您现在的位置是:首页 >其他 >SOME/IP协议详解[7 SOME/IP序列化]网站首页其他
SOME/IP协议详解[7 SOME/IP序列化]
什么是序列化与反序列化?
- 序列化是指将数据结构或对象按定义的规则转换成二进制串的过程。
- 反序列化是指将二进制串依据相同规则重新构建成数据结构或对象的过程。
而本质就是一种编码规范。
在SOME/IP中使用序列化的目的和作用?
- 使数据按照固定格式进行编排成为字节序,实现数据在网络上的传输。
7.1 说明
在AUTOSAR中是指数据在PDU中的表达形式,可以理解为来自应用层的真实数据转换成固定格式的字节序,以实现数据在网络上的传输。软件组件将数据从应用层传递到RTE层,在RTE层调用SOME/IP Transformer,执行可配置的数据序列化(Serialize)或反序列化(Deserialize)。SOME/IP Serializer将结构体形式的数据序列化为线性结构的数据;SOME/IP Deserializer将线性结构数据再反序列化为结构体形式数据。在服务端,数据经过SOME/IP Serializer序列化后,被传输到服务层的COM模块;在客户端,数据从COM模块传递到SOME/IP Deserializer反序列化后再进入RTE层。如下图参考Autosar Com过程。
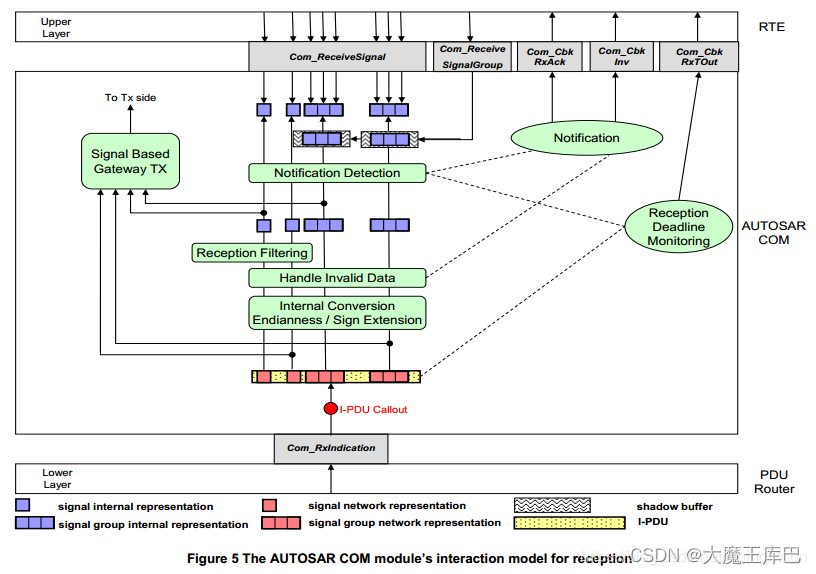
7.2 大小端问题
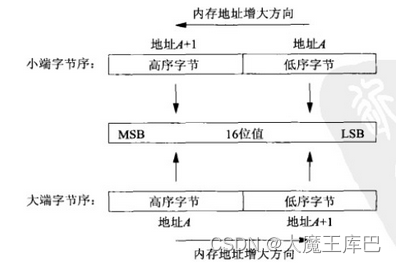
对于一个由2个字节组成的16位整数,在内存中存储这两个字节有两种方法:一种是将低序字节存储在起始地址,这称为小端(little-endian)字节序;另一种方法是将高序字节存储在起始地址,这称为大端(big-endian)字节序。
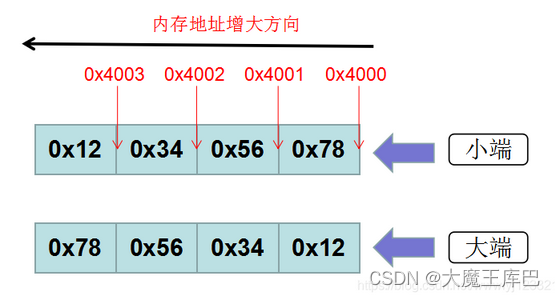
假如现有一32位int型数0x12345678,那么其MSB(Most Significant Byte,最高有效字节)为0x12,其LSB (Least Significant Byte,最低有效字节)为0x78,在CPU内存中有两种存放方式:(假设从地址0x4000开始存放)
总结:
- 大端是高字节存放到内存的低地址
- 小端是高字节存放到内存的高地址
假如有一个数据是0x12345678,直接用memcpy将这个数copy到下图中的Length里面来,如果是大端的话,((uint8)Length)[0]就等于0x12;如果是小端的话,就是0x78。

