您现在的位置是:首页 >其他 >【CVPR2023】Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation网站首页其他
【CVPR2023】Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation
Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation, CVPR2023
论文:https://arxiv.org/abs/2303.01276
代码:https://github.com/xiaoyao3302/CCVC/
摘要
半监督语义分割(SSS)可以减少对大规模全注释训练数据的需求。现有方法处理伪标记时常常会受到确认偏差的影响,这可以通过联合训练框架来缓解。目前基于联合训练的SSS方法依赖于手工制作的每个扰动来防止不同的子网坍塌,但人为扰动难以得到最优解。本文提出一种新的基于冲突的跨视图一致性(CCVC)方法,该方法基于两个分支的联合训练框架,旨在强制两个子网从不相关的视图中学习信息特征。首先提出一种新的跨视图一致性(CVC)策略,该策略通过引入特征差异损失来鼓励两个子网从同一输入中学习不同的特征,同时这些不连续的特征有望生成输入的一致预测分数。CVC策略有助于防止两个子网陷入崩溃。此外,进一步提出一种基于冲突的伪标记(CPL)方法,以保证模型将从冲突预测中学习更多有用的信息,以保证训练过程的稳定。
引言
全监督语义分割需要花费大量精力来收集精准的标注数据。半监督学习可以使用小量标注数据和大量未标记数据实现语义分割。但如何利用未标记数据来辅助标记数据进行模型训练是一个关键问题。
使用伪标签的方式,可能会受到确认偏置的影响,会由于训练不稳定导致性能下降。基于一致性正则化的方式显示出较好的性能,但大多数依赖于弱扰动输入的预测生成伪标签,再将伪标签作为强扰动输入预测的监督。也会受到确认偏置的影响。
协同训练,能使不同的子网能够从不同的视图推断出相同的实例,并通过伪标记将从一个视图学到的知识转移到另一个视图。特别是,协同训练依赖于多视图参考来增加对模型的感知,从而提高生成的伪标签的可靠性。关键是如何防止不同的子网相互崩溃,以便模型能够根据不同视图的输入做出正确的预测。然而,大多数SSS方法中使用的手工扰动并不能保证学习异质特征,从而有效地防止子网陷入崩溃。
面对上述问题,本文为SSS提出了一种新的基于冲突的跨视图一致性(CCVC)策略,该策略确保模型中的两个子网可以分别学习不同的特征,从而可以从两个互不相关的视图中学习可靠的预测以进行联合训练,从而进一步使每个子网能够做出可靠和有意义的预测。
- 首先提出了一种具有差异损失的交叉视图一致性(CVC)方法,以最小化两个子网提取的特征之间的相似性,从而鼓励它们提取不同的特征,从而防止两个子网相互崩塌。
- 然后,使用交叉伪标记将从一个子网学到的知识转移到另一个子网,以提高对网络的感知,从而正确地推理来自不同视图的相同输入,从而产生更可靠的预测。
- 然而,差异损失可能会给模型引入太强的扰动,使得子网提取的特征可能包含用于预测的不太有意义的信息,从而导致来自两个子网的不一致和不可靠的预测。这将导致确认偏差问题,从而损害子网的联合训练。为了解决这个问题,进一步提出了一种基于冲突的伪标签(CPL)方法,鼓励每个子网的冲突预测生成的伪标签对彼此的预测进行更强的监督,以强制两个子网进行一致的预测,以保留预测以及预测的可靠性。通过这种方式,有望减少确认偏差的影响,使训练过程更加稳定。
如图1所示,从交叉一致性正则化(CCR)模型的两个子网中提取的特征之间的相似性得分保持在较高水平,这表明CCR的推理观点有点相关。相反,CVC方法确保了重新分析的观点有足够的不同,从而产生更可靠的预测。

相关工作
语义分割
半监督语义分割
协同训练
方法
CCVC(conflict-based cross-view consistency)
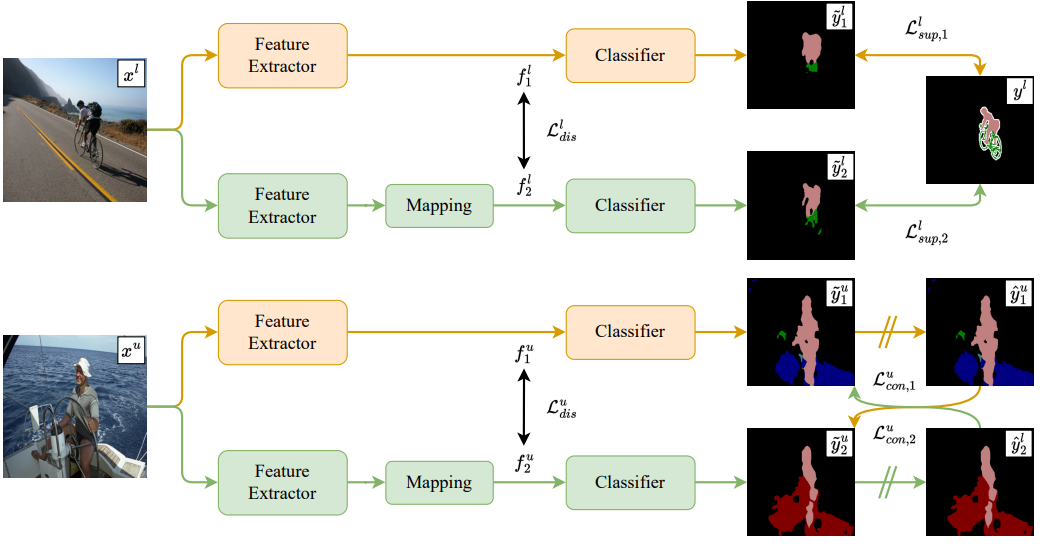

Cross-view consistency
跨视图一致性(CVC)方法。使用基于联合训练的两分支网络,其中两个子网(Ψ1和Ψ2),具有相似的架构,但参数不共享。将每个子网划分为特征提取器和分类器。目标是使两个子网能够推理来自不同视图的输入,因此提取的特征应该不同。因此,最小化两个特征提取器所提取的特征之间的余弦相似性。
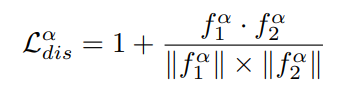
注意,系数1是为了确保损失的值总是非负的。鼓励两个子网输出没有共同关系的特征,从而强制两个子网学习从两个不相关的视图推理输入。
多数SSS方法采用在ImageNet上预训练的ResNet作为DeepLabv3+的主干,并且仅以较小的学习率对主干进行微调,这使得本文的特征差异最大化操作难以实现。为了解决这个问题,本文通过使用卷积层将提取的特征映射到另一个特征空间,来实现网络的异构性。差异损失重写为:

有标记和无标记数据都是用差异损失监督。差异的总损失为:
![]()
有标记数据使用真实标签作为监督,对两个子网都进行监督。有标记数据的监督损失为:
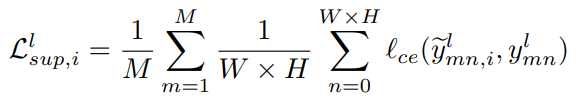
![]()
未标记数据采用伪标记方法使每个子网能够从另一个子网学习语义信息。应用交叉熵损失来微调模型。两个子网互为伪标签进行监督。未标记数据的损失为(交叉一致性损失):

![]()
整个网络的总损失:将监督损失,一致性损失,差异损失三者加权求和。
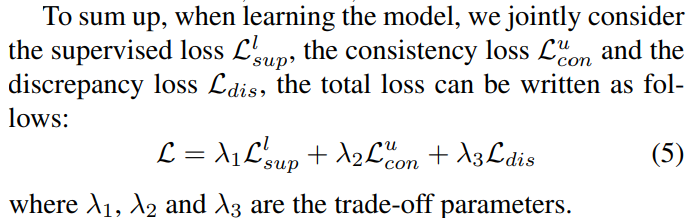
Conflict-based pseudo-labelling
使用跨视图一致性(CVC)方法,两个子网将从不同的视图中学习语义信息。但如果特征差异损失在模型上引入太强的扰动会使得训练不够稳定。因此,很难保证这两个子网能够相互学习有用的语义信息,这可能会进一步影响预测的可靠性。
于是,论文提出了一种基于冲突的伪标记(CPL)方法,使两个子网能够从冲突的预测中学习更多的语义信息,从而做出一致的预测,从而保证两个子网可以生成相同的可靠预测,并进一步稳定训练。使用二进制值δ来定义预测是否冲突.
