您现在的位置是:首页 >学无止境 >【Python可视化大屏】「淄博烧烤」热评舆情分析大屏网站首页学无止境
【Python可视化大屏】「淄博烧烤」热评舆情分析大屏
文章目录
一、开发背景
您好,我是@马哥python说 ,一枚10年程序猿。
自从2023.3月以来,"淄博烧烤"现象持续占领热搜流量,体现了后疫情时代众多网友对人间烟火气的美好向往,本现象级事件存在一定的数据分析实践意义。
动态效果演示:
【大屏演示】Python可视化舆情大屏「淄博烧烤」
二、爬虫代码
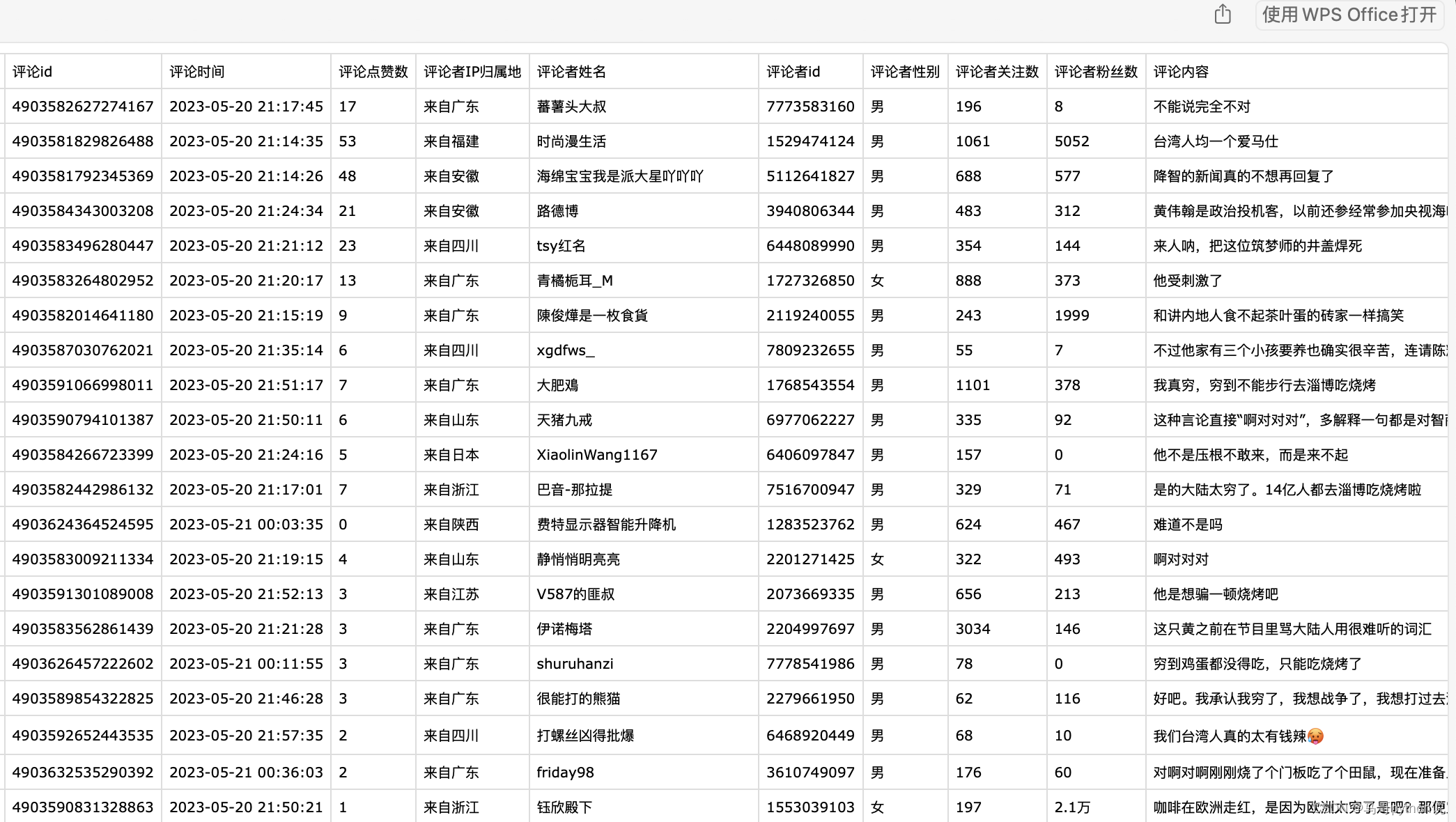
2.1 展示爬取结果
爬虫代码部分不做讲解。
展示爬取结果:
2.3 导入MySQL数据库
最核心的三行代码:
# 读取csv数据
df = pd.read_csv('去重后_' + comment_file)
# 把csv数据导入MySQL数据库
df.to_sql(name='t_zbsk', con=engine, chunksize=1000, if_exists='replace', index=False)
print('导入数据库完成!')
用create_engine创建数据库连接,格式为:
create_engine(‘数据库类型+数据库驱动://用户名:密码@数据库IP地址/数据库名称’)
这样,数据库连接就创建好了。
然后,用pandas的read_csv函数读取csv文件。
最后,用pandas的to_sql函数,把数据存入MySQL数据库:
- name=‘college_t2’ #mysql数据库中的表名
- con=engine # 数据库连接
- index=False #不包含索引字段
- if_exists=‘replace’ #如果表中存在数据,就替换掉
非常方便地完成了反向导入,即:从csv向数据库的导入。
这个部分的讲解视频:
仅用Python三行代码,实现数据库和excel之间的导入导出
三、可视化代码
3.1 大标题
由于pyecharts组件没有专门用作标题的图表,我决定灵活运用Line组件实现大标题。
首先,找到一张星空图作为大屏背景图:

然后,在Line组件中加入js代码,加载背景图:
# 设置背景图片
line3.add_js_funcs(
"""
var img = new Image(); img.src = './static/bg2.png';
"""
)
大标题效果如下:

3.2 词云图(含:加载停用词)
绘制词云图,需要先进行中文分词。既然分词,就要先设置停用词,避免干扰词影响分析结果。
这里采用哈工大停用词作为停用词词典。
# 停用词列表
with open('hit_stopwords.txt', 'r') as f:
stopwords_list = f.readlines()
stopwords_list = [i.strip() for i in stopwords_list]
这样,所有停用词就存入stopwords_list这个列表里了。
如果哈工大停用词仍然无法满足需求,再加入一些自定义停用词,extend到这个列表里:
# 加入自定义停用词
stopwords_list.extend(
['3', '5', '不', '都', '好', '人', '吃', '都', '去', '想', '说', '还', '很', '…', 'nan', '真的', '不是',
'没', '会', '看', '现在', '觉得', ' ', '没有', '上', '感觉', '大', '太', '真', '哈哈哈', '火', '挖', '做',
'一下', '不能', '知道', '这种', '快'])
现在就可以愉快的绘制词云图了,部分核心代码:
wc = WordCloud(init_opts=opts.InitOpts(width='600px', height=chart_height, theme=theme_config, chart_id='wc1'))
wc.add(series_name="评论内容",
data_pair=data300,
word_gap=1,
word_size_range=[20, 70],
) # 增加数据
wc.set_global_opts(
title_opts=opts.TitleOpts(pos_left='center',
pos_top='0%',
title=v_title,
title_textstyle_opts=opts.TextStyleOpts(font_size=20, color=title_color) # 设置标题
),
tooltip_opts=opts.TooltipOpts(is_show=True), # 显示提示
)
词云图效果:

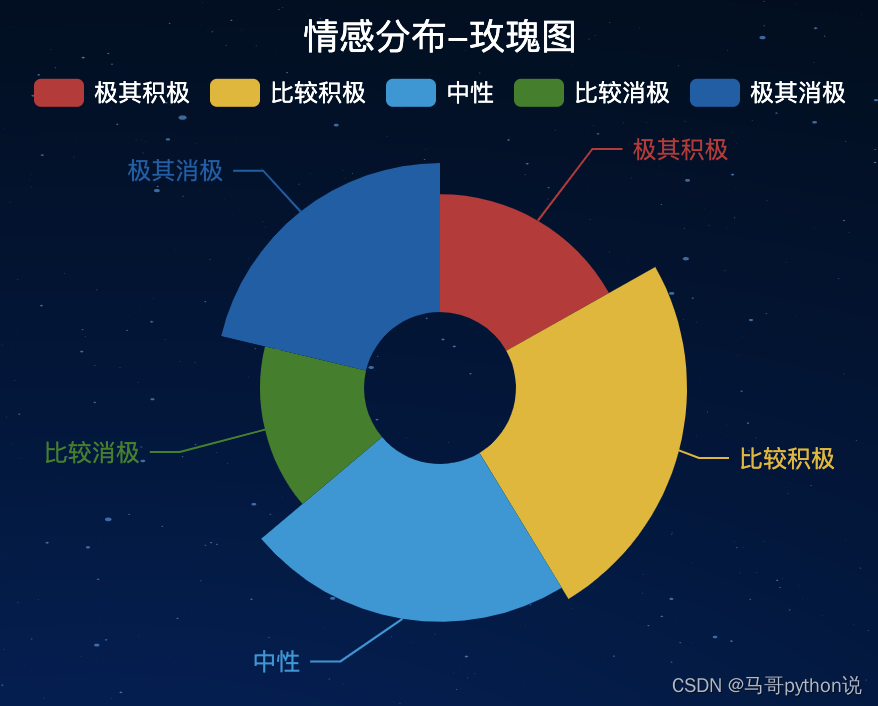
3.3 玫瑰图(含:snownlp情感分析)
先对评论数据进行情感判定,采用snownlp技术进行情感打分及判定结果:
for comment in cmt_list:
sentiments_score = SnowNLP(comment).sentiments
if 0 <= sentiments_score < 0.2: # 情感分小于0.2,判定为极其消极
tag = '极其消极'
neg_very_count += 1
elif 0.2 <= sentiments_score < 0.4: # 情感分在0.2和0.4之间,判定为比较消极
tag = '比较消极'
neg_count += 1
elif 0.4 <= sentiments_score < 0.6: # 情感分在0.4和0.6之间,判定为中性
tag = '中性'
mid_count += 1
elif 0.6 <= sentiments_score < 0.9: # 情感分在0.6和0.9之间,判定为比较积极
tag = '比较积极'
pos_count += 1
else: # 情感分大于0.9,判定为极其积极
tag = '极其积极'
pos_very_count += 1
将情感分析结果用pandas保存到一个Excel文件里,如下:
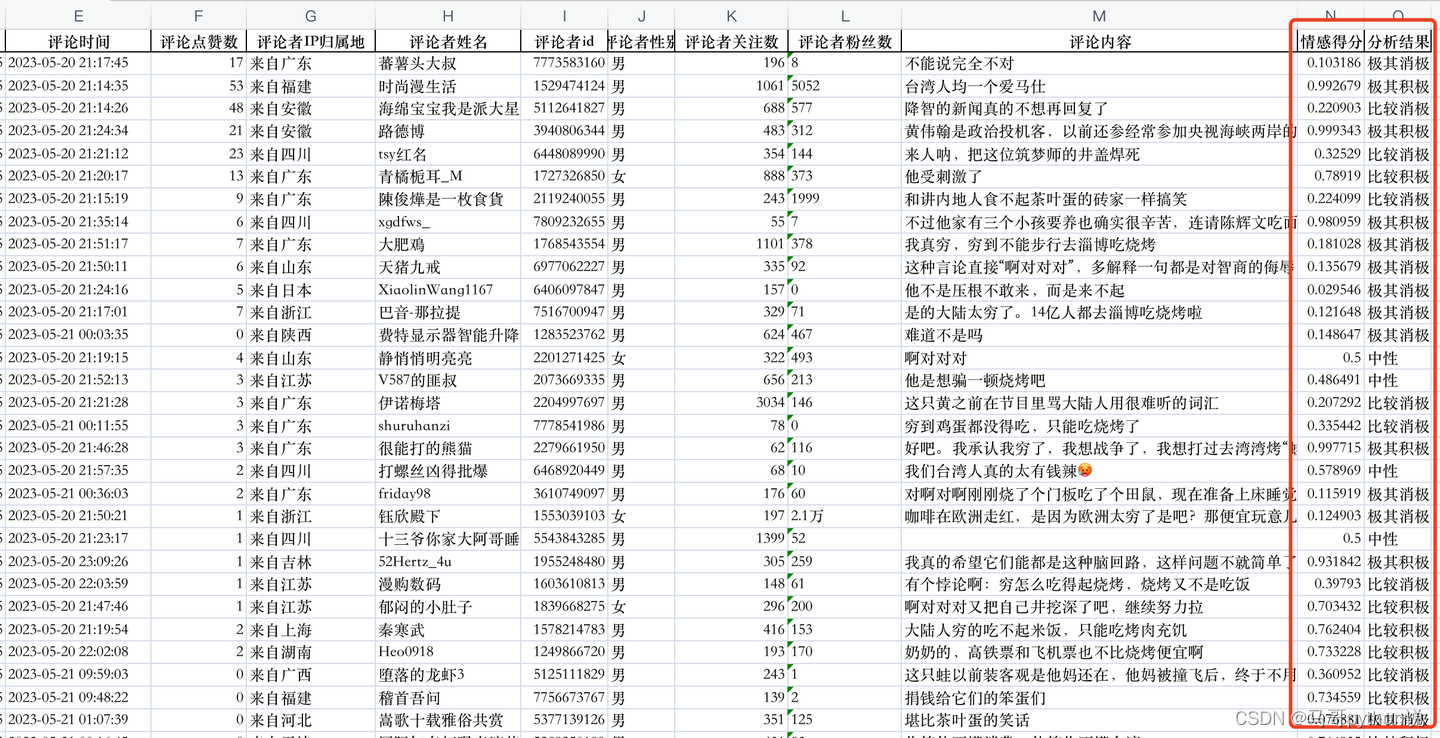
绘制玫瑰图,部分核心代码:
# 画饼图
pie = (
Pie(init_opts=opts.InitOpts(theme=theme_config, width=chart_width, height=chart_height, chart_id='pie1'))
.add(series_name="情感分类", # 系列名称
data_pair=[ # 添加数据
['极其积极', pos_very_count],
['比较积极', pos_count],
['中性', mid_count],
['比较消极', neg_count],
['极其消极', neg_very_count],
],
rosetype="radius", # 是否展示成南丁格尔图
radius=["20%", "65%"], # 扇区圆心角展现数据的百分比
