您现在的位置是:首页 >技术交流 >python批量下载怀俄明大学探空数据Wyoming soundings并处理网站首页技术交流
python批量下载怀俄明大学探空数据Wyoming soundings并处理
下载怀俄明大学的探空数据,之前用的是气象家园写的maltab脚本,但总是链接不上,而且有的站点需要用新网址,有的有需要用老网址,很麻烦,痛定思痛用决定终于用python了,主要有两种方式,各有各的优缺点吧,我们下面逐一介绍一下。
数据概况
怀俄明大学的探空数据下载网址在:http://weather.uwyo.edu/upperair/seasia.html
中国地区的网址似乎放在了新的地方:http://weather.uwyo.edu/upperair/bufrraob.shtml 数据改成了BUFF格式,不过我看了下,新网址的数据垂直分辨率更高,质量更好更全,但站点较少,我所需要的北极地区站点数据不全,因此我还是选择在老站点下载。
老站点下载需要手动选择站点和日期,随后跳转到一个网页,一般是TEXELIST,这个网址是不提供下载页面的,如果数据较少,我们直接copy到txt或者excel里就好,如果数据较多,则需要借助脚本下载。
一个典型的探空数据其内容如下:
<HTML>
<TITLE>University of Wyoming - Radiosonde Data</TITLE>
<BODY BGCOLOR="white">
<H2>21432 Ostrov Kotelnyj Observations at 12Z 07 Jan 2019</H2>
<PRE>
-----------------------------------------------------------------------------
PRES HGHT TEMP DWPT RELH MIXR DRCT SKNT THTA THTE THTV
hPa m C C % g/kg deg knot K K K
-----------------------------------------------------------------------------
1015.0 8 -36.1 -39.3 72 0.13 155 8 236.0 236.4 236.1
1000.0 124 -33.1 -35.7 77 0.18 170 8 240.1 240.6 240.1
996.0 152 -32.1 -34.5 79 0.21 170 8 241.4 241.9 241.4
977.0 288 -27.1 -29.0 84 0.36 171 9 247.7 248.7 247.8
952.0 474 -25.5 -26.8 89 0.45 173 11 251.2 252.4 251.2
947.0 512 -25.3 -26.9 86 0.45 173 12 251.7 253.0 251.8
925.0 681 -25.3 -27.7 80 0.43 175 14 253.4 254.7 253.5
850.0 1294 -27.3 -30.0 78 0.38 185 19 257.5 258.6 257.6
770.0 2002 -29.1 -33.7 64 0.29 185 27 263.0 263.9 263.0
本次使用python下载数据,主要使用两种方式:urlib和siphon
urlib下载
这个数据的下载思路很简单,就是根据时间和站点构建数据网址,利用urlib.request得到内容,将所有数据写入txt文件再保存:
import urllib.request
import os
import calendar
url0='http://weather.uwyo.edu/cgi-bin/sounding?region=ant&TYPE=TEXT%3ALIST&'
stids=['21432',]
hrs='00'
hre='12'
hr=['00','12']
for stname in stids:
path='D:/arctic-in-situ/uwyo_sounding/stn_'+stname+'/'
if os.path.isdir(path):
pass
else:
os.mkdir(path)
for y in range(2019, 2021):
yr=str(y)
for m in range(1, 13):
if m<10 :
mn='0'+str(m)
else:
mn=str(m)
day_num = calendar.monthrange(y, m)[1]
for d in range(1,day_num+1):
if d<10:
dy="0"+str(d)
else:
dy=str(d)
for h in hr:
url=url0+'YEAR='+yr+'&MONTH='+mn+'&FROM='+dy+h+'&TO='+dy+h+'&STNM='+stname
try:
print(url)
resp=urllib.request.urlopen(url)
html=resp.read()
fname=path+stname+'-'+yr+mn+dy+h+'.txt'
file=open(fname,'w')
file.write(str(html,"utf-8"))
file.close()
print(fname)
except Exception:
print("下载失败")
这个方法的好处是非常直接,处理也比较简单,再处理时,我直接使用pandas库的read,table对其处理即可:data[i]=pd.read_table(file_list[i],sep='s+',header=None,skiprows=9,skipfooter=1,names=['P','HT','TEMP','DWPT','RH','Q','DRCT','WS','THTA','THTE','THTV'] ,engine='python')
即可读取。
Siphon下载——添加混合比
iphon是pyhton语言写的一个工具包,可以用来下载预报数据、再分析数据以及怀俄明的探空数据,其官方文档就有下载怀俄明大学探空数据的例子:Siphon_upper_Air
之前已有一位大佬的博客讲述了如何使用Siphon批量下载的配置和代码Python下载Wyoming怀俄明大学探空数据,极具参考意义,不过由于需求与版本不同,在实际使用时会存在差异。
在我使用时,Siphon内默认下载网址可以正常使用,因此我跳过了数据网址更新步骤,添加代理部分我直接使用了自己的全局魔法(。),也并没有修改。
不过这里存在一个问题:Siphon默认下载的探空数据是不包含水汽混合比和位温的,需要我们进行一些修改。
进入你的Siphon下载路径,我的是在D:AnacondaLibsite-packages文件夹,可以用pip show Siphon查看安装路径。
进入simplewebservice文件夹,有个wyoming.py文件,进去,找到def _get_data,修改为:
def _get_data(self, time, site_id):
r"""Download and parse upper air observations from an online archive.
