您现在的位置是:首页 >技术杂谈 >(转载)有导师学习神经网络的回归拟合(matlab实现)网站首页技术杂谈
(转载)有导师学习神经网络的回归拟合(matlab实现)
简介(转载)有导师学习神经网络的回归拟合(matlab实现)
神经网络的学习规则又称神经网络的训练算法,用来计算更新神经网络的权值和阈值。学习规则有两大类别:有导师学习和无导师学习。在有导师学习中,需要为学习规则提供一系列正确的网络输入/输出对(即训练样本),当网络输入时,将网络输出与相对应的期望值进行比较,然后应用学习规则调整权值和阈值,使网络的输出接近于期望值。而在无导师学习中,权值和阈值的调整只与网络输入有关系,没有期望值,这类算法大多用聚类法,将输入模式归类于有限的类别。本章将详细分析两种应用最广的有导师学习神经网络(BP神经网络及RBF神经网络)的原理及其在回归拟合中的应用。
1 理论基础
1.1 BP神经网络概述
1.BP神经网络的结构
BP神经网络由Rumelhard和McClelland于1986年提出,从结构上讲,它是一种典型的多层前向型神经网络,具有一个输入层、数个隐含层(可以是一层,也可以是多层)和一个输出层。层与层之间采用全连接的方式,同一层的神经元之间不存在相互连接。理论上已经证明,具有一个隐含层的三层网络可以逼近任意非线性函数。隐含层中的神经元多采用S型传递函数,输出层的神经元多采用线性传递函数。图1所示为一个典型的BP神经网络结构,该网络具有一个隐含层,输入层神经元数目为m,隐含层神经元数目为l,输出层神经元数目为n,隐含层采用S型传递函数tansig,输出层传递函数为purelin.

图1 BP神经网络结构
2.BP神经网络的学习算法
BP神经网络的误差反向传播算法是典型的有导师指导的学习算法,其基本思想是对一定数量的样本对(输入和期望输出)进行学习,即将样本的输入送至网络输入层的各个神经元,经隐含层和输出层计算后,输出层各个神经元输出对应的预测值,若预测值与期望输出之间的误差不满足精度要求时,则从输出层反向传播该误差,从而进行权值和阈值的调整,使得网络的输出和期望输出间的误差逐渐减小,直至满足精度要求。
BP网络的精髓是将网络的输出与期望输出间的误差归结为权值和阈值的“过错”,通过反向传播把误差“分摊”给各个神经元的权值和阈值。BP网络学习算法的指导思想是权值和阈值的调整要沿着误差函数下降最快的方向——负梯度方向。下面详细推导利用BP网络学习算法对权值和阈值进行调整的公式。



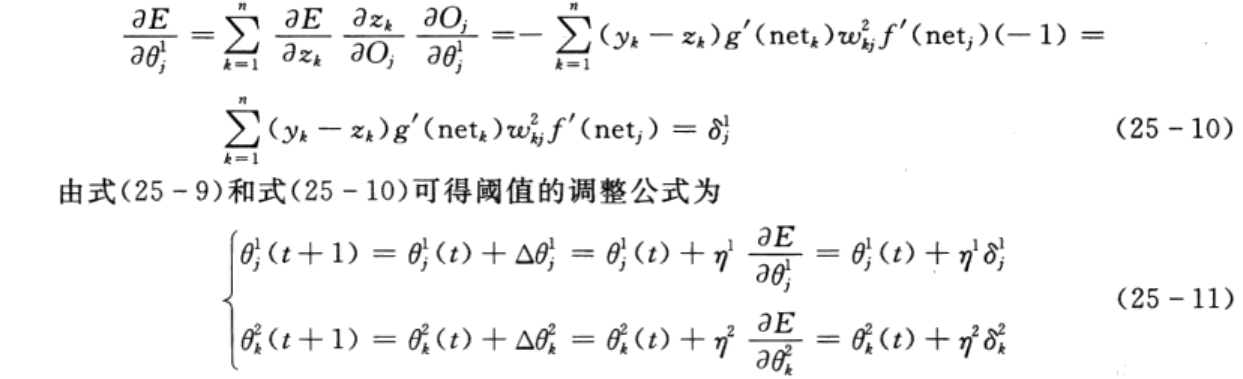
3.BP神经网络的MATLAB工具箱函数
MATLAB神经网络工具箱中包含了许多用于BP神经网络分析与设计的函数,本节将详细说明几个主要函数的功能、调用格式、参数意义及注意事项等。
(1)BP神经网络创建函数
函数newff用于创建一个BP神经网络,其调用格式为
