您现在的位置是:首页 >学无止境 >第七周:机器学习学习周报网站首页学无止境
第七周:机器学习学习周报
目录
摘要
在机器学习中训练模型的时候,为了及时发现模型存在的问题,会选择使用验证集进行阶段测试避免出现over fitting。但尽管在使用Validation Set决定模型的情况下,如果候选模型空间很大,那么选出来的Validation Set可能效果会很差,因此还是会产生over fitting。
在神经网络中,事实上,当实现同一个复杂函数,使用深度较大宽度较小的网络,相较于只有一层而宽度很大的网络来说,其参数量会小很多,也就是说其效率会更高,同时参数量小也就说明需要的训练数据量也会小,也就更加不容易过拟合。总而言之,深度学习可以减少模型中function的数量,需要的训练数据更少,并且效果也能够与宽度很大的神经网络相当。
Abstract
When training models in machine learning, in order to discover problems in the model in a timely manner, we will choose validation sets for stage testing to avoid overfitting. However, although in the case of using a Validation Set to determine the model,If the candidate model space is large, the selected Validation Set may have poor performance, thus still lead to over fitting.
In the neural networks, when implementing the same complex function and using networks with larger depths and smaller widths, compared to networks with only one layer and larger widths, the number of parameters is much smaller, which means its efficiency is higher. At the same time, the small number of parameters also means that the amount of training data required is also smaller, making it less easy to overfit. In summary, deep learning can reduce the number of functions in the model, require less training data, and achieve results comparable to neural networks with large widths.
1 为什么用了验证集结果还是过拟合
使用验证集可以筛选掉那些在训练集上过拟合的模型,那为什么用了验证集还是出现过拟合呢?
1.1 回顾验证集(Validation Set)
在选择模型的时候,先在Trining Set上找出三个模型表示的function中最好的那个function分别表示为、
、
,但不会直接在Training Set上确定它们三个哪个更好,实际上会做的是,分别计算
、
、
在Validation Set上Loss,看哪一个function在Validation Set上得到的Loss最低,再选择该function用在Testing Set(所有可能的data)上。

验证集用途及好处:
验证集可以用在训练的过程中,在训练模型时,跑完几个epoch结束后,就会跑一次验证集的数据看看效果,验证集不会跑得太频繁,否则会影响训练的速度。
