您现在的位置是:首页 >技术杂谈 >NLP——ELMO;BERT;Transformers网站首页技术杂谈
NLP——ELMO;BERT;Transformers
文章目录
ELMO

ELMO 简介
-
ELMo(Embeddings from Language Models)是一个在2018年由Allen AI研究所开发的新型深度语义词嵌入(word embedding)。ELMo词嵌入是基于上下文的,这意味着对于任何给定的词,它的表示都会根据它出现的上下文而变化。 这是一个重要的进步,因为传统的词嵌入,如Word2Vec或GloVe,为每个词提供一个固定的表示,不考虑词在特定上下文中可能有的不同含义。
-
ELMo的嵌入是通过训练一个**双向的语言模型(bi-directional language model)并使用模型的隐藏状态作为词的嵌入来产生的。**这个语言模型是一个双向的长短期记忆网络(Bi-LSTM),它从左到右(正向)和从右到左(反向)阅读文本,然后将两个方向的隐藏状态拼接在一起,得到每个词的嵌入。
ELMO 优点
相较于以往的方法,ELMo具有几个重要的优点:
-
上下文感知:由于ELMo是基于上下文的,它能够捕捉到词义消歧的信息,例如词“play”的不同含义在不同的上下文中。
-
预训练:和其他词嵌入一样,ELMo是预训练的,这意味着它可以被用作各种NLP任务的输入,从而提高模型的性能。
-
深度表示:由于ELMo使用了深度神经网络(在这种情况下是Bi-LSTM),它可以捕捉到词的复杂语义信息。
然而,与此同时,ELMo模型需要大量的计算资源和时间来训练,这是它的主要缺点。但一旦训练完成,可以将训练得到的模型用于各种NLP任务。
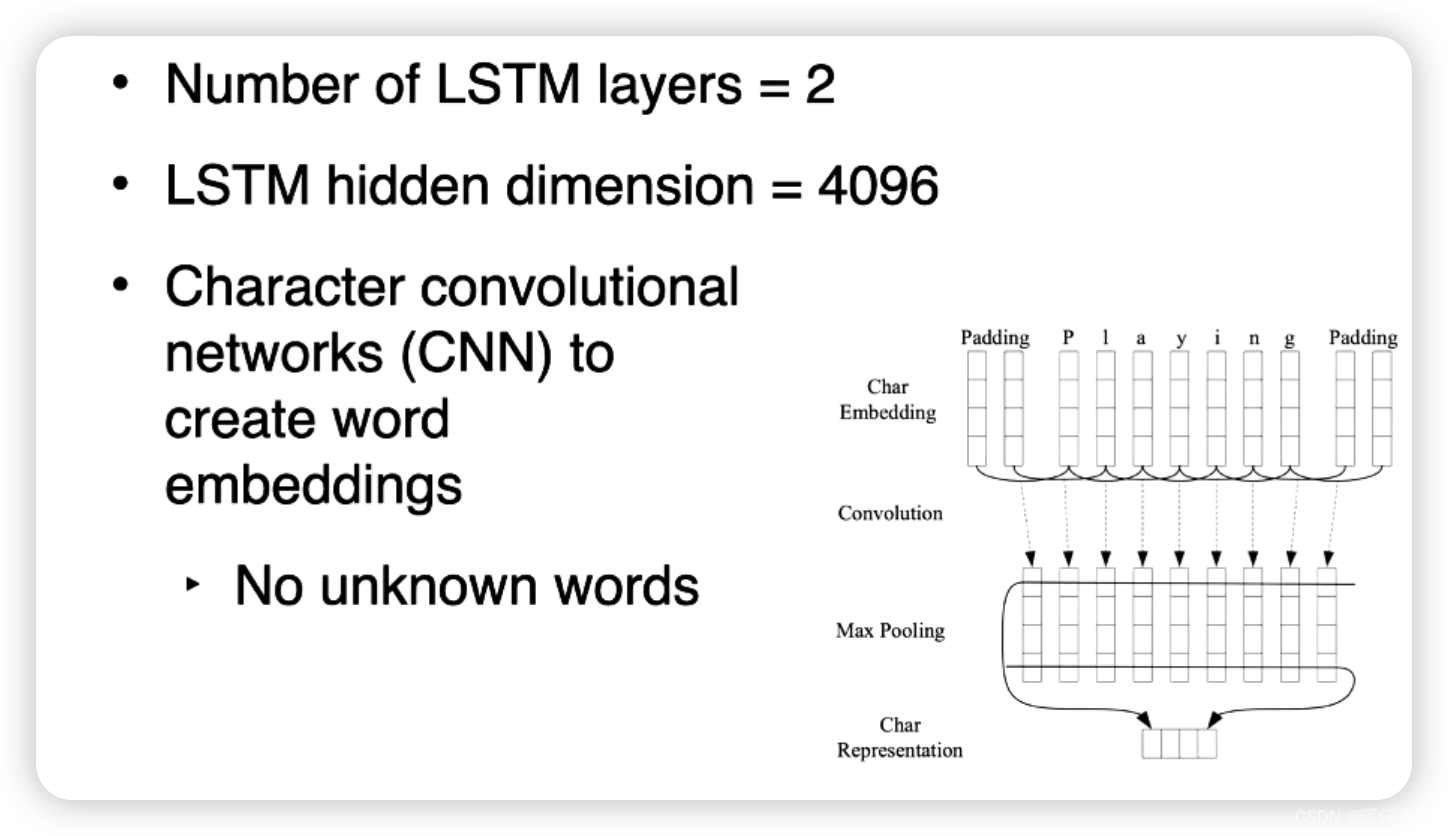
利用了多层的 hidden 表示

- 在传统的RNN(循环神经网络)或者LSTM(长短期记忆网络)中,通常会使用一个堆叠的结构,也就是多层的LSTM。在这种结构中,底层LSTM捕捉了一些局部和语法方面的信息,而顶层LSTM捕捉了一些更全局、更抽象的语义信息。这是因为底层的LSTM处理的是原始的输入词,而顶层的LSTM处理的是底层LSTM的输出,因此,顶层LSTM有更高层次的、更全局的视角。
- 然而,在传统的多层LSTM中,我们通常只使用最顶层的隐藏状态,忽略了底层的隐藏状态。这可能会损失一些有用的信息。