net=newff(P,T,[S1 S2...S(N-1)],{TF1 TF2...TFN1},BTF,BLF,PF,IPF,OPF,DDF)
其中,P为输入向量;T为输出向量;Si为隐含层神经元数目(默认为[]);TFi为传递函数(默认隐含层传递函数为tansig,输出层传递函数为purelin);BTF为网络训练函数(默认为trainlm);BLF为网络权值/阈值学习函数(默认为learngdm);PF为性能函数(默认为mse);IPF为输入处理函数(默认为{‘fixunknowns',‘removeconstantrows','mapminmax'});OPF为输出处理函数(默认为{‘removeconstantrows','mapminmax'});DDF为数据划分函数(默认为'dividerand’)。
(2)BP神经网络训练函数
函数train用于训练已经创建好的BP神经网络,其调用格式为
[net,tr,Y,E,Pf,Af]=train(net,P,T,Pi,Ai)
其中,net为训练前及训练后的网络;P为网络输入向量;T为网络目标向量(默认为0);P为初始的输入层延迟条件(默认为0);Ai为初始的输出层延迟条件(默认为0);tr为训练记录(包含步数及性能);Y为网络输出向量;E为网络误差向量;Pf为最终的输入层延迟条件;Af为最终的输出层延迟条件。
(3)BP网络预测函数
函数sim用于利用已经训练好的BP神经网络进行仿真预测,其调用格式为
[Y,Pf,Af,E,perf]= sim(net,P,Pi,Ai,T)
其中,net为训练好的网络;P为网络输入向量;Pi为初始的输入层延迟条件(默认为0);Ai为初始的隐含层延迟条件(默认为0);T为网络目标向量(默认为0);Y为网络输出向量;Pf为最终的输入层延迟条件;Af为最终的隐含层延迟条件;E为网络误差向量;perf为网络的性能。
1.2 RBF神经网络概述
1.RBF神经网络的结构
1985年,Powell提出了多变量插值的径向基函数(radial basis function,RBF)方法。1988年,Moody和Darken提出了一种神经网络结构,即RBF神经网络,它能够以任意精度逼近任意连续函数。RBF网络的结构与多层前向型网络类似,它是一种三层前向型网络,其网络结构如图2所示。输入层由信号源结点组成;第二层为隐含层,隐含层神经元数目视所描述问题的需要而定,隐含层神经元的传递函数是对中心点径向对称且衰减的非负非线性函数;第三层为输出层,它对输入模式的作用做出响应。从输入空间到隐含层空间的变换是非线性的,而从隐含层空间到输出层空间的变换是线性的。
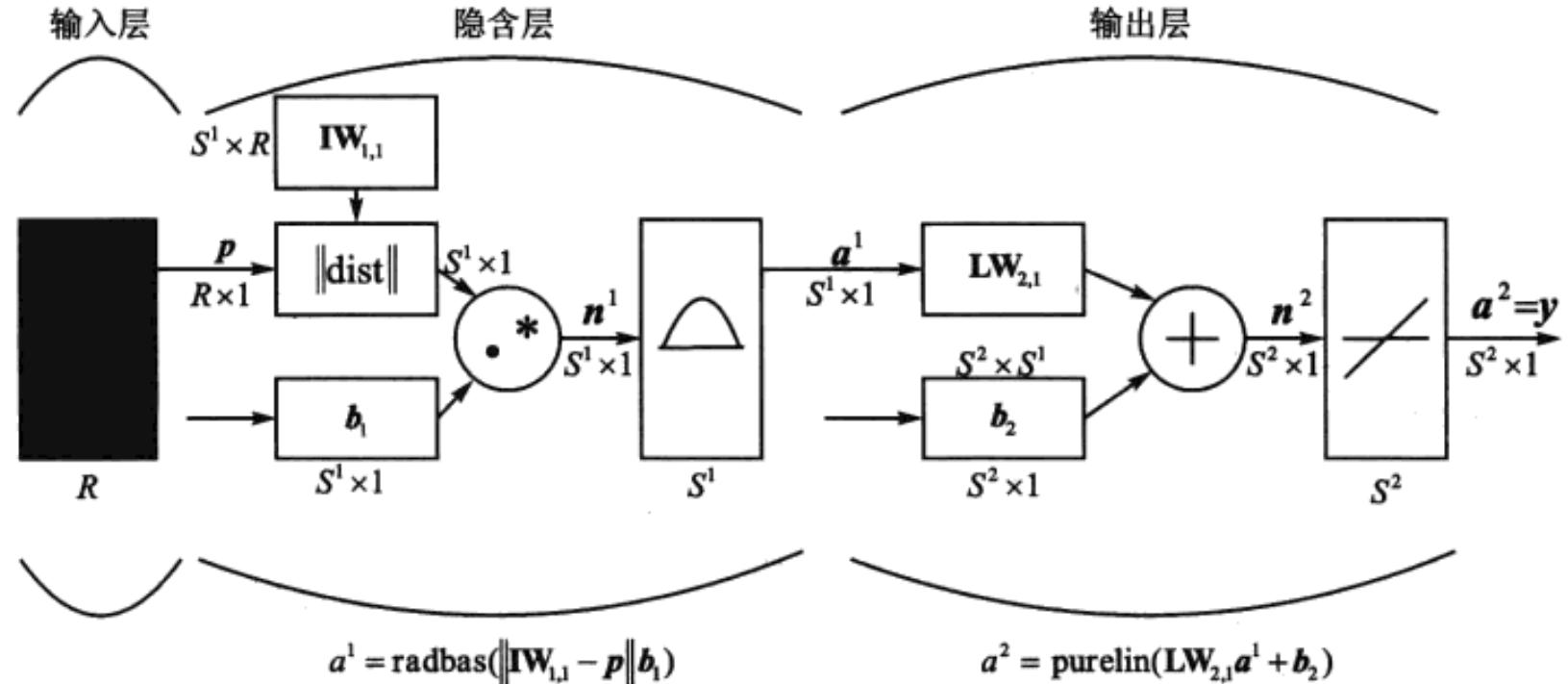 图2 RBF神经网络结构
图2 RBF神经网络结构
