您现在的位置是:首页 >学无止境 >经典多模态模型网站首页学无止境
经典多模态模型
整点传统多模态学习。
下游任务
在讲模型之前,我们先说说 传统多模态任务是下游任务。
图文检索(Image Text Retrieval)
里面包含图像到文本检索,文本到图像检索。给定一个数据库,搜索到ground truth的图像文本对。因为是检索,所以衡量指标是召回率(recall)。
视觉问答(VQA)
给定一个问题,给定一个图片,看是否能根据图片回答问题。
闭集VQA:分类问题,固定答案set从中选答案。multi answer classification。
开集VQA:文本生成任务
视觉推理(Visual Reasoning)
预测一个文本能否同时描述一对图片。二分类问题。
视觉蕴含(Visual Entailment)
给定一个假设,看是否能推理出前提。如果能推理出来则说明是蕴含entailment的关系,推不出来contradictory,无法判断neutral。所以可以说是一个三分类问题。
我们可以把传统多模态模型分成两类,一类是只用了transformer Encoder,一类是既用了 transformer encoder也用了 transformer decoder
只用Transformer Encoder的模型
ViLT
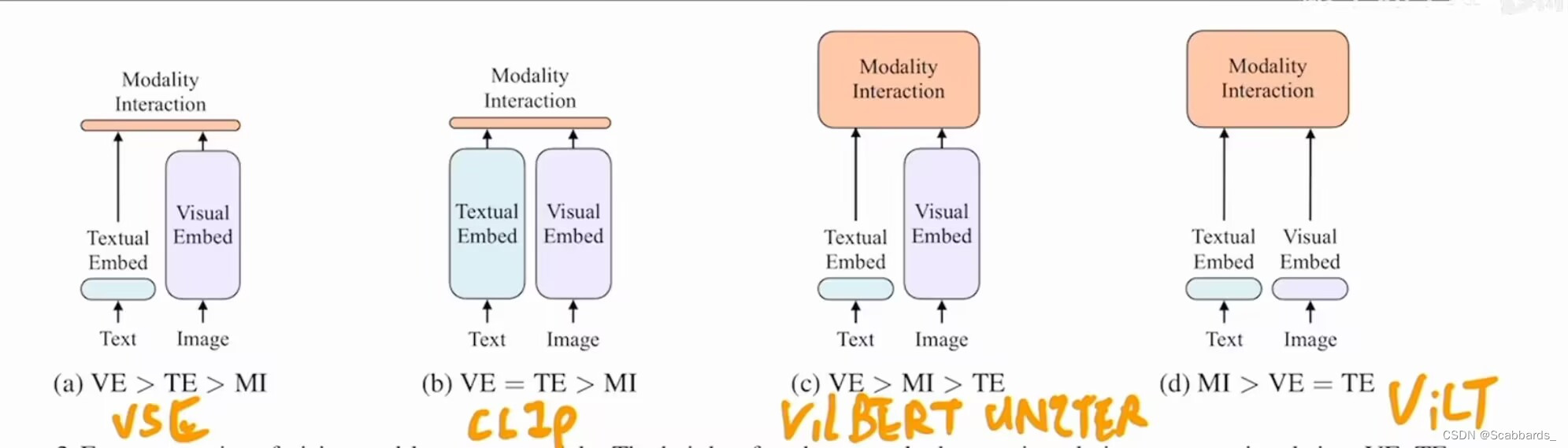
主要贡献
移除预训练的目标检测器,换成可学习的Patch Embedding Layer
vit基于patch的视觉特征和之前基于bounding box的视觉特征区别不大,这样就可以把超大的预训练好的目标检测器换成patch embedding
缺点
1. 性能不够高,简单而言视觉模型要大于文本模型效果才能好
2. 推理时间快,训练时间非常慢
因此,视觉模型要大于文本模型,同时模态之间的融合模型也要尽可能大 ,好的目标函数有ITC,ITM和MLM
Clip