- ELMo的一个重要的创新就是使用了所有层次的隐藏状态。 对于每个词,ELMo的表示是所有层次隐藏状态的加权平均。权重是通过训练学习的,不同的任务可能会赋予不同层次的隐藏状态不同的权重。 这意味着,对于不同的任务,我们可能会更关注不同层次的隐藏状态。 例如,命名实体识别可能更关注底层的语法信息,而情感分析可能更关注顶层的语义信息。
- 通过这种方式,ELMo能够捕捉到词的深层次的语义信息,同时也考虑了词的上下文信息。这使得ELMo在很多自然语言处理任务上都取得了非常好的效果。
ELMO 缺点
-
但是由于
ELMO是基于RNN原理的模型,因此受制于RNN的几个缺点:


-
值得注意的是:ELMo模型使用的是双向长短期记忆网络(Bi-LSTM)模型,它在两个方向上分别训练模型——从左到右和从右到左。这两个方向的LSTM是独立的,它们没有共享参数。 然后,ELMo将两个方向的隐藏状态进行拼接或者加权平均来得到词的表示。
-
同时 ELMO 还有以下缺陷:
-
计算成本高: Bi-LSTM需要在两个方向上 分别进行前向传播和反向传播,这使得它的计算成本比单向LSTM更高。 此外,LSTM模型本身就有很多参数,需要大量的计算资源和时间来训练。
-
无法并行化: 由于LSTM是一种循环神经网络,它需要**按照时间步骤的顺序进行计算,**这使得它无法进行并行化计算。这也是为什么训练LSTM模型需要大量时间的原因。