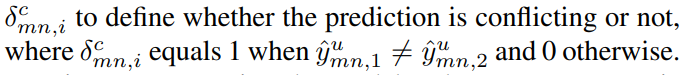
目的是鼓励模型从这些相互冲突的预测中学习更多的语义信息。因此,当使用这些预测来生成用于微调模型的伪标签时,将更高的权重ωc分配给由这些伪标签监督的交叉熵损失。
然而,在训练过程中,训练也可能受到确认偏差的影响,因为一些伪标签可能是错误的。论文将冲突预测进一步分为两类,即冲突和可信任(CC)预测, 冲突但不可信(CU)预测,并且只将ωc分配给由CC预测生成的伪标签。
使用二元值定义CC预测。使用
表示CU预测和无冲突预测的并集

仍然使用CU预测生成的伪标签来用正常权重微调模型,而不是直接丢弃它们,原因是这些CU预测也可以包含关于类间关系的潜在信息。一致性损失重写为:
![]()
其中,


CCVC方法可以有效地鼓励两个子网从不同的角度推理相同的输入,并且两个子网之间的知识转移可以增加了对每个子网的感知,从而提高了预测的可靠性。
推理阶段,只需要网络的一个分支就可以产生预测。
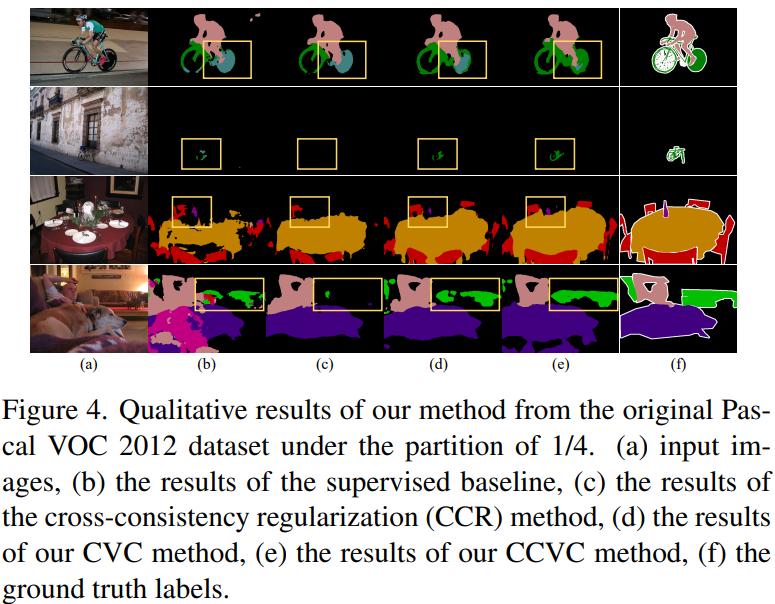
实验
![]()
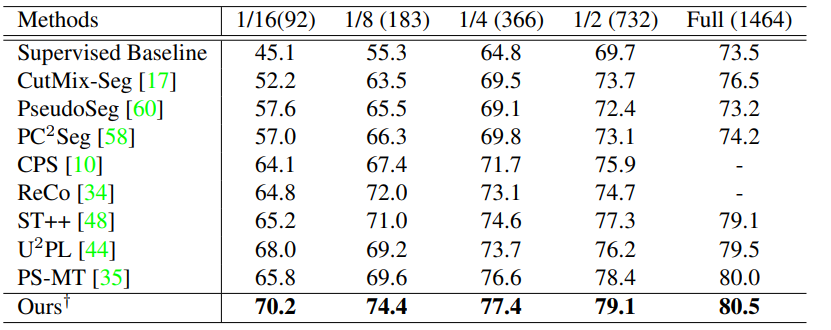
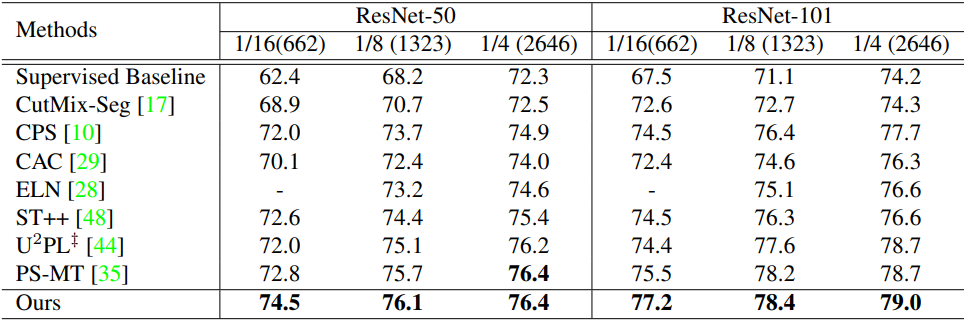
![]()
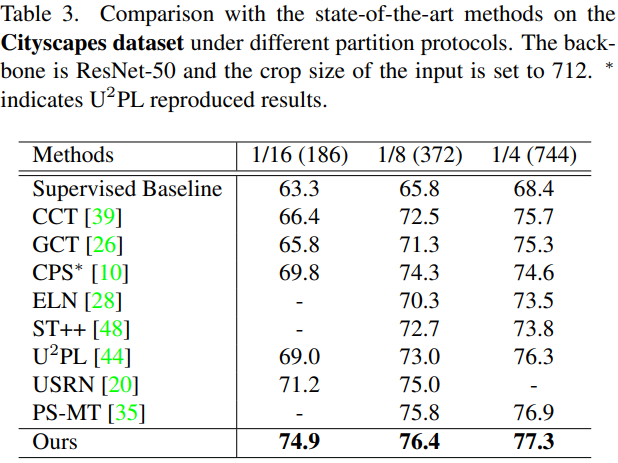


关键代码
CCVC_no_aug.py
# https://github.com/xiaoyao3302/CCVC/blob/master/CCVC_no_aug.py
args = parser.parse_args()
args.world_size = args.gpus * args.nodes
args.ddp = True if args.gpus > 1 else False
def main(gpu, ngpus_per_node, cfg, args):
args.local_rank = gpu
if args.local_rank <= 0:
os.makedirs(args.save_path, exist_ok=True)
logger = init_log_save(args.save_path, 'global', logging.INFO)
logger.propagate = 0
if args.local_rank <= 0:
tb_dir = args.save_path
tb = SummaryWriter(log_dir=tb_dir)
if args.ddp:
dist.init_process_group(backend='nccl', rank=args.local_rank, world_size=args.world_size)
# dist.init_process_group(backend='nccl', init_method='env://', rank=args.local_rank, world_size=args.world_size)
if args.local_rank <= 0:
logger.info('{}
'.format(pprint.pformat(cfg)))
random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.benchmark = True
model = Discrepancy_DeepLabV3Plus(args, cfg)
if args.local_rank <= 0:
logger.info('Total params: {:.1f}M
'.format(count_params(model)))
