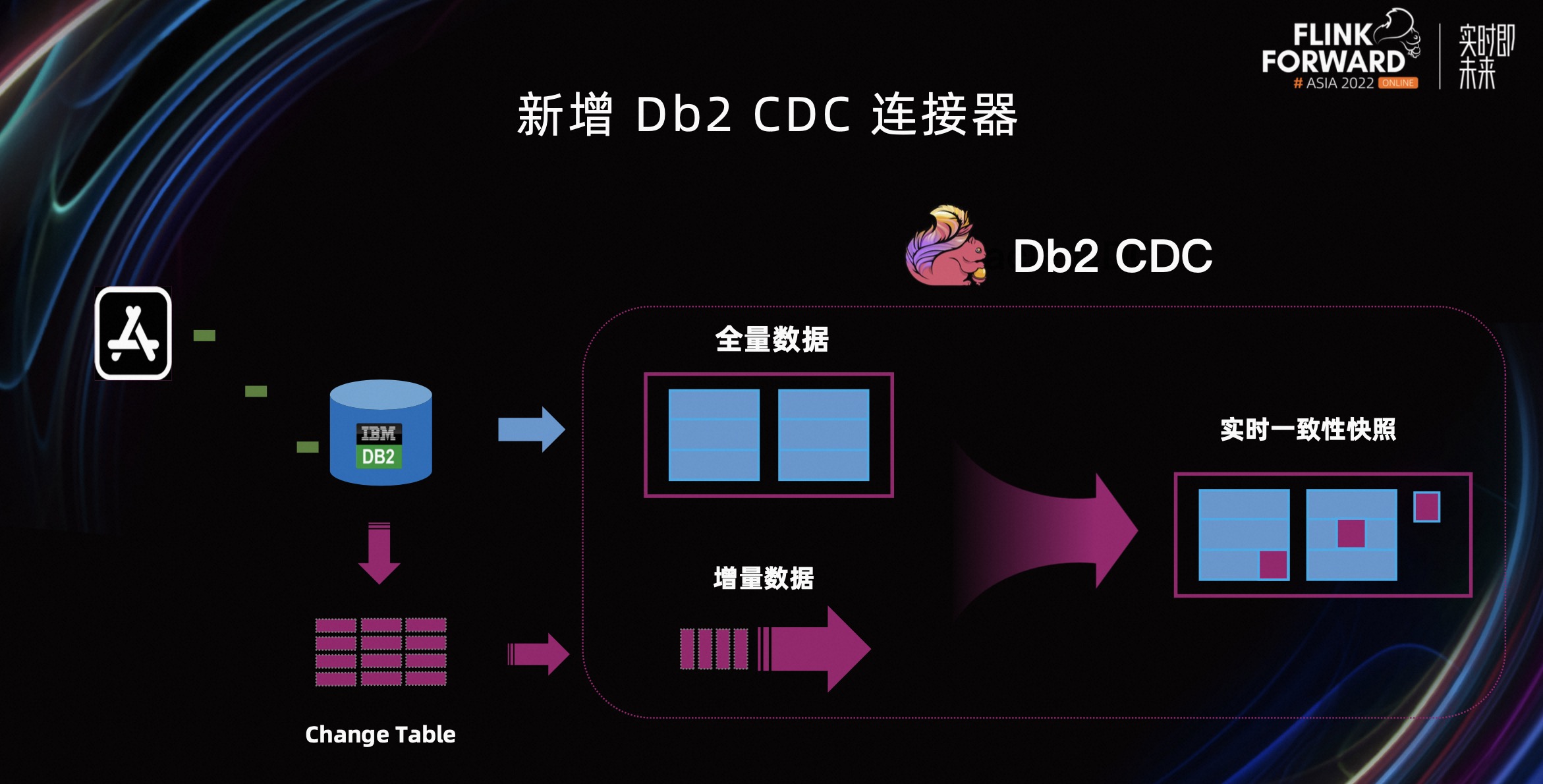
第一部分,Db2 CDC 连接器。Db2 数据库在国内外都有很多用户在使用,社区用户反馈的声音也比较大,所以在 Flink CDC 2.3 中版本中社区支持了 Db2。
Db2 CDC 的全量数据是通过 SQL 查询的方式拉取;而增量数据是当表开启了 Capture Mode 的时候,Db2 会把增量数据的 Changelog 写到 Change Table 里,在需要增量数据时,从 Change Table 中拉取 Changelog 即可。这样 Db2 CDC 就实现了全量数据和增量数据的一致性读取,在下游也提供了实时的一致性快照。
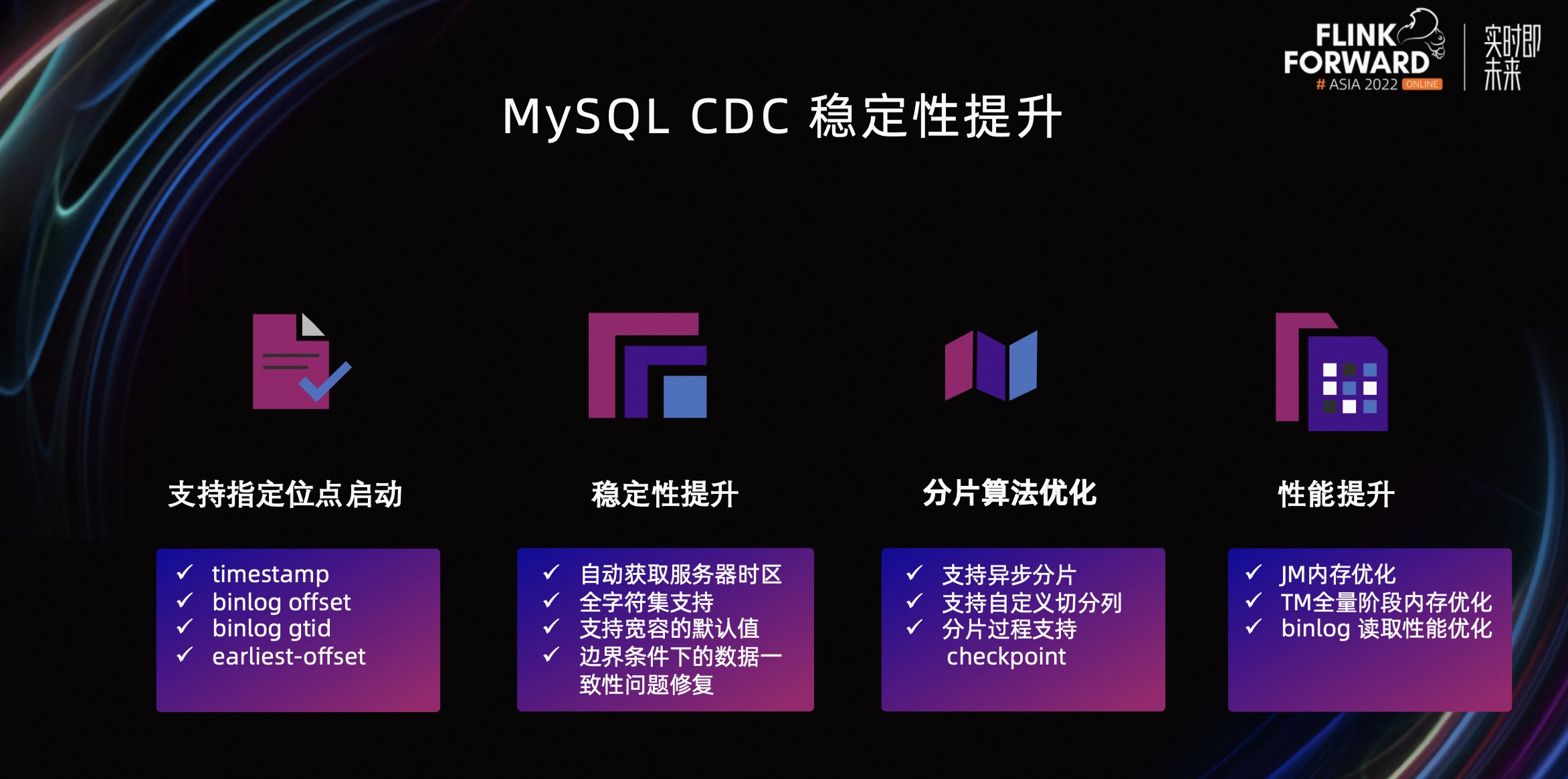
第二部分,MySQL CDC 稳定性提升,对它的提升主要包括以下四个方面。
- 支持指定位点启动,包括 timestamp、binlog offset、binlog gtid、earliest-offset 这这几种方式来指定位点。
- 稳定性提升,包括自动获取服务器时区;支持全字符集;支持解析更宽容的默认值;边界条件下的数据一致性问题修复等改进。
- 分片算法优化,包括支持异步分片;支持自定义切分列;分片过程支持 Checkpoint。
- 性能提升,包括 JM 内存优化;TM 全量阶段内存优化;Binlog 读取性能优化。
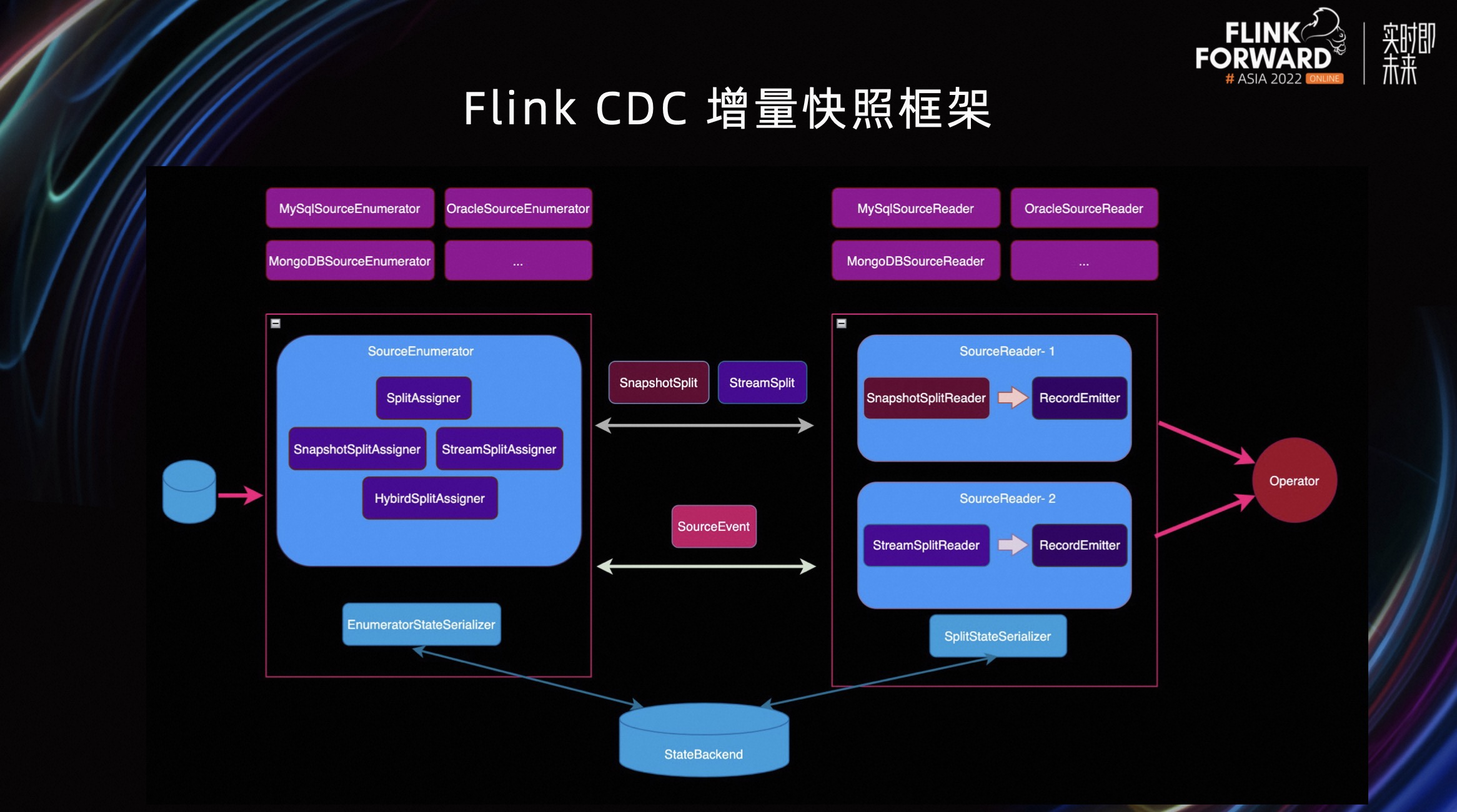
除了这两大核心特性,另外两个重点 Feature 就是 Oracle CDC 和 MongoDB CDC 均对接到了 Flink CDC 的增量快照框架。
