您现在的位置是:首页 >技术教程 >Hbase-- 03网站首页技术教程
Hbase-- 03
4.原理加强
4.1数据存储
4.1.1行式存储
传统的行式数据库将一个个完整的数据行存储在数据页中
4.1.2列式存储
列式数据库是将同一个数据列的各个值存放在一起

| 传统行式数据库的特性如下: 列式数据库的特性如下: |
4.1.3列族式存储
列族式存储是一种非关系型数据库存储方式,按列而非行组织数据。它的数据模型是面向列的,即把数据按照列族的方式组织,将属于同一列族的数据存储在一起。每个列族都有一个唯一的标识符,一般通过列族名称来表示。它具有高效的写入和查询性能,能够支持极大规模的数据
- 如果一个表有多个列族, 每个列族下只有一列, 那么就等同于列式存储。
- 如果一个表只有一个列族, 该列族下有多个列, 那么就等同于行式存储.

4.1.4hbase的存储路径:
在conf目录下的hbase-site.xml文件中配置了数据存储的路径在hdfs上
| XML |
hdfs上的存储路径:


4.2region
Region是HBase数据管理的基本单位,region有一点像关系型数据的分区。
Region中存储这用户的真实数据,而为了管理这些数据,HBase使用了RegionSever来管理region。
4.2.1region的分配
一个表中可以包含一个或多个Region。
每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。
regionServer其实是hbase的服务,部署在一台物理服务器上,region有一点像关系型数据的分区,数据存放在region中,当然region下面还有很多结构,确切来说数据存放在memstore和hfile中。我们访问hbase的时候,先去hbase 系统表查找定位这条记录属于哪个region,然后定位到这个region属于哪个服务器,然后就到哪个服务器里面查找对应region中的数据
4.2.2region结构

4.2.3数据的写入

4.2.4Memstore Flush流程
flus流程分为三个阶段:
- prepare阶段:遍历当前 Region中所有的 MemStore ,将 MemStore 中当前数据集 CellSkpiListSet 做一个快照 snapshot;然后再新建一个 CellSkipListSet。后期写入的数据都会写入新的 CellSkipListSet 中。prepare 阶段需要加一把 updataLock 对写请求阻塞,结束之后会释放该锁。因为此阶段没有任何费时操作,因此锁持有时间很短
- flush阶段:遍历所有 MemStore,将 prepare 阶段生成的snapshot 持久化为临时文件,临时文件会统一放到目录.tmp下。这个过程因为涉及到磁盘 IO 操作,因此相对耗时
- commit阶段:遍历所有 MemStore,将flush阶段生成的临时文件移动到指定的 ColumnFamily 目录下,针对 HFile生成对应的 StoreFile 和 Reader,把 StoreFile 添加到 HStore 的 storefiles 列表中,最后再清空 prepare 阶段生成的 snapshot快照
4.2.5Compact 合并机制
hbase中的合并机制分为自动合并和手动合并
4.2.5.1自动合并:
- minor compaction 小合并
- major compacton 大合并
minor compaction(小合并)
将 Store 中多个 HFile 合并为一个相对较大的 HFile 过程中会选取一些小的、相邻的 StoreFile 将他们合并成一个更大的 StoreFile,对于超过 TTL 的数据、更新的数据、删除的数据仅仅只是做了标记,并没有进行物理删除。一次 minor compaction 过后,storeFile会变得更少并且更大,这种合并的触发频率很高
4.2.5.1.1小合并的触发方式:
memstore flush会产生HFile文件,文件越来越多就需要compact.每次执行完Flush操作之后,都会对当前Store中的文件数进行判断,一旦文件数大于配置3,就会触发compaction。compaction都是以Store为单位进行的,而在Flush触发条件下,整个Region的所有Store都会执行compact
后台线程周期性检查
检查周期可配置:
hbase.server.thread.wakefrequency/默认10000毫秒)*hbase.server.compactchecker.interval.multiplier/默认1000
CompactionChecker大概是2hrs 46mins 40sec 执行一次
| XML |
4.2.5.1.2major compaction(大合并)
合并 Store 中所有的 HFile 为一个 HFile,将所有的 StoreFile 合并成为一个 StoreFile,这个过程中还会清理三类无意义数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。合并频率比较低,默认7天执行一次,并且性能消耗非常大,建议生产关闭(设置为0),在应用空间时间手动触发。一般是可以手动控制进行合并,防止出现在业务高峰期。
| XML |
4.2.5.2手动合并
一般来讲,手动触发compaction通常是为了执行major compaction,一般有这些情况需要手动触发合并是因为很多业务担心自动maior compaction影响读写性能,因此会选择低峰期手动触发也有可能是用户在执行完alter操作之后希望立刻生效,执行手动触发maiorcompaction:
造数据
| Shell |