这样做的第一个好处是,可以及时发现模型或者参数的问题,比如模型在验证集上的结果发散、或出现例如无穷大的奇怪的结果、mAP不增长或者增长很慢等情况,那么就可以及时终止训练,重新调参或者调整模型,而不需要等到训练结束。另外一个好处是验证模型的泛化能力,如果在验证集上的效果比训练集上差很多,就该考虑模型是否过拟合了。同时,还可以通过验证集对比不同的模型。
模型的参数包括普通参数和超参数(与模型设计和训练有关的一些参数),利用bp只能训练普通参数,而无法“训练”模型的超参数,因此,我们设置了验证集,通过验证集的效果进行反馈,根据效果看是否需要终止当前的模型训练,更改超参之后再训练,最终得到最优的模型!
Q:为什么在Validation Set上挑选Model的过程也可以想象成是一种Training呢?
A:在mode
组成的集合中,假设现在里有三种function分别是
、
、
,接下来在Validation Set上做”training”,做Validation Set就是在

1.2 通过验证集/训练集判断拟合
过拟合:训练集中错误率很低,但是验证集中错误率比验证集中高很多.方差很大.
欠拟合:训练集中错误率相对比较高,但是验证集的错误率和训练集中错误率差别不大.偏差很大.
偏差和方差都很大: 如果训练集得到的错误率较大,表示不能很好的拟合数据,同时验证集上的错误率甚至更高,表示不能很好的验证算法.这是偏差和方差都很大的情况.
较好的情况::训练集和验证集上的错误率都很低,并且验证集上的错误率和训练集上的错误率十分接近.
1.3 over fitting的原因
这件事情跟over fitting有什么关系呢?
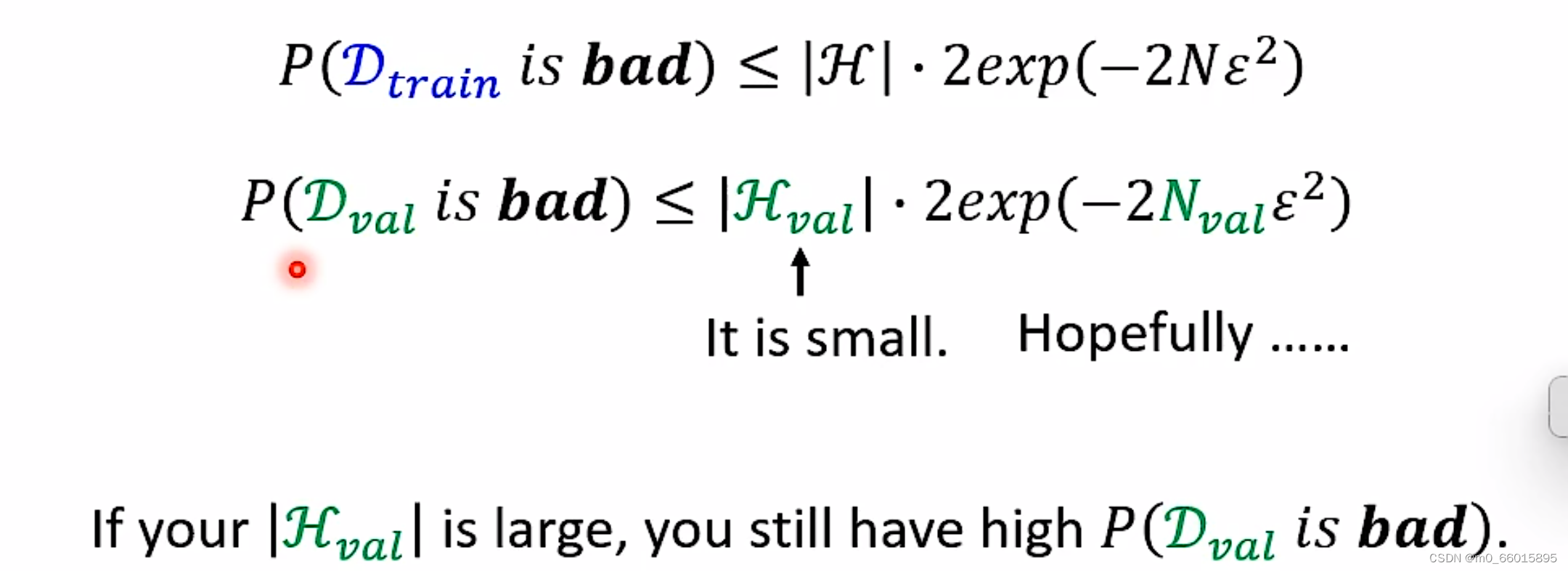
抽到不好的Training Data取决于的因素
①训练资料数量
②模型的复杂度(越复杂抽到的training data越差)
抽到不好的Validation Set取决于的因素
①Validation Set的大小
②对应模型
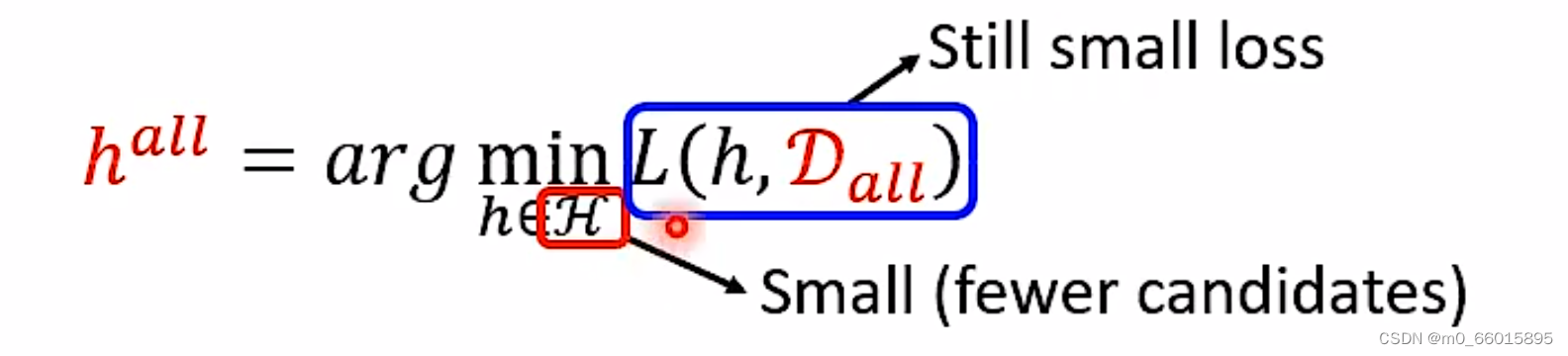