) # 加入数据
.set_global_opts( # 全局设置项
title_opts=opts.TitleOpts(title=v_title,
pos_left='center',
title_textstyle_opts=opts.TextStyleOpts(color=title_color, ), ), # 标题
legend_opts=opts.LegendOpts(pos_left='center', pos_top='8%', orient='horizontal',
textstyle_opts=opts.TextStyleOpts(color='white', )) # 图例字体颜色
)
)
玫瑰图效果:
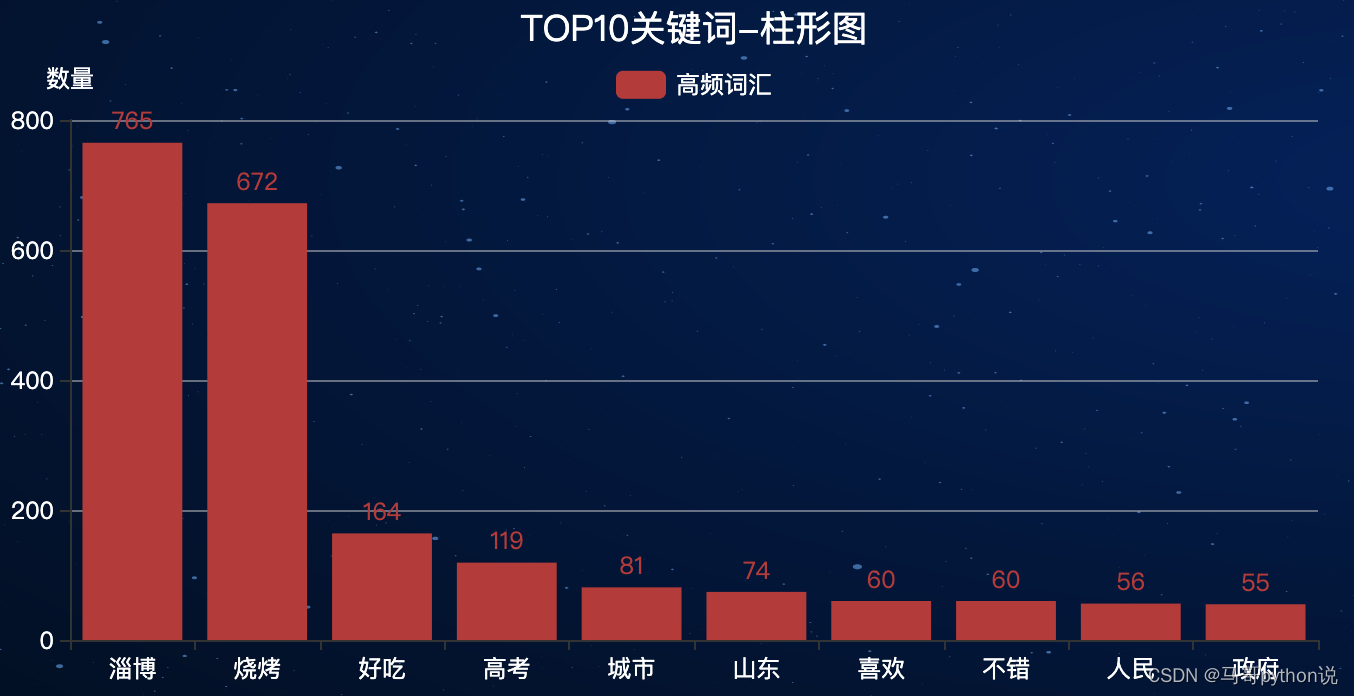
3.4 柱形图-TOP10关键词
先根据词云图部分提取出TOP10高频词(过滤掉停用词之后的):
data10 = collections.Counter(result).most_common(10)
然后带入柱形图,部分核心代码:
# 画柱形图
bar = Bar(
init_opts=opts.InitOpts(theme=theme_config, width='780px', height=chart_height,
chart_id='bar1')) # 初始化条形图
bar.add_xaxis(x_data) # 增加x轴数据
bar.add_yaxis("高频词汇", y_data) # 增加y轴数据
bar.set_series_opts(label_opts=opts.LabelOpts(position="top")) # Label出现位置
bar.set_global_opts(。。。)
柱形图效果:
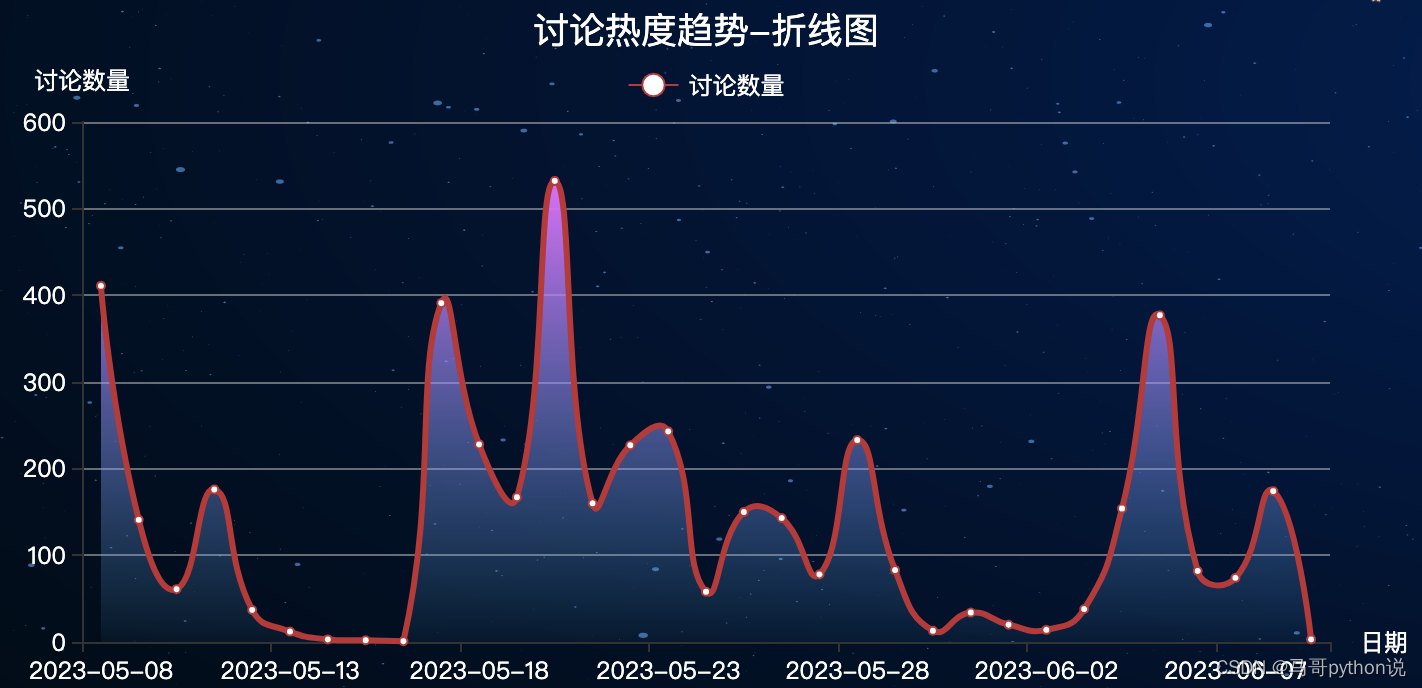
3.5 折线图-讨论热度趋势
首先,根据评论时间统计出每天的评论数量:
# 按日期分组统计评论数量
df_comments['评论日期'] = df_comments['评论时间'].astype(str).str[:10] # 提取日期
grp = df_comments.groupby('评论日期')['评论内容'].count()