# pdb.set_trace()
# TODO: check the parameter !!!
optimizer = SGD([{'params': model.branch1.backbone.parameters(), 'lr': args.base_lr * args.lr_backbone},
{'params': model.branch2.backbone.parameters(), 'lr': args.base_lr * args.lr_backbone},
{'params': [param for name, param in model.named_parameters() if 'backbone' not in name],
'lr': args.base_lr * args.lr_network}], lr=args.base_lr, momentum=0.9, weight_decay=1e-4)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
model.cuda(args.local_rank)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, broadcast_buffers=False, find_unused_parameters=False)
# # try to load saved model
# try:
# model.load_model(args.load_path)
# if args.local_rank <= 0:
# logger.info('load saved model')
# except:
# if args.local_rank <= 0:
# logger.info('no saved model')
# ---- #
# loss #
# ---- #
# CE loss for labeled data
criterion_l = nn.CrossEntropyLoss(reduction='mean', ignore_index=255).cuda(args.local_rank)
# consistency loss for unlabeled data
criterion_u = nn.CrossEntropyLoss(reduction='none').cuda(args.local_rank)
# ------- #
# dataset #
# ------- #
trainset_u = SemiDataset(cfg['dataset'], cfg['data_root'], 'train_u',
args.crop_size, args.unlabeled_id_path)
trainset_l = SemiDataset(cfg['dataset'], cfg['data_root'], 'train_l',
args.crop_size, args.labeled_id_path, nsample=len(trainset_u.ids))
valset = SemiDataset(cfg['dataset'], cfg['data_root'], 'val')
if args.ddp:
trainsampler_l = torch.utils.data.distributed.DistributedSampler(trainset_l)
else:
trainsampler_l = None
trainloader_l = DataLoader(trainset_l, batch_size=args.batch_size,
pin_memory=True, num_workers=args.num_workers, drop_last=True, sampler=trainsampler_l)
if args.ddp:
trainsampler_u = torch.utils.data.distributed.DistributedSampler(trainset_u)
else:
trainsampler_u = None
trainloader_u = DataLoader(trainset_u, batch_size=args.batch_size,
pin_memory=True, num_workers=args.num_workers, drop_last=True, sampler=trainsampler_u)
valloader = DataLoader(valset, batch_size=1, pin_memory=True, num_workers=args.num_workers, drop_last=False)
# if args.ddp:
# valsampler = torch.utils.data.distributed.DistributedSampler(valset)
# else:
# valsampler = None
# valloader = DataLoader(valset, batch_size=1, pin_memory=True, num_workers=args.num_workers, drop_last=False, sampler=valsampler)
total_iters = len(trainloader_u) * args.epochs
previous_best = 0.0
previous_best1 = 0.0
previous_best2 = 0.0
# can change with epochs, add SPL here
conf_threshold = args.conf_threshold
for epoch in range(args.epochs):
if args.local_rank <= 0:
logger.info('===========> Epoch: {:}, backbone1 LR: {:.4f}, backbone2 LR: {:.4f}, segmentation LR: {:.4f}'.format(
epoch, optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'], optimizer.param_groups[-1]['lr']))
logger.info('===========> Epoch: {:}, Previous best of ave: {:.2f}, Previous best of branch1: {:.2f}, Previous best of branch2: {:.2f}'.format(
epoch, previous_best, previous_best1, previous_best2))
total_loss, total_loss_CE, total_loss_con, total_loss_dis = 0.0, 0.0, 0.0, 0.0
total_mask_ratio = 0.0
trainloader_l.sampler.set_epoch(epoch)
trainloader_u.sampler.set_epoch(epoch)
loader = zip(trainloader_l, trainloader_u)
total_labeled = 0
total_unlabeled = 0
for i, ((labeled_img, labeled_img_mask), (unlabeled_img, ignore_img_mask, cutmix_box)) in enumerate(loader):
labeled_img, labeled_img_mask = labeled_img.cuda(args.local_rank), labeled_img_mask.cuda(args.local_rank)
unlabeled_img, ignore_img_mask, cutmix_box = unlabeled_img.cuda(args.local_rank), ignore_img_mask.cuda(args.local_rank), cutmix_box.cuda(args.local_rank)
model.train()
optimizer.zero_grad()
dist.barrier()
num_lb, num_ulb = labeled_img.shape[0], unlabeled_img.shape[0]
total_labeled += num_lb
total_unlabeled += num_ulb
# =========================================================================================
# labeled data: labeled_img, labeled_img_mask
# =========================================================================================
labeled_logits = model(labeled_img)
# =========================================================================================
# unlabeled data: unlabeled_img, ignore_img_mask, cutmix_box
# =========================================================================================
unlabeled_logits = model(unlabeled_img)
# to count the confident predictions
unlabeled_pred_confidence1 = unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[0]
unlabeled_pred_confidence2 = unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[0]
# =========================================================================================
# calculate loss
# =========================================================================================
# -------------
# labeled
# -------------
# CE loss
labeled_pred1 = labeled_logits['pred1']
labeled_pred2 = labeled_logits['pred2']
loss_CE1 = criterion_l(labeled_pred1, labeled_img_mask)
loss_CE2 = criterion_l(labeled_pred2, labeled_img_mask)
loss_CE = (loss_CE1 + loss_CE2) / 2
loss_CE = loss_CE * args.w_CE
# -------------
# unlabeled
# -------------
# consistency loss
unlabeled_pred1 = unlabeled_logits['pred1']
unlabeled_pred2 = unlabeled_logits['pred2']
if args.mode_confident == 'normal':
loss_con1 = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * ((unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[0] > conf_threshold) & (ignore_img_mask != 255))
loss_con1 = torch.sum(loss_con1) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * ((unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[0] > conf_threshold) & (ignore_img_mask != 255))
loss_con2 = torch.sum(loss_con2) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'soft':
confident_pred1, confident_pred2, unconfident_pred1, unconfident_pred2 = soft_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_con1_confident = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (confident_pred1 & (ignore_img_mask != 255))
loss_con2_confident = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (confident_pred2 & (ignore_img_mask != 255))
loss_con1_unconfident = args.w_unconfident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (unconfident_pred1 & (ignore_img_mask != 255))
loss_con2_unconfident = args.w_unconfident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (unconfident_pred2 & (ignore_img_mask != 255))
loss_con1 = (torch.sum(loss_con1_confident) + torch.sum(loss_con1_unconfident)) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = (torch.sum(loss_con2_confident) + torch.sum(loss_con2_unconfident)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote':