因为对于赋值的方便性来讲,大端是网络通信中常用的方式(例如TCP/IP),所以SOME/IP格式头也使用大端。Payload由于是用户自主定义的内容,所以用户可以自己决定大小端。
7.3 内存对齐与填充
SOME/IP协议通常使用4字节对齐方式进行数据传输。这意味着每个字段的长度应该是4的倍数。这种对齐方式的主要目的是提高传输效率,因为在很多处理器架构中,4字节对齐是最优的方式,可以在内存中更快地访问数据。此外,使用4字节对齐方式还可以确保字段的偏移量是整数,避免了在解析数据时出现未对齐数据的问题。
在进行SOME/IP序列化时,对于每个结构体中的字段,需要根据其数据类型和对齐要求计算其对齐偏移量。对于大多数数据类型,SOME/IP协议都要求其对齐偏移量是4的倍数。例如,对于一个8字节的double类型字段,其对齐偏移量应该是4的倍数,即0、4、8、12等。如果字段的大小不是4的倍数,那么需要在其后添加额外的填充字节,以便满足对齐要求。
在某些情况下,为了提高传输效率,可能需要使用不同的对齐方式。例如,在某些嵌入式系统中,可能需要使用2字节对齐或8字节对齐方式。在这种情况下,SOME/IP协议可以通过在消息头中包含对齐方式信息来指定所使用的对齐方式。但是,这需要在消息头中添加额外的信息,可能会导致消息大小增加,降低传输效率。因此,4字节对齐方式仍然是SOME/IP协议中最常用的对齐方式。(有些项目实际使用中用的是1字节对齐,即不对齐。因为1字节对齐是最简单的对齐方式,大多编译器很容易实现;并且采用一字节对齐,序列化后没有冗余数据,报文的有效负载段都是有意义的数据,所以总体传输效率得到了一定提升。)
通过在数据后插入填充元素来对齐数据的开头,以确保对齐的数据从特定的内存地址开始。对于有些处理器架构可以更高效地访问数据。
当可变元素不是序列化数据流中最后一个元素,应依据规则对可变元素进行位填充来实现数据对齐。
填充示例:
示例1.
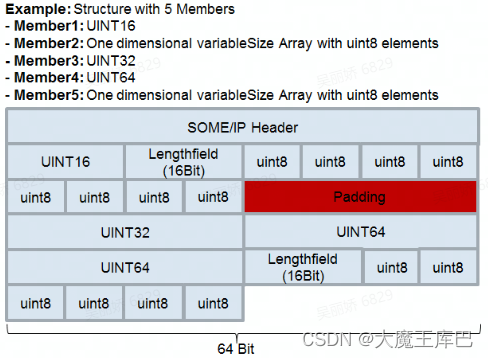
示例2.

注:数据对齐填充应尽量以8、16、32、64、128或256长度长度进行。
但是!
对于不同的CPU,数据的存放有不同的对齐原则,有8、16、32甚至64位对齐(可以配置)。如果一个数据是按照CPU对齐的,那么在反序列化的时候会有一定的性能优势。但是SOME/IP序列化的时候只支持对动态数据类型自动添加填充位(即动态数组、动态字符串)。使用场景比较局限且序列化的时候还会消耗一些性能,还有一种场景是使用一条tcp/udp报文承载多个someip报文的时候,原本对齐的数据也可能被破坏。博主感觉比较鸡肋,很多时候都默认使用8bit对齐(也就是不对齐)。我们也举个例子简单讲讲:

假如我们设计的服务接口有两个参数,一个是uint8 arr[5],另一个是uint8 arr2[2],且假设两个数组都是动态数组。动态数组都是要加长度域的,以表示后面的数组的字节数,假设arr使用2bytes的长度域,arr2使用1byte的字节域。当前CPU是4字节对齐,那么序列化完arr的5个数据后,就不能立即序列化arr2。因为arr的长度域+数据域一共7bytes,不是4的整数倍,要填充1byte。而后面的arr2由于是该someip报文的所有元素的末尾元素,虽然其也是动态数组,但是不用填充(因为后面没有数据了,不会影响后面数据的反序列化性能)。
7.4 都有哪些数据类型
拿C语言举例,能用到的数据类型有:
- 基础数据类型:就是C语言中的保留字能直接使用的类型及其重命名类型。如uint8,short,long和float64等
- 复杂数据类型:就是C语言中需要通过基础数据类型进行组合的新类型。如struct,union,array和string等
需要强调的一点是:string和动态array这样的类型在C语言中是不存在的,但是string可以通过array模拟;动态array也可以通过struct模拟。在CP协议中,可以识别这些模拟出来的类型,并序列化成string和动态array。下面列举一下someip所支持的所有可序列化的数据类型。
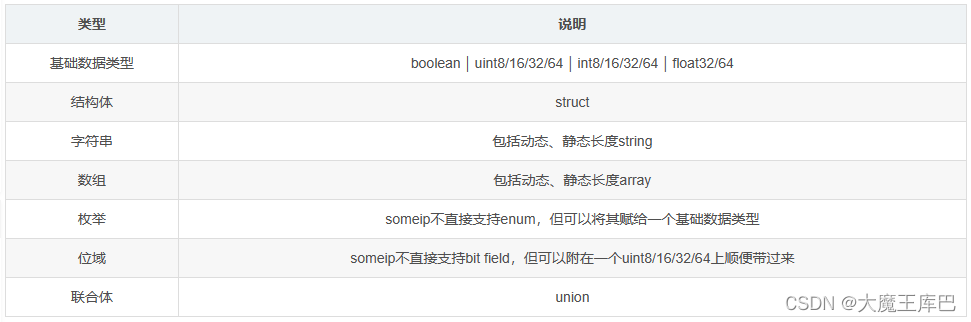
需要注意的是:
- someip不支持指针的直接序列化,因为没有任何意义,通信双方的内容地址和存放的数据都是不同的,直接传地址是去不到对应数据的。
- someip支持使用TLV(Tag Length Value)格式传输数据,需要配置打开,后续会有一章专门讲解。
7.5 基础数据类型序列化(Basic Datatypes)
本章比较简单,就是对基础数据类型的序列化规则,下面详细列举了所有someip支持传输的基础数据类型,看懂下面的表就可以了。

还有一点是,大于8bit的数据都有大小端问题,7.1章也讲过,Payload里的数据是支持用户配置大小端的。所以只要通信双方协商一致,就没有问题。
7.6 序列化:结构体(Struct)
上一章讲解的基础数据类型的序列化说简单一点就是挨个存放到buffer里,而负责数据类型的序列化是有一定规则的,下面要讲解的便是这些规则。
7.6.1 结构体序列化
结构体是由其他数据类型组合成的一个新的数据类型。单论结构体自身是没有任何意义的,也不能携带数据;只有结构体里面的元素才能存放数据。所以最终将结构体序列化后存放到buffer里玩外发的就是这些元素的值。
结构体也可以嵌套设计(这是应用上常用的方式,甚至可以结构体里有数组元素,数组元素的类型又是结构体等方式),总之c语言能定义出来的排列组合的数据类型,someip都能支持序列化。
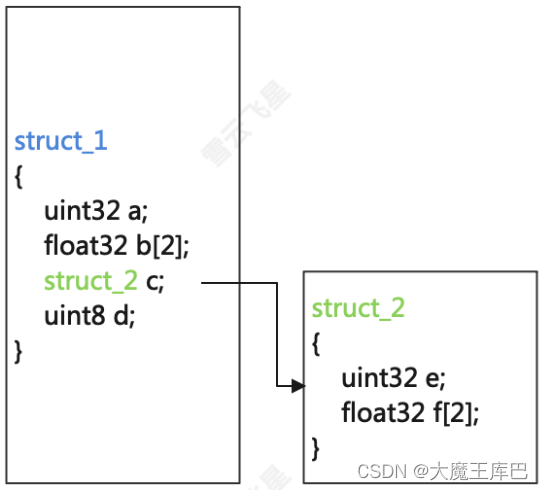
下面是3个结构体嵌套的举例:
- struct1里有三个元素,最后一个元素的数据类型是struct2
- struct2里也有三个元素,最后一个元素的数据类型是struct3
- struct3以此类推

