您现在的位置是:首页 >其他 >[笔记]C++并发编程实战 《五》C++内存模型和原子类型操作网站首页其他
[笔记]C++并发编程实战 《五》C++内存模型和原子类型操作
文章目录
前言
第5章 C++内存模型和原子类型操作
本章主要内容:
- C++11内存模型详解
- 标准库提供的原子类型
- 使用各种原子类型
- 原子操作实现线程同步功能
C++标准中,有一个十分重要特性,常被程序员们所忽略。它不是一个新语法特性,也不是新工具,它就是多线程(感知)内存模型。
内存模型没有明确的定义基本部件应该如何工作的话,之前介绍的那些工具就无法正常工作。那为什么大多数程序员都没有注意到它呢?
当使用互斥量保护数据和条件变量,或者是“期望”上的信号事件时,对于互斥量为什么能起到这样作用,大多数人不会去关心。只有当试图去“接触硬件”,才能详尽的了解到内存模型是如何起作用的。
C++是一个系统级别的编程语言,标准委员会的目标之一就是不需要比C++还要底层的高级语言。C++应该向程序员提供足够的灵活性,无障碍的去做他们想要做的事情;当需要的时候,可以让他们“接触硬件”。原子类型和原子操作就允许他们“接触硬件”,并提供底层级别的同步操作,通常会将常规指令数缩减到1~2个CPU指令。
本章,我们将讨论内存模型的基本知识,再了解一下原子类型和操作,最后了解与原子类型操作相关的各种同步。
这个过程会比较复杂:
- 除非已经打算使用原子操作(比如,第7章的无锁数据结构)同步你的代码;否则,就没有必要了解过多的细节。
让我们先轻松愉快的来看一下有关内存模型的基本知识。
5.1 内存模型基础
内存模型:
- 一方面是基本结构,这与内存布局的有关,
- 另一方面就是并发。并发基本结构很重要,特别是低层原子操作。
所以我将会从基本结构讲起,C++所有的对象都和内存位置有关。
5.1.1 对象和内存位置
一个C++程序中所有数据都是由对象构成。
不是说创建一个int的衍生类,或者是基本类型中存在有成员函数,或是像在Smalltalk和Ruby语言那样——“一切都是对象”。对象仅仅是对C++数据构建块的声明。
C++标准定义类对象为“存储区域”,但对象还是可以将自己的特性赋予其他对象,比如:
- 相应类型和生命周期。
像int或float这样的对象是基本类型。当然,也有用户定义类的实例。
一些对象(比如,数组,衍生类的实例,特殊(具有非静态数据成员)类的实例)拥有子对象,但是其他对象就没有。
无论对象是怎么样的类型,对象都会存储在一个或多个内存位置上。每个内存位置不是标量类型的对象,就是标量类型的子对象,比如,unsigned short、my_class*或序列中的相邻位域。
当使用位域时就需要注意:
- 虽然相邻位域中是不同的对象,但仍视其为相同的内存位置。
如图5.1所示,将一个struct分解为多个对象,并且展示了每个对象的内存位置。
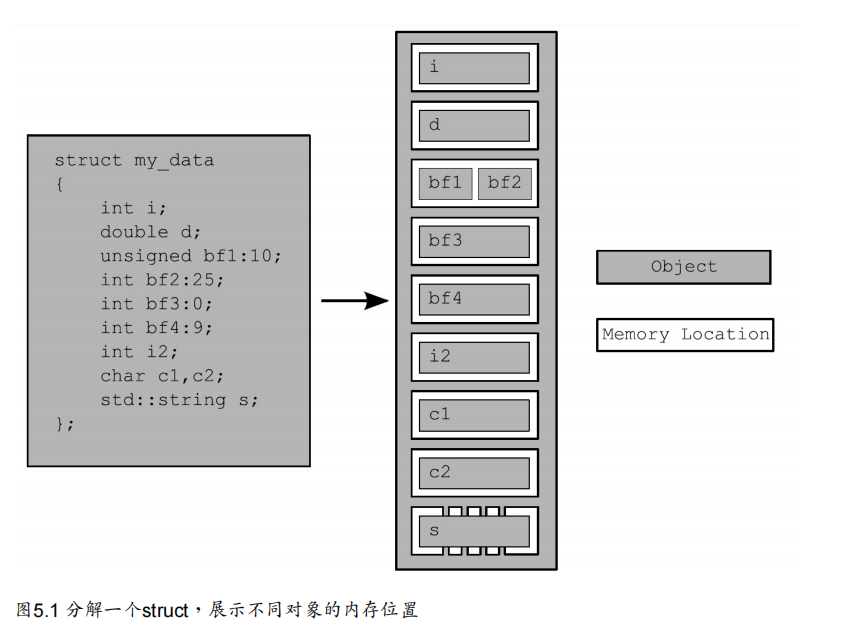
首先,完整的struct是一个有多个子对象(每一个成员变量)组成的对象。位域bf1和bf2共享同一个内存位置(int是4字节、32位类型),并且 std::string 类型的对象s由内部多个内存位置组成,但是其他的成员都拥有自己的内存位置。注意,位域宽度为0的bf3是如何与bf4分离,并拥有各自的内存位置的。
(译者注:图中bf3可能是一个错误展示,在C++和C中规定,宽度为0的一个未命名位域强制下一位域对齐到其下一type边界,其中type是该成员的类型。这里使用命名变量为0的位域,可能只是想展示其与bf4是如何分离的。有关位域的更多可以参考wiki的页面)。
这里有四个需要牢记的原则:
- 每一个变量都是一个对象,包括作为其成员变量的对象。
- 每个对象至少占有一个内存位置。
- 基本类型都有确定的内存位置(无论类型大小如何,即使他们是相邻的,或是数组的一部
分)。 - 相邻位域是相同内存中的一部分。
我确定你会好奇,这些在并发中有什么作用?下面就让我们来见识一下。
5.1.2 对象、内存位置和并发