-
可能损失长距离信息: 虽然LSTM设计成可以处理梯度消失问题,从而捕捉到一定程度的长距离依赖,但在实际应用中,如果序列过长,LSTM仍然可能无法捕捉到太长距离的信息。
-
BERT
-
为了解决 ELMO 模型存在的诸多问题,BERT 应运而生

BERT (Bidirectional Encoder Representations from Transformers) 是一个基于Transformer的模型,与ELMo相比,有一些重要的改进和优点: -
全方位的上下文感知: 虽然ELMo是一个上下文敏感的模型,但是它通过两个单向的LSTM来分别捕获上下文信息。BERT通过使用Transformer的自注意力机制,在每个位置都能捕获双向的上下文信息。 这使得BERT在理解上下文中的词语时更为全面。
- 在ELMo中,双向上下文信息的获取是通过两个独立的、单向的长短期记忆网络(LSTM)完成的。一个LSTM从左到右读取序列,另一个从右到左读取。每个LSTM只能获取单向的上下文信息,然后将两个方向的信息结合起来得到最后的词表示。这种方式虽然能够捕获到双向的上下文信息,但是因为两个方向的信息是独立处理和结合的,所以被认为是"浅"的双向表示。
- 相比之下,BERT使用的是基于Transformer的模型,该模型采用自注意力机制(self-attention mechanism)来获取双向上下文信息。在自注意力机制中,每个词的表示都会考虑到整个序列中所有词的信息,而且这个过程是同时进行的,不需要像LSTM那样一步一步地处理。 这样,每个词的表示都是在同时考虑到双向上下文信息的情况下得到的,因此被认为是"深"的双向表示。
-
并行计算: BERT使用的 Transformer 结构允许在计算时进行并行化,相比于ELMo中使用的RNN(Recurrent Neural Network,如LSTM),BERT在训练和预测时都能更有效地利用硬件资源。
-
预训练任务的设计: BERT使用了两种预训练任务,Masked Language Model (MLM) 和 Next Sentence Prediction (NSP)。MLM任务允许模型在预测被遮蔽(masked)的词时考虑到整个上下文,而NSP任务则让模型理解句子间的关系。这两种任务都使BERT在处理下游任务时具有更强的理解能力。
-
更强的性能: 在多种NLP任务上,BERT都比ELMo展现出了更好的性能。比如在阅读理解、情感分类、命名实体识别等任务上,BERT都设立了新的性能标准。
