您现在的位置是:首页 >技术交流 >Postgresql源码(105)分区表剪枝代码分析网站首页技术交流
Postgresql源码(105)分区表剪枝代码分析
对于分区表,子表剪枝是保证性能最重要的手段,优化器在生成Plan的过程中对子表进行了剪枝,本篇对剪枝流程做简要总结。
1 构造数据
CREATE TABLE measurement (
city_id int not null,
logdate date not null,
peaktemp int,
unitsales int
) PARTITION BY RANGE (logdate);
CREATE TABLE measurement_y2006m01 PARTITION OF measurement FOR VALUES FROM ('2006-01-01') TO ('2006-02-01');
CREATE TABLE measurement_y2006m02 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01');
CREATE TABLE measurement_y2006m03 PARTITION OF measurement FOR VALUES FROM ('2006-03-01') TO ('2006-04-01');
CREATE TABLE measurement_y2006m04 PARTITION OF measurement FOR VALUES FROM ('2006-04-01') TO ('2006-05-01');
CREATE TABLE measurement_y2006m05 PARTITION OF measurement FOR VALUES FROM ('2006-05-01') TO ('2006-06-01');
insert into measurement values (1, '2006-01-03', floor(random() * 100), floor(random() * 100));
insert into measurement values (2, '2006-02-04', floor(random() * 100), floor(random() * 100));