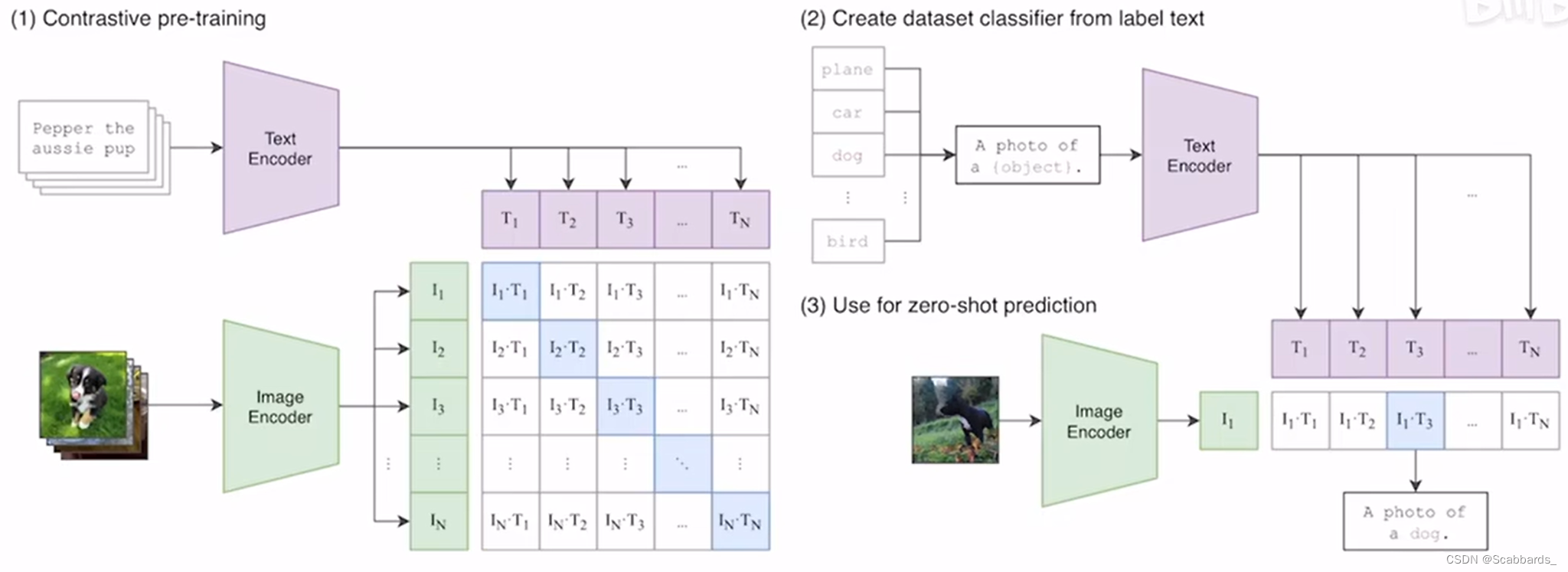
Clip是典型的双塔模型,有两个model,一个对应文本一个对于视觉
clip采用了对比学习,因为这样可以有更小的计算量。其中正样本在对角线上,拿图片的特征和文本的特征去做cosin similarity,把和图像最相似的文本特征所对应的句子挑出来,从而完成分类任务。对于图像文本匹配和图像文本检索效果相当好。但是对VQA,VR,VE效果就不好了。
image encoder 可以是resnet和vit
主要贡献
1)跨模态表示学习
CLIP模型通过使用Transformer的encoder部分,将图像和文本编码到一个共享的特征空间中。这使得CLIP模型能够学习到图像和文本之间的语义对齐,即使在不同的模态下也能够理解它们之间的关系。这种跨模态的表示学习为图像和文本的相互理解提供了强大的基础。
2)zeroshot
clip的一大亮点是zeroshot,而few shot 可以用于一定的专业知识的领域
-
Zero-shot(零样本)学习:在零样本学习中,模型可以在没有为特定任务进行显式训练的情况下进行推理和预测。它使用先前学到的知识和通用的背景信息来解决新任务。这意味着模型可以通过理解问题的语义或结构等特征,从而进行推理和预测。通常情况下,模型需要通过阅读说明或示例来理解新任务,并利用其先前的知识进行预测。零样本学习是一种在新领域中进行迁移学习的技术。
-
Few-shot(少样本)学习:在少样本学习中,模型需要利用少量的训练样本来学习新任务。这个数量可以是几个样本到几十个样本,通常远远少于传统机器学习中需要的大量训练样本。在少样本学习中,模型需要能够从有限的样本中推理和泛化,以便在新任务中取得良好的性能。为了提高泛化能力,少样本学习通常使用技术如元学习(meta-learning)、模型参数共享和数据增强等。
q:prompt* template 转换句子所有句子的前缀都是一样的吗?
