您现在的位置是:首页 >技术交流 >主从架构&lua脚本-Redis(四)网站首页技术交流
主从架构&lua脚本-Redis(四)
上篇文章介绍了rdb、aof持久化。
持久化RDB/AOF-Redis(三)![]() https://blog.csdn.net/ke1ying/article/details/131148269
https://blog.csdn.net/ke1ying/article/details/131148269
- redis数据备份策略
- 写job每小时copy一份到其他目录。
- 目录里可以保留最近一个月数据。
- 把目录日志保存到其他服务器,防止机器损坏。
- 主从复制
第一步:复制一份redis.conf
第二步:将相关配置修改如下
Port 6380
# 把pid进程号写入pidfile配置文件
Pidfile /var/run/redis_6380.pid
Logfile “6380.log”
Dir /usr/local/redis-5.0.3/data/6380
第三步:配置主从(重要)
# 从本机6379额redis复制数据
Replicaof 192.168.81.128 6379
# 只读不写
Replica-read-only yes
第四步:启动从节点
src/redis-server redis_6380.conf
第五步:连接从redis
Src/redis-cli -p 6380

从我搭建的结果可以看到:
6379redis写入数据,在6380里是可以看到的,并且因为配置了只读,所以我在6380redis里操作set命令不能成功。
全量复制:
1、当你为master配置了slave,不管是否是第一次连接,都会发送PSYNC命令给master请求复制数据。
2、master收到后会在后台bgsave生成最新rdb快照文件,缓存中继续接受新数据。Slave收到文件则加载到内存,再接受缓存中的master数据。(此处rdb和配置的rdb持久化没关系)
如果master收到并发连接,只会持久化一次,把这一份数据发给所有slave。
增量复制:
如果slave挂了几分钟,这时候不需要同步全量数据,只需要复制新增的master数据。
第一步:slave发送psync(offset)
第二步:master在repl backlog buffer中有offset则只同步新增数据,否则全量复制。
如果从节点太多怎么办呢,也就是主从复制风暴怎么解决?
当出现这种情况是从节点太多导致主节点同步压力过大,可以采取从节点给节点复制的方案来解决。
三、Redis LUA脚本
- 减少网络开销。(多个命令一起发送,所以开销少)
- 原子性。
- 事务特性。
127.0.0.1:6379> eval "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1 key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
这段lua脚本意思是返回两个key和value,其中key1前面的2代表key的个数
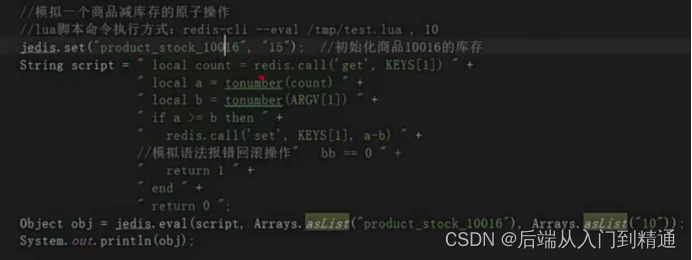
那我们用lua脚本模拟如何实现事务的回滚以及原子性呢?
如图所示,我们先set product_stock_10016为15
Script里有一个KEYS[1]和ARGV[1],这两个值分别对应着下面代码eval的两个参数,所以a的值获取为15,b的值获取为10.
第四行很好理解,如果a>=b则走再次复制 a-b
也就是15-10
因为return 1,最后obj=1,而product_stock_10016 为5。
如果我们把语法错误 bb==0注释解开。
则会回滚。
Lua脚本不会执行,则product_stock_10016为15
因为redis是单线程,前面也说了不能有大key,获取key不能用keys命令。
这里则不能再lua脚本出现死循环和耗时运算,因为他是单线程,如果因为lua脚本耗时太长甚至死循环,则整个redis会阻塞。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结