这部分对于C++的多线程来说是至关重要的:所有东西都在内存中。当两个线程访问不同的内存位置时,不会存在任何问题,一切都工作顺利。当两个线程访问同一个内存位置,就要小心了。如果没有线程更新数据,那还好;只读数据不需要保护或同步。当有线程对内存位置上的数据进行修改,那就有可能会产生条件竞争,就如第3章所述的那样。
为了避免条件竞争,两个线程就需要一定的执行顺序。第一种方式,如第3章所述,使用互斥量来确定访问的顺序;当同一互斥量在两个线程同时访问前被锁住,那么在同一时间内就只有一个线程能够访问到对应的内存位置,所以后一个访问必须在前一个访问之后。另一种是使用原子操作(详见5.2节中对于原子操作的定义),决定两个线程的访问顺序。
使用原子操作来规定顺序在5.3节中会有介绍。当多于两个线程访问同一个内存地址时,对每个访问这都需要定义一个顺序。
如果不规定两个不同线程对同一内存地址访问的顺序,那么访问就不是原子的;并且,当两个线程都是“作者”时,就会产生数据竞争和未定义行为。
以下的声明由为重要:未定义的行为是C++中最黑暗的角落。根据语言的标准,一旦应用中有任何未定义的行为,就很难预料会发生什么事情;因为,未定义行为是难以预料的。我就知道一个未定义行为的特定实例,让某人的显示器起火的案例。虽然,这种事情应该不会发生在你身上,但是数据竞争绝对是一个严重的错误,需要不惜一切代价避免它。
另一个重点是:当程序对同一内存地址中的数据访问存在竞争,可以使用原子操作来避免未定义行为。当然,这不会影响竞争的产生——原子操作并没有指定访问顺序——但原子操作把程序拉回到定义行为的区域内。
在了解原子操作前,还有一个有关对象和内存地址的概念需要重点了解:
- 修改顺序。
5.1.3 修改顺序
每个C++程序中的对象,都有(由程序中的所有线程对象)确定好的修改顺序,且在初始化开始阶段确定。大多数情况下,这个顺序不同于执行中的顺序,但在给定的程序中,所有线程都需要遵守这个顺序。如果对象不是一个原子类型(将在5.2节详述),必须确保有足够的同步操作,来确定每个线程都遵守了变量的修改顺序。当不同线程在不同序列中访问同一个值时,可能就会遇到数据竞争或未定义行为(详见5.1.2节)。如果使用原子操作,编译器就有责任去做
必要的同步。
这意味着:
- 投机执行是不允许的,因为当线程按修改顺序访问一个特殊的输入,之后的读操作,必须由线程返回较新的值,并且之后的写操作必须发生在修改顺序之后。同样的,同一线程上允许读取对象的操作,要不就返回一个已写入的值,要不在对象的修改顺序后(也就是在读取后)再写入另一个值。虽然,所有线程都需要遵守程序中每个独立对象的修改顺序,但没有必要遵守在独立对象上的操作顺序。在5.3.3节中会有更多关于不同线程间操作顺序的内容。
所以,什么是原子操作?它如何来规定顺序?接下来的一节中,会揭晓答案。
5.2 C++中的原子操作和原子类型
原子操作是个不可分割的操作。系统的所有线程中,不可能观察到原子操作完成了一半;要么就是做了,要么就是没做,只有这两种可能。如果读取对象的加载操作是原子的,那么这个对象的所有修改操作也是原子的,所以加载操作得到的值要么是对象的初始值,要么是某次修改操作存入的值。
另一方面,非原子操作可能会被另一个线程观察到只完成一半。如果这个操作是一个存储操作,那么其他线程看到的值,可能既不是存储前的值,也不是存储的值,而是别的什么值。
如果非原子操作是一个加载操作,它可能先取到对象的一部分,然后值被另一个线程修改,然后它再取到剩余的部分,所以它取到的既不是第一个值,也不是第二个值,而是两个值的某种组合。如第3章所述,这就有了竞争风险,但在也就构成了数据竞争(见5.1节),会出现未定义行为。
C++中多数时候,需要原子类型对应得到原子的操作,我们先来看下这些类型。
5.2.1 标准原子类型