因此可以看出增加训练集样本的数据N或者减少假设空间的大小∣H∣都可以使得拿到坏数据集的概率降低
如果我们在训练过程中扩大了超参数的搜索空间|H|,进行了大量的超参数搜索,同时验证集的样本数量N又不够大,就很容易导致上面不等式的误差概率上界很高,从而以高概率选中一种”误差“很大的模型超参数,造成过拟合。
也就是说如果用Validation Set决定模型的时候,待选择的模型如果太多了即
2 鱼和熊掌可兼得-深度学习
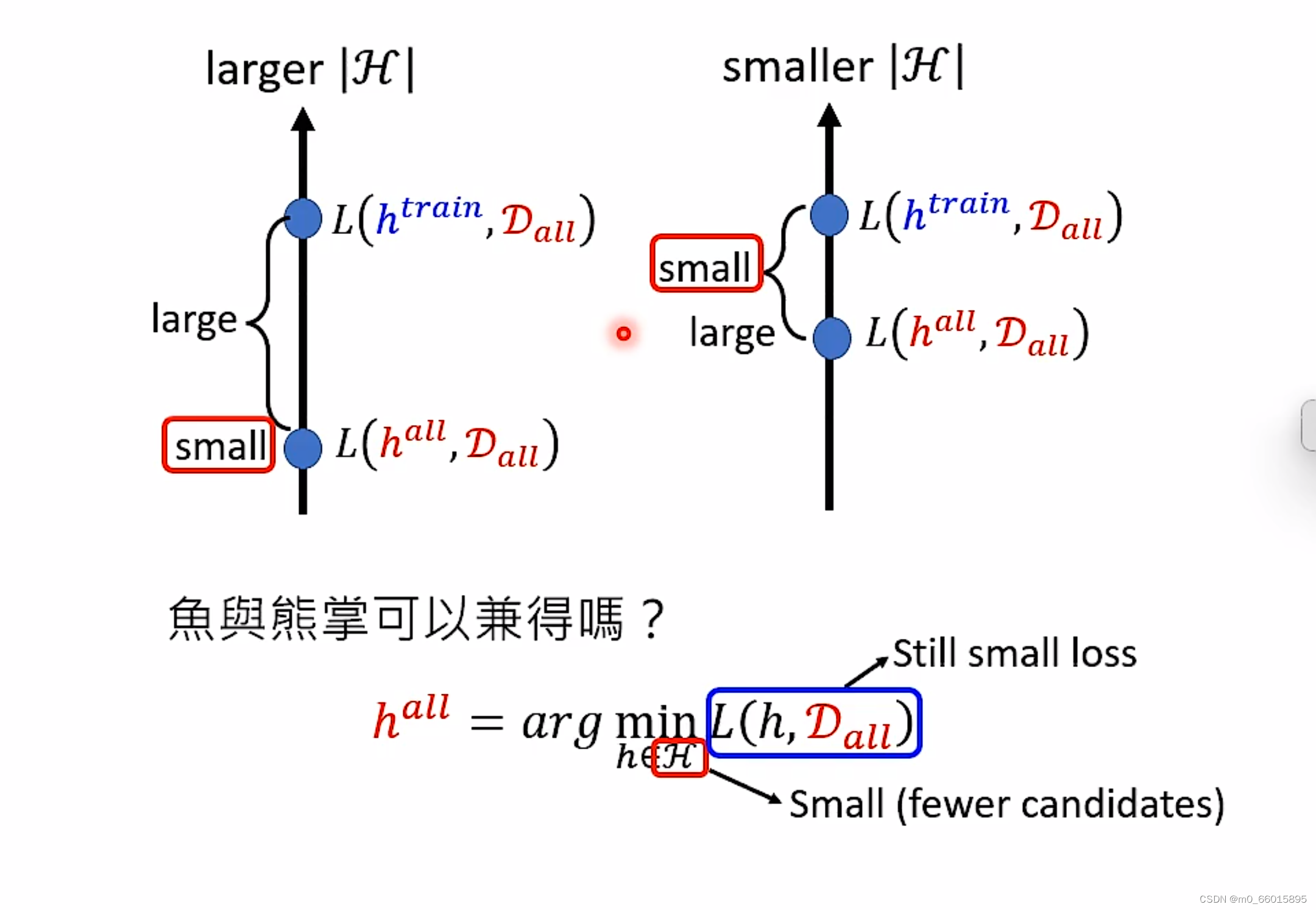
当候选模型空间|H|很大的时候,可以选择的function很多,因此在实际上的Loss可以很小,但是理想和现实差距很大,当候选模型空间|H|很小的时候,可以选择的function很少,那么在实际上的loss就会比较大,但理想和现实却可以比较接近,鱼和熊掌怎么兼得?那么有没有可能有一个loss很低的完美假设,同时还能够让现实训练出来的假设和理想很接近呢?,即图中两个small都要。
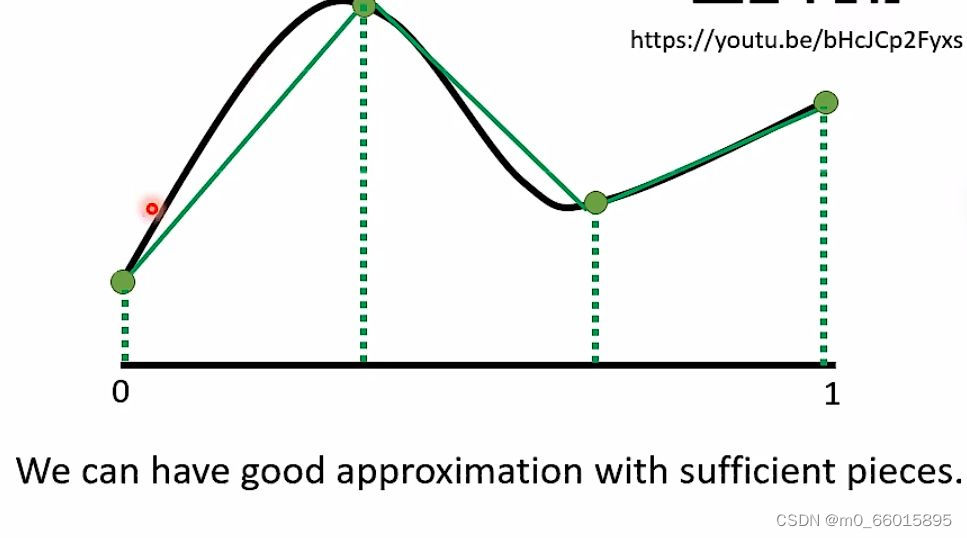
2.1 回顾:为什么我们需要深度学习
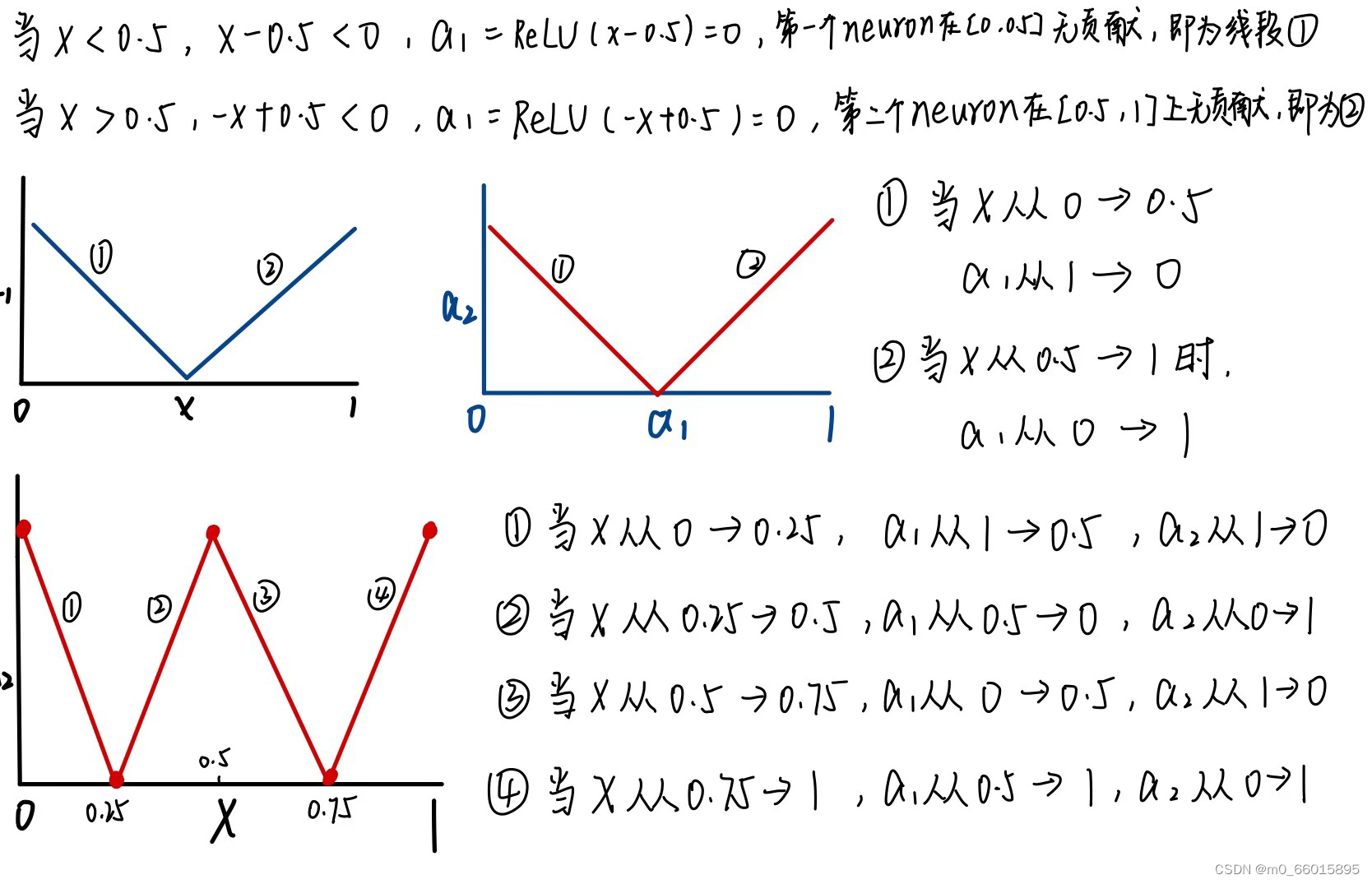
通过深度学习可以制造出所有可能的function,输入是图中C轴,输出是Y轴,怎么找到一个function用神经网来产生这条线呢?只要分的点足够的细,即生成的直线越多,就越能逼近曲线。
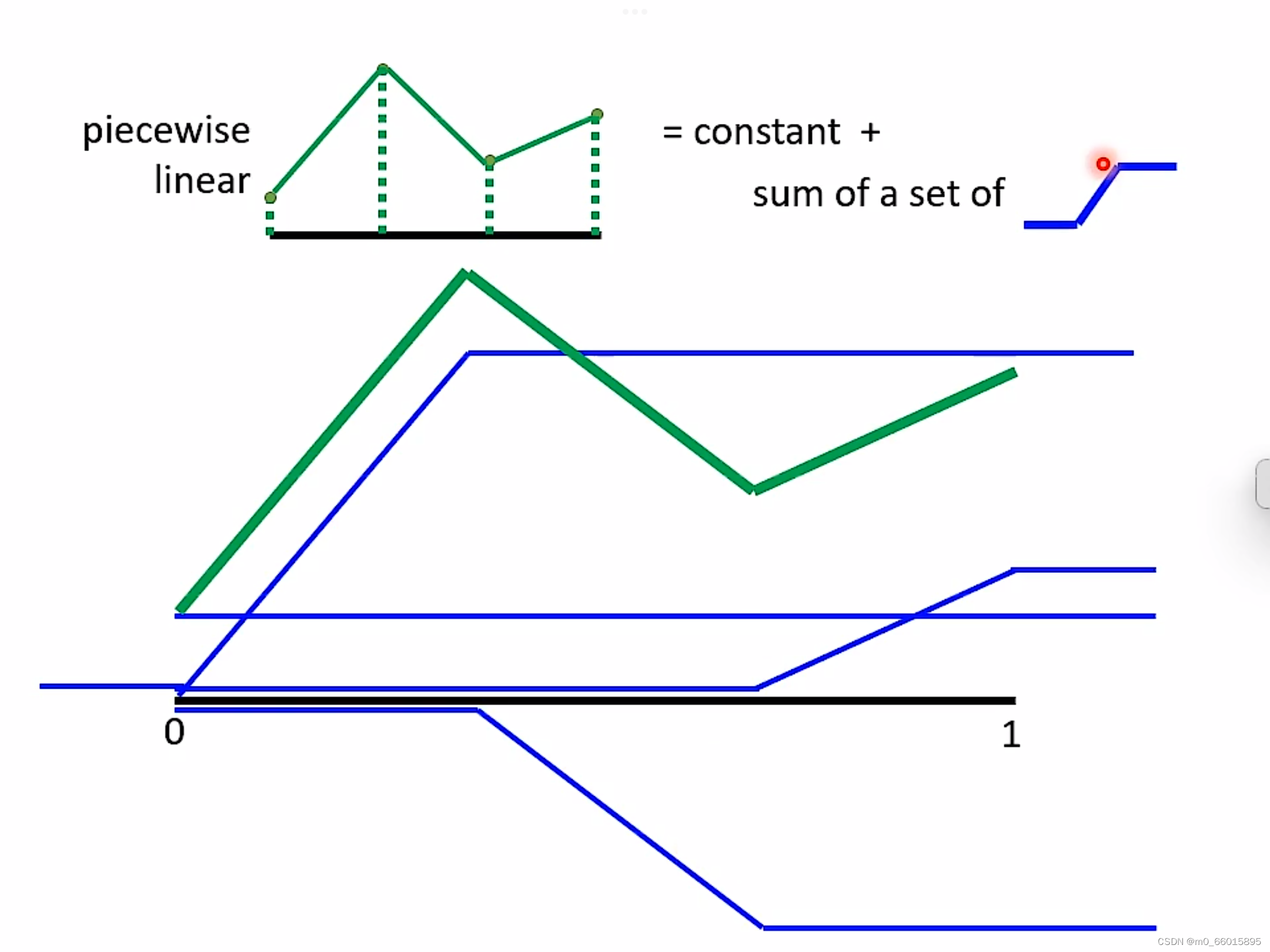
piecewise linear = 常量+若干个neuron。即这个绿色的线,可以由每一个neural产生的蓝色的线拼凑而成,任何再复杂的function只要有足够的neuron就可以产生。
为了表现这个function,最后经过sigmoid把它曲线化,结果化为0-1之间的数值。
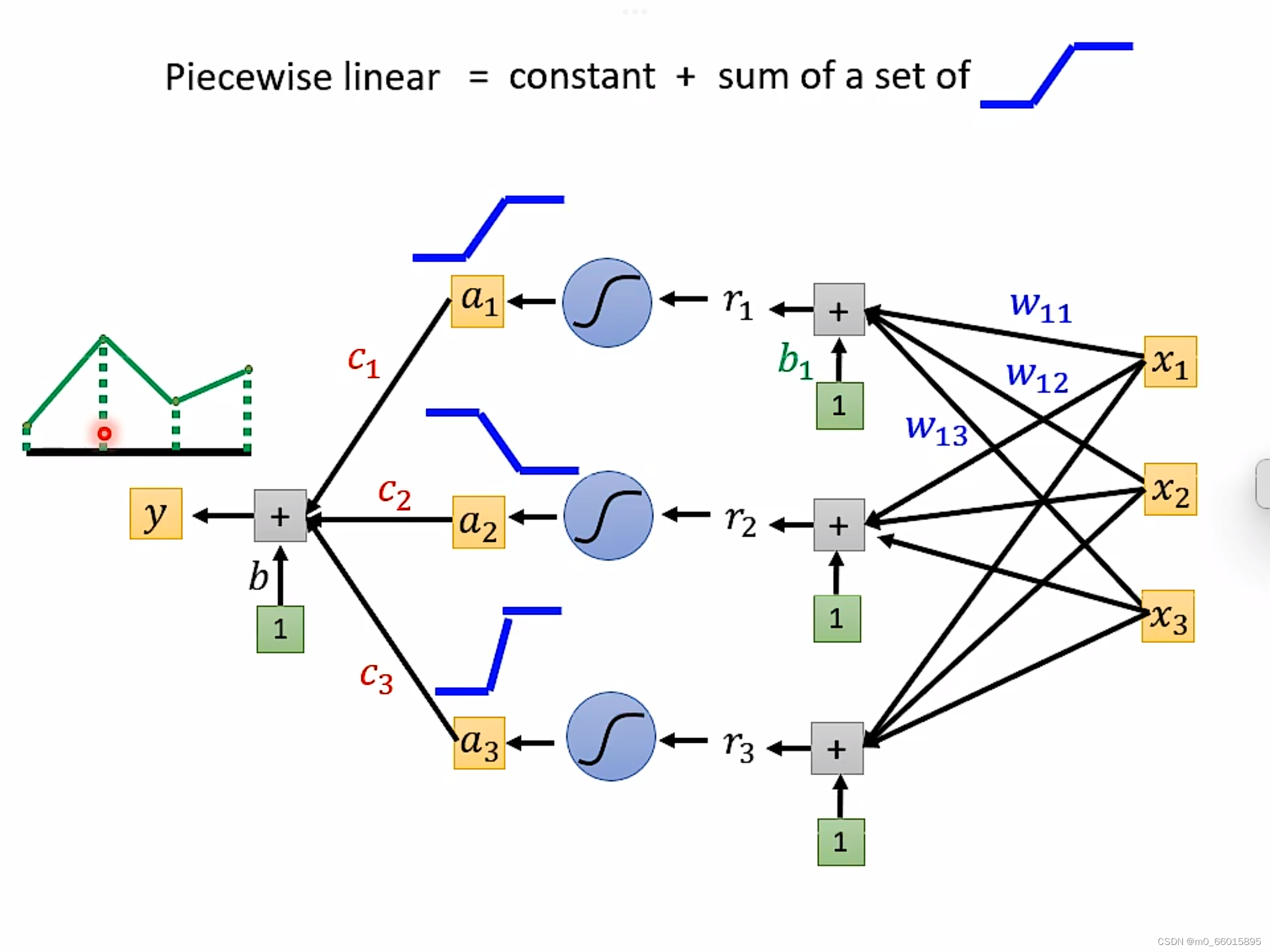