RBF网络的基本思想是:用RBF作为隐含层神经元的“基”构成隐含层空间,这样就可以将输入矢量直接映射到隐含层空间,而不需要通过权连接。当RBF的中心点确定以后,这种映射关系也就确定了。而隐含层空间到输出空间的映射是线性的,即网络的输出是隐含层神经元输出的线性加权和。此处的权即为网络可调参数。由此可见,从总体上看,网络由输入到输出的映射是非线性的,而网络输出对可调参数而言却又是线性的。这样网络的权就可以由线性方程直接解出,从而大大加快学习速度并避免局部极小问题。
2.RBF神经网络的学习算法
根据隐含层神经元数目的不同,RBF神经网络的学习算法总体上可以分为两种:
(1)隐含层神经元数目逐渐增加,经过不断的循环迭代,实现权值和阈值的调整与修正。
(2)隐含层神经元数目确定(与训练集样本数目相同),权值和阈值由线性方程组直接解出。
对比不难发现,第二种学习算法速度更快、精度更高,由于篇幅所限,本书仅讨论第二种学习算法,即隐含层神经元数目等于训练集样本数目这一类型。具体的学习算法步骤如下:
(1)确定隐含层神经元径向基函数中心
不失一般性,设训练集样本输入矩阵P和输出矩阵T分别为



3.RBF神经网络的MATLAB工具箱函数
函数newrbe用于创建一个精确的RBF神经网络,其调用格式如下:
net= newrbe(P,T,spread)
其中,P为网络输入向量;T为网络目标向量;spread为径向基函数的扩展速度(默认为1.0);net为创建好的RBF网络。
2 案例背景
2.1 问题描述
辛烷值是汽油最重要的品质指标,传统的实验室检测方法存在样品用量大、测试周期长和费用高等问题,不适用于生产控制,特别是在线测试。近年发展起来的近红外光谱分析方法(NIR),作为一种快速分析方法,已广泛应用于农业、制药、生物化工、石油产品等领域。其优越性是无损检测、低成本、无污染、能在线分析,更适合于生产和控制的需要。
针对采集得到的60组汽油样品,利用傅里叶近红外变换光谱仪对其进行扫描,扫描范围为900~1700nm,扫描间隔为2nm,每个样品的光谱曲线共含401个波长点。样品的近红外光谱曲线如图3所示。同时,利用传统实验室检测方法测定其辛烷值含量。现要求利用BP神经网络及RBF神经网络分别建立汽油样品近红外光谱及其辛烷值间的数学模型,并对模型的性能进行评价。
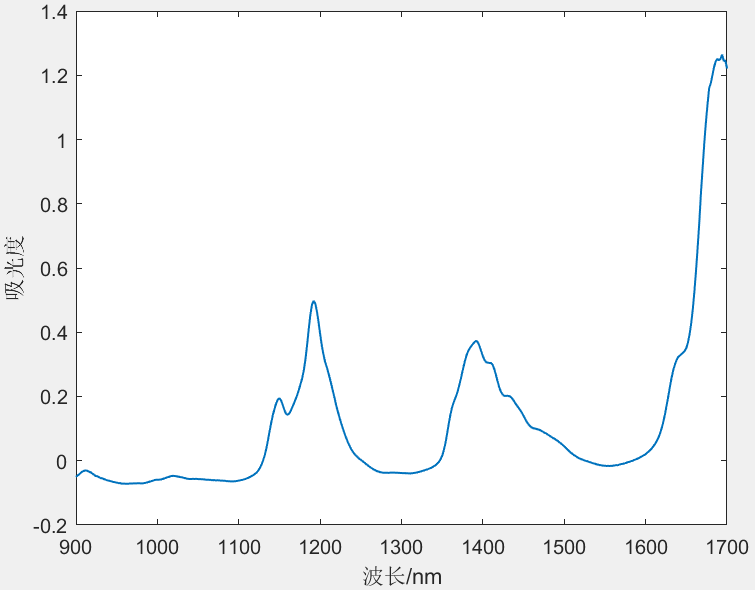
图3 近红外光谱曲线
2.2 解题思路及步骤
依据问题描述中的要求,实现BP神经网络及RBF神经网络的模型建立及性能评价,大体上可以分为以下几个步骤,如图4所示。

图4 模型建立步骤
1.产生训练集/测试集
为了保证建立的模型具有良好的泛化能力,要求训练集样本数量足够多,且具有良好的代表性。一般认为,训练集样本数量占总体样本数量的2/3~3/4为宜,剩余的1/4~1/3作为测试集样本。同时,尽量使得训练集与测试集样本的分布规律近似相同。
2.创建/训练BP神经网络
创建BP神经网络前需要确定网络的结构,即需要确定以下几个参数:输入变量个数、隐含层数及各层神经元个数、输出变量个数。如前文所述,只含有一个隐含层的三层BP神经网络可以逼近任意非线性函数,因此,本书仅讨论单隐含层BP神经网络。从问题描述中可知,输入变量个数为401,输出变量个数为1,隐含层神经元个数对网络性能的影响较大,具体讨论参见第4节。网络结构确定后,设置相关训练参数(如训练次数、学习率等),便可以对网络进行训练。