Flink CDC 的增量快照框架的来源是 Flink CDC 2.0 版本提供的一个增量快照算法,它提供了无所读取、并发读取、断点续传三个核心特性。 但当时只支持 MySQL CDC Connector 接入,其他 Connector 接入成本较高,所以社区就把这套算法抽象成了一个框架,叫 Flink CDC 的增量快照框架,方便其他 Connector 接入。之后在 Flink CDC 2.3 版本中,社区便接入了 Oracle 和 MongoDB 两个数据源。

现在,Oracle 和 MongoDB 都支持在全量阶段进行并行读取。全量读取完之后,通过无所一致性切换到增量阶段。 全量到增量的切换是全自动的,不需要人为干预。
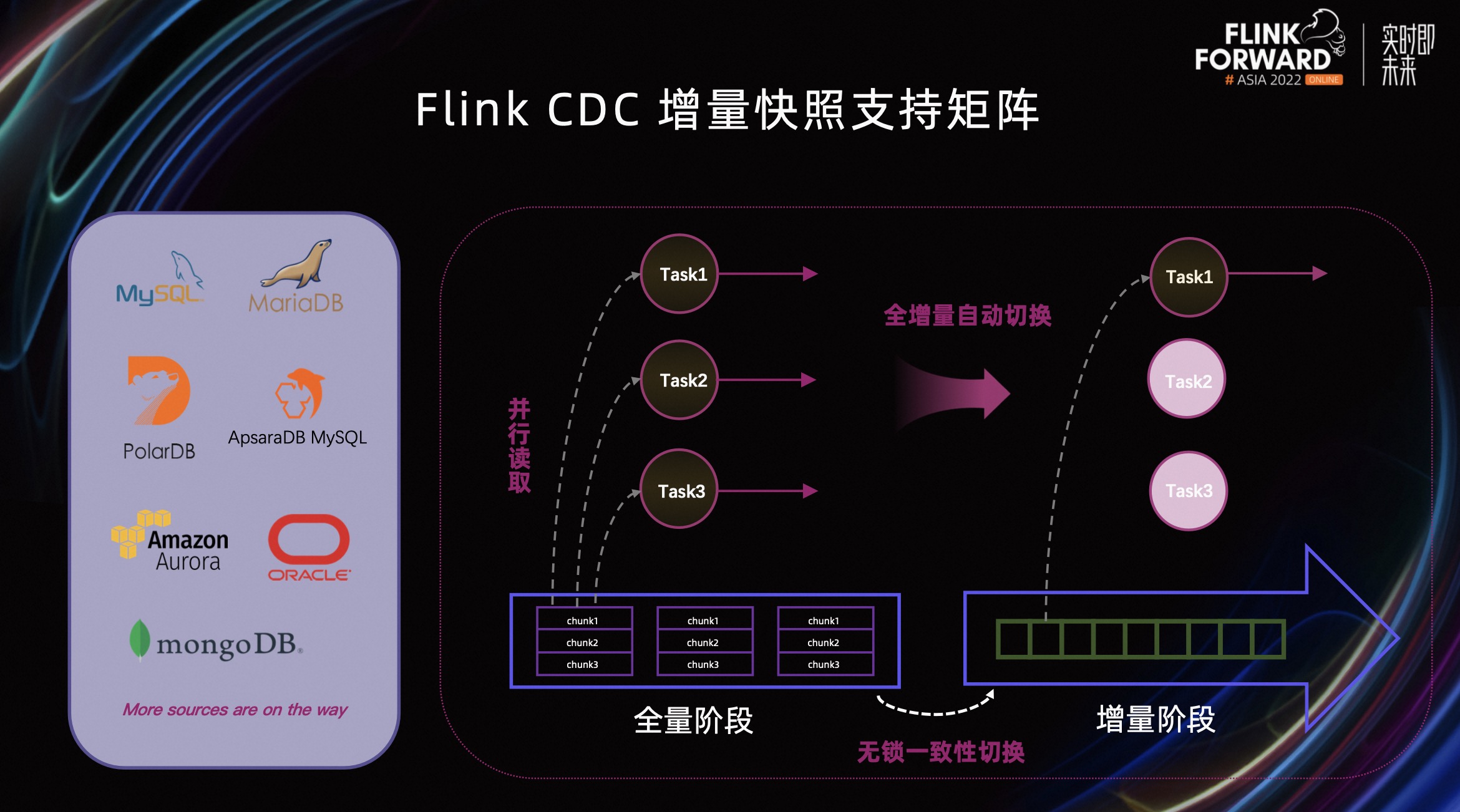
在接入 Oracle CDC 和 MongoDB CDC 到增量快照框架之后,Flink CDC 的增量快照框架支持的矩阵就变得相当丰富,覆盖了包括 MySQL、MariaDB、PoloDB、ORACLE、MongoDB 等数据源。
二、基于 Flink CDC 构建现代数据栈
2.1 现代数据栈(Modern Data Stack)
数据栈这个概念在最近几年比较火热,特别是在海外数据集成的行业或者圈子里。首先看一下数据栈相关的两个概念。
数据栈是一组对原始数据进行采集、转换和存储(ETL)的技术或工具的组合,这些工具可以让数据工程师和分析师能够提取和清洗数据,将原始数据转换为有价值的数据并存储,然后根据需要进行分析。