a: -是
clip优势:
1.摆脱 categorical label的限制
2.支持非常广的domain
"domain"(领域)通常指的是数据集或问题的特定领域或上下文。一个领域可以由具有共同特征、数据分布或任务定义的数据样本组成。
深度学习模型通常需要在特定领域中进行训练和应用,因为不同领域的数据具有不同的特征和分布。模型在一个领域中的性能可能会因为领域的变化而下降,这被称为领域间的"领域迁移"问题。因此,了解和理解特定领域的特征对于开发有效的深度学习模型非常重要。
在领域适应(domain adaptation)和迁移学习(transfer learning)中,"domain"用于描述不同数据集或任务之间的关系。通过在一个领域上进行训练,并将模型迁移到另一个相关领域,可以实现对新领域中的数据进行有效预测。
自监督
自监督学习(Self-Supervised Learning)是一种无需人工标注标签的训练方法,其中模型利用数据本身的自动生成目标进行学习。它为利用未标记数据进行无监督学习提供了一种有效的方法,并在提高模型性能和泛化能力方面展现了潜力。
在传统的监督学习中,我们需要为数据提供人工标签作为目标,例如将图像分类为不同的类别或为文本分配标签。但在自监督学习中,数据本身被用作生成目标,无需人工标签。
自监督学习的核心思想是通过利用数据中的内在结构或模式来设计自动生成的任务。例如,在图像领域中,可以通过对图像进行随机的遮挡、旋转、颜色变换等操作,将原始图像作为输入,并要求模型重建或预测被修改的图像部分。模型在学习过程中尝试重构或预测修改后的部分,从而通过自我生成的目标进行训练。
自监督学习的优势在于无需人工标签,因此可以在大规模未标记的数据上进行训练。这对于许多领域来说非常有价值,因为标记大量数据的成本往往很高。通过自监督学习,可以在未标记数据上训练模型,然后将其迁移到标记有限的数据集上,以提高模型性能。
其中自训练中很重要的一个概念便是伪标签↓
伪标签
在伪标签的方法中,首先使用已标记的少量数据对模型进行初始训练。然后,使用这个初始训练好的模型对未标记的数据进行预测,并将这些预测结果作为伪标签(或伪目标)。将未标记数据与其伪标签一起作为扩展的训练集,再次对模型进行训练,以进一步改进模型的性能。
伪标签的思想基于一个假设:对于给定的未标记数据,模型的预测结果可能是正确的。通过利用这些伪标签进行训练,可以让模型尽可能地适应未标记数据的分布和特征,从而提高模型的泛化能力。
伪标签的优点包括:
-
利用未标记数据:伪标签允许利用大量未标记的数据,这有助于提高模型的训练样本规模,从而更好地捕捉数据的分布和特征。
-
自我生成目标:伪标签使用模型自身的预测结果作为训练目标,避免了人工标注数据的成本和主观性。
-
提高模型性能:通过迭代地使用伪标签进行训练,模型可以逐渐改进,并在未标记数据上获得更好的性能。