虽然BERT在以上方面都优于ELMo,但值得注意的是,BERT模型相比于ELMo更加复杂和参数更多,因此需要更多的计算资源和时间进行训练。不过,和ELMo一样,BERT模型一般也是预训练好后,用于各种下游任务,而不需要在每个特定任务上从头开始训练。
BERT V.S. ELMO

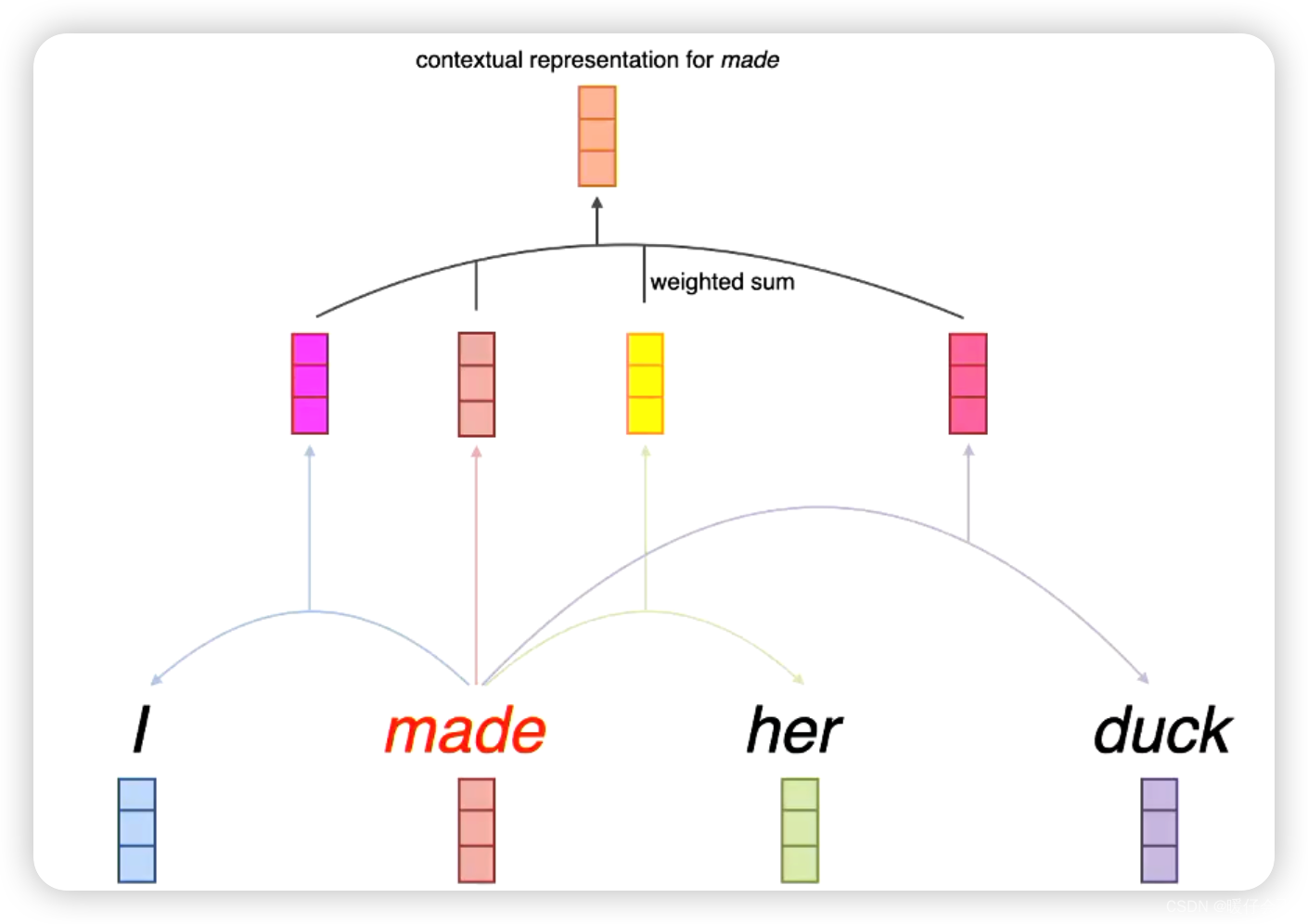
- 从这张图中清晰看出,对 ELMO, E 1 E_1 E1 分别输入两个 LSTM,在左边的 LSTM 的第一层 E 1 E_1 E1 被隐层编码,然后到第二个时间步 E 2 E_2 E2 的信息也被纳入进来,由此 E 1 E_1 E1 和 E 2 E_2 E2 的信息被模型综合考虑、表示;对于逆向的 LSTM 也是如此
- 然而,虽然这种方法可以获取双向的上下文信息,但是由于正向和反向的信息是独立处理的,具体来说,我们并没有在同一时间考虑左右两个方向的上下文。也就是说,**正向LSTM在处理序列时,并不知道反向LSTM的输出,反之亦然。**因此,这种双向表示可能没有充分利用双向上下文信息,只是生硬地拼接了双向的上下文的表示使得表示更加丰富了。