same_pred, different_pred = vote_label_selection(unlabeled_pred1, unlabeled_pred2)
loss_con1_same = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (same_pred & (ignore_img_mask != 255))
loss_con2_same = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (same_pred & (ignore_img_mask != 255))
loss_con1_different = args.w_confident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_pred & (ignore_img_mask != 255))
loss_con2_different = args.w_confident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_pred & (ignore_img_mask != 255))
loss_con1 = (torch.sum(loss_con1_same) + torch.sum(loss_con1_different)) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = (torch.sum(loss_con2_same) + torch.sum(loss_con2_different)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote_threshold':
different1_confident, different1_else, different2_confident, different2_else = vote_threshold_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_con1_else = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different1_else & (ignore_img_mask != 255))
loss_con2_else = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different2_else & (ignore_img_mask != 255))
loss_con1_cc = args.w_confident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different1_confident & (ignore_img_mask != 255))
loss_con2_cc = args.w_confident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different2_confident & (ignore_img_mask != 255))
loss_con1 = (torch.sum(loss_con1_else) + torch.sum(loss_con1_cc)) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = (torch.sum(loss_con2_else) + torch.sum(loss_con2_cc)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote_soft':
same_pred, different_confident_pred1, different_confident_pred2, different_unconfident_pred1, different_unconfident_pred2 = vote_soft_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_con1_same = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (same_pred & (ignore_img_mask != 255))
loss_con2_same = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (same_pred & (ignore_img_mask != 255))
loss_con1_different_confident = args.w_confident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_confident_pred1 & (ignore_img_mask != 255))
loss_con2_different_confident = args.w_confident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_confident_pred2 & (ignore_img_mask != 255))
loss_con1_different_unconfident = args.w_unconfident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_unconfident_pred1 & (ignore_img_mask != 255))
loss_con2_different_unconfident = args.w_unconfident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different_unconfident_pred2 & (ignore_img_mask != 255))
loss_con1 = (torch.sum(loss_con1_same) + torch.sum(loss_con1_different_confident) + torch.sum(loss_con1_different_unconfident)) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = (torch.sum(loss_con2_same) + torch.sum(loss_con2_different_confident) + torch.sum(loss_con2_different_unconfident)) / torch.sum(ignore_img_mask != 255).item()
else:
loss_con1 = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (ignore_img_mask != 255)
loss_con1 = torch.sum(loss_con1) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (ignore_img_mask != 255)
loss_con2 = torch.sum(loss_con2) / torch.sum(ignore_img_mask != 255).item()
loss_con = (loss_con1 + loss_con2) / 2
loss_con = loss_con * args.w_con
# -------------
# both
# -------------
# discrepancy loss
cos_dis = nn.CosineSimilarity(dim=1, eps=1e-6)
# labeled
labeled_feature1 = labeled_logits['feature1']
labeled_feature2 = labeled_logits['feature2']
loss_dis_labeled1 = 1 + cos_dis(labeled_feature1.detach(), labeled_feature2).mean()
loss_dis_labeled2 = 1 + cos_dis(labeled_feature2.detach(), labeled_feature1).mean()
loss_dis_labeled = (loss_dis_labeled1 + loss_dis_labeled2) / 2
# unlabeled
unlabeled_feature1 = unlabeled_logits['feature1']
unlabeled_feature2 = unlabeled_logits['feature2']
loss_dis_unlabeled1 = 1 + cos_dis(unlabeled_feature1.detach(), unlabeled_feature2).mean()
loss_dis_unlabeled2 = 1 + cos_dis(unlabeled_feature2.detach(), unlabeled_feature1).mean()
loss_dis_unlabeled = (loss_dis_unlabeled1 + loss_dis_unlabeled2) / 2
loss_dis = (loss_dis_labeled + loss_dis_unlabeled) / 2
loss_dis = loss_dis * args.w_dis
# -------------
# total
# -------------
loss = loss_CE
if args.use_con:
loss = loss + loss_con
if args.use_dis:
loss = loss + loss_dis
dist.barrier()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_loss_CE += loss_CE.item()
total_loss_con += loss_con.item()
total_loss_dis += loss_dis.item()
total_confident = (((unlabeled_pred_confidence1 >= 0.95) & (ignore_img_mask != 255)).sum().item() + ((unlabeled_pred_confidence2 >= 0.95) & (ignore_img_mask != 255)).sum().item()) / 2
total_mask_ratio += total_confident / (ignore_img_mask != 255).sum().item()
iters = epoch * len(trainloader_u) + i
# update lr
backbone_lr = args.base_lr * (1 - iters / total_iters) ** args.mul_scheduler
backbone_lr = backbone_lr * args.lr_backbone
seg_lr = args.base_lr * (1 - iters / total_iters) ** args.mul_scheduler
seg_lr = seg_lr * args.lr_network
optimizer.param_groups[0]["lr"] = backbone_lr
optimizer.param_groups[1]["lr"] = backbone_lr
for ii in range(2, len(optimizer.param_groups)):
optimizer.param_groups[ii]['lr'] = seg_lr
if (i % (len(trainloader_u) // 8) == 0) and (args.local_rank <= 0):
tb.add_scalar('train_loss_total', total_loss / (i+1), iters)
tb.add_scalar('train_loss_CE', total_loss_CE / (i+1), iters)
tb.add_scalar('train_loss_con', total_loss_con / (i+1), iters)
tb.add_scalar('train_loss_dis', total_loss_dis / (i+1), iters)
if (i % (len(trainloader_u) // 8) == 0) and (args.local_rank <= 0):
logger.info('Iters: {:}, Total loss: {:.3f}, Loss CE: {:.3f}, '
'Loss consistency: {:.3f}, Loss discrepancy: {:.3f}, Mask: {:.3f}'.format(
i, total_loss / (i+1), total_loss_CE / (i+1), total_loss_con / (i+1), total_loss_dis / (i+1),
total_mask_ratio / (i+1)))
if args.use_SPL:
conf_threshold += 0.01
if conf_threshold >= 0.95:
conf_threshold = 0.95
if cfg['dataset'] == 'cityscapes':
eval_mode = 'center_crop' if epoch < args.epochs - 20 else 'sliding_window'
else:
eval_mode = 'original'
dist.barrier()
# test with different branches
if args.local_rank <= 0:
if epoch == 4:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=5)
elif epoch == 9:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=10)
elif epoch == 19:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=20)