3.创建RBF神经网络
创建RBF神经网络时需要考虑spread的值对网络性能的影响,具体讨论参见第4节。
4.仿真测试
模型建立后,将测试集的输入变量送入模型,模型的输出便是对应的预测结果。
5.性能评价
通过计算测试集预测值与真实值间的误差,可以对模型的泛化能力进行评价。在此基础上,可以进行进一步的研究和改善。
3 MATLAB程序实现
利用MATLAB神经网络工具箱提供的函数,可以方便地在MATLAB环境下实现上述步骤。
%% 清空环境变量
clear all
clc
%% 训练集/测试集产生
load spectra_data.mat
% 随机产生训练集和测试集
temp = randperm(size(NIR,1));
% 训练集——50个样本
P_train = NIR(temp(1:50),:)';
T_train = octane(temp(1:50),:)';
% 测试集——10个样本
P_test = NIR(temp(51:end),:)';
T_test = octane(temp(51:end),:)';
N = size(P_test,2);
%% BP神经网络创建、训练及仿真测试
% 创建网络
net = newff(P_train,T_train,9);
% 设置训练参数
net.trainParam.epochs = 1000;
net.trainParam.goal = 1e-3;
net.trainParam.lr = 0.01;
% 训练网络
net = train(net,P_train,T_train);
% 仿真测试
T_sim_bp = sim(net,P_test);
%% RBF神经网络创建及仿真测试
% 创建网络
net = newrbe(P_train,T_train,0.3);
% 仿真测试
T_sim_rbf = sim(net,P_test);
%% 性能评价
% 相对误差error
error_bp = abs(T_sim_bp - T_test)./T_test;
error_rbf = abs(T_sim_rbf - T_test)./T_test;
% 决定系数R^2
R2_bp = (N * sum(T_sim_bp .* T_test) - sum(T_sim_bp) * sum(T_test))^2 / ((N * sum((T_sim_bp).^2) - (sum(T_sim_bp))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