现代数据栈是在数据栈的基础上,使用创新的(如 ELT)或基于云上数仓/湖的工具或技术的组合,现代数据栈基于云上构建的特点,具备传统数据栈很难具备的弹性和扩容优势,现代数据栈层次清晰有利于垂直领域的工具形成标准的 SaaS 服务,而 SaaS 服务极大地降低了运维和管理成本。
2.2 现代数据栈组件

在刚刚介绍现在数据栈概念的时候,提到了两个词,ETL 和 ELT。
ETL 是经典数据集成里的一个处理过程,即采集、转换、存储。以 Flink CDC 为例,在传统的数据栈里做 ETL。Flink CDC 做采集的时候,如果还需要进一步转换,就通过 Flink 来做,然后 load 到下游存储。
转换到现代数据栈 ELT 的架构。还以 Flink CDC 为例,它负责采集和 load,即帮助数据从数据源采集并 load 到存储里,这个存储包括 Iceberg、Hudi 等等。而转换一般都围绕在数据湖或者数据仓库上,所以可以用其他工具做一些转换,从而把 E 和 L 提取出来。
2.3 开源现代数据栈

上图是 State of Data Engineering 2022 map,在这个图里可以发现,有很多和现代数据栈或者数据集成领域相关的技术和组件。比如 Airbyte、Fivetran 等等,既有开源的,也有闭源的。

上图是一个典型的开源现代数据栈,可以发现这个表里每一行都代表一个垂直领域。比如我们要做数仓,就可以用 rudderstack、Airbyte 等开源数据集成工具来做等等。
2.4 基于 Flink CDC 的现代数据栈

如上图所示,Flink CDC 是一个非常好的数据集成框架,它目前已经支持了 MySQL、MongoDB、Db2 等丰富的数据源,用户可以针对自己的需求选择并对数据进行加工。
