您现在的位置是:首页 >技术交流 >深入浅出对话系统——自然语言理解模块网站首页技术交流
深入浅出对话系统——自然语言理解模块
自然语言理解
首先回顾一下自然语言理解的概念。
自然语言理解(Natural Language Understanding)包含三个子模块:

其中领域识别和意图识别都是分类问题,而语义槽填充属于序列标注问题。所以,在自然语言理解中,我们要解决两个分类任务和一个序列标注任务。既然其中两个问题都属于分类任务,那么我们可以用什么模型/方法来解决它们呢?
常见的文本分类模型有:
- Average Word Embedding
- Text CNN
- Text RNN
- Transformer
Average Word Embedding

其实就是把文本中的所有单词向量进行平均,这样就得到了文本的表示向量。然后依据该向量进行分类。
Text-CNN
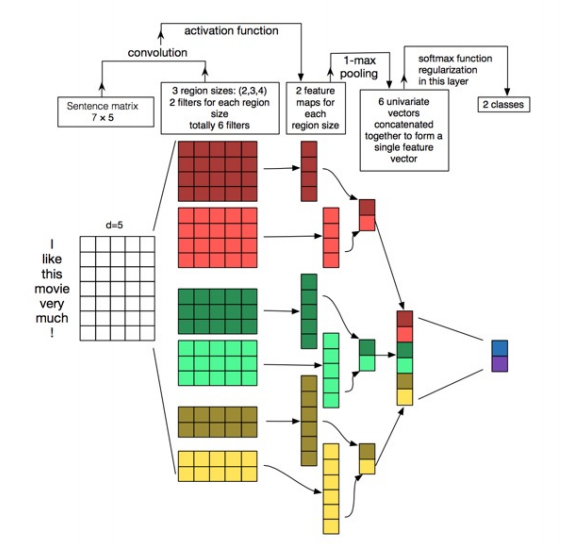
Text-CNN计算文本向量表示的方法是。
- 首先也是拿到文本中每个单词的词向量。以上图为例,假设这里的文本是一句话
I like this movie very much !,这里有7个单词,假设词嵌入维度为5,那么该句子的形状就是一个 7 × 5 7 imes 5 7×5的矩阵; - 然后沿着该矩阵行的方向做一维卷积,然后这里采用6个卷积核,对于每个卷积核都会得到一个表示向量,然后进行池化操作,比如最大池化。这样我们对于每个卷积核的结果都得到了一个标量;
- 接着将所有的这些标量拼接起来,就可以得到和卷积核数量一样长的卷积向量,我们可以将该向量看成是整句话的表示向量;
- 最后依据该向量进行分类;
其中每个卷积核可以有不同的大小,卷积核的长度类似n-gram中的n大小。
Text RNN
RNN就是按照顺序读取文本中的词向量,最后输出的隐藏状态就是整个文本的表示向量。
Transformer

这里是一个Transformer块,Transformer在前面的文章有过详细的介绍,比如点此。我们知道,它最后也能得到一个向量表示。
下面我们来看一下序列标注。
Sequence Labeling
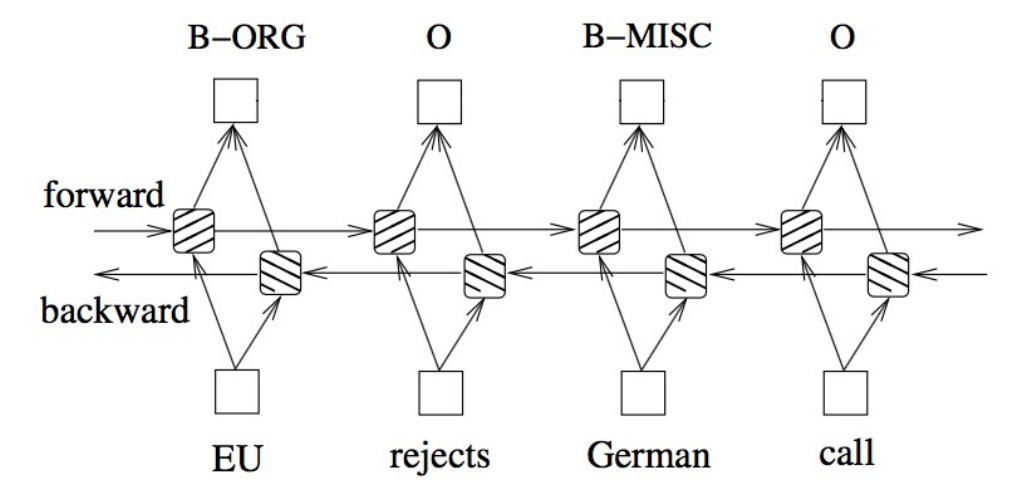
序列标注任务的本质是对序列中的每个单词进行分类,首先也需要得到每个单词的词向量,然后进行实体分类。
BIO Notation
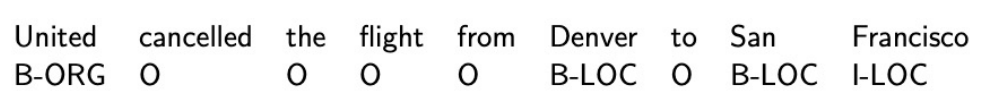
我们进行序列标注时,标注的实体(比如地名)可能不止包含一个单词,甚至它们可能出现在一起,那么该如何区分呢。
这时需要采用像BIO这种标注方式,比如为地名开始分配B-LOC这样的标注,为属于同一地名后的所有词分配I-LOC这样的标注。
意图和槽位的联合识别
为什么意图和槽位填充需要联合识别?