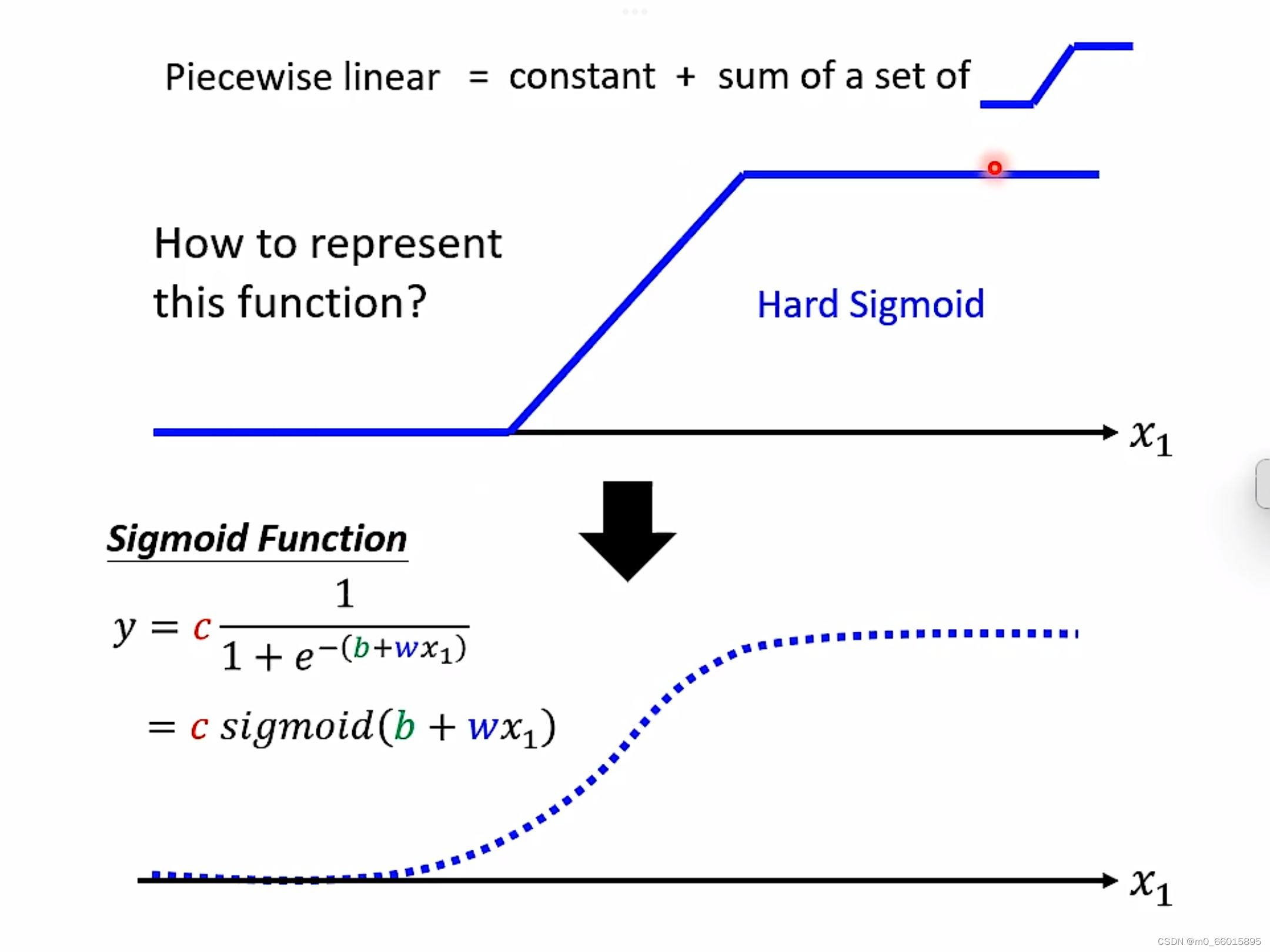 通过设置不同weigh权重以及不同的bias制造出不同的sigmoid function,把他们统统加起来再加上常数,你可以得到任何的picewiselinear function。
通过设置不同weigh权重以及不同的bias制造出不同的sigmoid function,把他们统统加起来再加上常数,你可以得到任何的picewiselinear function。
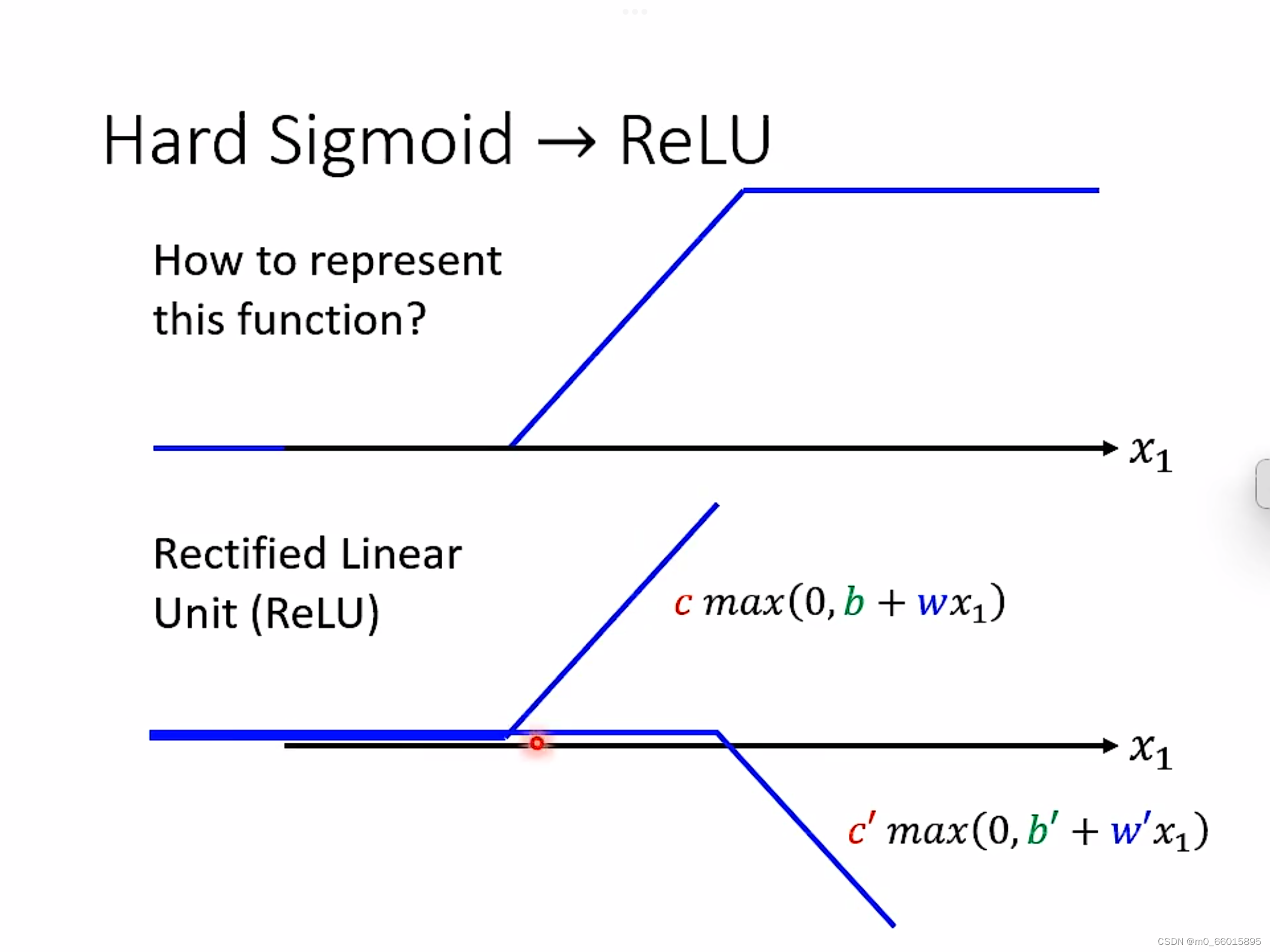
 Hard Sigmoid的另一种方法就是ReLU,可以把sigmoid换成ReLU,两个ReLU可以合成一个hard sigmoid,够多的hard sigmoid就能形成piecewiselinear function,而picewiselinear function可以逼近任何的function。
Hard Sigmoid的另一种方法就是ReLU,可以把sigmoid换成ReLU,两个ReLU可以合成一个hard sigmoid,够多的hard sigmoid就能形成piecewiselinear function,而picewiselinear function可以逼近任何的function。
2.2 深度学习
当越来越深时,H就越来越大就代表你的理想越来越美好!如果你有巨大的训练资料,你的效果就会很好!这就是深度学习
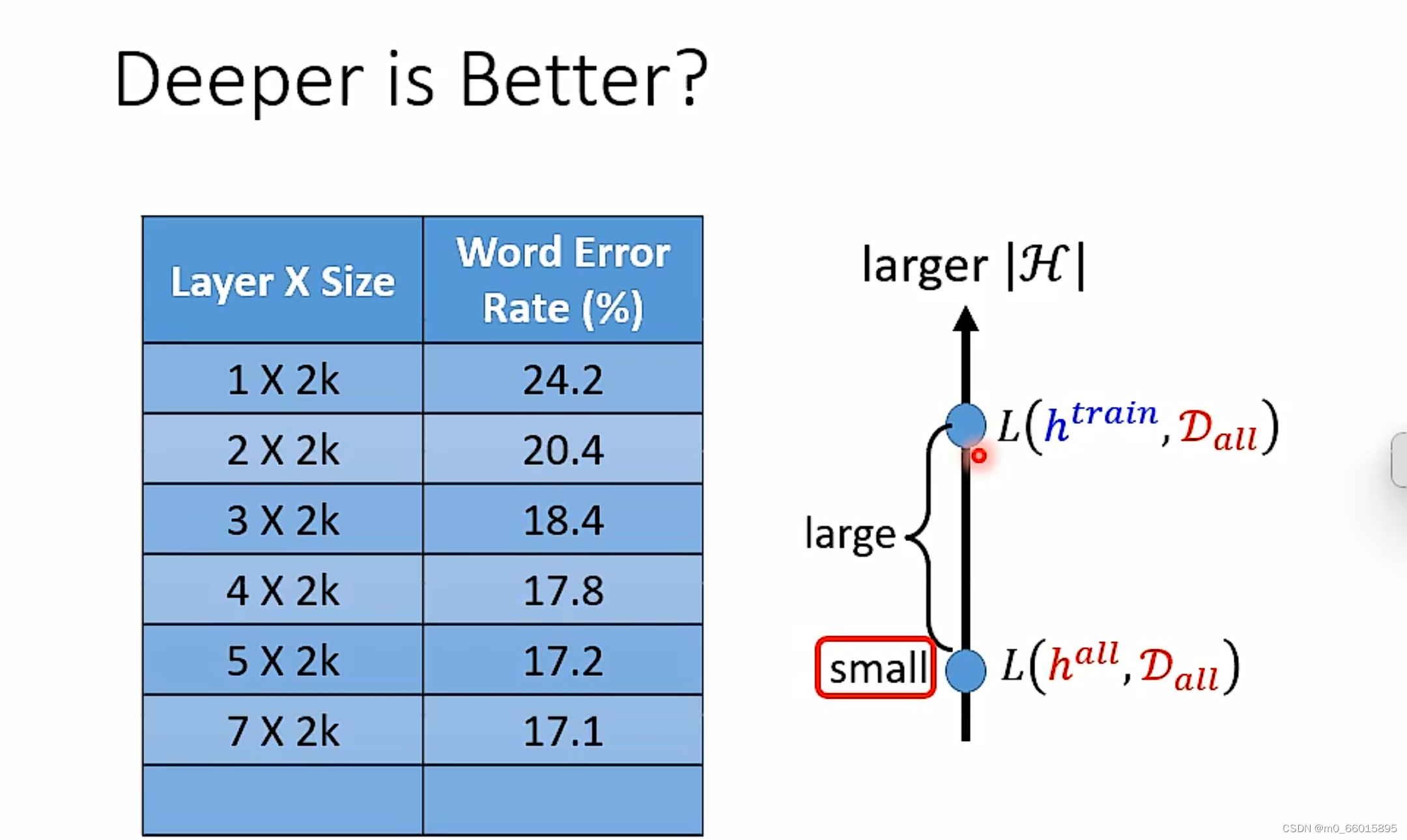
在现实生活中,neuron越深错误率可能越低,但是越深的neuron产生的模型就会越复杂,那么理想的loss就会很低,要想要现实和理想接近,按照公式可以得出,就需要有更多的Data。
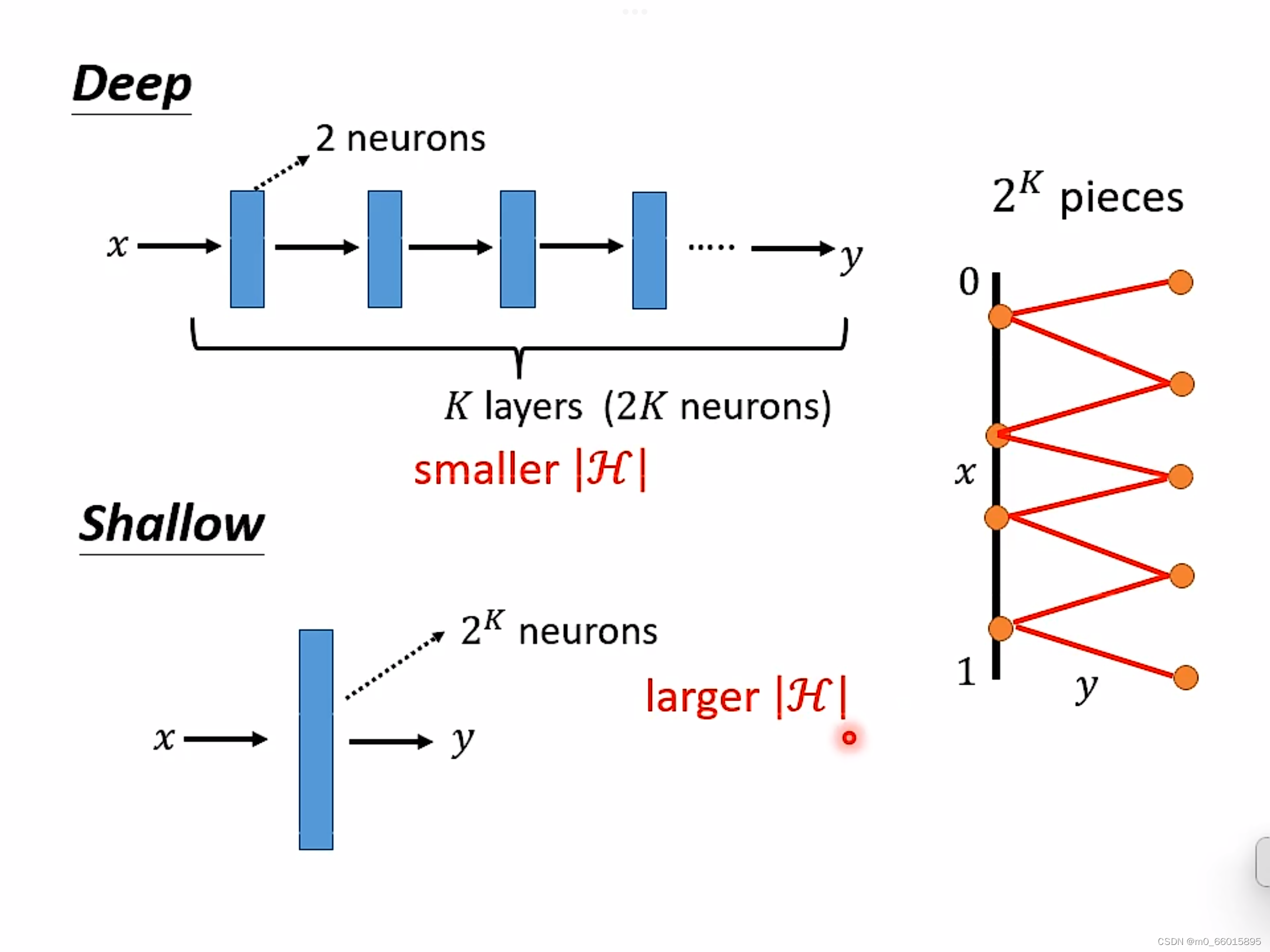
2.2.1 胖矮VS瘦高
当参数一样的时候,是选择矮胖(层数少neuron多)的还是选择高瘦(层数深neuron少)的更好?