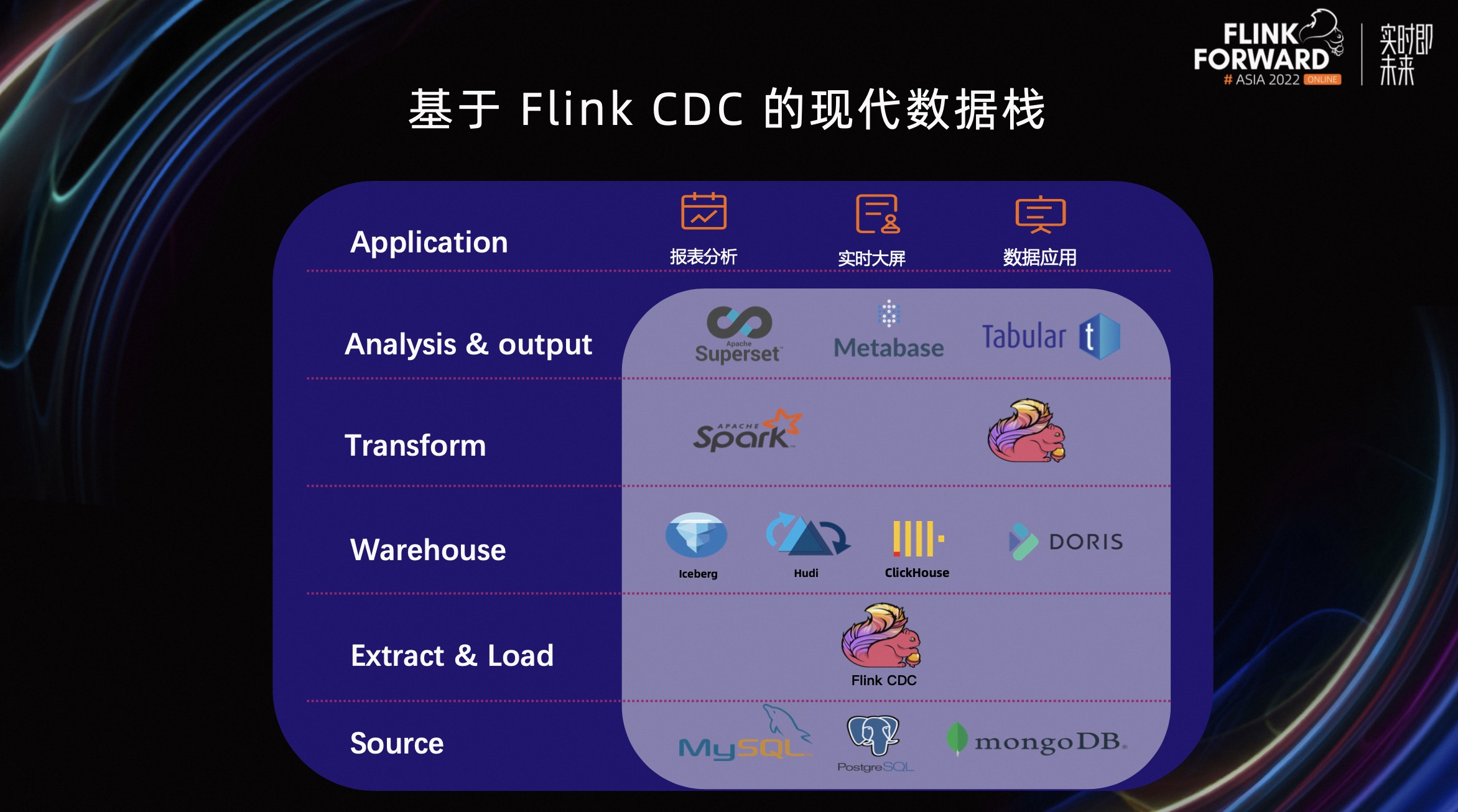
那么如何基于 Flink CDC 构建现代数据栈呢?如上图所示,数据栈的最底层是数据源,比如 MySQL、PG、Oracle、MongoDB 等等。EL 由 Flink CDC 来做,它负责从数据源里提取数据,load 到经典的数据仓库或者数据湖这层。
Transformation 通过 Flink、Spark 在数仓之上做分析,然后通过 Superset、Metabase、Tabular 等等 BI 工具,对其结果进一步加工。加工完之后,最上层是面向终端用户的,比如各种应用的报表分析、实时大屏、数据应用,这就构成了一个基于 Flink CDC 的现代数据栈。
三、阿里云内部实践和改进
3.1 常见业务场景的实践

场景一,海量 CDC 数据实时 ETL。通过 Flink CDC 表实时读取源表修改,用在实时作业里进行一些计算和处理,最终写入到下游数据仓库中。比如使用 Flink CDC 源表和其他实时数据流进行 Join,打宽业务表并写入下游数据库中。在这样的使用场景下,同一个作业可能会同时访问数据库中的多张表,经常一个作业包含多个 CDC 表,同时持有多个 Binlog Client。
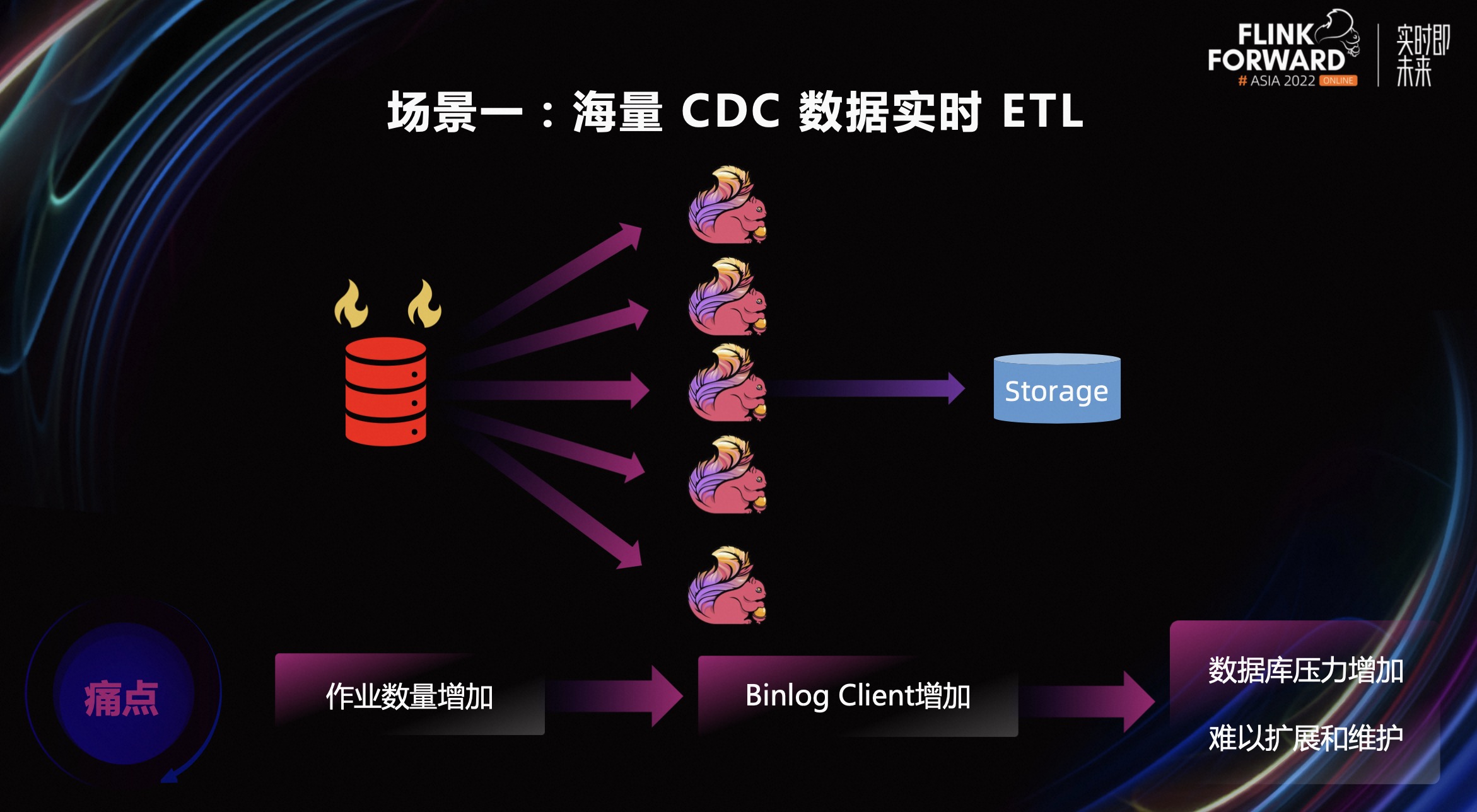
随着业务规模的不断扩展,开发的作业数量也会持续增加。但每个作业的 Binlog Client 是独占的,无法进行复用,这会使连接到数据库时 Binlog Client 也持续增加。最终导致数据库侧的压力持续增加,甚至影响数据库上承担的线上业务。