因为意图识别和槽值检测是紧密联系的。而传统独立的建模意图识别和槽值填充,既会引出错误级联,也无法利用共有的知识。
比如:

这句话意图是WatchMoive,那么这句话包含的Slot(槽值)应该是电影。而如果不知道意图,可能Watch后面变成了书的名字或其他的。
那么如何做呢?
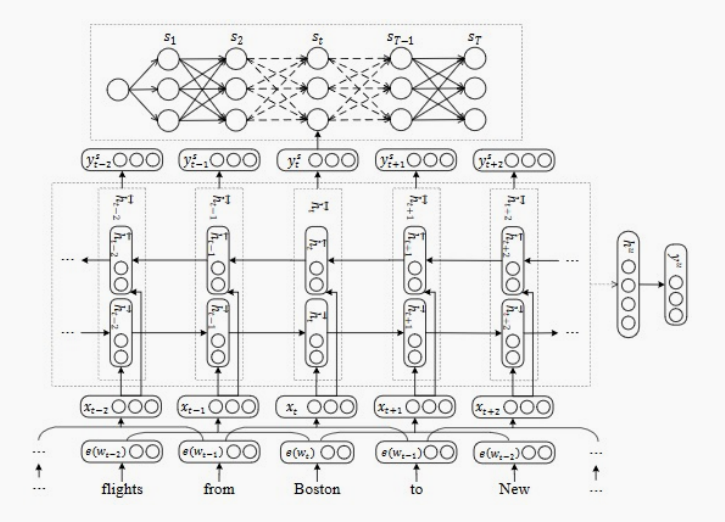
来自论文 A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding
比如这篇论文的做法是基于GRU的方法联合建模意图识别和槽值填充任务,具体的做法是,
① 把输入中的每个词表示成一个词向量;
② 输入到双向GRU中得到每个词的向量表示;
③ 基于每个词的向量表示通过某种方式(比如Max Pooling)得到这句话的一个整体表示;
④ 基于这个句子的向量表示加上分类头做意图识别;
⑤ 同时对每个词的向量表示加上分类头做槽值检测(序列标注,这里还加上了CRF);
⑥ 把所有的loss加起来同时训练;
这样隐式地学习两者的关系。
后面还出现了很多变种,我们再看比较有代表性的两个做法。第一个是:
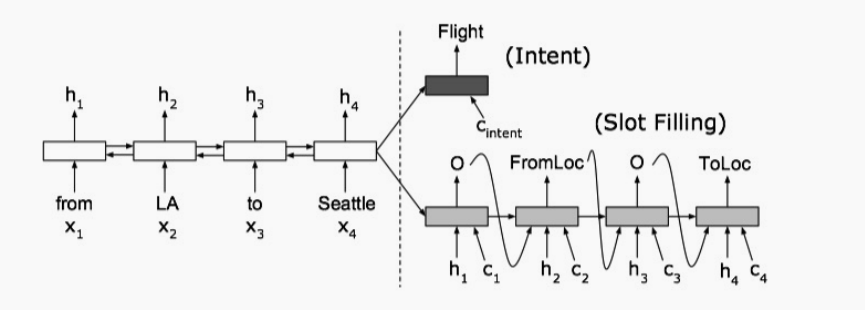
来自论文 Attention-Based Recurrent Neural Network Models for Joint Intent Detection
该论文把槽值检测任务变成了序列到序列任务(加上了Attention),我们知道槽值检测是一个序列标注任务,它需要给出输入的每个词对应的序列标签,本质上是接收一个序列,输出另一个序列。
因此这里的输入是一个token序列,输出是一个slot标签所对应的序列。我们知道seq2seq中有编码器和解码器,编码器会把输入序列编码成一个隐向量所组成的序列,然后把隐向量序列输入到解码器中,解码器会输出最后的标签序列。