R2_rbf = (N * sum(T_sim_rbf .* T_test) - sum(T_sim_rbf) * sum(T_test))^2 / ((N * sum((T_sim_rbf).^2) - (sum(T_sim_rbf))^2) * (N * sum((T_test).^2) - (sum(T_test))^2));
% 结果对比
result_bp = [T_test' T_sim_bp' T_sim_rbf' error_bp' error_rbf']
%% 绘图
figure
plot(1:N,T_test,'b:*',1:N,T_sim_bp,'r-o',1:N,T_sim_rbf,'k-.^')
legend('真实值','BP预测值','RBF预测值')
xlabel('预测样本')
ylabel('辛烷值')
string = {'测试集辛烷值含量预测结果对比(BP vs RBF)';['R^2=' num2str(R2_bp) '(BP)' ' R^2=' num2str(R2_rbf) '(RBF)']};
title(string)
本章选用的两个评价指标为相对误差和决定系数,其计算公式分别如下:
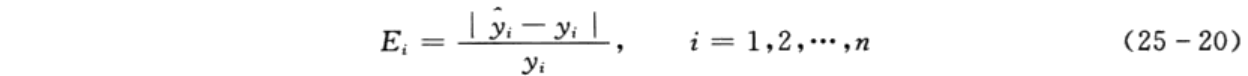

说明:
(1)相对误差越小,表明模型的性能越好。
(2)决定系数范围在[0,1]内,愈接近于1,表明模型的性能愈好;反之,愈趋近于0,表明模型的性能愈差。
由于训练集和测试集是随机产生的,每次运行结果都会不同。某次运行结果如图5所示。从图中可以清晰地看到,BP神经网络和RBF神经网络均能较好地实现辛烷值含量的预测。

图5 某次运行结果
4 延伸阅读
4.1 网络参数的影响及选择
1.隐含层神经元个数的选择
如前文所述,隐含层神经元个数对BP神经网络的性能影响较大。若隐含层神经元的个数较少,则网络不能充分描述输出和输入变量之间的关系;相反,若隐含层神经元的个数较多,则会导致网络的学习时间变长,甚至会出现过拟合的问题。一般地,确定隐含层神经元个数的方法是在经验公式的基础上,对比隐含层不同神经元个数对模型性能的影响,从而进行选择。
2.spread值的选择
一般而言,spread值越大,函数的拟合就越平滑。然而,过大的spread将需要非常多的神经元以适应函数的快速变化;反之,若spread值太小,则意味着需要许多的神经元来适应函数的缓慢变化,从而导致网络性能不好。
4.2 案例延伸
BP及RBF神经网络以其良好的非线性逼近能力,已经广泛地应用于各行各业中。近年来,不少专家和学者提出了很多改进算法,以解决BP神经网络初始权值和阈值对性能的影响、容易陷入局部极小、RBF神经网络隐含层神经元中心选取等问题。此外,由于近红外光谱所包含的波长点数(即输入变量)较多,波长点间存在多重共线性,而且容易造成建模时间长等问题,可以利用主成分分析、偏最小二乘分析、遗传算法等方法先对光谱数据进行压缩,然后再进行建模。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结