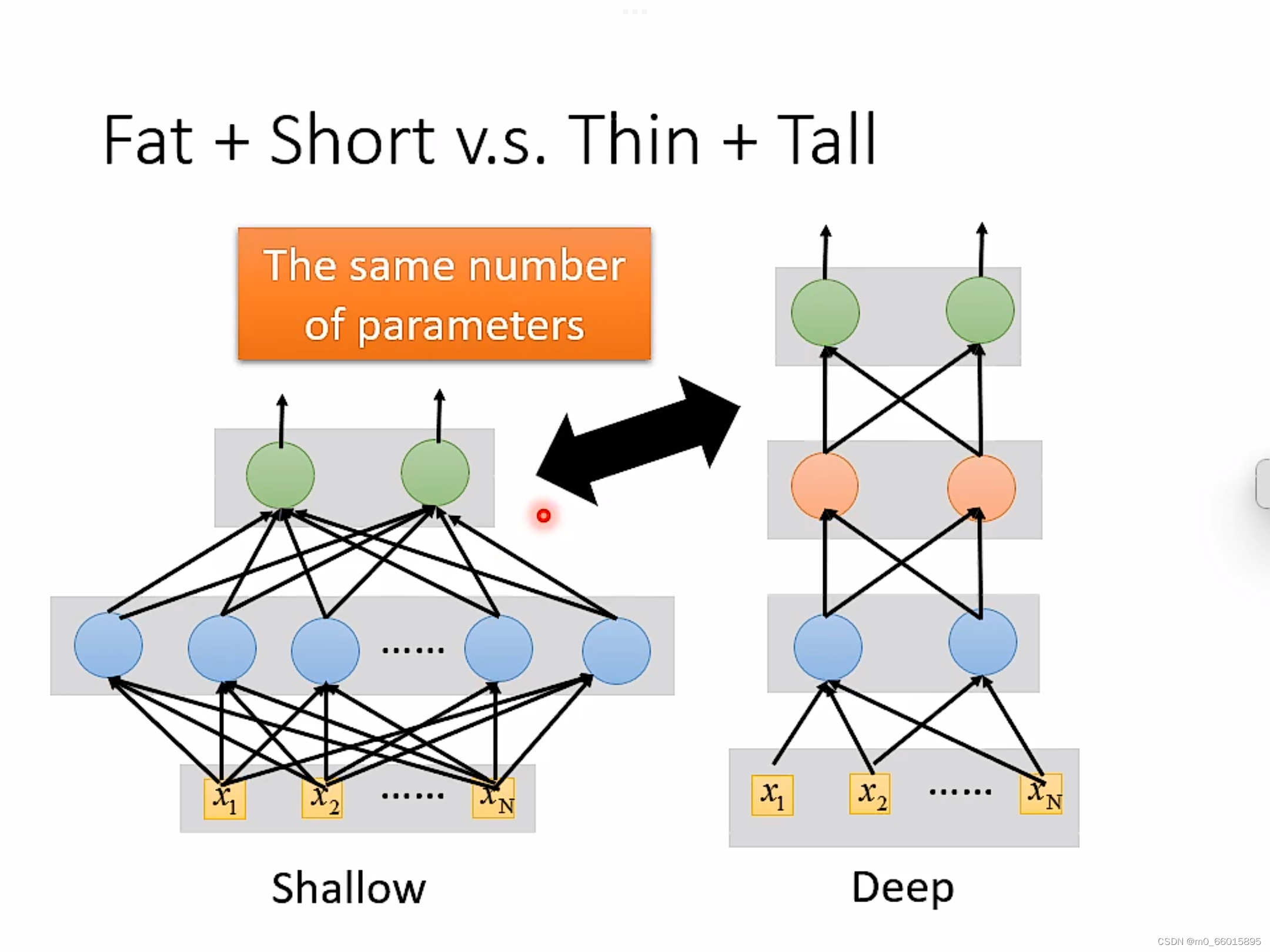
从测试结果的错误率来看,当参数量一样时高瘦明显比矮胖效果更好。这是为什么呢?
因为实现同一个funciton时,深的只需要比胖的更少的参数就能达到效果。
事实上,在实现同一个复杂函数时,使用深度较大宽度较小的网络,相较于只有一层而宽度很大的网络来说,其参数量会小很多,也就是说其效率会更高,同时参数量小也就说明需要的训练数据量也会小,也就更加不容易过拟合。
总而言之,深度学习可以使得function的集合H的大小减小,并且效果也能够与宽度很大的神经网络相当。如果让你loss很低的那个function是复杂且有规律的(语音、影像等),那么deep neuron会优于shallow neuron,深度学习的效果可以更好,其参数量可以更小。
2.2.2 Analogy
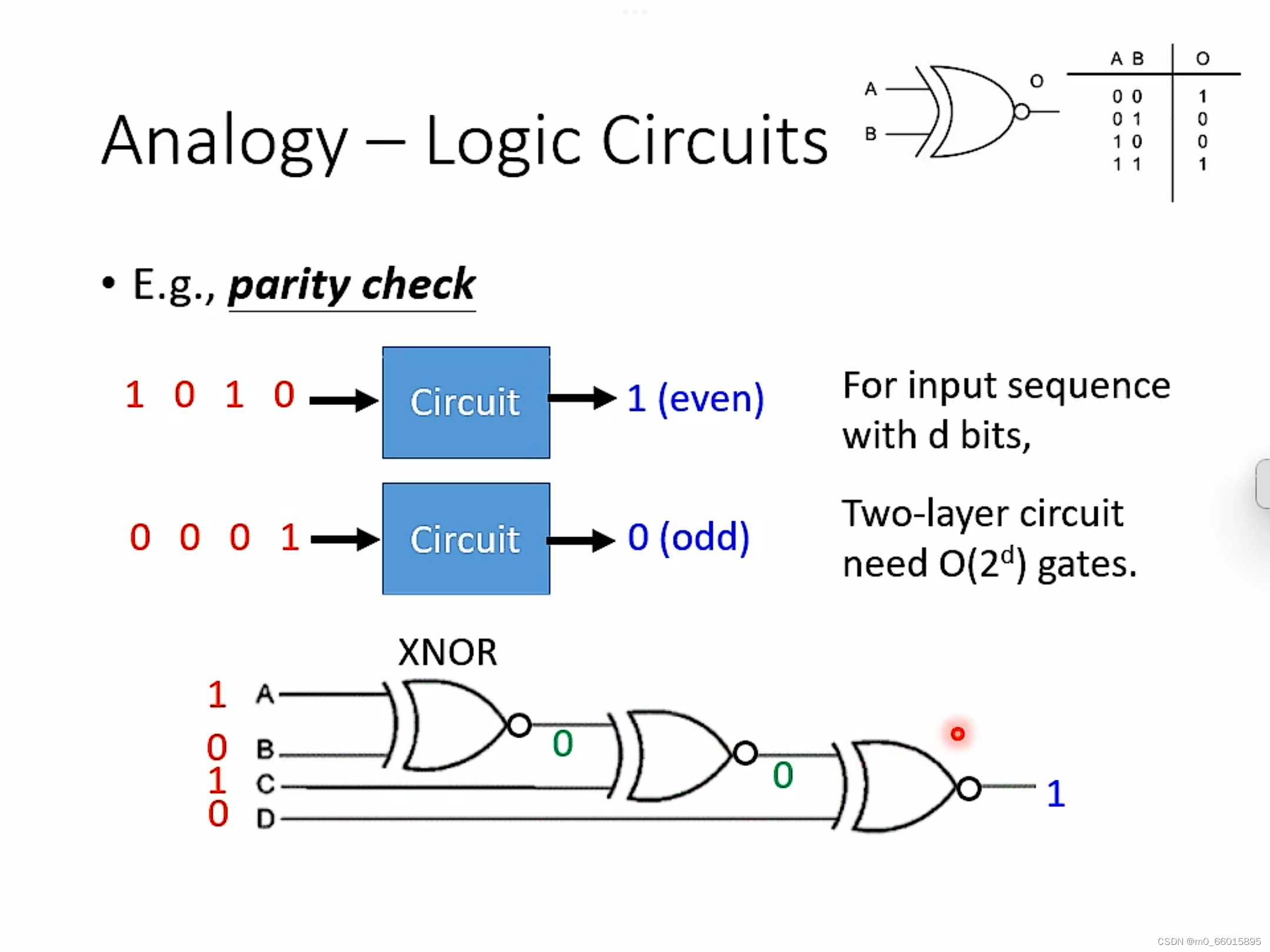
2.2.2.1 逻辑电路
首先用逻辑电路的例子说明一下,对于表示同样的逻辑表达式,单层网络需要O( )个门电路,但是如果是多层结构,只需要O(d)个门电路。