那么这里通过共享的序列编码Encoder来联合隐式地学习意图识别和槽值检测,即首先通过编码器得到输入语句的整体表示,然后在整体的语句表示上做意图识别任务,然后把编码器得到的每个token的表示拿来做序列标注任务。也同时优化这两个loss来试图让模型学会它们之间的交互。
但是这些做法的缺陷也很明显,它们仅仅是共享了共同的句子或token的表征,并没有显示地进行交互。
下面这篇论文,也就是我们要介绍的第二个做法尝试解决这个问题。
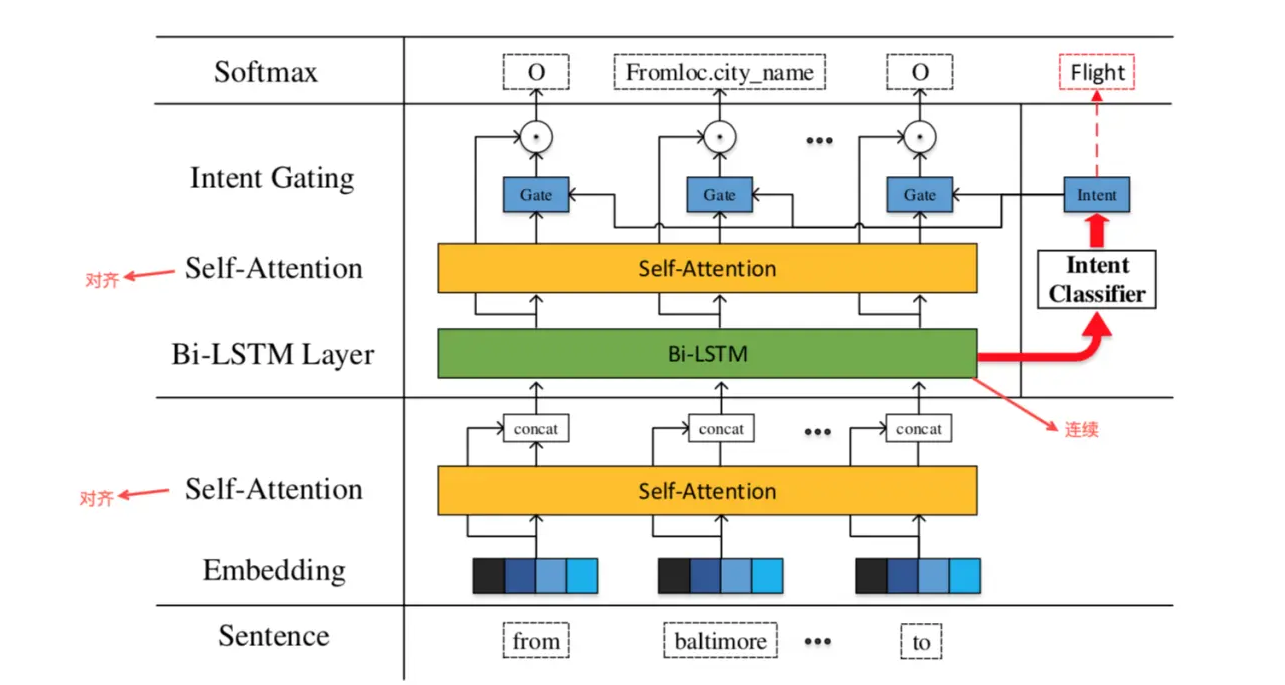
来自论文 Changliang Li, et al. A self-attentive model with gate mechanism for spoken language understanding
做法为:
- 利用LSTM提取这句话的向量表示;
- 基于句子的向量表示做意图识别;
- 得到意图分类后,把意图映射为意图的表示向量;
- 基于这个意图表示向量计算一个门控机制,加在计算槽位的每个词的隐变量上;
- 使用经过门控机制的隐变量去做槽值检测任务;
这里在经过LSTM之前使用了一个 Self-Attention,即用每个词自己做为query,用序列中的所有词做key和value,去计算注意权重。在LSTM之后也有一个Self-Attention。这两个Selft-Attention可以认为是促进了词与词之间的交互。
但在工业界并没有实现意图和槽值的联合检测,在做槽值检测时依然有很多的规则,比如基于词表的简单匹配。但联合识别是一个未来的方向。
考虑上下文的NLU
考虑上下文的自然语言理解即在多轮对话场景中,考虑历史对话信息。
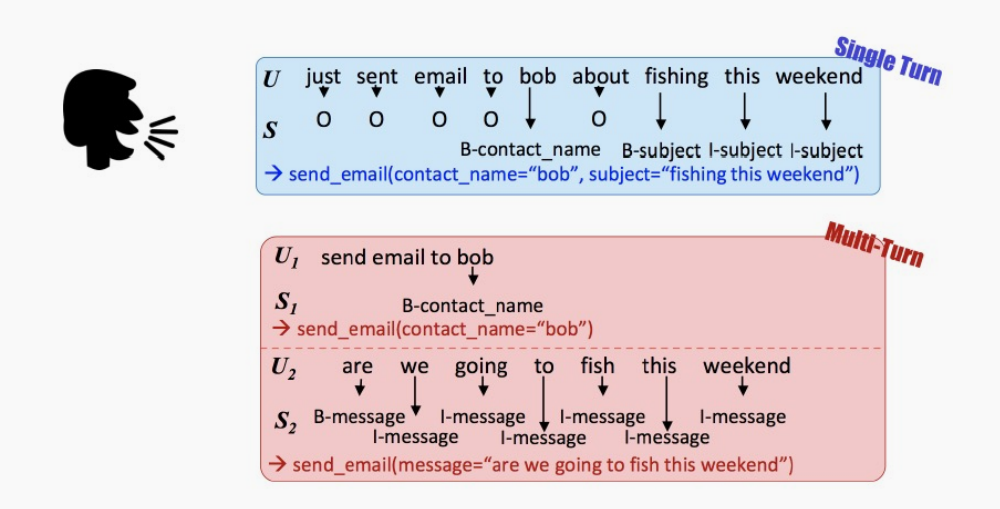
比如上面的多轮对话例子中,用户输入的第一句是“发送邮件给鲍勃”,第二句就是要发送的内容。
那么如何实现呢?