然后,根据统计数据画出折线图,部分核心代码:
line = Line(
init_opts=opts.InitOpts(width='780px', height=chart_height, theme=theme_config, chart_id='line1')) # 实例化
line.add_xaxis(x_data) # 加入X轴数据
line.add_yaxis('讨论数量', y_data, is_smooth=True,
areastyle_opts=opts.AreaStyleOpts(color=JsCode(area_color_js), opacity=1), ) # 加入Y轴数据
line.set_global_opts(。。。)
折线图效果:
3.6 地图-IP分布
由于IP属地字段都包含"来自"两字,先进行数据清洗,将"来自"去掉:
# 数据清洗-ip属地
ip_count = df_comments['评论者IP归属地'].str.replace('来自', '')
然后统计各个IP属地的数量,方便后续带入地图可视化:
# 统计各IP数量
ip_count = ip_count.value_counts()
下面开始绘制地图,部分核心代码:
f_map = (
Map(init_opts=opts.InitOpts(width='600px',
height='600px',
theme=theme_config,
page_title=v_title,
chart_id='map1',
bg_color=None))
.add(series_name="评论数量",
data_pair=list(zip(loc_list, value_list)),
maptype="china", # 地图类型
is_map_symbol_show=False)
.set_global_opts(。。。)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=8, ),
markpoint_opts=opts.MarkPointOpts(
symbol_size=[90, 90], symbol='circle'),
effect_opts=opts.EffectOpts(is_show='True', )
)
)
地图效果,如下:

当然,地图中的颜色,都是自己设置的十六进制颜色,可以根据自己的喜好更改。
3.7 Page组合大屏
最后,也是最关键的一步,把以上所有图表组合到一起,用Page组件,并且选用DraggablePageLayout方法,即拖拽的方式,组合图表:
# 绘制:整个页面
page = Page(
page_title='热门评论可视化分析大屏-以"淄博烧烤"为例',
layout=Page.DraggablePageLayout,
)
page.add(
# 绘制:大标题
make_title(v_title='热门评论可视化分析大屏-以"淄博烧烤"为例'),
# 绘制:词云图
make_wordcloud(v_title='评论内容-词云图'),
# 绘制:饼图
make_analyse_pie(v_title='情感分布-玫瑰图'),
# 绘制:柱形图
make_bar(v_title='TOP10关键词-柱形图'),
# 绘制:折线图
make_line(v_title='讨论热度趋势-折线图'),
# 绘制:地图
make_map(v_title='评论IP分布-中国地图'),
)
page.render('大屏_临时.html')
本代码执行完毕后,打开临时html并排版,排版完点击Save Config,把json文件放到本目录下。
再执行最后一步,调用json配置文件,生成最终大屏文件。
Page.save_resize_html(
source="大屏_临时.html", # 源html文件
cfg_file="chart_config.json", # 配置文件
dest="大屏_最终.html" # 目标html文件
)
至此,所有代码执行完毕,生成了最终大屏html文件。
四、彩蛋-多种颜色主题
分享一个小技巧,我设置了一键更换颜色主题:
# 整体主题颜色
theme_config = ThemeType.SHINE
只需更换ThemeType参数,即可实现一键更换主题!
4.1 INFOGRAPHIC主题

4.2 MACARONS主题

4.3 SHINE主题

4.4 WALDEN主题

4.5 WESTEROS主题

4.6 WHITE主题

4.7 WONDERLAND主题

更多颜色主题等待小伙伴去发掘!
五、技术总结
技术开发流程:
- requests 爬虫发送请求
- json 解析返回数据
- re 正则表达式清洗文本
- pandas保存csv文件
- sqlalchemy 保存MySQL数据
- pyecharts 可视化开发
- snownlp 情感分析
- jieba 中文分词
- pyecharts+page 组合大屏
- flask 启动网页服务
六、在线体验
为了方便大家体验可视化动态交互效果,我把此大屏部署到了服务器,请移步:
马哥python说 - 效果演示
七、演示视频
效果演示视频:
【大屏演示】Python可视化舆情大屏「淄博烧烤」
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结