您现在的位置是:首页 >学无止境 >【LeetCode】每日一题 -- 1170. 比较字符串最小字母出现频次 -- Java Version网站首页学无止境
【LeetCode】每日一题 -- 1170. 比较字符串最小字母出现频次 -- Java Version
题目链接:https://leetcode.cn/problems/compare-strings-by-frequency-of-the-smallest-character/
1. 题解(1170. 比较字符串最小字母出现频次)
昨天的每日一题 2699. 修改图中的边权 有点难,研究了一会儿,学习了一下
Dijkstra算法,下午就无心学习,跑去玩了。
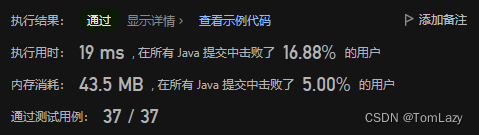
1.1 暴力解法:排序 + 二分
时间复杂度O((n+m)*p),空间复杂度O(n)
【哔哔叨叨】:
很惭愧,从小就不喜欢读题,虽然做出来了,但是没按照题目要求来。该题首先让我们定义一个函数f(s),用来统计一个字符串中(按字典序比较)最小字母的出现频次。这里我直接没管,自己想到哪写到哪了属于是 。
……
【解题思路】:
那么下面我们就来看一下实现的思路:排序+二分;
题目给我们了两个数组queries以及words,然后让我们返回一个数组ans。其中:
queries需要我们与words进行对比查询,把得到的结果存入ans;words是一个词汇表,需要我们提前将其中每个字符串的最小字母的出现频次计算好,并将结果也存入一个数组中保存;……
分析到这题目已经十分明晰,我们具体要做的就是首先遍历一遍words数组,得到其中所有的字符串的最小字母的出现频次,存入一个临时数组tmp,然后对临时数组进行排序,方便我们后面统计words中有多少比queries[i]最小字母的出现频次高的字符串数量;之后,就是遍历words,对比比较,根据二分查找找出tmp数组中符合queries[i]最小字母的出现频次的右边界,此时 右边界+1 一直到tmp数组结尾都是当前字符串频次大的数,所以我们可以直接通过数组长度减去右边界索引+1的方式得到ans[i];
class Solution {
public int[] numSmallerByFrequency(String[] queries, String[] words) {
/* 获取 queries 数组长度 */
int n = queries.length;
/* 定义答案数组 */
int[] ans = new int[n];
/* 定义 tmp 数组,用于临时存储 word 的最小字典序字母的数量 */
int m = words.length;
int[] tmp = new int[m];
/* 统计 words 数组中所有 word 的最小字典序字母的数量 */
for (String word : words)
{
char[] ch = word.toCharArray();
Arrays.sort(ch);
int cnt = word.length() - word.replaceAll(String.valueOf(ch[0]),"").length();
tmp[--m] = cnt;
}
/* 对 tmp 进行排序 */
Arrays.sort(tmp);
m = words.length;
int i = 0;
/* 遍历 queries 数组,计算答案 */
for (String query : queries)
{
char[] ch = query.toCharArray();
Arrays.sort(ch);
int cnt = query.length() - query.replaceAll(String.valueOf(ch[0]),"").length();
int idx = bSearch(tmp, cnt, 0, m-1);
ans[i++] = m - 1 == 0 ? m - idx : m - 1 - idx;
}
return ans;
}
/* 二分找右边界 */
public int bSearch(int[] arr, int x, int l, int r) {
while (l < r)
{
int mid = l + r + 1 >> 1;
if (arr[mid] <= x) l = mid;
else r = mid - 1;
}
return l;
}
}
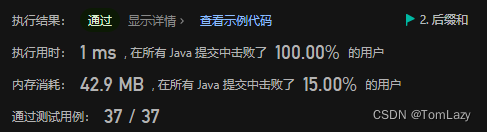
1.2 精简解法:后缀和 ⭐
时间复杂度O((n+m)*p),空间复杂度O(1)
【哔哔叨叨】:
后缀和,顾名思义,就是前缀和反过来,例如,Sn = a[1]+a[2]+……+a[n]; 那么,后缀和就是 Sn = a[n], Sn-1 = a[n-1] + a[n], …… , S1 = a[1]+a[2]+……+a[n]; 在这里后缀和是为了方便我们加快答案的计算。
……
【解题思路】:
- 根据题意,定义一个函数
f(s),用来统计一个字符串中(按字典序比较)最小字母的出现频次;- 根据限定条件
1 <= queries[i].length, words[i].length <= 10,我们可以知道最小字母的出现频次最大不会超过10,因此我们可以直接定义一个数组 count 来记录word中最小字母的出现频次各有多少,然后倒序遍历,实现后缀和(方便计算,可以直接返回);- 遍历
queries,让 res[i] 等于 count[当前字符串最小字母的出现频次+1](因为我们要找到的是比当前字符串最小字母的出现频次大的数量,所以要加1);- 最后返回结果。
class Solution {
public int[] numSmallerByFrequency(String[] queries, String[] words) {
int[] count = new int[12]; // 限定条件
for (String s : words) {
count[f(s)]++;
}
/* 小于 count[i] 的数,也一定小于 count[i+1] */
for (int i = 9; i >= 1; i--) {
count[i] += count[i + 1];
}
/* 遍历 queries, 计算答案 */
int[] res = new int[queries.length];
for (int i = 0; i < queries.length; i++) {
String s = queries[i];
res[i] = count[f(s) + 1];
}
return res;
}
/* 返回一个字符串中最小字母的出现频次 */
public int f(String s) {
int cnt = 0;
char ch = 'z';
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c < ch) {
ch = c;
cnt = 1;
} else if (c == ch) {
cnt++;
}
}
return cnt;
}
}
2. 参考资料






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结