- 但是 BERT 不同,BERT 没有时间步的概念,因此,BERT通过使用Transformer的自注意力机制,在每个位置都能同时考虑整个输入序列中的所有词。从图中可以看出,每个词向量的表示都是结合所有的上下文信息。


两种预训练任务
Object1: Masked Language Model

- 在 MLM 中,输入序列的一部分词会被替换为一个特殊的 [MASK] 标记,然后模型的任务是预测这些被遮蔽的词。这使得模型必须理解上下文,才能准确地预测被遮蔽的词。
Object2: Next sentence prediction

- 在 NSP 任务中,模型需要预测两个句子是否是连续的,这使得模型必须理解句子间的关系。
训练细节

如何使用 BERT

BERT 应用——垃圾邮件分类

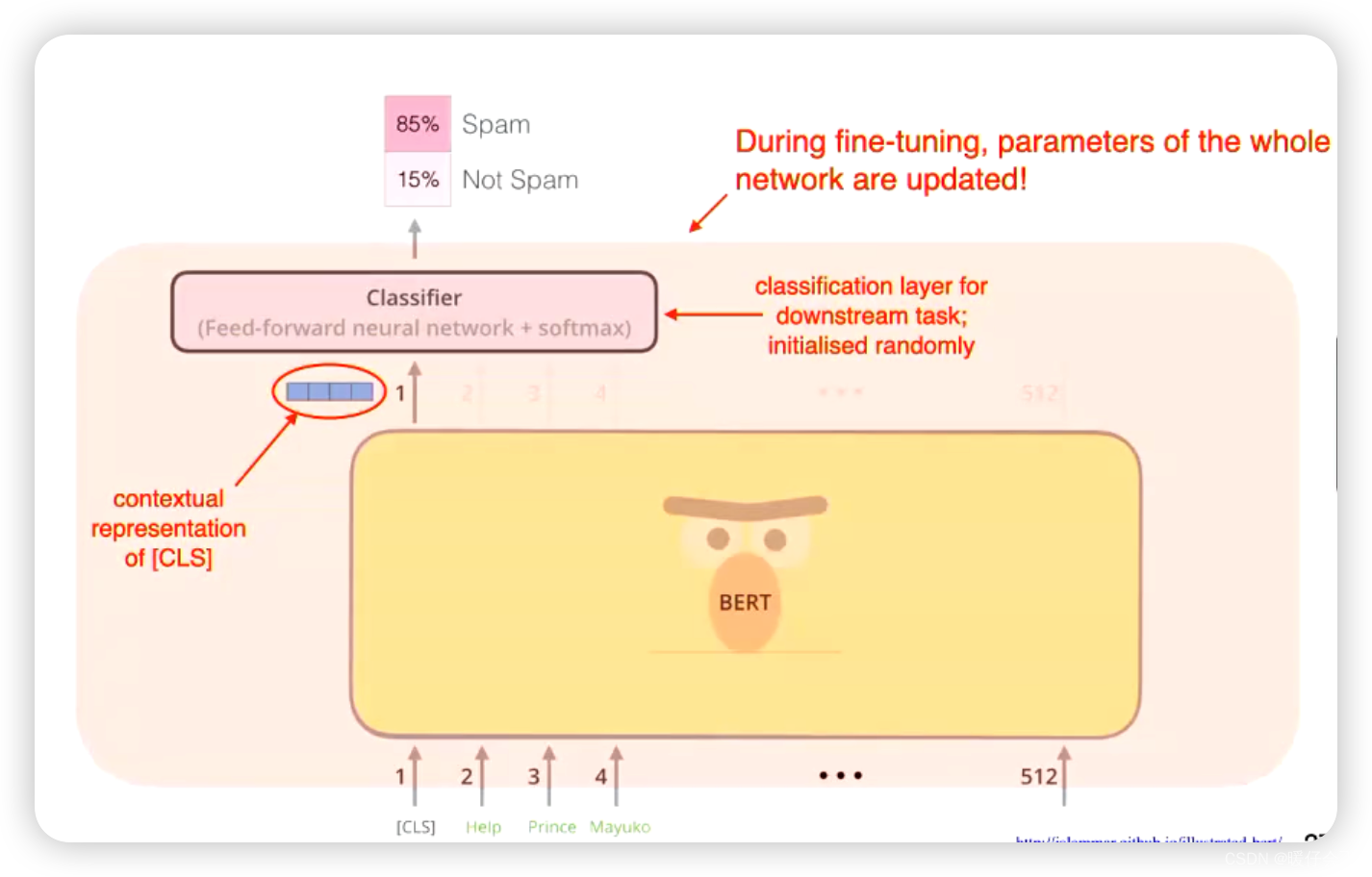
- 只需要使用 [cls] 位置的信息进行分类即可
Transformer
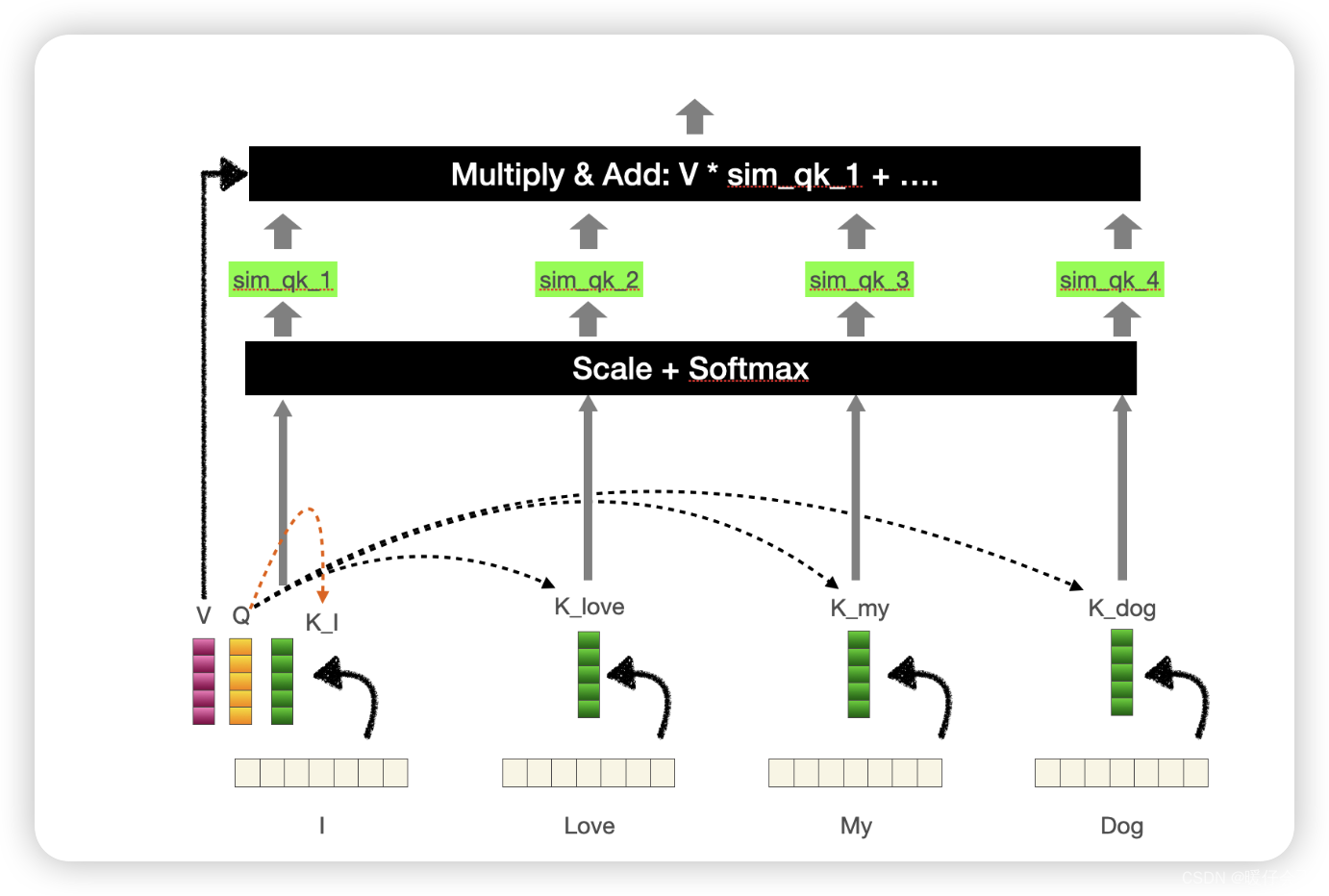
self-attention

- 具体的计算过程请参考我的另一篇博客:Transformer解读之:Transformer 中的 Attention 机制