嵌套的结构体就形成了一个树,我们做序列化就是在做遍历这颗树,然后存放到buffer中。而someip序列化遍历都是使用的深度遍历法,即在一层结构体的各个元素,要先进入元素内部遍历下一层,而不是遍历到下一个元素。如果按照下图来说明:
深度遍历的顺序是:aàbàefàd
广度遍历的顺序是:aàbàdàef
还有一点是上述序列化到buffer中都是连续的,不能插入一些无用数据。
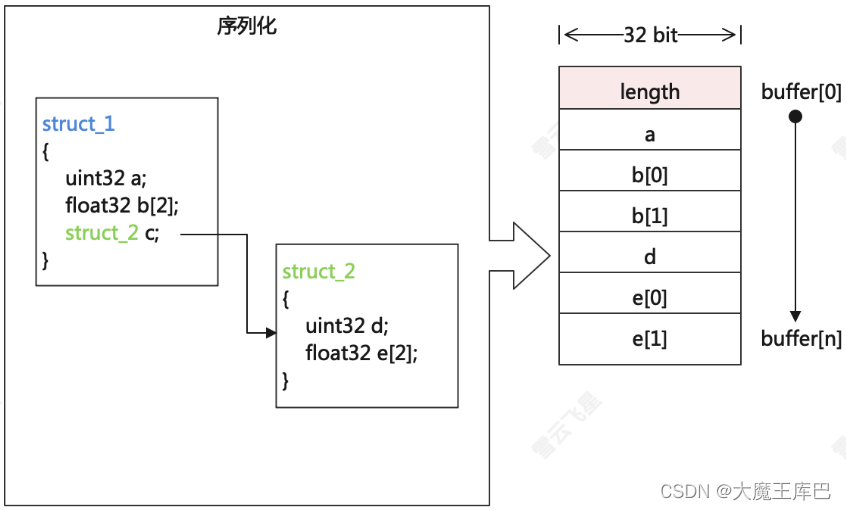
7.6.2 结构体可选长度域
结构体序列化的时候,还可以添加一个长度域,用来表示后面多长是这个结构体的数据。这个length可以配置占有0/8/16/32位,且这个length里面的长度值的计算不包含length本身的长度(按byte数计算)。比如下图中的length的值就应该是24(6*4byte)。
7.7 序列化:字符串(String)
7.7.1 字符串序列化
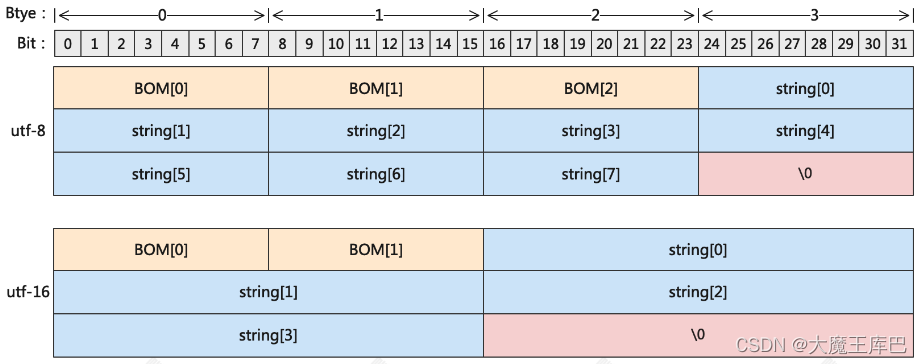
为了更好的兼容所有平台,someip规定对string的定义要基于标准的utf-8/16BE/16LE。
- utf-8:字符串的单个字符要按照8bit编码;字符串序列化前面需要有3 bytes的BOM(byte order mark,大家可以理解为一个必要的string格式的标识符,具体可以谷歌一下,这里就不细讲了);字符串必须以�(0x00,注意这里占用1字节)结尾
- utf-16:字符串的单个字符要按照16bit编码;字符串序列化前面需要有2 bytes的BOM(16BE和16LE的2 bytes的BOM顺序刚好相反);字符串必须以�(0x0000,占用2字节)结尾
从utf-16的定义上不难看出,其字节数必定是偶数。一般我们常用的是utf-8,但是如果说要传输中文字符串,那必然要选择utf-16,不过实际应用中很少遇到。
7.7.2 静态字符串
像c语言这样的嵌入式语言没有直接对string类型的定义,一般是通过数组模拟出来。特别是在嵌入式系统中,一般不允许动态开辟内存,所以都会给string一个长度上限。而在序列化的时候,只会序列化到�的地方,后面的数据就不会继续序列化了。
还有值得一提的是,某些车厂仍然将string序列化成array的形式,这种形式不是未来安全所提倡的趋势,someip中有开关可以控制,但是大家尽量使用我们讲解的标准someip的序列化形式。
7.7.3 动态字符串
动态字符串与静态最大的区别是在字符串头部添加了长度域,该长度域的长度值等于后续从BOM开始到�的长度和。动态字符串的长度域本身默认占用4个bytes(如下图,以utf-8为例),也可以配置成1,2个bytes。在反序列化的时候会校验length的长度和解析到�的长度是否一致,如果有偏差会报错。