elif epoch == 39:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=40)
else:
evaluate_result = evaluate(args.local_rank, model, valloader, eval_mode, args, cfg)
mIOU1 = evaluate_result['IOU1']
mIOU2 = evaluate_result['IOU2']
mIOU_ave = evaluate_result['IOU_ave']
tb.add_scalar('meanIOU_branch1', mIOU1, epoch)
tb.add_scalar('meanIOU_branch2', mIOU2, epoch)
tb.add_scalar('meanIOU_ave', mIOU_ave, epoch)
logger.info('***** Evaluation with branch 1 {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU1))
logger.info('***** Evaluation with branch 2 {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU2))
logger.info('***** Evaluation with two branches {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU_ave))
if mIOU1 > previous_best1:
if previous_best1 != 0:
os.remove(os.path.join(args.save_path, 'branch1_%s_%.2f.pth' % (args.backbone, previous_best1)))
previous_best1 = mIOU1
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'branch1_%s_%.2f.pth' % (args.backbone, mIOU1)))
if mIOU2 > previous_best2:
if previous_best2 != 0:
os.remove(os.path.join(args.save_path, 'branch2_%s_%.2f.pth' % (args.backbone, previous_best2)))
previous_best2 = mIOU2
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'branch2_%s_%.2f.pth' % (args.backbone, mIOU2)))
if mIOU_ave > previous_best:
if previous_best != 0:
os.remove(os.path.join(args.save_path, 'ave_%s_%.2f.pth' % (args.backbone, previous_best)))
previous_best = mIOU_ave
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'ave_%s_%.2f.pth' % (args.backbone, mIOU_ave)))
CCVC_aug.py
# https://github.com/xiaoyao3302/CCVC/blob/master/CCVC_aug.py
args = parser.parse_args()
args.world_size = args.gpus * args.nodes
args.ddp = True if args.gpus > 1 else False
def main(gpu, ngpus_per_node, cfg, args):
args.local_rank = gpu
if args.local_rank <= 0:
os.makedirs(args.save_path, exist_ok=True)
logger = init_log_save(args.save_path, 'global', logging.INFO)
logger.propagate = 0
if args.local_rank <= 0:
tb_dir = args.save_path
tb = SummaryWriter(log_dir=tb_dir)
if args.ddp:
dist.init_process_group(backend='nccl', rank=args.local_rank, world_size=args.world_size)
# dist.init_process_group(backend='nccl', init_method='env://', rank=args.local_rank, world_size=args.world_size)
if args.local_rank <= 0:
logger.info('{}
'.format(pprint.pformat(cfg)))
random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
torch.backends.cudnn.benchmark = True
model = Discrepancy_DeepLabV3Plus(args, cfg)
if args.local_rank <= 0:
logger.info('Total params: {:.1f}M
'.format(count_params(model)))
# pdb.set_trace()
# TODO: check the parameter !!!
optimizer = SGD([{'params': model.branch1.backbone.parameters(), 'lr': args.base_lr * args.lr_backbone},
{'params': model.branch2.backbone.parameters(), 'lr': args.base_lr * args.lr_backbone},
{'params': [param for name, param in model.named_parameters() if 'backbone' not in name],
'lr': args.base_lr * args.lr_network}], lr=args.base_lr, momentum=0.9, weight_decay=1e-4)
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
model.cuda(args.local_rank)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, broadcast_buffers=False, find_unused_parameters=False)
# # try to load saved model
# try:
# model.load_model(args.load_path)
# if args.local_rank <= 0:
# logger.info('load saved model')
# except:
# if args.local_rank <= 0:
# logger.info('no saved model')
# ---- #
# loss #
# ---- #
# CE loss for labeled data
if args.mode_criterion == 'CE':
criterion_l = nn.CrossEntropyLoss(reduction='mean', ignore_index=255).cuda(args.local_rank)
else:
criterion_l = ProbOhemCrossEntropy2d(**cfg['criterion']['kwargs']).cuda(args.local_rank)
# consistency loss for unlabeled data
criterion_u = nn.CrossEntropyLoss(reduction='none').cuda(args.local_rank)
# ------- #
# dataset #
# ------- #
trainset_u = SemiDataset(cfg['dataset'], cfg['data_root'], 'train_u',
args.crop_size, args.unlabeled_id_path)
trainset_l = SemiDataset(cfg['dataset'], cfg['data_root'], 'train_l',
args.crop_size, args.labeled_id_path, nsample=len(trainset_u.ids))
valset = SemiDataset(cfg['dataset'], cfg['data_root'], 'val')
if args.ddp:
trainsampler_l = torch.utils.data.distributed.DistributedSampler(trainset_l)
else:
trainsampler_l = None
trainloader_l = DataLoader(trainset_l, batch_size=args.batch_size,
pin_memory=True, num_workers=args.num_workers, drop_last=True, sampler=trainsampler_l)
if args.ddp:
trainsampler_u = torch.utils.data.distributed.DistributedSampler(trainset_u)
else:
trainsampler_u = None
trainloader_u = DataLoader(trainset_u, batch_size=args.batch_size,
pin_memory=True, num_workers=args.num_workers, drop_last=True, sampler=trainsampler_u)
valloader = DataLoader(valset, batch_size=1, pin_memory=True, num_workers=args.num_workers, drop_last=False)
# if args.ddp:
# valsampler = torch.utils.data.distributed.DistributedSampler(valset)
# else:
# valsampler = None
# valloader = DataLoader(valset, batch_size=1, pin_memory=True, num_workers=args.num_workers, drop_last=False, sampler=valsampler)
total_iters = len(trainloader_u) * args.epochs
previous_best = 0.0
previous_best1 = 0.0
previous_best2 = 0.0
# can change with epochs, add SPL here
conf_threshold = args.conf_threshold
for epoch in range(args.epochs):
if args.local_rank <= 0:
logger.info('===========> Epoch: {:}, backbone1 LR: {:.4f}, backbone2 LR: {:.4f}, segmentation LR: {:.4f}'.format(
epoch, optimizer.param_groups[0]['lr'], optimizer.param_groups[1]['lr'], optimizer.param_groups[-1]['lr']))
logger.info('===========> Epoch: {:}, Previous best of ave: {:.2f}, Previous best of branch1: {:.2f}, Previous best of branch2: {:.2f}'.format(
epoch, previous_best, previous_best1, previous_best2))
total_loss, total_loss_CE, total_loss_con, total_loss_dis = 0.0, 0.0, 0.0, 0.0
total_mask_ratio = 0.0
trainloader_l.sampler.set_epoch(epoch)
trainloader_u.sampler.set_epoch(epoch)
loader = zip(trainloader_l, trainloader_u)
total_labeled = 0
total_unlabeled = 0
for i, ((labeled_img, labeled_img_mask), (unlabeled_img, aug_unlabeled_img, ignore_img_mask, unlabeled_cutmix_box)) in enumerate(loader):
labeled_img, labeled_img_mask = labeled_img.cuda(args.local_rank), labeled_img_mask.cuda(args.local_rank)
unlabeled_img, aug_unlabeled_img, ignore_img_mask, unlabeled_cutmix_box = unlabeled_img.cuda(args.local_rank), aug_unlabeled_img.cuda(args.local_rank), ignore_img_mask.cuda(args.local_rank), unlabeled_cutmix_box.cuda(args.local_rank)
optimizer.zero_grad()
dist.barrier()
num_lb, num_ulb = labeled_img.shape[0], unlabeled_img.shape[0]
total_labeled += num_lb