场景二,日志数据实时入湖入仓。用户通常会将日志先汇聚到消息队列中,比如 Kafka,再从 Kafka 中消费进行分析、归档,比如通过 Flink 实时消费日志数据后,归档到下游的数据仓库或者数据湖中。

在这样的场景下,用户开发一个作业的时间会比较长,需要的人力也会很多。首先需要手动创建好下游的存储表,在开发 SQL 作业时,需要编写对应的 Source 表,Sink 表的 CREATE TABLE 语句,参照不同连接器的需求,自行定义好表的 Schema 和需要使用的配置,并且这样的作业无法同步 Schema 的变更。
以上图左侧为例,实现了从 Kafka_monitor_log 同步到 Hudi_monitor_log 的 Hudi 表的作业编写。首先要通过 CRATE TABLE 语句创建一张 Kafka 表,并定义好表的三个字段 id、event、level,以及 WITH 参数里表的一些配置。同样,在 Hudi 表的定义时还要进行这样重复的操作。
3.2 常见业务场景的扩展和改进
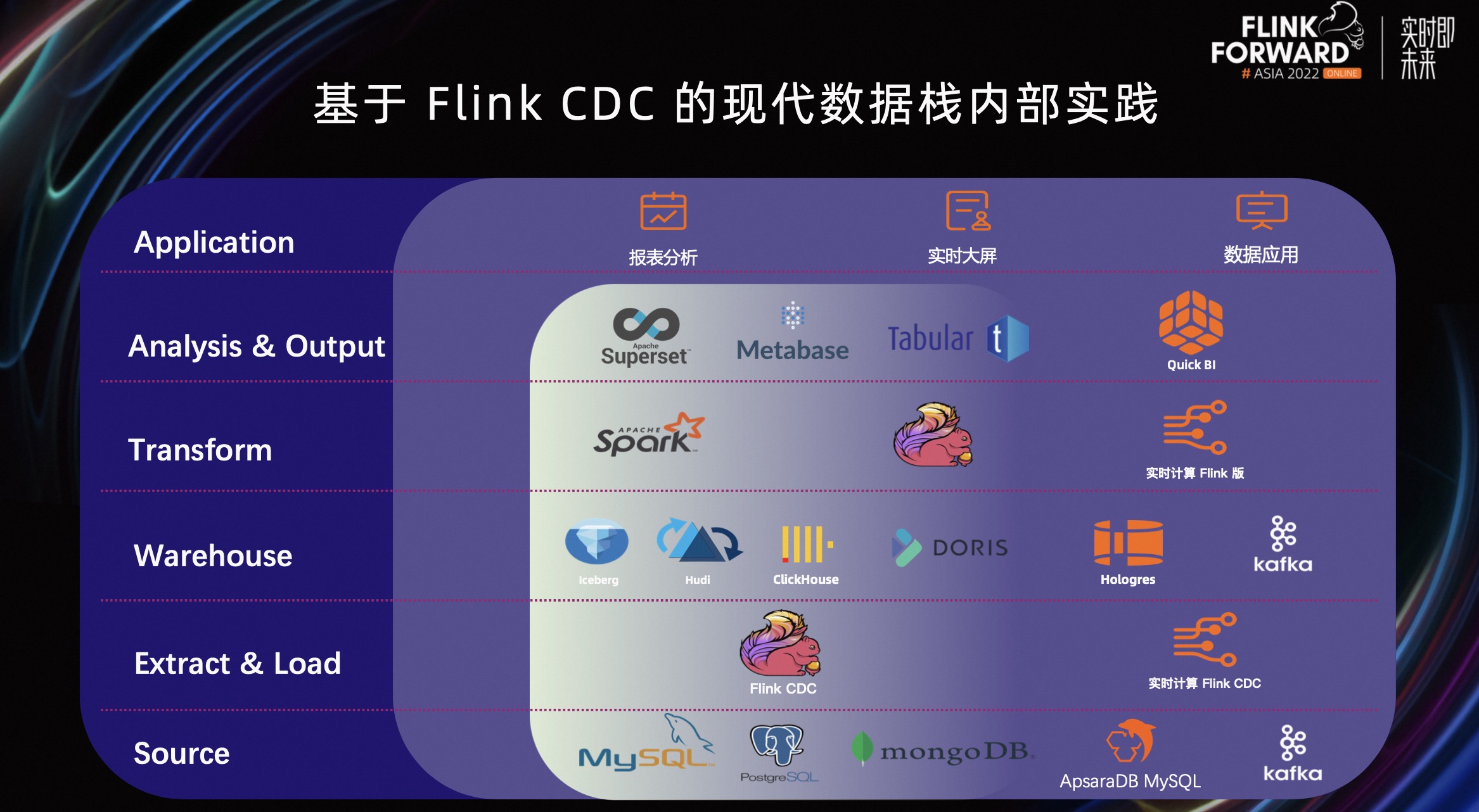
上图是阿里云内部基于 Flink CDC 的现代数据栈。除了前文介绍过的对开源部分的支持,阿里云内部还进行了一些额外的改进和扩展。
数据源方面,我们不仅支持数据库,还支持了 Kafka 消息队列,并且在采集层可以在实时计算 Flink 版中,启动 Flink CDC 作业进行采集,将数据采集到数据仓库中。除了常见的开源仓库对接,也提供了企业级实时数仓 Hologress 和消息队列 Kafka 的支持。