首先我们关注的核心要点有:
- 哪些历史对话轮次可以帮助当前轮次对话的理解
- 这些历史对话对当前对话传递了哪些有用的信息
举个订票系统的例子。

比如对于用户最后输入的“火车票价格呢?”,其中用户假设机器人已经知道了起点和终点信息。为了更好理解这句话的意图,我们需要把用户输入的第一句话“查一下上海到背景的机票价格”考虑进来,做为一个上下文信息。
下面介绍几种实现。
第一种是基于memory netowork(记忆网络)的方式,因为我们想要理解上下文信息需要记住上下文信息,所以使用记忆网络是一个不难想到的选择。
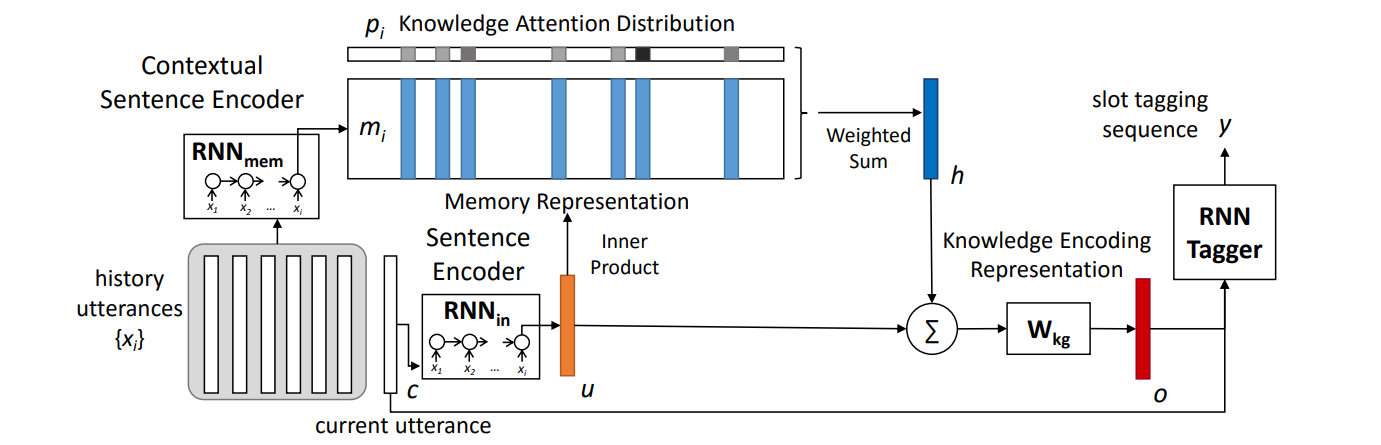
来自论文 End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding
现在随着预训练的发展,大家发现不需要显示地使用记忆模块,只要把前面所有的对话历史拼成一句话,喂给比如BERT来得到这句很长的话的向量表示就可以足够去做上下文相关的自然语言理解了。但这种方式随着对话轮数的变多会增加模型计算的负担,因为需要拼接的字符串会越来越长。
我们回到主题,来看下如何使用记忆网络来建模更好的上下文信息。所谓更好的上下文信息,即在对当前的一句话做意图检测时能得到更好的表示,也就是说考虑了上下文的表示。
如何提取出这个更好的表示,或表示的增强呢。它的做法是从上下文中提取出一个表示向量,和当前语句的表示向量进行融合,做为增加表示向量。如何从当前上下文中提取出这样的表示呢?