Parameters
----------
time : datetime
The date and time of the desired observation.
site_id : str
The three letter ICAO identifier of the station for which data should be
downloaded.
Returns
-------
:class:`pandas.DataFrame` containing the data
"""
raw_data = self._get_data_raw(time, site_id)
soup = BeautifulSoup(raw_data, 'html.parser')
tabular_data = StringIO(soup.find_all('pre')[0].contents[0])
col_names = ['pressure', 'height', 'temperature', 'dewpoint', 'mixr', 'direction', 'speed']
df = pd.read_fwf(tabular_data, skiprows=5, usecols=[0, 1, 2, 3, 5, 6, 7], names=col_names)
df['u_wind'], df['v_wind'] = get_wind_components(df['speed'],
np.deg2rad(df['direction']))
# Drop any rows with all NaN values for T, Td, winds
df = df.dropna(subset=('temperature', 'dewpoint', 'mixr', 'direction', 'speed',
'u_wind', 'v_wind'), how='all').reset_index(drop=True)
# Parse metadata
meta_data = soup.find_all('pre')[1].contents[0]
lines = meta_data.splitlines()
# If the station doesn't have a name identified we need to insert a
# record showing this for parsing to proceed.
if 'Station number' in lines[1]:
lines.insert(1, 'Station identifier: ')
station = lines[1].split(':')[1].strip()
station_number = int(lines[2].split(':')[1].strip())
sounding_time = datetime.strptime(lines[3].split(':')[1].strip(), '%y%m%d/%H%M')
latitude = float(lines[4].split(':')[1].strip())
longitude = float(lines[5].split(':')[1].strip())
elevation = float(lines[6].split(':')[1].strip())
pw = float(lines[-1].split(':')[1].strip())
df['station'] = station
df['station_number'] = station_number
df['time'] = sounding_time
df['latitude'] = latitude
df['longitude'] = longitude
df['elevation'] = elevation
df['pw'] = pw
# Add unit dictionary
df.units = {'pressure': 'hPa',
'height': 'meter',
'temperature': 'degC',
'dewpoint': 'degC',
'mixr': 'g/kg',