然而,伪标签也有一些限制和风险:
-
错误传播:由于伪标签是由模型的预测结果生成的,如果模型的预测出现错误,这些错误可能会被传播到后续的训练中,导致模型性能的下降。
-
标签噪声:未标记数据的伪标签并不一定都是准确的,可能存在一定程度的标签噪声。这可能对模型的学习造成一定的负面影响。
如之前所言,clip是对比任务,那什么是对比任务和预测任务呢
对比和预测任务
"对比任务"(contrastive task)是一种用于学习表示或特征的任务形式。它的目标是通过将相似的样本彼此靠近,将不相似的样本彼此分开,以便在学习过程中构建有意义的表示空间。
对比任务通常涉及两个关键的步骤:
-
正样本对比:选择一对相似的样本(正样本),并鼓励模型将它们在表示空间中彼此靠近。这意味着模型应该能够捕捉到这些样本之间的共同特征和相似性。
-
负样本对比:选择一对不相似的样本(负样本),并鼓励模型将它们在表示空间中彼此分开。这意味着模型应该能够区分不同类别或不同特征的样本。
通过正样本对比和负样本对比的训练,模型可以学习到更具区分性的特征表示。这些特征表示可以在许多机器学习任务中使用,如相似性搜索、聚类、分类等。
其中,clip中对比学习的loss叫ITC loss(Image Text Contrastive Loss)
图像文本对比损失(Image Text Contrastive Loss)是一种用于学习图像和文本之间的相似性关系的损失函数。它广泛应用于图像和文本之间的多模态检索、对齐和关联任务中。
该损失函数的目标是通过最大化正样本对的相似性,同时最小化负样本对的相似性,来推动图像和文本之间的对应关系的学习。在训练过程中,每个正样本对由一个图像和一个与其相关的文本组成,而每个负样本对则由一个图像和一个与其不相关的文本组成。
具体而言,对于正样本对,目标是使图像和文本之间的特征表示在嵌入空间中更加接近。而对于负样本对,目标是使图像和文本之间的特征表示在嵌入空间中更加远离。
通常,图像和文本的特征表示通过卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型提取得到。然后,使用欧氏距离或余弦相似度等度量方法来衡量图像和文本特征之间的相似性。
论文中clip模型采用了混精度训练以减少计算量
混精度训练
混合精度训练(Mixed Precision Training)是一种通过同时使用低精度(例如半精度)和高精度(例如单精度)数据类型来进行深度学习模型训练的技术。
在混合精度训练中,通常会将模型的参数和梯度存储为低精度的数据类型,如半精度浮点数(FP16),而输入数据和中间激活值则使用高精度的数据类型,如单精度浮点数(FP32)。这样可以减少模型中参数所占用的内存空间,同时加快模型的计算速度。
混合精度训练的优点包括:
-