假设现在已经有了当前语句的表示,想理解当前语句中的意图和槽值。
首先我们已经有了对话历史中每句话的向量表示,把对话历史中每句话的句向量表示喂给RNN,得到RNN的输出,该输出就认为是一个记忆向量,它考虑了历史对话信息。
然后把当前句子输入给一个语句编码器,它会得到这句话的隐状态表示向量,接着把当前语句的(上图橘黄色)表示向量当成是一个query,把memory里面的(上图有6个)表示向量当成key和value,它们做一个Attention,得到对话历史所有(上图有6个)表示向量的加权平均。
接下来,融合当前语句表示向量和这个加权平均得到增强的表示(上图红色),融合的方式有很多种,这里用到的是简单的相加。
这个增强之后的句向量表示可以帮忙我们更好的去做意图识别和序列标注任务,比如做意图分类可以直接拿这个增强的句向量来做;而做序列标注时可以把这个增强的句向量表示拼到当前输入每个token得到的词向量上,然后再取做序列标注。
后续研究者们提供了更多的一些改进工作,试图用一些更加新颖、复杂的方式得到更好的上下文表示。基本的思想都是使用Attention的方式来得到上下文的表示。比如:
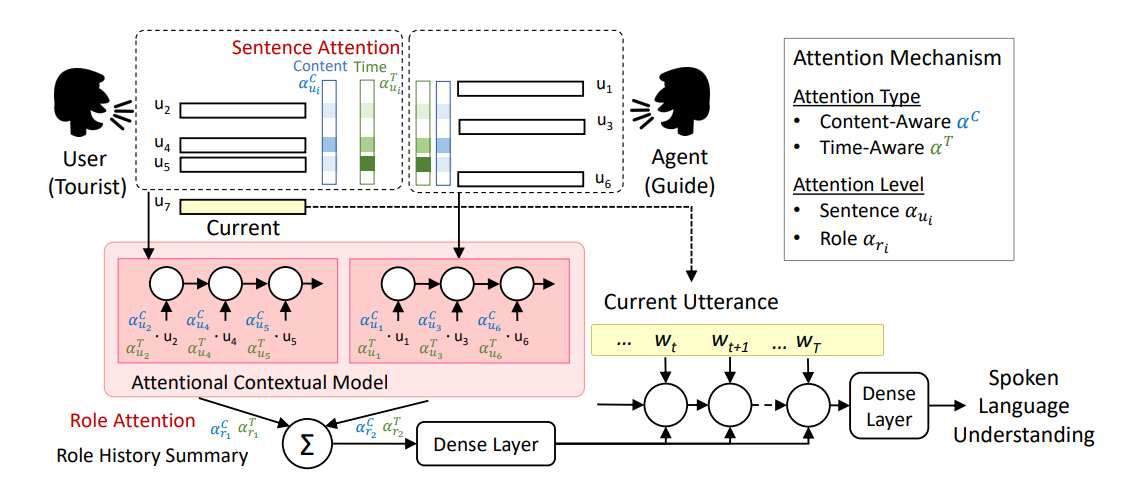
来自论文 Dynamic time-aware attention to speaker roles and contexts for spoken language understanding
这篇论文中使用了分角色的Attention,这里的角色有用户(User)和机器人(Agent)。在用户所说的句子上做Atttention和在机器人所说的句子上做Attention应该是不一样的,应该要区别对待,从而得到更好的表示向量。
它把对话历史中所有的句子分成了两部分,左边部分是用户所说的句子,右边部分是机器人所说的句子。然后维护两个Attention(记忆),第一个Attention关注用户所说的句子,第二个Attentioni关注机器人所说的句子,分别进行注意力计算,然后融合这两个注意力结果,得到当前上下文的增强表示。
这篇论文还提出了一点是考虑了时间信息,它认为对于当前句子来说,对当前句子理解比较重要的应该是时间上比较近的哪些句子,而比较久远的句子影响应该减弱。这里使用了一个特殊的加权平均方式,即离得近的句子权重更大,离得远的句子权重更小。这里通过 1 d ( u i ) frac{1}{d(u_i)} d(ui)1来实现, d ( u i ) d(u_i) d(ui)就是离当前句子 u i u_i ui的距离,显然这是与距离成反比的。