标准原子类型定义在头文件 中。这些类型的所有操作都是原子的,语言定义中只有这些类型的操作是原子的,不过可以用互斥锁来模拟原子操作。实际上,标准原子类型的实现就可能是这样模拟出来的:它们(几乎)都有一个 is_lock_free() 成员函数,这个函数可以让用户查询某原子类型的操作是直接用的原子指令( x.is_lock_free() 返回 true ),还是内部用了一个锁结构( x.is_lock_free() 返回 false )。
原子操作的关键就是使用一种同步操作方式,来替换使用互斥量的同步方式;如果操作内部使用互斥量实现,那么期望达到的性能提升就是不可能的事情。所以要对原子操作进行实现,最好使用用于获取且基于互斥量的实现来替代。这就是第7章所要讨论的无锁数据结构。
标准库提供了一组宏,在编译时对各种整型原子操作是否无锁进行判别。C++17中,所有原子类型有一个static constexpr成员变量,如果相应硬件上的原子类型X是无锁类型,那么X::is_always_lock_free将返回true。例如:给定目标硬件平台 std::atomic 可能是无锁的,所以 std::atomic::is_always_lock_free 将会返回true,不
过 std::atomic<uintmax_t> 可能只在最终运行的硬件上被支持时才没有锁,因为这是一个运行时属性,所以 std::atomic<uintmax_t>::is_always_lock_free 在该平台编译时可能为false。
宏都有ATOMIC_BOOL_LOCK_FREE , ATOMIC_CHAR_LOCK_FREE ,ATOMIC_CHAR16_T_LOCK_FREE , ATOMIC_CHAR32_T_LOCK_FREE ,ATOMIC_WCHAR_T_LOCK_FREE,ATOMIC_SHORT_LOCK_FREE ,
ATOMIC_INT_LOCK_FREE , ATOMIC_LONG_LOCK_FREE ,ATOMIC_LLONG_LOCK_FREE和ATOMIC_POINTER_LOCK_FREE。
它们指定了内置原子类型的无锁状态和无符号对应类型(LLONG对应long long,POINTER对应所有指针类型)。如
果原子类型不是无锁结构,那么值为0;如果原子类型是无锁结构,那么值为2;如果原子类
型的无锁状态在运行时才能确定,那么值为1。
只有 std::atomic_flag 类型不提供is_lock_free()。该类型是一个简单的布尔标志,并且在这种类型上的操作都是无锁的;当有一个简单无锁的布尔标志时,可以使用该类型实现一个简单的锁,并且可以实现其他基础原子类型。当觉得“真的很简单”时,就说明对 std::atomic_flag 明确初始化后,做查询和设置(使用test_and_set()成员函数),或清除(使
用clear()成员函数)都很容易。这就是:无赋值,无拷贝,没有测试和清除,没有任何多余操作。
剩下的原子类型都可以通过特化 std::atomic<> 类型模板得到,并且拥有更多的功能,但不可能都是无锁的(如之前解释的那样)。在主流平台上,原子变量都是无锁的内置类型(例如 std::atomic 和 std::atomic<void*> )。后面将会看到,每个特化接口所反映出的类型特点;位操作(如:&=)就没有为普通指针所定义,所以它也就不能为原子指针所定义。
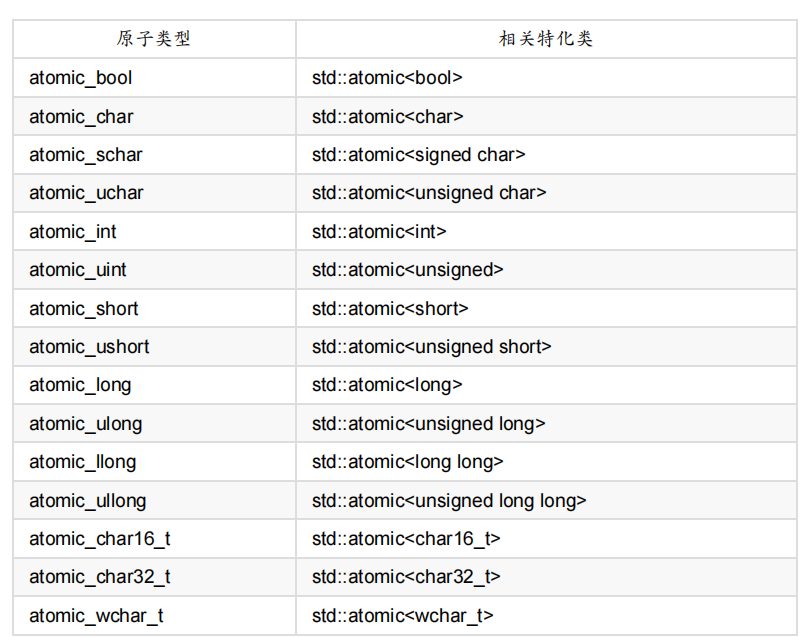
除了直接使用 std::atomic<> 类型模板外,你可以使用在表5.1中所示的原子类型集。由于历史原因,原子类型已经添加入C++标准中,这些备选类型名可能参考相应的 std::atomic<> 特化类型,或是特化类型。同一程序中混合使用备选名与 std::atomic<> 特化类名,会使代码的移植性大打折扣。
表5.1 标准原子类型的备选名和与其相关的 std::atomic<> 特化类
C++标准库不仅提供基本原子类型,还定义了与原子类型对应的非原子类型,就如同标准库中的 std::size_t 。如表5.2所示这些类型:
表5.2 标准原子类型定义(typedefs)和对应的内置类型定义(typedefs)