total_unlabeled += num_ulb
# =========================================================================================
# labeled data: labeled_img, labeled_img_mask
# =========================================================================================
model.train()
labeled_logits = model(labeled_img)
# =========================================================================================
# unlabeled data: unlabeled_img, ignore_img_mask, cutmix_box
# =========================================================================================
# first feed the data into the model with no grad to get gt
with torch.no_grad():
model.eval()
unlabeled_logits = model(unlabeled_img)
unlabeled_pseudo_label1 = unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()
unlabeled_pseudo_label2 = unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()
unlabeled_pred1 = unlabeled_logits['pred1'].detach()
unlabeled_pred2 = unlabeled_logits['pred2'].detach()
# then perform cutmix
aug_unlabeled_img_for_mix = aug_unlabeled_img.clone()
aug_unlabeled_ignore_img_mask_for_mix = ignore_img_mask.clone()
aug_unlabeled_pseudo_label1_for_mix = unlabeled_pseudo_label1.clone()
aug_unlabeled_pseudo_label2_for_mix = unlabeled_pseudo_label2.clone()
aug_unlabeled_pred1_for_mix = unlabeled_pred1.clone()
aug_unlabeled_pred2_for_mix = unlabeled_pred2.clone()
# initial cutmix is companied with a probablility 0.5, increase the data divergence
aug_unlabeled_img_for_mix[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_img_for_mix.shape) == 1] = aug_unlabeled_img_for_mix.flip(0)[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_img_for_mix.shape) == 1]
aug_unlabeled_ignore_img_mask_for_mix[unlabeled_cutmix_box == 1] = aug_unlabeled_ignore_img_mask_for_mix.flip(0)[unlabeled_cutmix_box == 1]
aug_unlabeled_pseudo_label1_for_mix[unlabeled_cutmix_box == 1] = aug_unlabeled_pseudo_label1_for_mix.flip(0)[unlabeled_cutmix_box == 1]
aug_unlabeled_pseudo_label2_for_mix[unlabeled_cutmix_box == 1] = aug_unlabeled_pseudo_label2_for_mix.flip(0)[unlabeled_cutmix_box == 1]
aug_unlabeled_pred1_for_mix[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_pred1_for_mix.shape) == 1] = aug_unlabeled_pred1_for_mix.flip(0)[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_pred1_for_mix.shape) == 1]
aug_unlabeled_pred2_for_mix[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_pred2_for_mix.shape) == 1] = aug_unlabeled_pred2_for_mix.flip(0)[unlabeled_cutmix_box.unsqueeze(1).expand(aug_unlabeled_pred2_for_mix.shape) == 1]
# finally feed the mixed data into the model
model.train()
cutmixed_aug_unlabeled_logits = model(aug_unlabeled_img_for_mix)
# one extra branch: unlabeled data
raw_unlabeled_logits = model(unlabeled_img)
# to count the confident predictions
unlabeled_pred_confidence1 = raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[0]
unlabeled_pred_confidence2 = raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[0]
# =========================================================================================
# calculate loss
# =========================================================================================
# -------------
# labeled
# -------------
# CE loss
labeled_pred1 = labeled_logits['pred1']
labeled_pred2 = labeled_logits['pred2']
loss_CE1 = criterion_l(labeled_pred1, labeled_img_mask)
loss_CE2 = criterion_l(labeled_pred2, labeled_img_mask)
loss_CE = (loss_CE1 + loss_CE2) / 2
loss_CE = loss_CE * args.w_CE
# -------------
# unlabeled
# -------------
# consistency loss
raw_unlabeled_pred1 = raw_unlabeled_logits['pred1']
raw_unlabeled_pred2 = raw_unlabeled_logits['pred2']
cutmixed_aug_unlabeled_pred1 = cutmixed_aug_unlabeled_logits['pred1']
cutmixed_aug_unlabeled_pred2 = cutmixed_aug_unlabeled_logits['pred2']
if args.mode_confident == 'normal':
loss_con1 = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * ((aug_unlabeled_pred1_for_mix.softmax(dim=1).max(dim=1)[0] > conf_threshold) & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1 = torch.sum(loss_con1) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * ((aug_unlabeled_pred2_for_mix.softmax(dim=1).max(dim=1)[0] > conf_threshold) & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2 = torch.sum(loss_con2) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_raw_con1 = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * ((raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[0] > conf_threshold) & (ignore_img_mask != 255))
loss_raw_con1 = torch.sum(loss_raw_con1) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * ((raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[0] > conf_threshold) & (ignore_img_mask != 255))
loss_raw_con2 = torch.sum(loss_raw_con2) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'soft':
confident_pred1, confident_pred2, unconfident_pred1, unconfident_pred2 = soft_label_selection(aug_unlabeled_pred1_for_mix, aug_unlabeled_pred2_for_mix, conf_threshold)
loss_con1_confident = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (confident_pred1 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_confident = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (confident_pred2 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1_unconfident = 0.5 * criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (unconfident_pred1 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_unconfident = 0.5 * criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (unconfident_pred2 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1 = (torch.sum(loss_con1_confident) + torch.sum(loss_con1_unconfident)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = (torch.sum(loss_con2_confident) + torch.sum(loss_con2_unconfident)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
raw_confident_pred1, raw_confident_pred2, raw_unconfident_pred1, raw_unconfident_pred2 = soft_label_selection(raw_unlabeled_pred1, raw_unlabeled_pred2, conf_threshold)
loss_raw_con1_confident = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_confident_pred1 & (ignore_img_mask != 255))
loss_raw_con2_confident = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_confident_pred2 & (ignore_img_mask != 255))
loss_raw_con1_unconfident = 0.5 * criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_unconfident_pred1 & (ignore_img_mask != 255))
loss_raw_con2_unconfident = 0.5 * criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_unconfident_pred2 & (ignore_img_mask != 255))