但在实现时论文作者设计了很多复杂的规则,这些规则是否具有普适性呢,也就是说是否能应用到我们自己的数据上来说是存疑的。
不过我们还是可以从中吸取一些思想,主要是尽量把人工的先验知识反映到模型中,从而得到更好的效果。
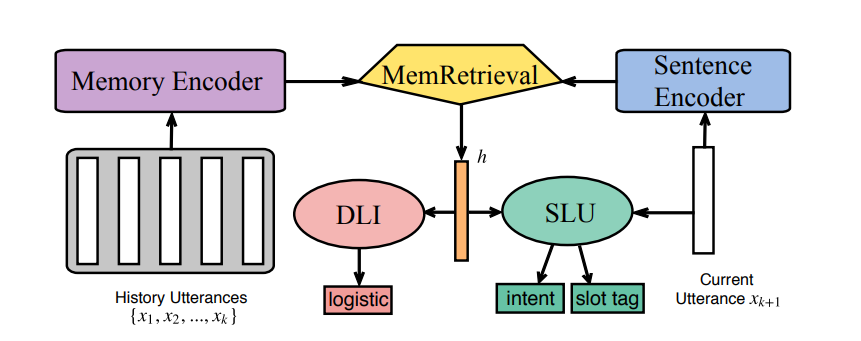
来自论文 Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference
为了更好地建模上下文信息,还有人提出了上面这样的模型。它基于历史对话语句通过一个记忆编码器得到一个编码,然后根据当前语句的语句编码器得到另一个编码,用后者对前者进行记忆检索(各种各样的Attention)得到当前对话历史的表示(橙色)。基于这个表示去做意图分类和序列标注。
但不止如此,作者加入了一个额外的任务,叫做对话逻辑推理(Dialogue Logistic Inference,DLI),具体做法是试图利用得到的橙色增强向量进行(先随机打乱然后)对话历史的还原,这里主要是还原对话历史中的语句顺序。
NLU中的少样本学习
深度学习需要大量的标注数据,但获取大量标注数据非常昂贵,此时出现了一个研究方向——少样本学习(Few-shot learning),目的是尽量使用少的样本来实现某个任务。
这里介绍一下少样本学习领域中的术语。
对于分类任务来说,有K-way N-shot分类任务。
- 支持集(Support Set):K类别,N实例
- 模型只要学习K个类别,每个类别有N个实例。称为K-way N-shot分类任务。
- 传统意义上的训练集这里称为支持集。
- 查询集(Query Set)
- 传统意义上的测试集这里称为查询集。
实现方法上可以分为两类:基于KNN的方法;基于优化的方法。
基于KNN的少样本学习方法本质上是学习一个相似度度量函数,它可以接收两个样本作为输入,然后计算它们之间的相似度作为二分类。
目的就是学习这样一个相似度度量函数,或者说是匹配函数、距离函数。如果把这个函数学得很好,就能解决少样本学习的任务。在这个方向上有三个主要的模型,分为孪生网络、匹配网络和原型网络。
孪生网络
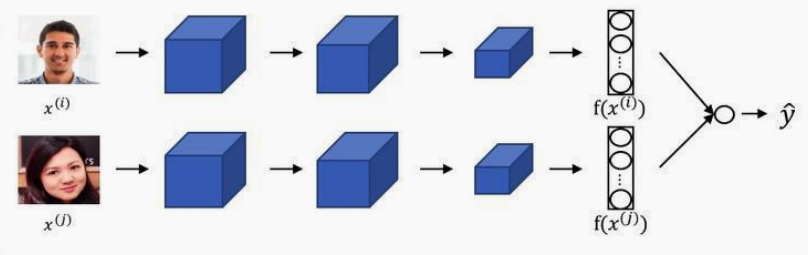
它的思想是通过有监督的方法学习两个样本的相似性,在新任务上用复用特征提取器实现少样本分类。
做法是基于这K个类别构建很多个正样本和负样本,即属于同一个类别之间的实例为正样本,属于不同类别间的实例为负样本。然后基于这些正负样本学习一个距离网络,度量两个样本之间的距离。