insert into measurement values (3, '2006-03-05', floor(random() * 100), floor(random() * 100));
insert into measurement values (4, '2006-03-06', floor(random() * 100), floor(random() * 100));
insert into measurement values (5, '2006-03-07', floor(random() * 100), floor(random() * 100));
insert into measurement values (6, '2006-03-08', floor(random() * 100), floor(random() * 100));
insert into measurement values (7, '2006-04-09', floor(random() * 100), floor(random() * 100));
insert into measurement values (8, '2006-04-10', floor(random() * 100), floor(random() * 100));
insert into measurement values (9, '2006-05-11', floor(random() * 100), floor(random() * 100));
insert into measurement values (10, '2006-05-12', floor(random() * 100), floor(random() * 100));
2 验证SQL
SQL1
这是一条经过裁剪的SQL,只扫描4月分区:
explain select * from measurement where logdate between '2006-04-05' and '2006-04-20';
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on measurement_y2006m04 measurement (cost=0.00..37.75 rows=9 width=16)
Filter: ((logdate >= '2006-04-05'::date) AND (logdate <= '2006-04-20'::date))
SQL2
这是一条无法裁剪的SQL,扫描所有月份的分区。
explain select * from measurement where peaktemp between 1 and 10;
QUERY PLAN
------------------------------------------------------------------------------------------
Append (cost=0.00..188.97 rows=45 width=16)
-> Seq Scan on measurement_y2006m01 measurement_1 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m02 measurement_2 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m03 measurement_3 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m04 measurement_4 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m05 measurement_5 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
3 SQL1分析(可剪枝SQL)
select * from measurement where logdate between '2006-04-05' and '2006-04-20';
3.1 语义分析阶段结果:pg_analyze_and_rewrite_fixedparams
p elog_node_display(LOG, "querytree_list", querytree_list, true)