实际上动态字符串和静态字符串都可以是动态的,因为静态字符串是按照�之前的数据序列化,长度也是动态的。只是它们两个在c语言中的类型定义有所不同:
- 静态string是一个char数组
- 动态string是一个struct,struct里有两个元素,一个是指示后面有多少个string元素的size indicator,一个是char数组

需要注意的一点是这里的sizeIndicator是指的后面的string中有多少个元素(如果是utf-16,等于字节数除以2);而最终序列化到buffer中,是指的序列化后的长度,是后面的字节数。比如同样是 “HelloWorld” 这句话,那么:
- utf-8:
sizeIndicator = 11(HelloWorld共10个字符,加上�,共11个元素)
length = 14(上述11+3bytes的BOM)
- utf-16:
sizeIndicator = 11(HelloWorld共10个字符,加上�,共11个元素)
length = 24(上述11*2+2bytes的BOM)

7.8 序列化:数组(Arrays)
数组和字符串很类似,都是分为静态和动态两类,但是在序列化的方式上又有所区别。
7.8.1 静态长度数组
静态数组的长度是固定的,不像静态字符串那样通过�来实现变长。且静态数组可以像动态字符串那样通过配置添加一个长度域(也可以没有)。
我们举一个2维数组的例子看看实际序列化后的样子:
![]()
可以看到2维数组有两类不同的长度域,一种是第1维度的length_all,长度为后续所有数据的字节数总和16;另一种是第2维度的legnth_0/1,分别代表arr[0]/[1]的长度,都是4。如果后续还有3维,或者更高维度的数组,以此类推即可。

7.8.2 动态长度数组
动态长度数组和静态的区别也是在其数据类型的定义上(和string类似),sizeIndicator也是指的元素,length是指长度,这里不再赘述。动态长度数组必须要有length域,否则就是静态数组;someip会按照sizeIndicator的大小进行序列化,sizeIndicator没有覆盖的数据不会被传输。序列化后的layout也上面静态数组中的图长的一样。

当然,以上仅仅是举例,数组的元素也可以不是基础数据类型,是一些结构体,或者string之类的都行。
7.9 序列化:联合体(Union/Variant)
联合体可以说是我们使用最少的类型了,甚至有的车厂直接静止使用联合体,以确保someip通信报文的易读性;同时有些c语言规范也不提倡使用联合体,容易在使用中出问题,所以可能是我们使用中最不常见的一种形式 联合体是说将一块内存的数据可以解析成不同的类型,以方便调用,而序列化的时候,只能选定其中一种类型进行传输。比如我们有如下的union定义:

我们选定按照b类型传输,那么最终的layout如图:

我们分为3段来看:
- length 代表这个union序列化后的长度,这里包括后面的type+数据+填充的长度。这个长度域也可以配置占用字节数(0,1,2,4bytes;其中0就是不要有长度域)
- type 代表要将这个联合体以哪种类型进行序列话,比如我们选择上面的uint16,那么对应的类型是2(0保留为NULL的含义,从1开始算,uint16对应type==2)
- 然后就是uint16 类型的b这个数据本身
- 最后为了之前讲过的对齐原因,这里填充了2bytes
7.10 序列化:TLV简述(Tag Length Value)
7.10.1 什么是TLV
TLV是Tag Length Value的简称,是someip序列化的一种格式,会有部分车厂在使用,但并不是主流。我们简单讲解一下,让大家知道这个干什么的,不对细节做进一步分析。与之前讲过的所有的类型的序列化格式有所区别,tlv还会再加一层标签,对每个数据进行单独标识,方便管理。标签可以在两个地方加:
- someip服务接口参数
- 某参数定义的struct里的成员
7.10.2 TLV格式
从下图中可以看到,如果光看蓝色部分,就是和前面章节中讲解的序列化方式是一样的,而这个主要加了2 bytes的tag头。一个someip报文里可以有很多这样的数据。可以看出,tag+length+数据的形式就在字节流中将每个数据划分成了一段,形成了一个链表,如果不想要该tag的数据,就可以通过length直接跳过去,甚至不用再反序列化(注意的一点是,这里length无论是静态动态数据类型,只要不是基础数据类型都必须要有长度域,以便能通过长度域找到下一个数据)。

再说一下上面图中的tag头,主要是3部分组成,1bit的res保留,3bits的wire type,和12bits的data ID:
- wire type: wire type用来指示后续的长度域占用几个bytes,如果是基础数据类型,没有长度域,其余类型都必须有长度域

- data ID: data ID对于每一层级的数据要唯一,比如有一个2维度嵌套的struct,那么每一维度都可以使用data ID = 1,但是同一维度ID不能相同。







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结