loss_raw_con1 = (torch.sum(loss_raw_con1_confident) + torch.sum(loss_raw_con1_unconfident)) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = (torch.sum(loss_raw_con2_confident) + torch.sum(loss_raw_con2_unconfident)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote':
same_pred, different_pred = vote_label_selection(unlabeled_pred1, unlabeled_pred2)
loss_con1_same = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (same_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_same = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (same_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1_different = 1.5 * criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (different_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_different = 1.5 * criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (different_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1 = (torch.sum(loss_con1_same) + torch.sum(loss_con1_different)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = (torch.sum(loss_con2_same) + torch.sum(loss_con2_different)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
raw_same_pred, raw_different_pred = vote_label_selection(raw_unlabeled_pred1, raw_unlabeled_pred2)
loss_raw_con1_same = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_same_pred & (ignore_img_mask != 255))
loss_raw_con2_same = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_same_pred & (ignore_img_mask != 255))
loss_raw_con1_different = 1.5 * criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_pred & (ignore_img_mask != 255))
loss_raw_con2_different = 1.5 * criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_pred & (ignore_img_mask != 255))
loss_raw_con1 = (torch.sum(loss_raw_con1_same) + torch.sum(loss_raw_con1_different)) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = (torch.sum(loss_raw_con2_same) + torch.sum(loss_raw_con2_different)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote_threshold':
different1_confident, different1_else, different2_confident, different2_else = vote_threshold_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_con1_else = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (different1_else & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_else = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (different2_else & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1_cc = args.w_confident * criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (different1_confident & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_cc = args.w_confident * criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (different2_confident & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1 = (torch.sum(loss_con1_else) + torch.sum(loss_con1_cc)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = (torch.sum(loss_con2_else) + torch.sum(loss_con2_cc)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
raw_different1_confident, raw_different1_else, raw_different2_confident, raw_different2_else = vote_threshold_label_selection(raw_unlabeled_pred1, raw_unlabeled_pred2, conf_threshold)
loss_raw_con1_else = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different1_else & (ignore_img_mask != 255))
loss_raw_con2_else = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different2_else & (ignore_img_mask != 255))
loss_raw_con1_cc = args.w_confident * criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different1_confident & (ignore_img_mask != 255))
loss_raw_con2_cc = args.w_confident * criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different2_confident & (ignore_img_mask != 255))
loss_raw_con1 = (torch.sum(loss_raw_con1_else) + torch.sum(loss_raw_con1_cc)) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = (torch.sum(loss_raw_con2_else) + torch.sum(loss_raw_con2_cc)) / torch.sum(ignore_img_mask != 255).item()
elif args.mode_confident == 'vote_soft':
same_pred, different_confident_pred1, different_confident_pred2, different_unconfident_pred1, different_unconfident_pred2 = vote_soft_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_con1_same = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (same_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_same = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (same_pred & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1_different_confident = 1.5 * criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (different_confident_pred1 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_different_confident = 1.5 * criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (different_confident_pred2 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1_different_unconfident = 0.5 * criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (different_unconfident_pred1 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con2_different_unconfident = 0.5 * criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (different_unconfident_pred2 & (aug_unlabeled_ignore_img_mask_for_mix != 255))
loss_con1 = (torch.sum(loss_con1_same) + torch.sum(loss_con1_different_confident) + torch.sum(loss_con1_different_unconfident)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = (torch.sum(loss_con2_same) + torch.sum(loss_con2_different_confident) + torch.sum(loss_con2_different_unconfident)) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
raw_same_pred, raw_different_confident_pred1, raw_different_confident_pred2, raw_different_unconfident_pred1, raw_different_unconfident_pred2 = vote_soft_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
loss_raw_con1_same = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_same_pred & (ignore_img_mask != 255))
loss_raw_con2_same = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_same_pred & (ignore_img_mask != 255))
loss_raw_con1_different_confident = 1.5 * criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_confident_pred1 & (ignore_img_mask != 255))
loss_raw_con2_different_confident = 1.5 * criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_confident_pred2 & (ignore_img_mask != 255))
loss_raw_con1_different_unconfident = 0.5 * criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_unconfident_pred1 & (ignore_img_mask != 255))
loss_raw_con2_different_unconfident = 0.5 * criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (raw_different_unconfident_pred2 & (ignore_img_mask != 255))
loss_raw_con1 = (torch.sum(loss_raw_con1_same) + torch.sum(loss_raw_con1_different_confident) + torch.sum(loss_raw_con1_different_unconfident)) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = (torch.sum(loss_raw_con2_same) + torch.sum(loss_raw_con2_different_confident) + torch.sum(loss_raw_con2_different_unconfident)) / torch.sum(ignore_img_mask != 255).item()