节省内存:使用低精度的参数可以大幅减少模型所占用的内存空间,尤其是对于大型模型和大规模数据集来说,这一点尤为重要。这使得可以在更大的批次大小下进行训练,从而加速训练过程。
-
提高计算效率:低精度的计算可以在硬件加速器(如GPU)上更快地执行。由于低精度操作所需的计算量较小,可以在相同的时间内执行更多的计算,从而加快模型训练的速度。
-
加速模型部署:使用混合精度训练可以减小模型的尺寸,使得模型在推理阶段的内存占用和计算时间都得到显著减少。这对于在嵌入式设备或边缘设备上部署深度学习模型非常有益。
需要注意的是,混合精度训练也会引入一定的数值精度损失。由于参数和梯度存储为低精度,可能会导致数值计算上的一些不确定性和误差累积。因此,在应用混合精度训练时,需要小心处理数值不稳定性,并进行合适的数值调整和梯度缩放。
多GPU运算可以参考↓
How to Train Really Large Models on Many GPUs? | Lil'Log
ALBEF
模型结构
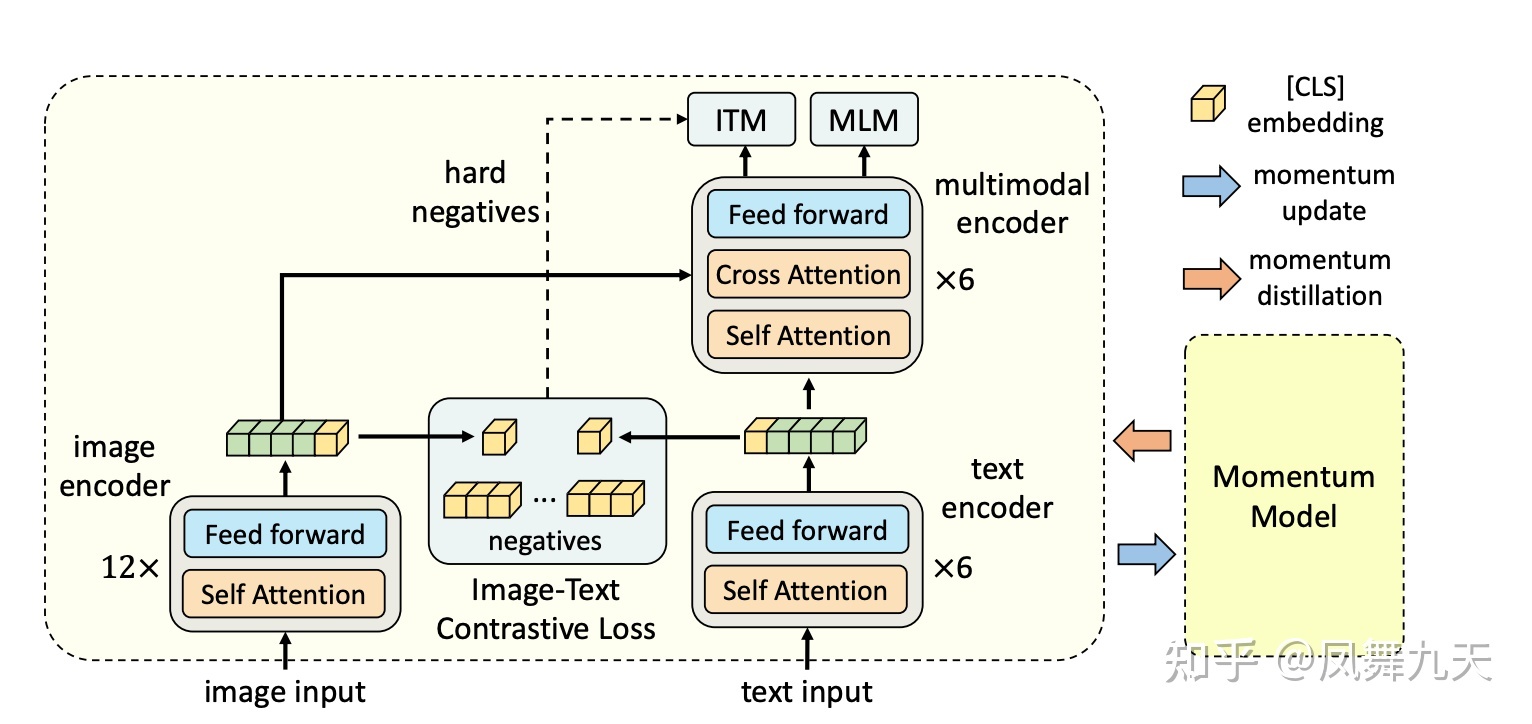
图像:12层Transformer base Model(n)
文本:12层bert model劈成两部分,前六层作为文本编码器(l),后六层用作多模态融合编码器(n-l)
Momentum Model:也是vit + bert 的组合,但是参数是通过主模型moving average得到,比起gradient占的内存相对较小
Loss:
2*ITC(Image Text Contrastive) :对比任务,对比样本之间的(余弦)相似度
输入:(Image,Text)
ITM(Image Text Maching):二分类任务,判断样本是否匹配。因为及其容易收敛,所以会通过ITC得到的除了正样本之外余弦相似度最高的负样本(最接近正样本的负样本)
输入:(Image,Text)
2*MLM(Mask Language Modeling):BERT里面用的完型填空。但是在本模型中会通过图像来恢复被mask掉的模型
输入:(Image, Masked Text)
*ITC和MLM除了在基本模型外,在momentum model中也有,ITC本身是基于ground truth的,所以在momentum model中没有
主要贡献
1)在Mutli-Model Encoder之前将把输入的图像和文本的特征align起来:提出loss(其实就是ITC),在fusing之前align上
2)momentum distillation