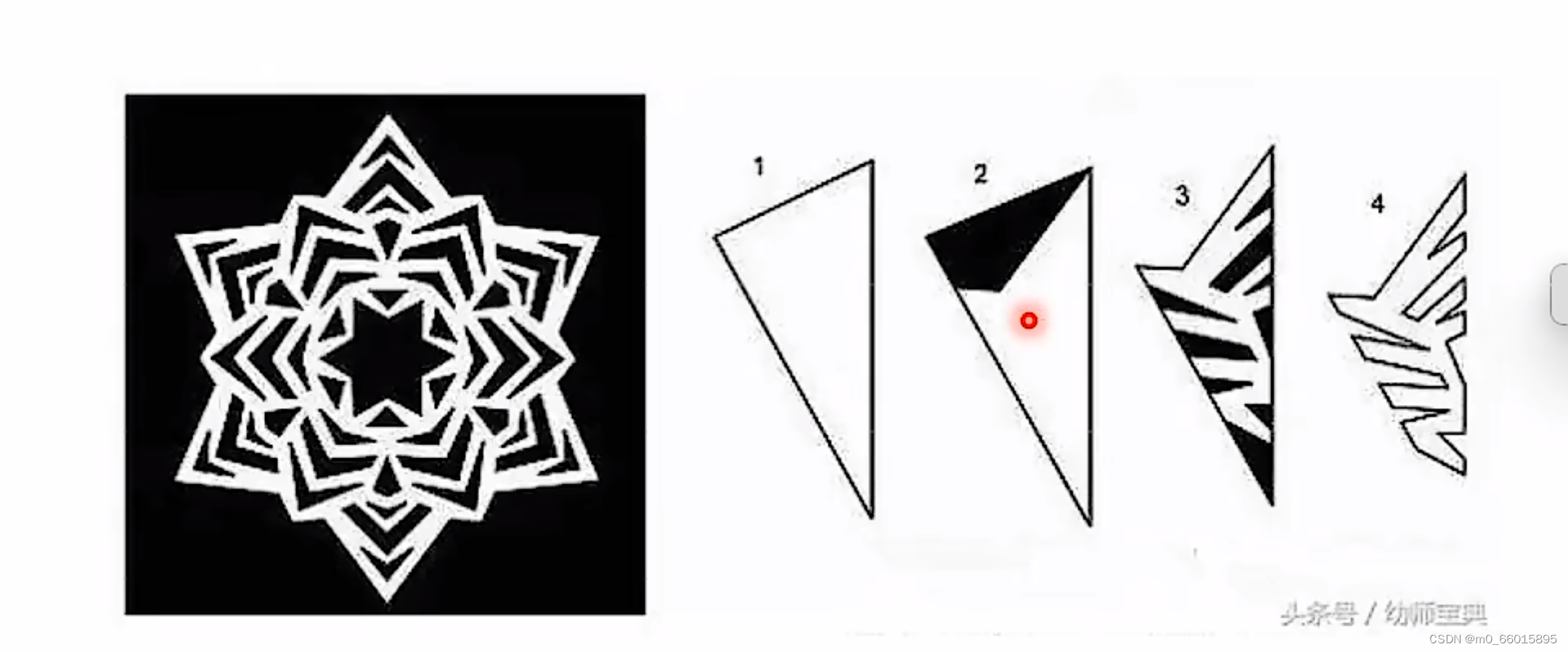
2.2.2.2.窗花
在剪窗花的时候,可以折起来一次性剪好,如果一整张减可能要花费几倍的时间,这个折叠起来剪得工作就类似于深度学习做的事情。
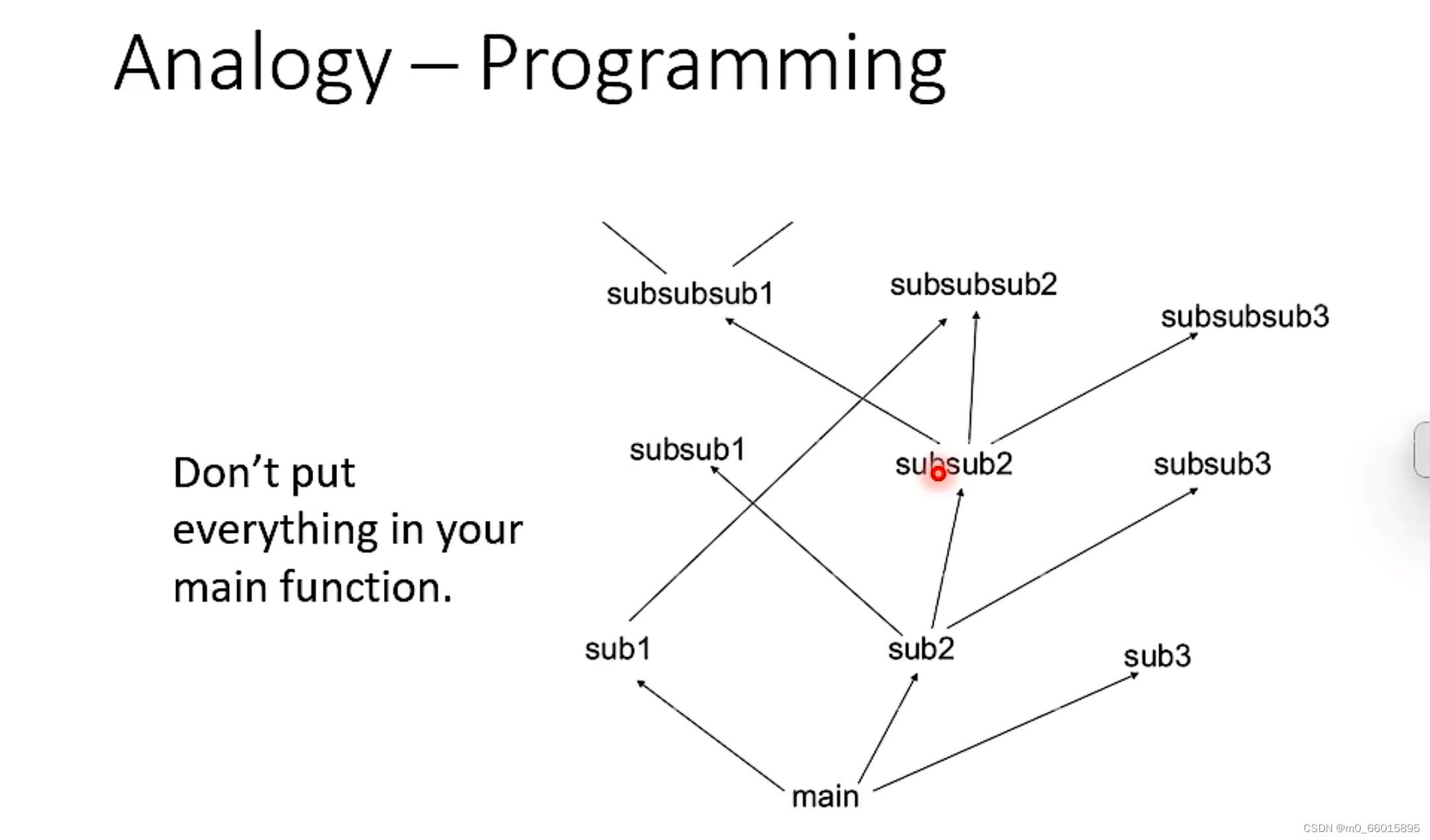
2.2.2.3 编程
在进行模块化编程的时候,设计思想就是将一个功能封装为一个函数,函数是可以重复调用的,这因此可以增加复用性,提高开发效率。
2.2.3 Deep Network
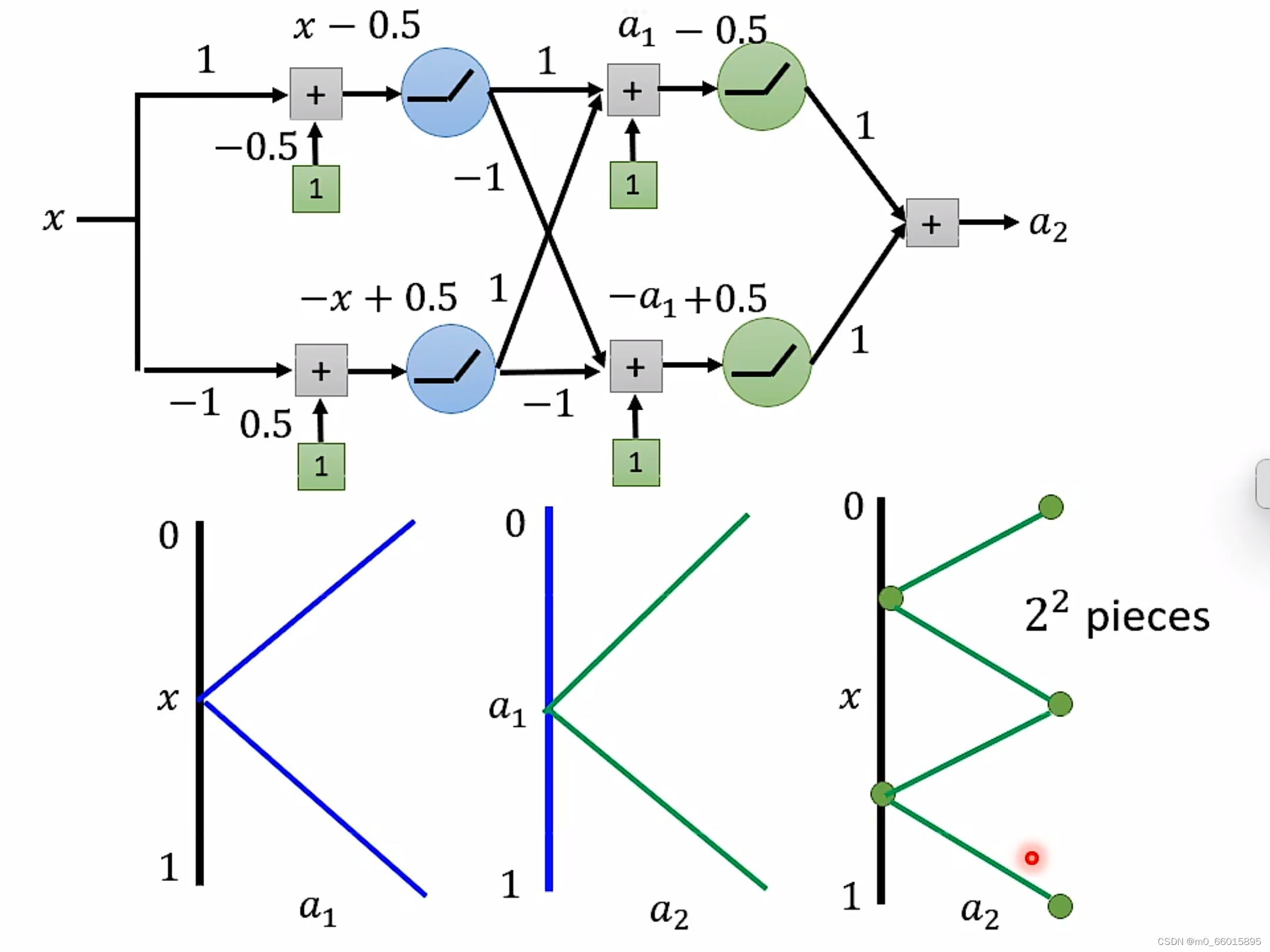
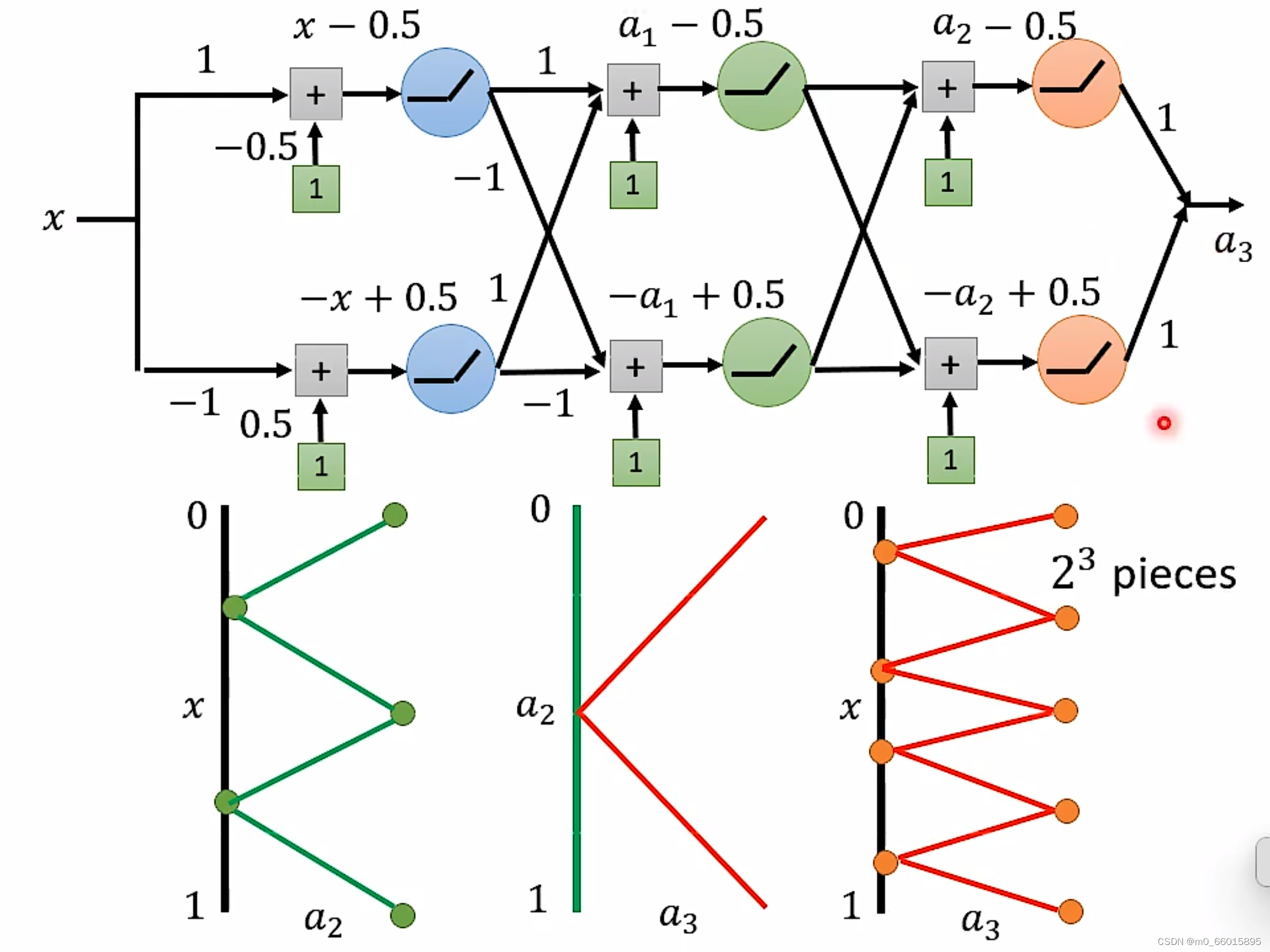
如果同样要实现
的锯齿线段,两者之间区别:
对于Deep来说,每一层只需要两个neuron,有K层,因此总共需要2K个neuron即可。
对于Shallow来说,只有一层,如果使用ReLU,那么每一个neuron只能产生一条线段,那么要生成
要产生同样的function,Deep的neuron参数量比较小,它有有比较简单的模型,而Shallow的参数量比较大,需要一个比较复杂的模型。而复杂的模型因为比较容易过拟合,因此需要大量的资料。由此可是,要做到同样的事情,Shallow需要的资料远远大于Deep。
总结
1、我们在利用验证集进行超参数搜索的时候一定要注意不能无限制地扩大超参数搜索空间,同时构造相对更大样本数的验证集的也是一种减少过拟合风险的途径。除此之外需要注意的是,测试集不能被用作训练模型的信号,只能用作模型的评估。
2、如果目标function,即可以让Loss很低的那个function是复杂且有规律的话(语音、影像),那Deep network会比shallow network表现得更好,这就是为什么今天深度学习在解决语言、影像等问题上效果非常好。
2、想要做到鱼和熊掌兼得,首先要使模型的复杂度小,即模型所需的参数量少,避免模型太复杂造成过拟合,才有可能从H里面找到一个h使得Loss值很小,兼得即H很小Loss很低两者同时成立。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结