| Shell |

4.2.6region的拆分
region中存储的是一张表的数据,当region中的数据条数过多的时候,会直接影响查询效率。当region过大的时候,region会被拆分为两个region,HMaster会将分裂的region分配到不同的regionserver上,这样可以让请求分散到不同的RegionServer上,已达到负载均衡 , 这也是HBase的一个优点
4.2.6.1region的拆分策略
1. ConstantSizeRegionSplitPolicy:0.94版本前,HBase region的默认切分策略
| 当region中最大的store大小超过某个阈值(hbase.hregion.max.filesize=10G)之后就会触发切分,一个region等分为2个region。 但是在生产线上这种切分策略却有相当大的弊端(切分策略对于大表和小表没有明显的区分):
|
2. IncreasingToUpperBoundRegionSplitPolicy:0.94版本~2.0版本默认切分策略
| 总体看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大的store大小大于设置阈值就会触发切分。 但是这个阈值并不像ConstantSizeRegionSplitPolicy是一个固定的值,而是会在一定条件下不断调整,调整规则和region所属表在当前regionserver上的region个数有关系. region split阈值的计算公式是:
例如:
特点
|
3. SteppingSplitPolicy:2.0版本默认切分策略
| 相比 IncreasingToUpperBoundRegionSplitPolicy 简单了一些 region切分的阈值依然和待分裂region所属表在当前regionserver上的region个数有关系
这种切分策略对于大集群中的大表、小表会比 IncreasingToUpperBoundRegionSplitPolicy 更加友好,小表不会再产生大量的小region,而是适可而止。 |
4. KeyPrefixRegionSplitPolicy
| 根据rowKey的前缀对数据进行分区,这里是指定rowKey的前多少位作为前缀,比如rowKey都是16位的,指定前5位是前缀,那么前5位相同的rowKey在相同的region中 |
5. DelimitedKeyPrefixRegionSplitPolicy
| 保证相同前缀的数据在同一个region中,例如rowKey的格式为:userid_eventtype_eventid,指定的delimiter为 _ ,则split的的时候会确保userid相同的数据在同一个region中。 按照分隔符进行切分,而KeyPrefixRegionSplitPolicy是按照指定位数切分 |
6. BusyRegionSplitPolicy
| 按照一定的策略判断Region是不是Busy状态,如果是即进行切分 如果你的系统常常会出现热点Region,而你对性能有很高的追求,那么这种策略可能会比较适合你。它会通过拆分热点Region来缓解热点Region的压力,但是根据热点来拆分Region也会带来很多不确定性因素,因为你也不知道下一个被拆分的Region是哪个 |
7. DisabledRegionSplitPolicy:不启用自动拆分, 需要指定手动拆分
4.2.6.2手动合并拆分region
手动合并
| Shell |
手动拆分
| Shell |
4.2.7bulkLoad实现批量导入
bulkloader : 一个用于批量快速导入数据到hbase的工具/方法
用于已经存在一批巨量静态数据的情况!如果不用bulkloader工具,则只能用rpc请求,一条一条地通过rpc提交给regionserver去插入,效率极其低下
4.2.7.1原理

相比较于直接写HBase,BulkLoad主要是绕过了写WAL日志这一步,还有写Memstore和Flush到磁盘,从理论上来分析性能会比Put快!
4.2.7.2BulkLoad实战示例1:importTsv工具
原理:
Importtsv是hbase自带的一个 csv文件--》HFile文件 的工具,它能将csv文件转成HFile文件,并发送给regionserver。它的本质,是内置的一个将csv文件转成hfile文件的mr程序!
案例演示:
| Shell |
| ImportTsv命令的参数说明如下: -Dimporttsv.skip.bad.lines=false - 若遇到无效行则失败 -Dimporttsv.separator=, - 使用特定分隔符,默认是tab也就是 -Dimporttsv.timestamp=currentTimeAsLong - 使用导入时的时间戳 -Dimporttsv.mapper.class=my.Mapper - 使用用户自定义Mapper类替换TsvImporterMapper -Dmapreduce.job.name=jobName - 对导入使用特定mapreduce作业名 -Dcreate.table=no - 避免创建表,注:如设为为no,目标表必须存在于HBase中 -Dno.strict=true - 忽略HBase表列族检查。默认为false -Dimporttsv.bulk.output=/user/yarn/output 作业的输出目录 |
示例演示:
| Plain Text |
4.3hfile
4.3.1逻辑数据组织格式:

- Scanned block section:表示顺序扫描HFile时(包含所有需要被读取的数据)所有的数据块将会被读取,包括Leaf Index Block和Bloom Block;
- Non-scanned block section:HFile顺序扫描的时候该部分数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分;
- Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index等各种索引的元数据信息;
- Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
- Data Block:主要存储用户的key,value信息
- Meta Block:记录布隆过滤器的信息
- Root Data Index:DataBlock的根索引以及MetaBlock和Bloom Filter的索引
- Intermediate Level Index:DataBlock的第二层索引
- Leaf Level Index:DataBlock的第三层索引,即索引数的叶子节点
- Fileds for midKey:这部分数据是Optional的,保存了一些midKey信息,可以快速地定位到midKey,常常在HFileSplit的时候非常有用
- MetaIndex:即meta的索引数据,和data index类似,但是meta存放的是BloomFilter的信息
- FileInfo:保存了一些文件的信息,如lastKey,avgKeylen,avgValueLen等等
- Bloom filter metadata:是布隆过滤器的索引
4.3.2物理数据结构图:

4.3.3数据的读取
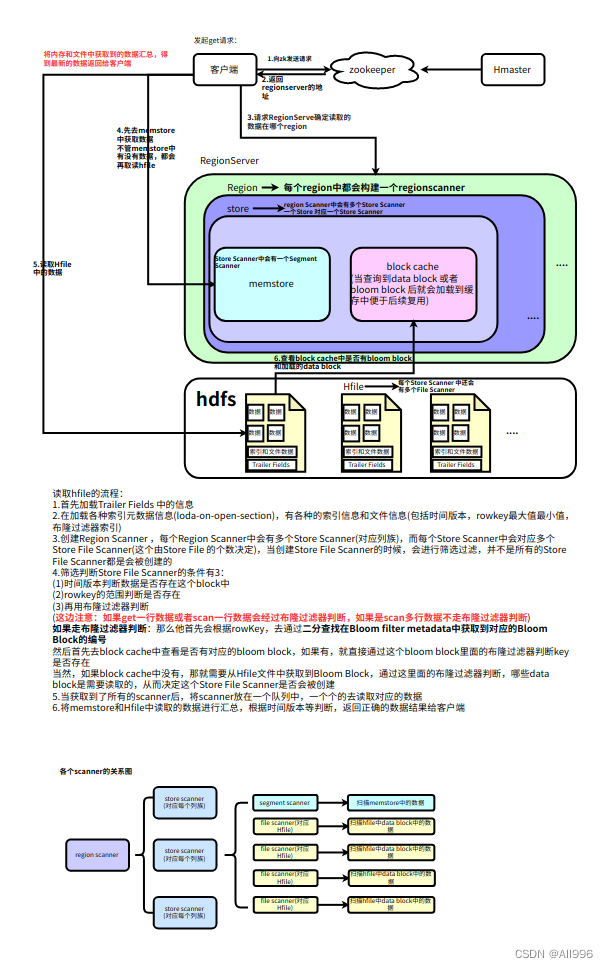
- Client访问zookeeper,获取hbase:meta所在RegionServer的节点信息
- Client访问hbase:meta所在的RegionServer,获取hbase:meta记录的元数据后先加载到内存中,然后再从内存中根据需要查询的RowKey查询出RowKey所在的Region的相关信息(Region所在RegionServer)
- Client访问RowKey所在Region对应的RegionServer,发起数据读取请求
- 读取memstore中的数据,看是否有key对应的value的值
- 不管memstore中有没有值,都需要去读取Hfile中的数据(再读取Hfile中首先通过索引定位到data block)
- 判断cache block中中是否已经加载过需要从文件中读取的bloom block和data block,如果加载过了,就直接读取cache block中的数据,如果没有,就读取文件中的block数据
- 将memstore和Hfile中读取的数据汇总取正确的数据返回给客户端
4.4rowkey的设计
4.4.1设计的三大原则
- Rowkey长度原则
Rowkey是一个二进制码流,Rowkey的长度被很多开发者建议设计在10-100个字节,不过建议是越短越好,不要超过16个字节
原因如下:
- 数据的持久化文件HFile中是按照KeyValue存储的,如果Rowkey过长比如100个字节,1000万列数据光Rowkey就要占用100*1000万=10亿个字节,将近1G数据,这会极大影响Hfile的存储效率;
- MemStore将缓存部分数据到内存,如果Rowkey字段过长内存的有效利用率降低,系统将无法缓存更多的数据,这会降低检索效率,因此Rowkey的字节长度越短越好。
- 目前操作系统一般都是64位系统,内存8字节对齐,空值在16个字节,8字节的整数倍利用操作系统的最佳特性。
- Rowkey散列原则
如果Rowkey是按时间戳的方式递增,因为rowkey是按照字典顺序排序的,这样会出现大量的数据插入到一个reion中,而其他的region相对比较空闲从而造成热点问题,所以尽量不要将开头相同的内容作为rowkey造成热点问题,可以将时间戳反转后在作为rowkey。
- Rowkey唯一原则
必须在设计Rowkey上保证其唯一性。否则前面插入的数据将会被覆盖。
4.4.2常见的避免热点的方法以及它们的优缺点
加盐
这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点。
哈希
哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转
第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。
比如手机号的反转,时间戳的反转,当一个连续递增的数字类型想要作为rowkey时,可以用一个很大的数去减这个rowkey,反转后再当成rowkey





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结