孪生网络的架构是用同一个网络为不同的样本计算一个向量表示,然后计算不同样本所对应向量表示的距离。
匹配网络
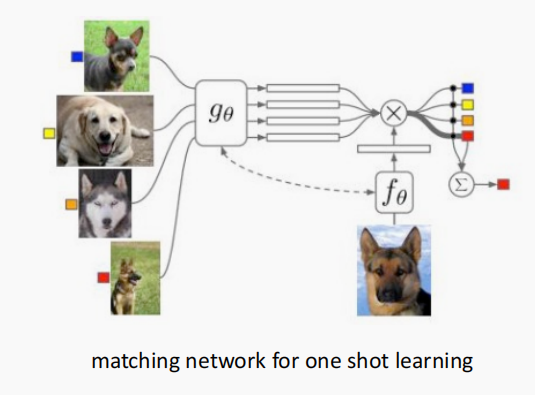
匹配网络对孪生网络进行了一些改进,为支持集合查询集构建不同的编码器,最终分类器的输出是支持集合查询集自检预测值的加权求和。
原型网络
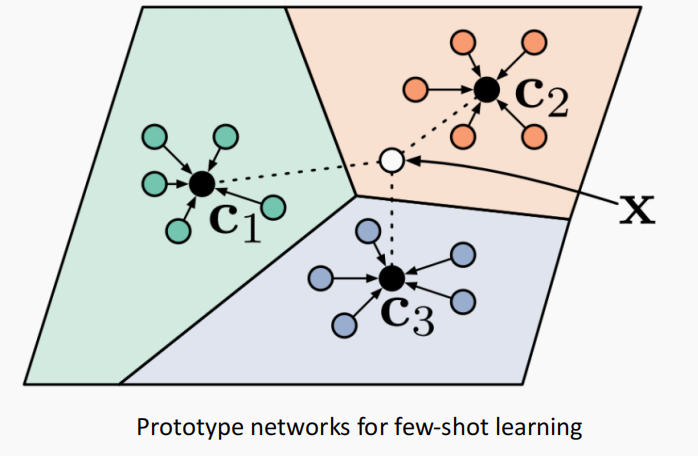
原型网络试图构建样本的嵌入空间,然后试图优化这个空间,使得在这个嵌入空间里同类别的样本之间距离应该足够的近,不同类别样本之间的距离足够的远。
这样就可以利用这个嵌入空间做少样本学习,来了一个新样本只要 投影到这个空间中,然后找距离最近的类别(中心)。
元学习
上面是基于KNN的方法,下面来介绍下基于优化的方法。
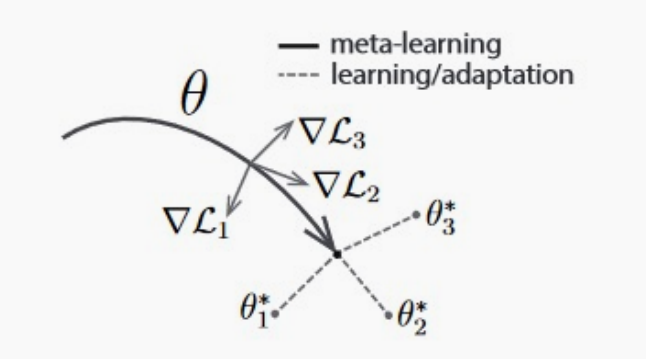
在训练的过程中,试图学习的模型权重是一个更好的初值,从该初值出发可以用最少的分类样本快速适应一个新任务。
NLU中的OOD检测
我们之前看到的方法都有一个默认假设,假设训练数据集和测试数据集是同分布的。即在测试时遇到的类别都在训练时见过。但这个假设实际上过强了,尤其是在NLU中,我们不知道用户会输入怎样的命令。

比如上面这个人对你的NLU模型说“把相册吃掉”,这个意图显然是有问题的,无法实现的,应该归类为空意图或异常意图。
但是难点在于我们无法预先知道会有哪些有问题的命令,同时哪怕是用户输入的这些异常语句,它们和正常语句可能就相差一两个词语。比如上面变成“把相册删掉”就是一个正常意图。
OOD(Out-Of-Domain)检测就是如何检测出这些异常的输入。那么怎么做呢?
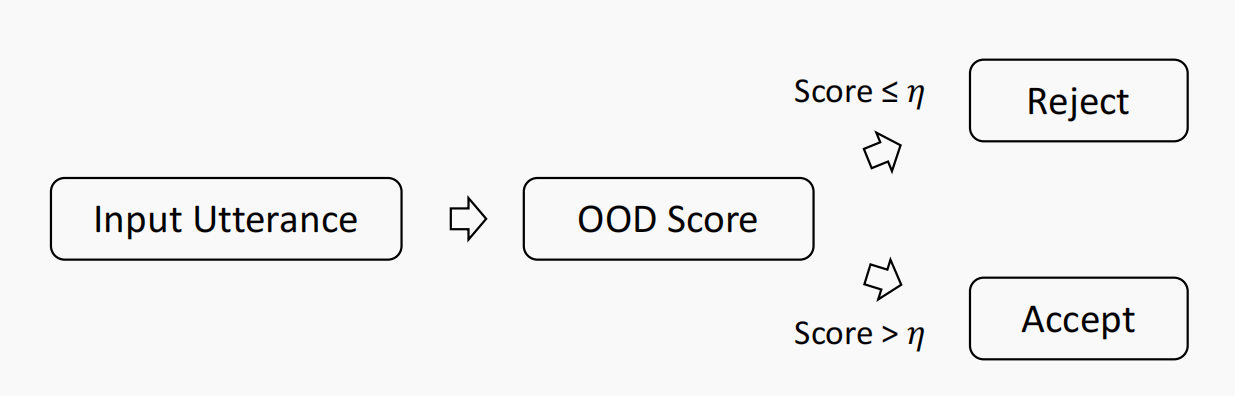
常用的做法是计算一个OOD分数,并设定一个阈值,如果超过该阈值才接收,否则当成异常输入。
大家的工作主要在于如何更准确地计算这个OOD分数。
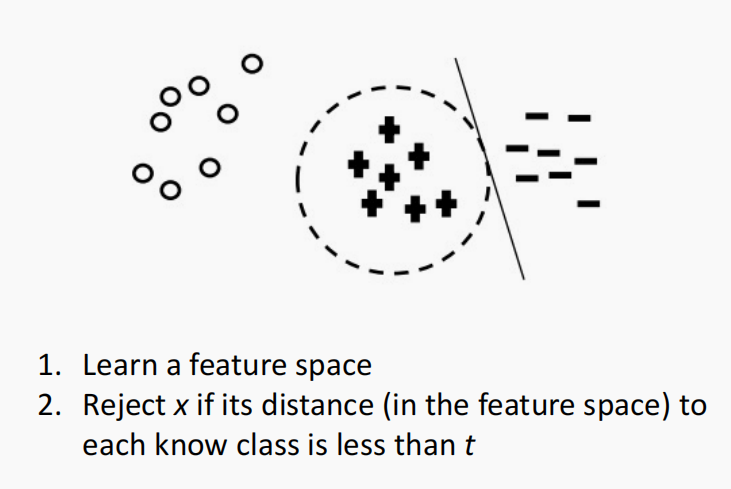
来自论文 Breaking the Closed World Assumption in Text Classification. NAACL 20 16
比较容易想到的就是基于KNN的方式,也就是基于距离的方式。
即学习一个特征空间,计算新来样本的表示,然后计算该表示里已知类别(簇)的最小值,如果该最小值过大,那么就认为是一个异常输入。

来自论文 A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