 因为大多数收集到的图像文本对的数据都是非常noisy的,因此one-hot的ground truth 并不一定是最优解。为了从noisy的数据有效学习文本图像特征,以自训练的方式进行学习,也是用伪标签(pseudo label)。用动量模型(momentum model)去生成pseudo target,从而达到自训练。如图所示,有时动量模型上产生的pseudo target比ground truth 更能准确描述图片。 在已有的模型上运用exponential moving average EMA,让其不仅和ground truth的one hot label 接近,还让其和 pseudo target尽量的match。
因为大多数收集到的图像文本对的数据都是非常noisy的,因此one-hot的ground truth 并不一定是最优解。为了从noisy的数据有效学习文本图像特征,以自训练的方式进行学习,也是用伪标签(pseudo label)。用动量模型(momentum model)去生成pseudo target,从而达到自训练。如图所示,有时动量模型上产生的pseudo target比ground truth 更能准确描述图片。 在已有的模型上运用exponential moving average EMA,让其不仅和ground truth的one hot label 接近,还让其和 pseudo target尽量的match。
作用:为同一个图像文本对生成不同视角,变相做data argumentation,从而让训练出来的模型具有Semantic Preserving的功能
成就:图文检索效果拔群,训练亲民
VLMo
在前面说到的模型中,双塔模型如clip用余弦相似度做匹配则会又快又好,但在其他任务表现比较差;而用transformer则在匹配任务上则会很慢。VLMo针对这个问题对模型做出改进,也就是Mixture of Modality Expert。
模型结构

目标函数
ITC(Image Text Contrastive) ,ITM(Image Text Maching),MLM(Mask Language Modeling)
主要贡献
1)模型结构改进:Mixture of Modality Expert。自注意力所有模态共享,但是在Feed Forward FC层,每个模态都会对应自己的expert。在训练的时候哪个模态数据来了就训练哪个模态的expert,在推理的时候根据输入数据决定使用模型。
2)分阶段模型预训练:解决了数据集难找,制作成本高的问题。
先把vision expert在vision数据集上训练
然后吧vision ffn和self attention 冻住,再在language expert在language 数据集(text-only data)训练,此时模型参数已经非常好的被初始化过了
最后再在多模态数据集上做pretraining。
Transformer Encoder 和 Decoder 一起的模型
BLIP
模型结构

可以说是ALBEF和VLmo模型的结合
*本图中同样的颜色是共享参数的
图像(n层):一个标准的vit模型