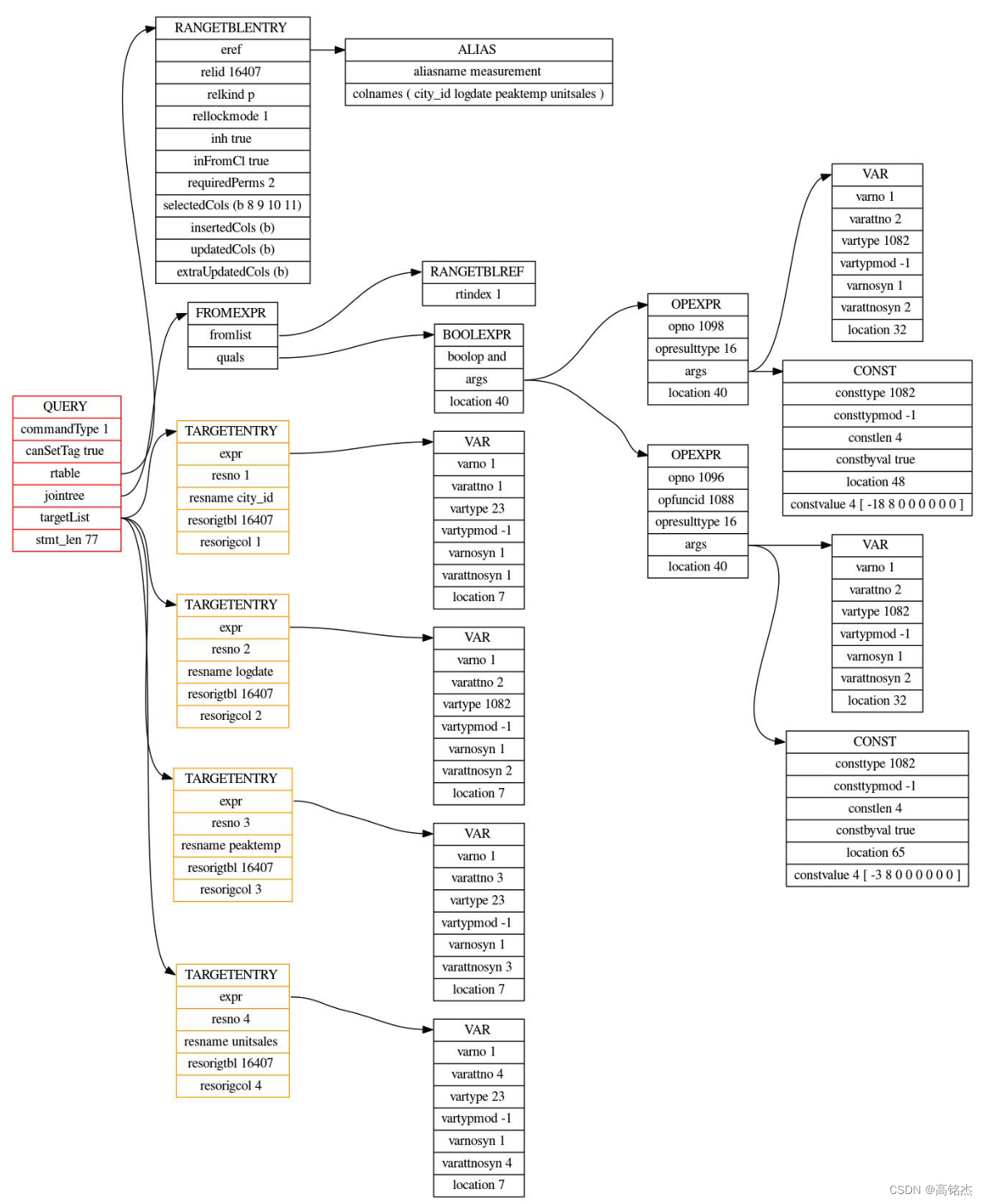
在语义分析阶段未剪枝。
3.2 计划生成阶段结果:pg_plan_queries
p elog_node_display(LOG, "plantree_list", plantree_list, true)
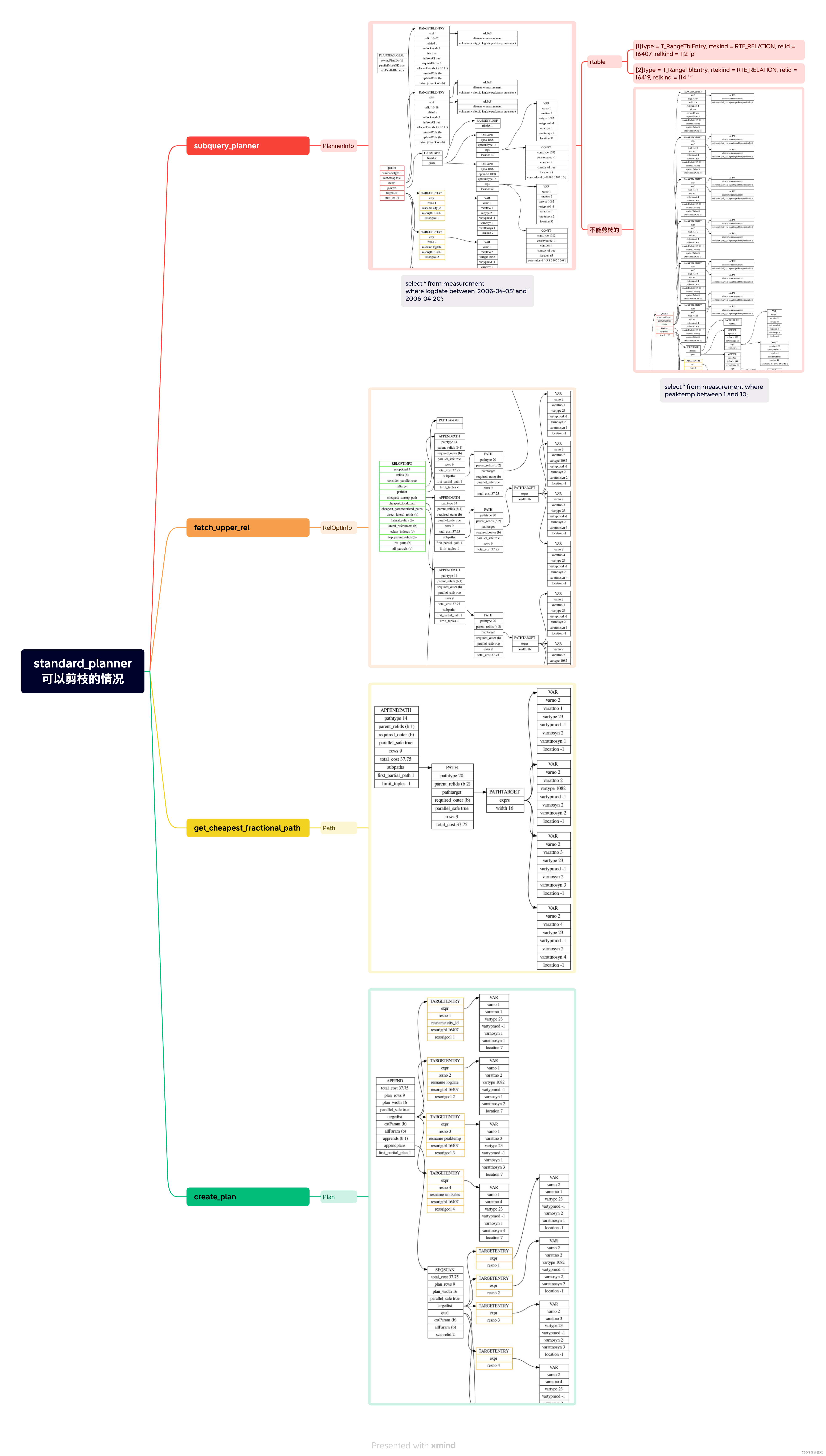
pg_plan_queries
pg_plan_query
planner
standard_planner
subquery_planner // 【1】第一步
fetch_upper_rel // 【2】第二步
get_cheapest_fractional_path // 【3】第三步
create_plan // 【4】第四步
第一步到第四步的输出结果(除了最右面的图用来对比,其他都是当前可剪枝SQL的):
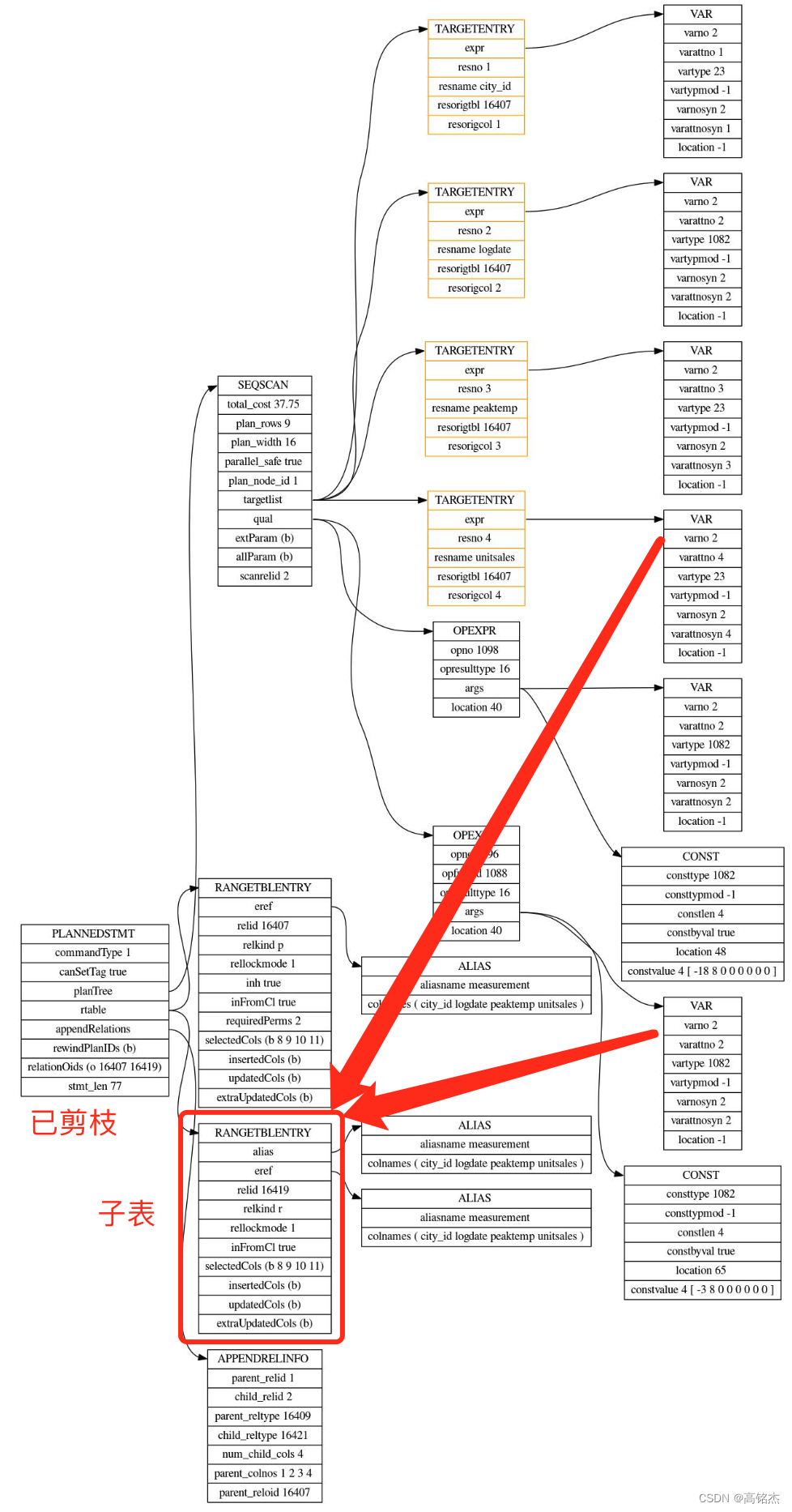
3.2.1 剪枝发生在subquery_planner
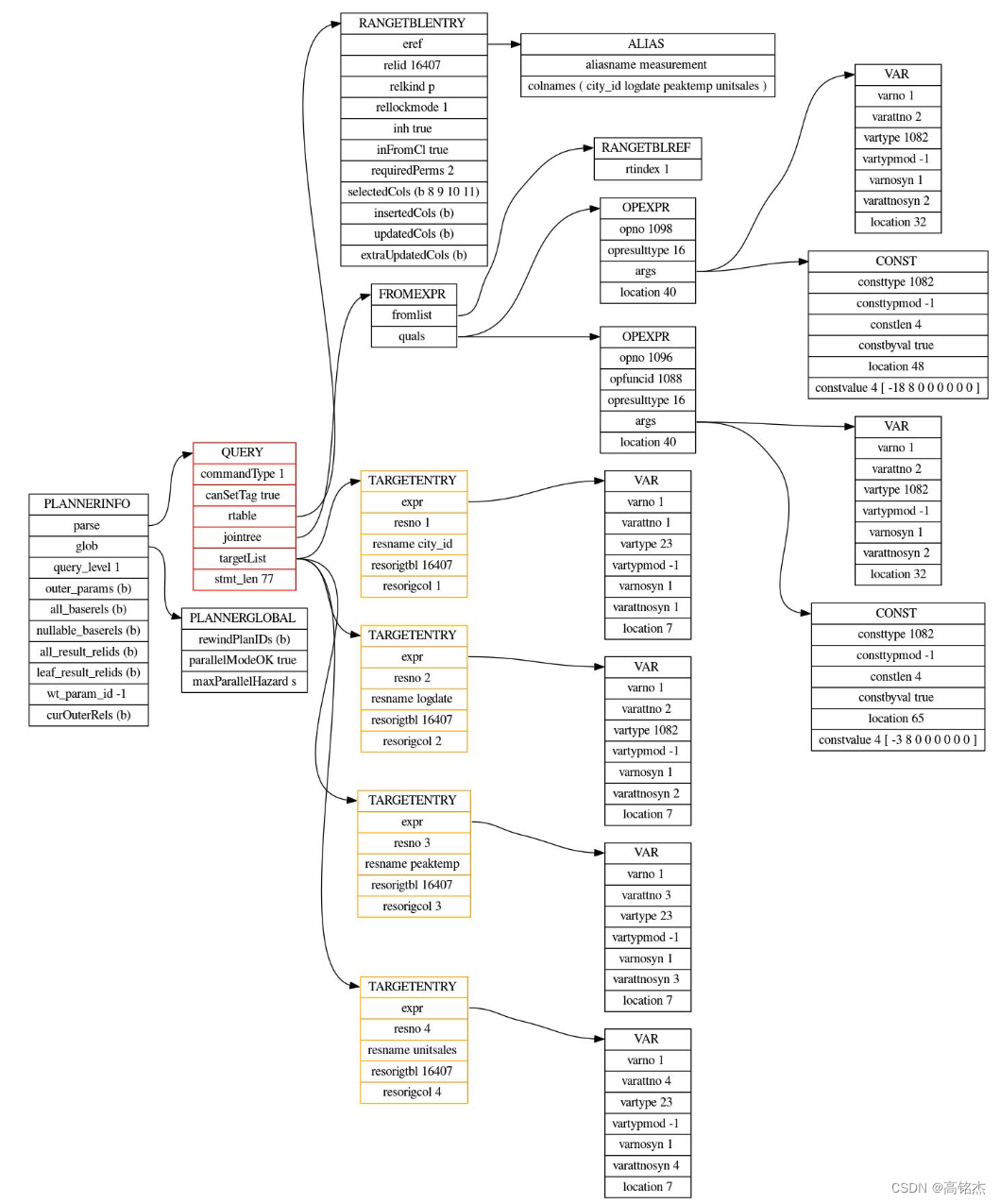
【1】subquery_planner函数中:PlannerInfo初始状态

【2】subquery_planner函数中:进入grouping_planner前都没有剪枝
subquery_planner
foreach(l, parse->rtable)
switch (rte->rtekind)
case RTE_RELATION:
if (rte->inh)
rte->inh = has_subclass(rte->relid); // 确认当前父表存在子表!去pg_class查relhassubclass字段
...
...
grouping_planner // 进入前
【3】prune_append_rel_partitions函数开始剪枝!
query_planner
...
...
add_other_rels_to_query
/* If it's marked as inheritable, look for children. */
if (rte->inh)
expand_inherited_rtentry