Multi-head Attention
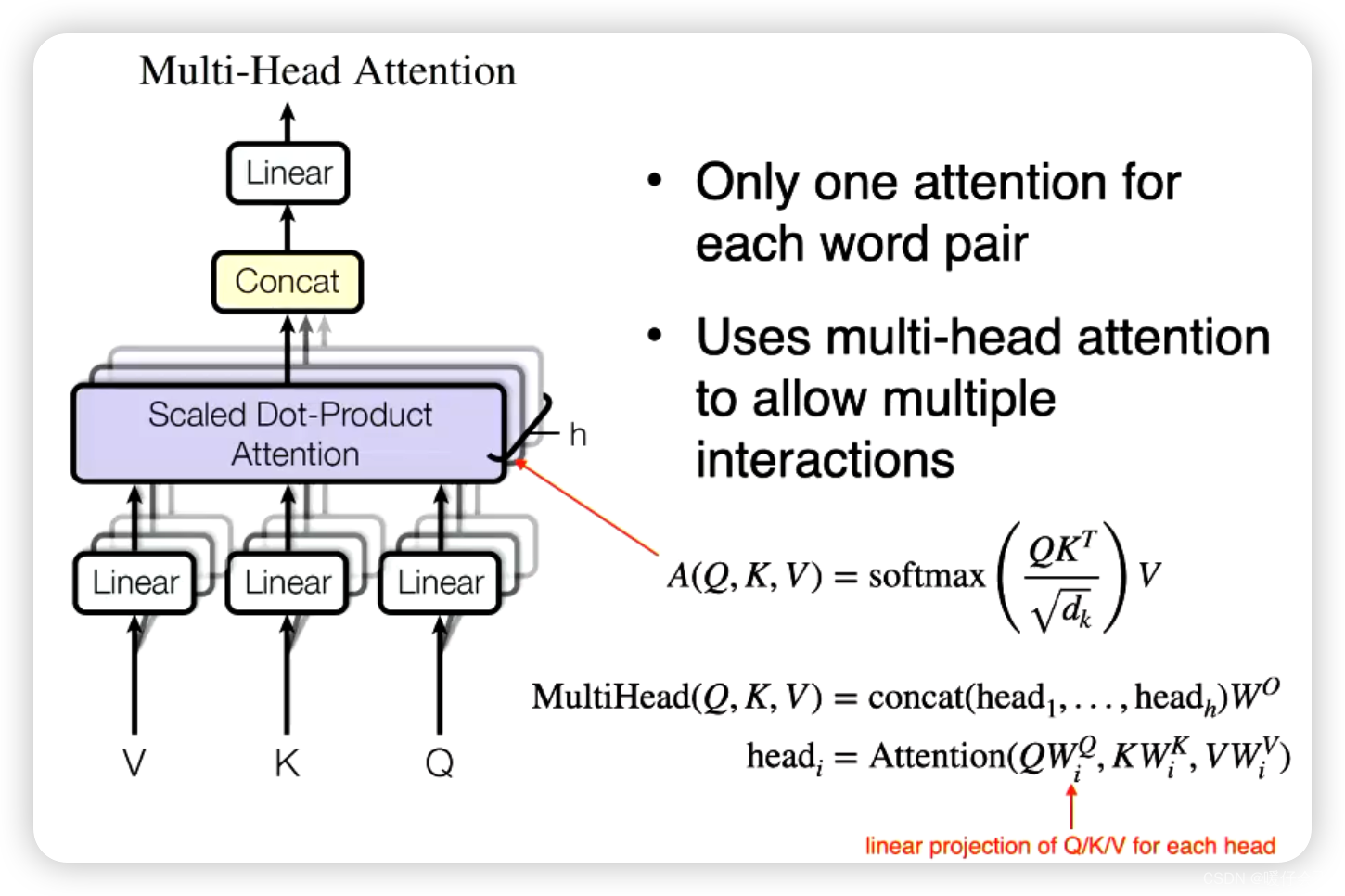
Transformer Block
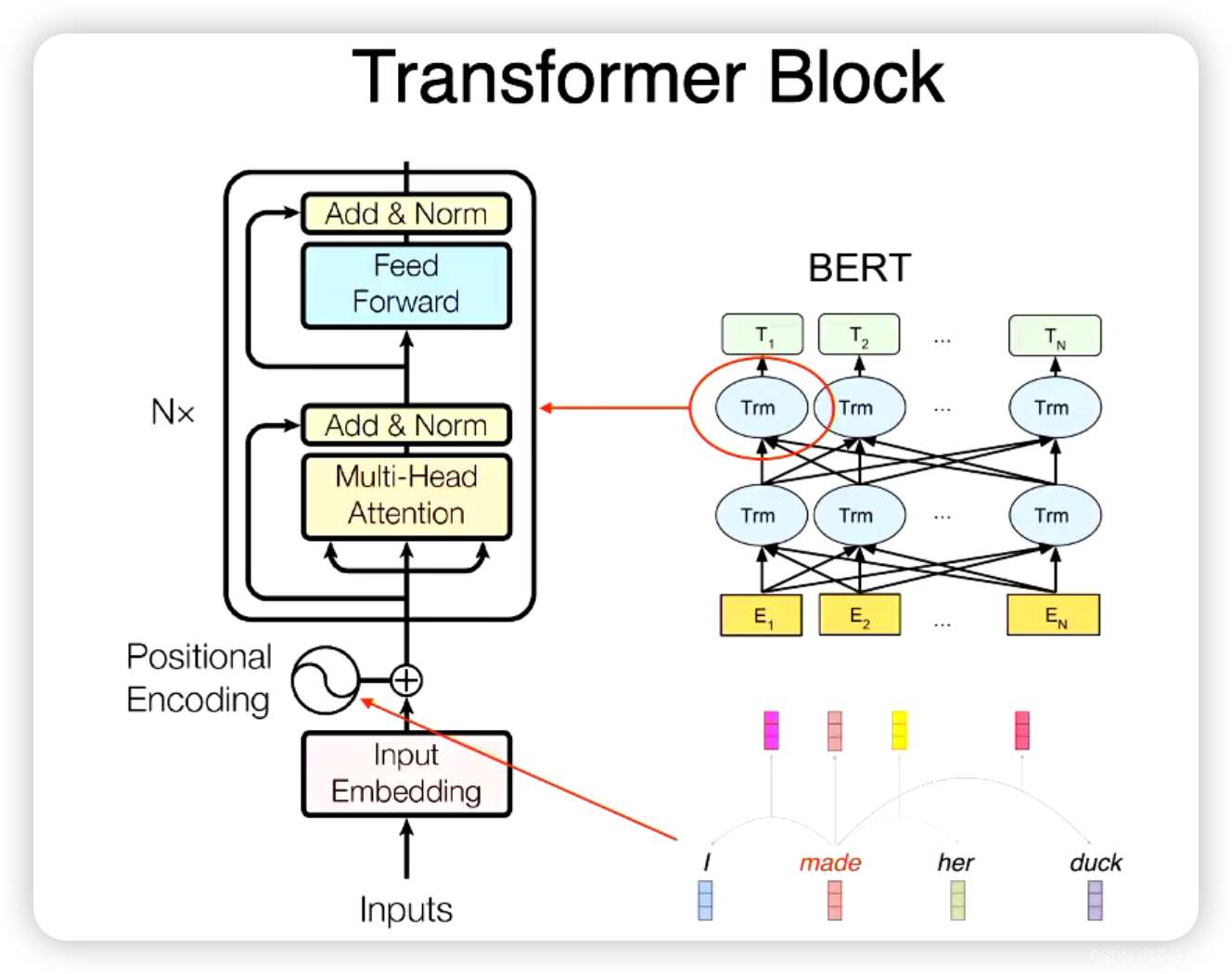
Position encoding
Transformer模型是一种处理序列数据的模型,它完全依赖于自注意力(Self-Attention)机制。这种机制允许模型为序列中的每个元素生成一个上下文相关的表示,这一表示不仅考虑到该元素本身,而且还考虑到其他元素。
然而,自注意力机制本身是不包含顺序信息的,也就是说,它对输入序列的顺序不敏感。这在自然语言处理等需要考虑元素顺序的任务中是一个问题。
为了解决这个问题,Transformer引入了位置编码(Position Encoding)来加入序列中元素的位置信息。这种编码是将每个位置 i i i 编码为一个向量,然后将这个向量加到对应位置的元素的表示上。
位置编码的设计需要满足两个条件:一是,不同位置的编码需要不同;二是,它需要能够表示出位置之间的相对关系。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结