else:
loss_con1 = criterion_u(cutmixed_aug_unlabeled_pred2, aug_unlabeled_pseudo_label1_for_mix) * (aug_unlabeled_ignore_img_mask_for_mix != 255)
loss_con1 = torch.sum(loss_con1) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_con2 = criterion_u(cutmixed_aug_unlabeled_pred1, aug_unlabeled_pseudo_label2_for_mix) * (aug_unlabeled_ignore_img_mask_for_mix != 255)
loss_con2 = torch.sum(loss_con2) / torch.sum(aug_unlabeled_ignore_img_mask_for_mix != 255).item()
loss_raw_con1 = criterion_u(raw_unlabeled_pred2, raw_unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (ignore_img_mask != 255)
loss_raw_con1 = torch.sum(loss_raw_con1) / torch.sum(ignore_img_mask != 255).item()
loss_raw_con2 = criterion_u(raw_unlabeled_pred1, raw_unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (ignore_img_mask != 255)
loss_raw_con2 = torch.sum(loss_raw_con2) / torch.sum(ignore_img_mask != 255).item()
loss_con = (loss_con1 + loss_con2 + loss_raw_con1 + loss_raw_con2) / 4
loss_con = loss_con * args.w_con
# -------------
# both
# -------------
# discrepancy loss
cos_dis = nn.CosineSimilarity(dim=1, eps=1e-6)
# labeled
labeled_feature1 = labeled_logits['feature1']
labeled_feature2 = labeled_logits['feature2']
loss_dis_labeled1 = 1 + cos_dis(labeled_feature1.detach(), labeled_feature2).mean()
loss_dis_labeled2 = 1 + cos_dis(labeled_feature2.detach(), labeled_feature1).mean()
loss_dis_labeled = (loss_dis_labeled1 + loss_dis_labeled2) / 2
# unlabeled
cutmixed_aug_unlabeled_feature1 = cutmixed_aug_unlabeled_logits['feature1']
cutmixed_aug_unlabeled_feature2 = cutmixed_aug_unlabeled_logits['feature2']
loss_dis_cutmixed_aug_unlabeled1 = 1 + cos_dis(cutmixed_aug_unlabeled_feature1.detach(), cutmixed_aug_unlabeled_feature2).mean()
loss_dis_cutmixed_aug_unlabeled2 = 1 + cos_dis(cutmixed_aug_unlabeled_feature2.detach(), cutmixed_aug_unlabeled_feature1).mean()
loss_dis_cutmixed_aug_unlabeled = (loss_dis_cutmixed_aug_unlabeled1 + loss_dis_cutmixed_aug_unlabeled2) / 2
raw_unlabeled_feature1 = raw_unlabeled_logits['feature1']
raw_unlabeled_feature2 = raw_unlabeled_logits['feature2']
loss_dis_raw_unlabeled1 = 1 + cos_dis(raw_unlabeled_feature1.detach(), raw_unlabeled_feature2).mean()
loss_dis_raw_unlabeled2 = 1 + cos_dis(raw_unlabeled_feature2.detach(), raw_unlabeled_feature1).mean()
loss_dis_raw_unlabeled = (loss_dis_raw_unlabeled1 + loss_dis_raw_unlabeled2) / 2
loss_dis_unlabeled = (loss_dis_cutmixed_aug_unlabeled + loss_dis_raw_unlabeled) / 2
loss_dis = (loss_dis_labeled + loss_dis_unlabeled) / 2
loss_dis = loss_dis * args.w_dis
# -------------
# total
# -------------
loss = loss_CE + loss_con + loss_dis
dist.barrier()
loss.backward()
optimizer.step()
total_loss += loss.item()
total_loss_CE += loss_CE.item()
total_loss_con += loss_con.item()
total_loss_dis += loss_dis.item()
total_confident = (((unlabeled_pred_confidence1 >= 0.95) & (ignore_img_mask != 255)).sum().item() + ((unlabeled_pred_confidence2 >= 0.95) & (ignore_img_mask != 255)).sum().item()) / 2
total_mask_ratio += total_confident / (ignore_img_mask != 255).sum().item()
iters = epoch * len(trainloader_u) + i
# update lr
backbone_lr = args.base_lr * (1 - iters / total_iters) ** args.mul_scheduler
backbone_lr = backbone_lr * args.lr_backbone
seg_lr = args.base_lr * (1 - iters / total_iters) ** args.mul_scheduler
seg_lr = seg_lr * args.lr_network
optimizer.param_groups[0]['lr'] = backbone_lr
optimizer.param_groups[1]['lr'] = backbone_lr
for ii in range(2, len(optimizer.param_groups)):
optimizer.param_groups[ii]['lr'] = seg_lr
if (i % (len(trainloader_u) // 8) == 0) and (args.local_rank <= 0):
tb.add_scalar('train_loss_total', total_loss / (i+1), iters)
tb.add_scalar('train_loss_CE', total_loss_CE / (i+1), iters)
tb.add_scalar('train_loss_con', total_loss_con / (i+1), iters)
tb.add_scalar('train_loss_dis', total_loss_dis / (i+1), iters)
if (i % (len(trainloader_u) // 8) == 0) and (args.local_rank <= 0):
logger.info('Iters: {:}, Total loss: {:.3f}, Loss CE: {:.3f}, '
'Loss consistency: {:.3f}, Loss discrepancy: {:.3f}, Mask: {:.3f}'.format(
i, total_loss / (i+1), total_loss_CE / (i+1), total_loss_con / (i+1), total_loss_dis / (i+1),
total_mask_ratio / (i+1)))
if args.use_SPL:
conf_threshold += 0.01
if conf_threshold >= 0.95:
conf_threshold = 0.95
if cfg['dataset'] == 'cityscapes':
eval_mode = 'center_crop' if epoch < args.epochs - 20 else 'sliding_window'
else:
eval_mode = 'original'
dist.barrier()
# test with different branches
if args.local_rank <= 0:
if epoch == 4:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=5)
elif epoch == 9:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=10)
elif epoch == 19:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=20)
elif epoch == 39:
evaluate_result = evaluate_save(cfg['dataset'], args.save_path, args.local_rank, model, valloader, eval_mode, args, cfg, idx_epoch=40)
else:
evaluate_result = evaluate(args.local_rank, model, valloader, eval_mode, args, cfg)
mIOU1 = evaluate_result['IOU1']
mIOU2 = evaluate_result['IOU2']
mIOU_ave = evaluate_result['IOU_ave']
tb.add_scalar('meanIOU_branch1', mIOU1, epoch)
tb.add_scalar('meanIOU_branch2', mIOU2, epoch)
tb.add_scalar('meanIOU_ave', mIOU_ave, epoch)
logger.info('***** Evaluation with branch 1 {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU1))
logger.info('***** Evaluation with branch 2 {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU2))
logger.info('***** Evaluation with two branches {} ***** >>>> meanIOU: {:.2f}
'.format(eval_mode, mIOU_ave))
if mIOU1 > previous_best1:
if previous_best1 != 0:
os.remove(os.path.join(args.save_path, 'branch1_%s_%.2f.pth' % (args.backbone, previous_best1)))
previous_best1 = mIOU1
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'branch1_%s_%.2f.pth' % (args.backbone, mIOU1)))
if mIOU2 > previous_best2:
if previous_best2 != 0:
os.remove(os.path.join(args.save_path, 'branch2_%s_%.2f.pth' % (args.backbone, previous_best2)))
previous_best2 = mIOU2
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'branch2_%s_%.2f.pth' % (args.backbone, mIOU2)))
if mIOU_ave > previous_best:
if previous_best != 0:
os.remove(os.path.join(args.save_path, 'ave_%s_%.2f.pth' % (args.backbone, previous_best)))
previous_best = mIOU_ave
torch.save(model.module.state_dict(),
os.path.join(args.save_path, 'ave_%s_%.2f.pth' % (args.backbone, mIOU_ave)))






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结