还有一个做法是直接使用Softmax的预测作为OOD检测的标准,即使用预测概率最大值最为OOD检测的标准,如果这个概率最大值很小,那么就认为是异常输入。
☆这也是目前常用的检测方法,因为它的效果很不错。
NLU系统的可扩展性
随着对话系统的扩展,所支持的意图和领域越来越多。
这个问题的难点在于不同领域之间的意图可能会有冲突。
比如用户输入“购物公园附近的餐厅”,百度地图和大众点评都能完成这个意图,百度地图做的是导航,假设用户想到那里去;而大众点评给出的是其他人的评价,假设用户想知道这里的餐厅怎么样。具体要归在哪个意图可能还需要结合用户的偏好。
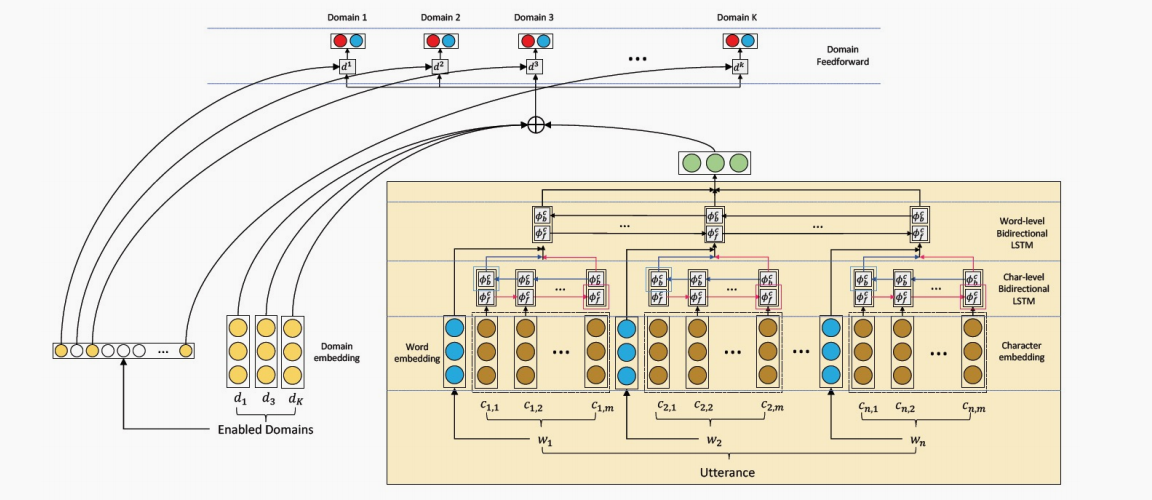
来自论文 Efficient Large-Scale Domain Classification with Personalized Attention
这里有一篇可参考的思路,它会每个领域都维护一个二分类器,同时为用户的偏好维护一个特殊的表示向量。根据用户的偏好来激活每个不同的领域,这种做法可以很好地维护一个可扩展的NLU系统。后续会有一篇专门的文章来分析这篇论文。
参考
- 贪心学院课程
- A Joint Model of Intent Determination and Slot Filling for Spoken Language Understanding
- Attention-Based Recurrent Neural Network Models for Joint Intent Detection
- A self-attentive model with gate mechanism for spoken language understanding
- Changliang Li, et al. A self-attentive model with gate mechanism for spoken language understanding
- End-to-end memory networks with knowledge carryover for multi-turn spoken language understanding
- Dynamic time-aware attention to speaker roles and contexts for spoken language understanding
- Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结