好多种类型!不过,它们有一个相当简单的模式;对于标准类型进行typedef T,相关的原子类型就在原来的类型名前加上atomic_的前缀:atomic_T。除了singed类型的缩写是s,unsigned的缩写是u,和long long的缩写是llong之外,这种方式也同样适用于内置类型。对于 std::atomic 模板,使用相应的T类型去特化模板的方式,要好于使用别名的方式。
通常,标准原子类型是不能进行拷贝和赋值的,它们没有拷贝构造函数和拷贝赋值操作符。
但是,可以隐式转化成对应的内置类型,所以这些类型依旧支持赋值,可以使用load()和store()、exchange()、compare_exchange_weak()和compare_exchange_strong()。
它们都支持复合赋值符:+=, -=, *=, |= 等等。并且使用整型和指针的特化类型还支持++和–操作。当然,这些操作也有功能相同的成员函数所对应:fetch_add(), fetch_or()等等。赋值操作和成员函数的返回值,要么是被存储的值(赋值操作),要么是操作前的值(命名函数),这就能避免赋值操作符返回引用。为了获取存储在引用中的值,代码需要执行单独的读操作,从而允许另一个线程在赋值和读取的同时修改这个值,这也就为条件竞争打开了大门。
std::atomic<> 类模板不仅仅是一套可特化的类型,作为一个原发模板也可以使用用户定义类型创建对应的原子变量。因为,它是一个通用类模板,操作被限制为load(),store()(赋值和转换为用户类型),exchange(),compare_exchange_weak()和compare_exchange_strong()。
每种函数类型的操作都有一个内存排序参数,这个参数可以用来指定存储的顺序。5.3节中,会对存储顺序选项进行详述。现在,只需要知道操作分为三类:
- Store操作,可选如下顺序:memory_order_relaxed, memory_order_release,
memory_order_seq_cst。 - Load操作,可选如下顺序:memory_order_relaxed, memory_order_consume,
memory_order_acquire, memory_order_seq_cst。 - Read-modify-write(读-改-写)操作,可选如下顺序:memory_order_relaxed,
memory_order_consume, memory_order_acquire, memory_order_release,
memory_order_acq_rel, memory_order_seq_cst。
总结
本章中已经对C++内存模型的底层知识进行详尽的了解,并且了解了原子操作能在线程间提供同步。包含基本的原子类型,由 std::atomic<> 类模板和 std::experimental::atomic_shared_ptr<> 模板特化后提供的接口;以及对于这些类型的操作,还要有对内存序列选项的各种复杂细节,都由 std::atomic<> 类模板提供。
也了解了栅栏,如何让执行序列中,对原子类型的操作成对同步。最后,回顾了本章开始的一些例子,了解了原子操作也可以在不同线程上的非原子操作间使用,并进行有序执行。以及了解了高级工具所提供的同步能力。
下一章中,我们将看到如何使用高级同步工具,以及使用原子操作并发的设计访问高效的容器,我们还将编写一些并行处理数据的算法。
关于博主
wx/qq:binary-monster/1113673178
CSDN:https://blog.csdn.net/qq1113673178
码云:https://gitee.com/shiver
Github: https://github.com/ShiverZm
个人博客:www.shiver.fun






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结