expand_partitioned_rtentry
PartitionDirectoryLookup
relinfo->live_parts = live_parts = prune_append_rel_partitions(relinfo);
剪枝函数:prune_append_rel_partitions
剪枝后只有一个分区:relinfo->live_parts = {nwords = 1, words = 0x173e4c0}
剪枝依据:relinfo:
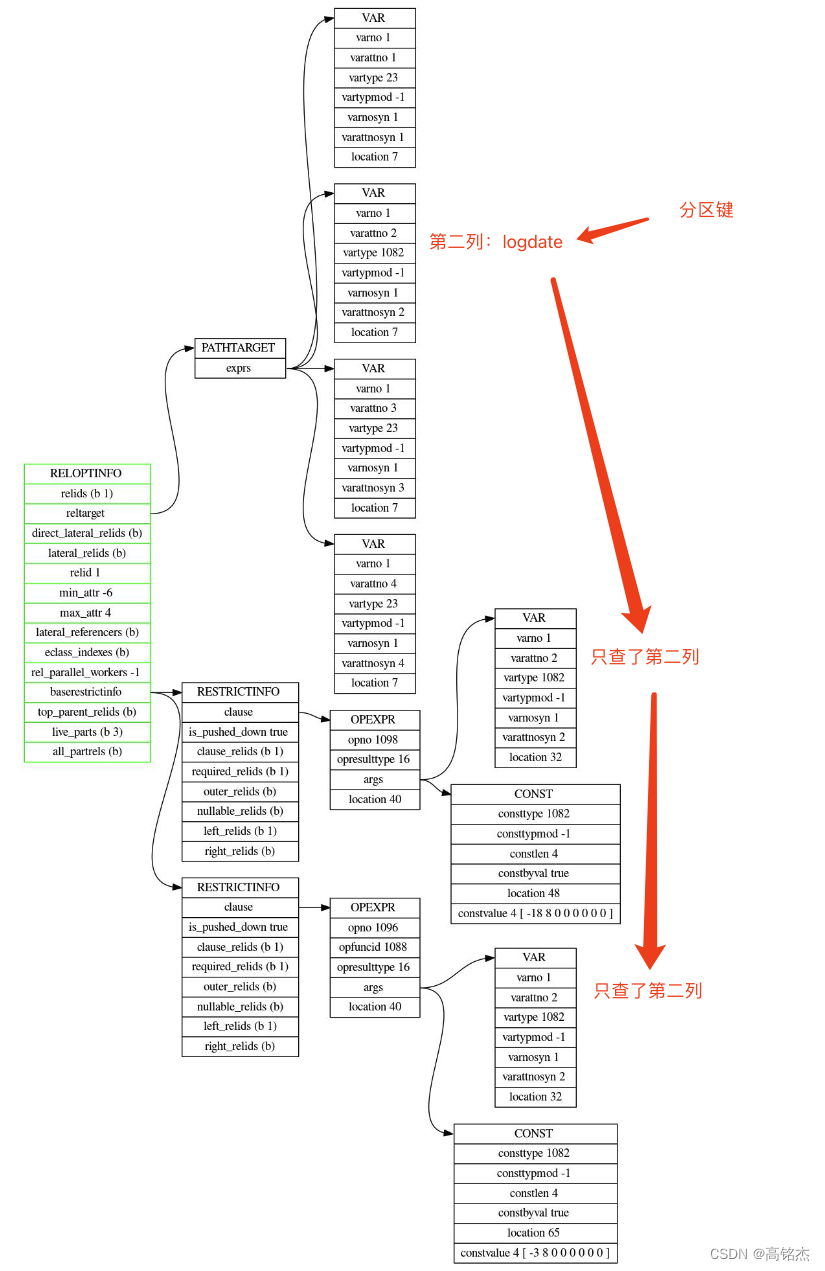
- prune_append_rel_partitions构造裁剪步骤steps调用get_matching_partitions
- get_matching_partitions收到steps:三步(between产生两个比较,和一个固定的combine)
prune_append_rel_partitions
get_matching_partitions(&context, pruning_steps); // 收到pruning_steps
pruning_steps:
{step = {type = T_PartitionPruneStepOp, step_id = 0}, opstrategy = 2, exprs = 0x172cfe0, cmpfns = 0x172cf88, nullkeys = 0x0}
exprs = Const
cmpfns = 1092 date_cmp
{step = {type = T_PartitionPruneStepOp, step_id = 1}, opstrategy = 4, exprs = 0x172d1f0, cmpfns = 0x172d198, nullkeys = 0x0}
exprs = Const
cmpfns = 1092 date_cmp
{step = {type = T_PartitionPruneStepCombine, step_id = 2}, combineOp = PARTPRUNE_COMBINE_INTERSECT, source_stepids = 0x172d350}