文本:根据输入模态和目标函数的不同,选择大模型里不同的部分去做模型forward
模型1 Text Encoder(n层):根据输入的内容做understanding分类。得到文本特征后去和视觉特征做ITCloss。Token:CLS
模型2 Image-grounded Text encoder:借助图像的信息去完成多模态的任务。Token:Encode
不看模型3完全就是 ALBEF嘛!不过它借鉴了VLMO里self attention 是可以共享参数的。
模型3 Image-grounded Text decoder:用于生成文本。它第一层用的是causal self-attention,因果关系注意力 Token:Decoder
目标函数LM:GPT系列的目标函数,给定一些词,预测一些词
主要贡献
1)Cap filter Model / Caption filtering
先用嘈杂的数据训练一个模型Cap,然后用该模型在更干净的数据集上训练一个更干净的模型,再看看用更干净的数据能不呢train出更好的模型

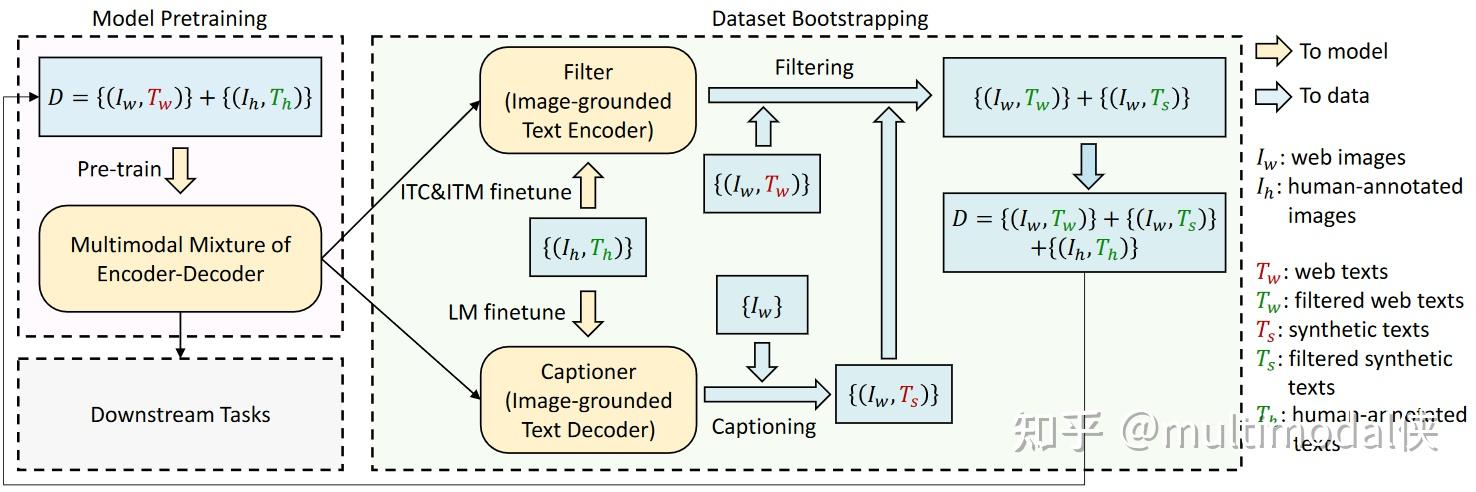
step1:
先用嘈杂的数据训练一个模型Cap
step2:
用该模型在更干净的数据集(Coco)上训练出一个filter,再用这个filter对原始数据进行处理,获得更干净的数据。同时用Captioner:blip模型生成的文字可能比原有的ground truth 更匹配,于是用新文本当作数据集。
step3:
用step2新生成的数据集再对blip模型进行训练。
这三个步骤可以分开训练。
2)Unified
模型上的修改,使其能够生成。
CoCa
BEIT
PaLI
DaLL.E
DALL·E是一种基于Transformer架构的神经网络模型,专门用于根据文本描述生成图像。它在图像生成方面展现出令人瞩目的能力,为将自然语言和图像生成结合起来提供了新的可能性。
DALL·E的特点是它可以根据给定的文本描述生成对应的图像。与传统的图像生成模型不同,DALL·E能够根据自然语言的描述生成与描述相匹配的图像,而不仅仅是通过对图像的像素进行重建或合成。
DALL·E使用了一种称为自回归生成的方法。它将文本描述编码为向量表示,并使用Transformer架构来学习文本和图像之间的关系。然后,根据这个学习到的关系,DALL·E可以生成与描述相一致的图像。
这使得DALL·E在生成与描述相关的图像方面非常出色,并且在一些视觉推理任务上表现出令人印象深刻的能力。然而,值得注意的是,DALL·E是在大规模数据集上进行训练的,并且其生成结果可能受到一些限制,例如对于复杂场景的细节捕捉可能有限。
参考视频:






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结