在计算层,可以在实时计算 Flink 版中进行 SQL 作业的开发和数据分析处理。在分析层,可以借助各种 BI 工具数据分析,最终对接终端完成报表分析、实时大屏,或其他数据应用。
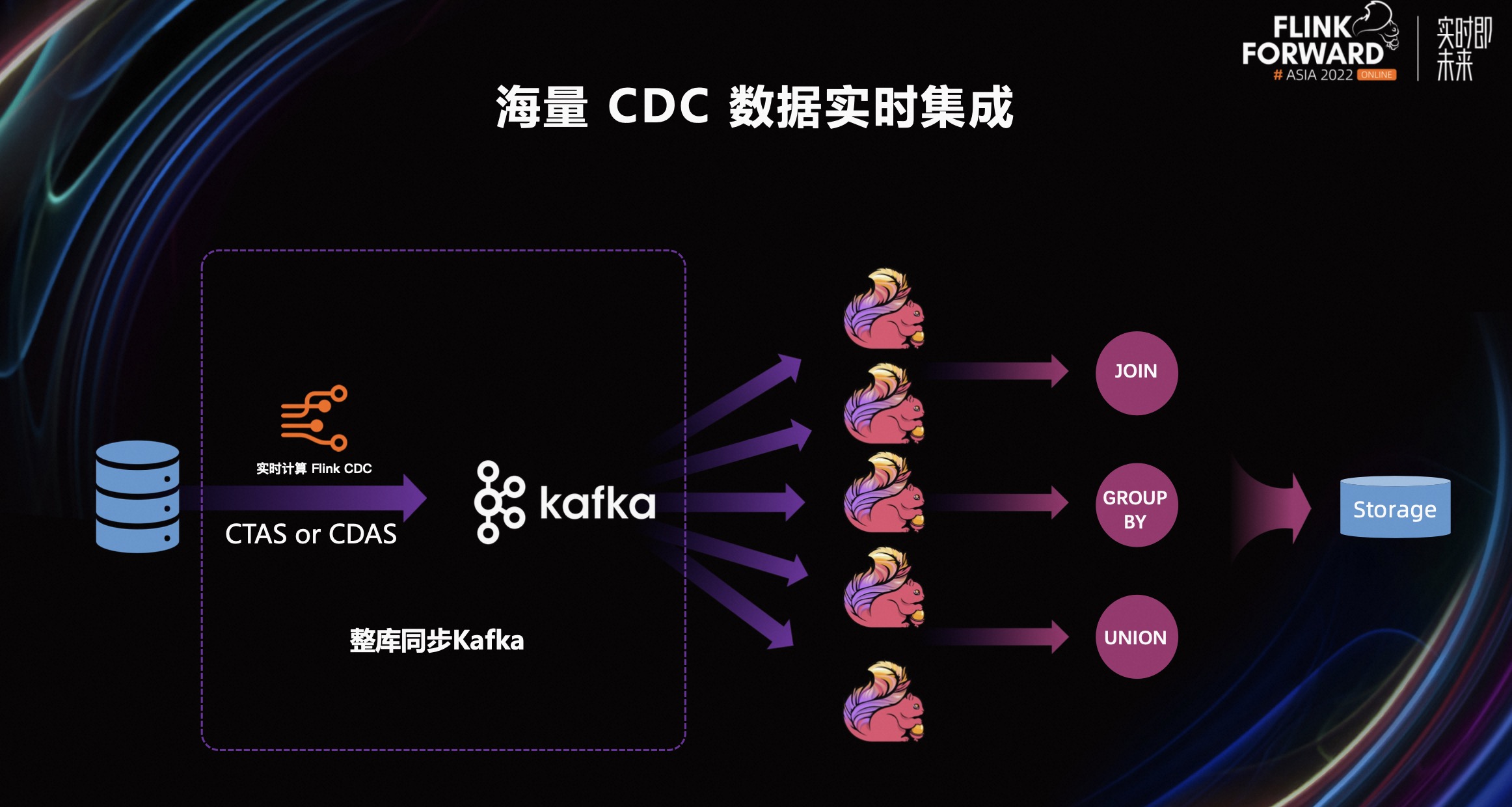
借助我们内部基于 Flink CDC 的现代数据栈,解决了数据库 Flink CDC 数据集成和日志数据集成两大场景的痛点。
第一个场景是海量 CDC 数据的实时集成场景。在这个场景中,为了解决数据库压力过大的问题,我们通过提供 Kafka JSON Catalog,结合 CTAS、CDAS 的整库同步语法,将上游的数据库的数据同步到 Kafka 中来进行解耦。将数据库中的热点表同步到 Kafka 后,后续使用到该表的作业可以直接消费对应的 Kafka Topic,从而降低了源头数据库的压力。
在 CDAS 这样一个整库同步的过程中,可以对 Binlog Client 进行复用,这样 Binlog Client 连接就不再随着业务的扩展而增加,同时降低了 Binlog 的复制压力。另外,这样一个整库同步的作业,启动时只会进行一次全量的数据同步,不会每次作业启动都进行一次全增量的同步,降低了全量阶段产生的数据库查询压力。
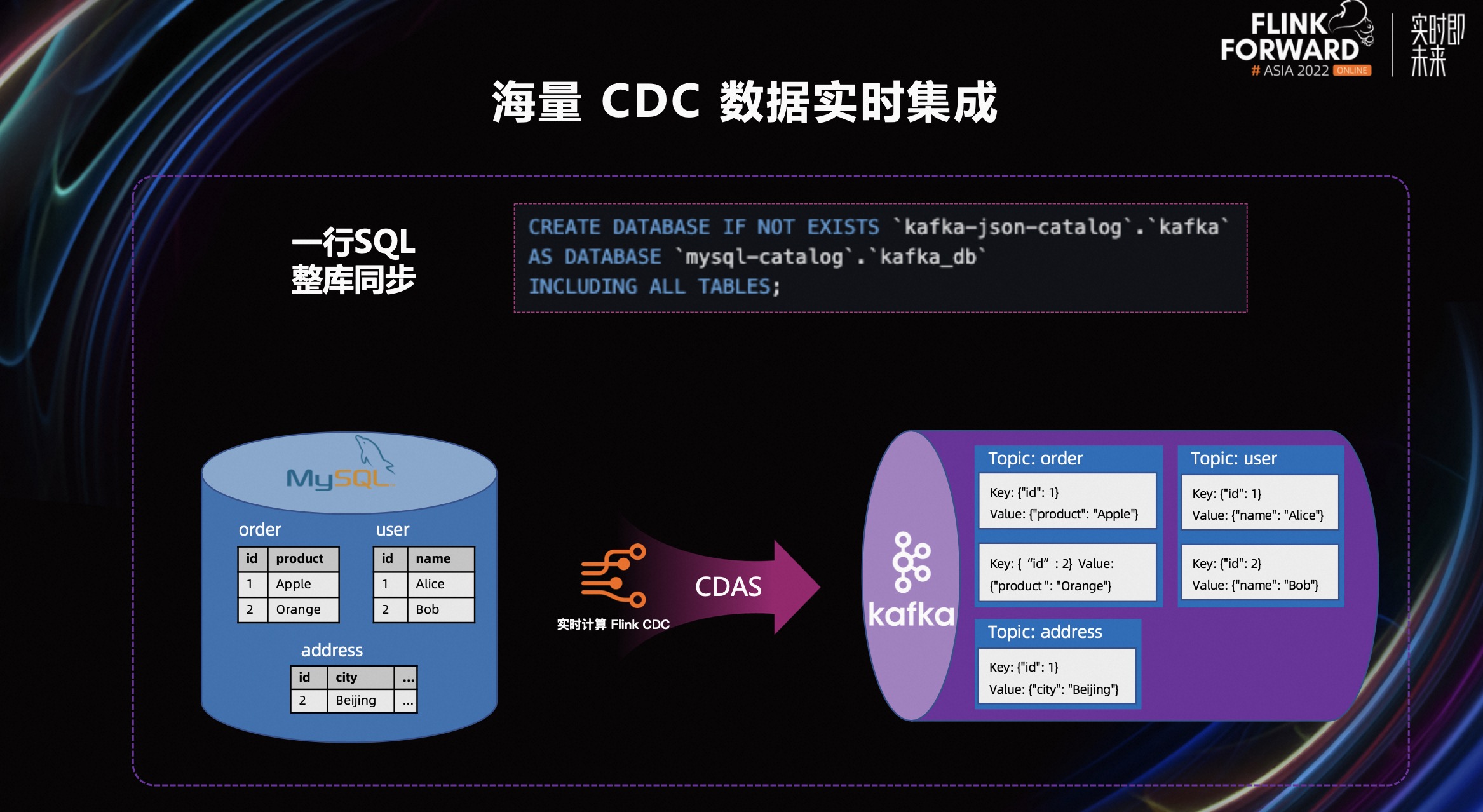
开发这样一个整库同步作业只需要如上图所示。注册 Kafka JSON Catalog 和 MySQL Catalog 后,只需要简单的一条 SQL 就可以完成同步任务开发,节省了开发者的开发时间。