source_stepids = {0, 1}
get_matching_partitions 处理上面steps,产生结果:results[]
PruneStepResult = {bound_offsets = 0x172d558, scan_default = false, scan_null = false}
bound_offsets = Bitmapset{0001 1111}
PruneStepResult = {bound_offsets = 0x172d5a8, scan_default = false, scan_null = false}
bound_offsets = Bitmapset{0111 0000}
PruneStepResult = {bound_offsets = 0x172d5f8, scan_default = false, scan_null = false}
bound_offsets = Bitmapset{0001 0000} // 只存了4
expand_partitioned_rtentry函数中,使用4找到4-1=3号子表:
expand_partitioned_rtentry
while ((i = bms_next_member(live_parts, i)) >= 0)
Oid childOID = partdesc->oids[i]; // i = 3 找到3号子表
剪枝流程完成,后续细节不再展开。
3.3 执行阶段
按照裁剪计划数执行,只扫描4月表measurement_y2006m04
explain select * from measurement where logdate between '2006-04-05' and '2006-04-20';
QUERY PLAN
----------------------------------------------------------------------------------
Seq Scan on measurement_y2006m04 measurement (cost=0.00..37.75 rows=9 width=16)
Filter: ((logdate >= '2006-04-05'::date) AND (logdate <= '2006-04-20'::date))