'direction': 'degrees',
'speed': 'knot',
'u_wind': 'knot',
'v_wind': 'knot',
'station': None,
'station_number': None,
'time': None,
'latitude': 'degrees',
'longitude': 'degrees',
'elevation': 'meter',
'pw': 'millimeter'}
return df
主要是将水汽混合比保存读取,保存运行,下载的数据变多了水汽混合比这一列:
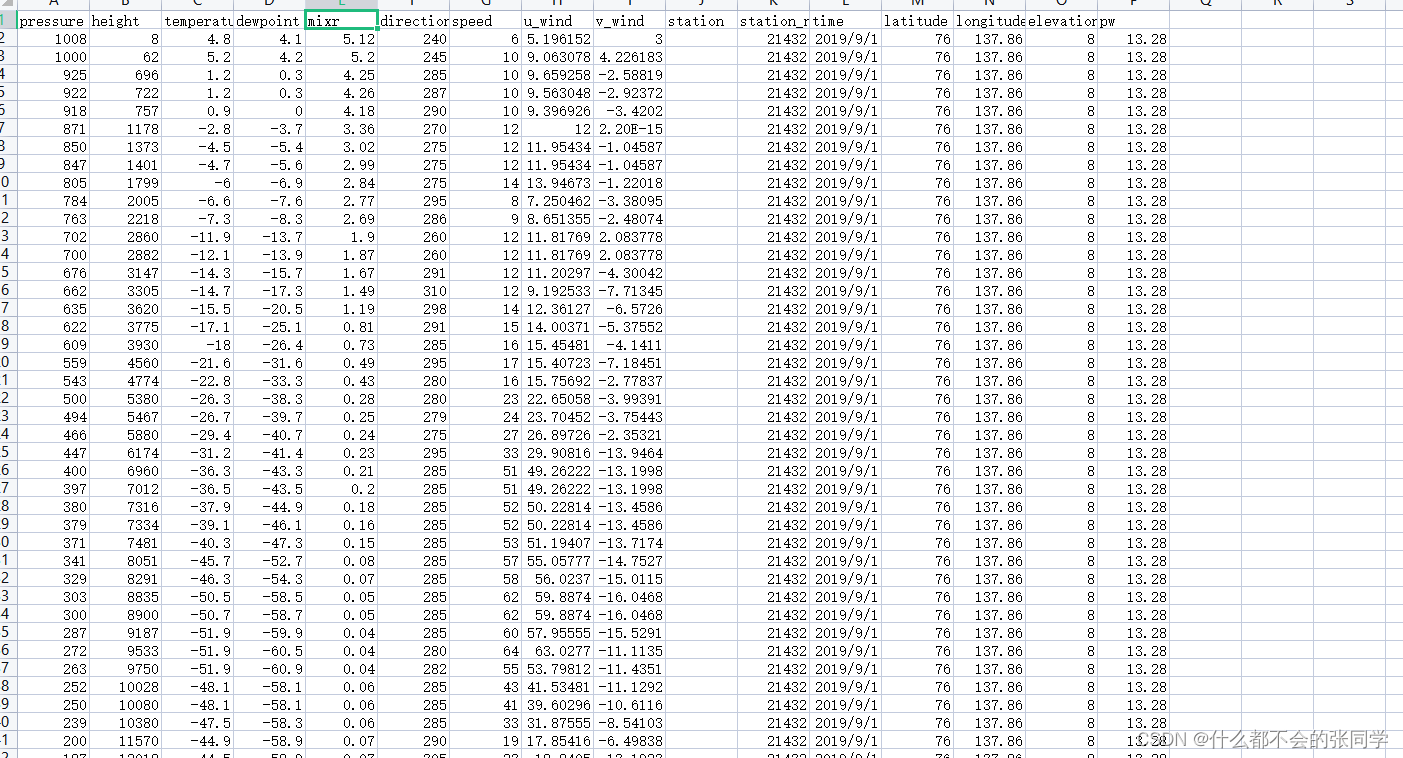
代码如下,主要参考上述提到的博客python批量下载Wyoming代码:
import os
from datetime import datetime
import datetime as dt
from metpy.units import units
from siphon.simplewebservice.wyoming import WyomingUpperAir
# 设置下载时段(这里是UTC时刻)
start = datetime(2019, 3, 1, 0)
end = datetime(2019, 8, 31, 0)
datelist = []
nodata=[]
data_missing=[]
while start<=end:
datelist.append(start)
start+=dt.timedelta(hours=12)
datelist_s=[]
stids=['21432',]
for stname in stids:
path='D:/arctic-in-situ/uwyo_sounding/'+stname+'/'
if os.path.isdir(path):
pass
else:
os.mkdir(path)
datelist_s=datelist.copy()
for date in datelist_s:
try:
df = WyomingUpperAir.request_data(date, stname)
df.to_csv(path+date.strftime('%Y%m%d%H')+'.csv',index=False)
print(stname+date.strftime('%Y%m%d_%H')+'下载成功')
except Exception as e:
print('错误类型是',e.__class__.__name__)
print('错误明细是',e)
print(stname+date.strftime('%Y%m%d_%H')+'下载失败,原因如下:')
if e.__class__.__name__=="IndexError":
#加入无数据队列
print(
'No data available for {time:%Y-%m-%d %HZ} '
'for station {stid}.'.format(time=date, stid=stname))
nodata.append(stname+'_'+date.strftime('%Y%m%d%H'))
elif e.__class__.__name__=="TypeError":
print('Error data type in web page')
nodata.append(stname + '_' + date.strftime('%Y%m%d%H'))
elif e.__class__.__name__=="KeyError":
print('Missing data in web page')
data_missing.append(stname + '_' + date.strftime('%Y%m%d%H'))
# 其他需要忽略下载的错误可以继续往下加
else:
print('等待重新下载'+stname+date.strftime('%Y%m%d_%H'))
datelist_s.append((date))






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结