如上图右侧展示,MySQL 数据库里包含 Order、User、Address 三张数据表。在启动了 CDAS 整库同步作业后,Kafka JSON Catalog 会自动在 Kafka 集群里,创建 Order、User、Address 三个 Topic,然后进行 CDAS 作业的启动,把数据同步到对应的 Topic 中。
在存储时会以 JSON 格式存储数据。在 key 部分会存储对应的数据表主键,在 value 部分会存储除了主键以外的其他字段。后续的作业可以直接使用 Kafka 集群里的 Kafka 表完成作业的分析和计算。

第二个场景是日志数据实时入湖入仓。通过 Kafka JSON Catalog 可以简单的使用 CTAS 或 CDAS 的整库同步语法同步数据到数据仓库,如数据湖 Hudi,这个过程极大地简化日志数据实时入湖入仓的开发难度,同时实现上我们也对 Kafka Source 进行了合并优化(Source Merge),减少了资源的使用。
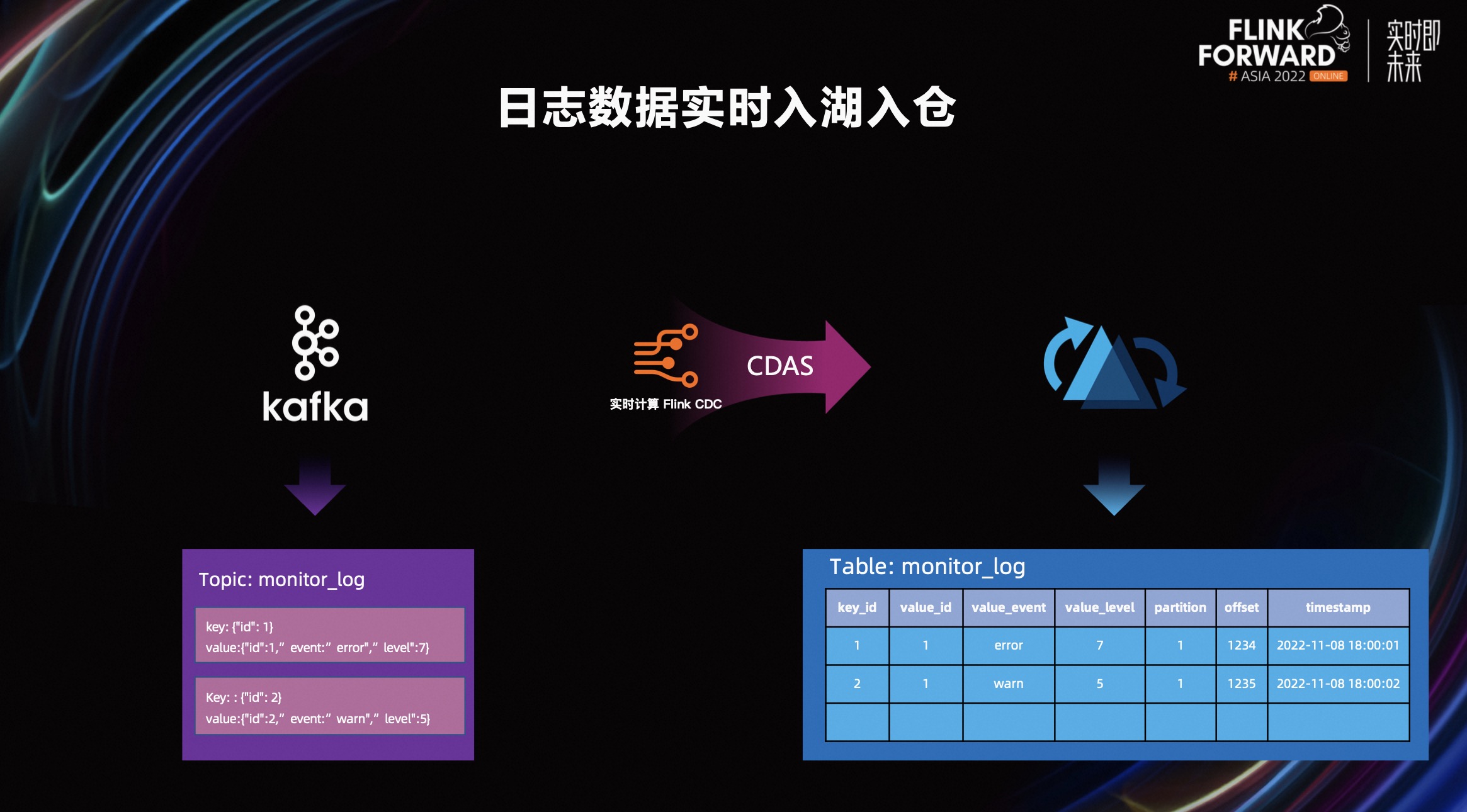
上图展示了从 Kafka_monitor_log 同步日志数据到 Hudi 数据湖中的过程。在 Kafka_monitor_log 的 Topic 中,key 部分存在一个字段 id,value 部分有三个字段 id,event、level。同步作业会自动解析 Kafka 字段,并在 Hudi 中完成建表的操作,然后启动作业进行同步。
为了防止字段产生冲突,Kafka JSON Catalog 在解析 Schema 时,会在 key 的字段名前加 key_ 的前缀,在 value 字段添加 value_的前缀。同时会添加 Kafka 的元数据列,partition,offset 和 timestamp。