4 SQL2分析(无法裁剪)
select * from measurement where peaktemp between 1 and 10;
4.1 计划生成阶段
p elog_node_display(LOG, "plantree_list", plantree_list, true)
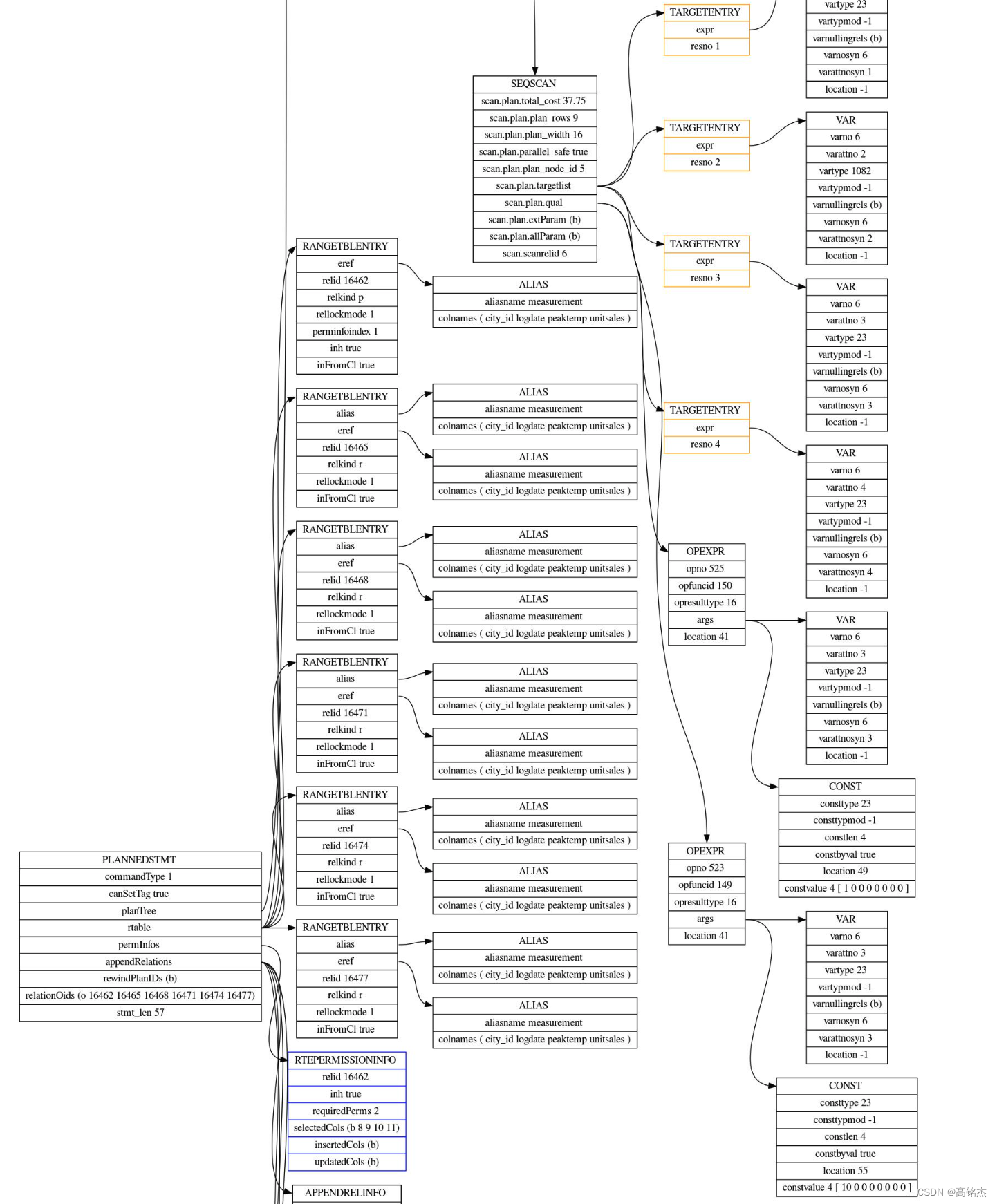
4.2 执行阶段
按照计划数执行会自动把所有子表扫一遍。
explain select * from measurement where peaktemp between 1 and 10;
QUERY PLAN
------------------------------------------------------------------------------------------
Append (cost=0.00..188.97 rows=45 width=16)
-> Seq Scan on measurement_y2006m01 measurement_1 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m02 measurement_2 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m03 measurement_3 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m04 measurement_4 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))
-> Seq Scan on measurement_y2006m05 measurement_5 (cost=0.00..37.75 rows=9 width=16)
Filter: ((peaktemp >= 1) AND (peaktemp <= 10))






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结