这样一个同步作业开发,只需要像上图右侧这样写一条 SQL,即 CREATE TABLE AS 语句,定义好从 Kafka 的哪张表,同步到下游 Hudi 数据湖中的哪张表即可。作业启动后,会自动在 Hudi 中创建表,并且会同步 Kafka 中的变化字段到 Hudi。极大降低了用户的开发难度和开发时间。
四、Demo & 未来规划
4.1 Demo

下面针对之前提到的两个用户痛点场景进行 demo 展示,第一个 demo 主要展示:如何将数据库整库同步到 Kafka 进行数据打宽,最终处理写入到 Hudi 数据湖中。第二个 demo 主要展示:Kafka 中的日志数据如何整库同步到 Hudi 数据湖中。
Demo 演示:基于 Flink CDC 的现代数据栈实践 - Demo_哔哩哔哩_bilibili
4.2 未来规划
未来 Flink CDC 2.4 版本在社区中的规划如下:
- 支持 Batch 模式,优化全量阶段的读取性能。
- 支持限流配置,减少全量阶段对数据库的影响。
- 提供更丰富的监控指标,如已处理的表数量,不同类型变更记录的处理数量等。
- 后续也会持续提升 CDC Connector 的易用性和性能。如增量框架在全量阶段结束后的 reader 资源释放,更多的数据源应用增量快照框架等。
更多内容

活动推荐
阿里云基于 Apache Flink 构建的企业级产品-实时计算 Flink 版现开启活动:
0 元试用 实时计算 Flink 版(5000CU*小时,3 个月内)
了解活动详情:阿里云免费试用 - 阿里云







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结