您现在的位置是:首页 >学无止境 >机器学习实战:Python基于LDA线性判别模型进行分类预测(五)网站首页学无止境
机器学习实战:Python基于LDA线性判别模型进行分类预测(五)
文章目录
1 前言
1.1 线性判别模型的介绍
线性判别模型(Linear Discriminant Analysis,LDA)是一种经典的监督学习算法,它旨在通过学习输入特征和它们所属类别之间的线性关系来进行分类任务。线性判别模型通常可以被看作是一种分类器,可以用于二元分类和多元分类问题。
线性判别模型的主要思想是将输入特征空间中的样本投影到一条直线或者一个超平面上,从而实现对样本的分类。这个超平面的选择是通过最小化类内距离和最大化类间距离来完成的。类内距离指的是同一类别样本之间的距离,类间距离则指不同类别样本之间的距离。通过最小化类内距离和最大化类间距离,线性判别模型能够更好地区分不同类别的样本。
优点:
-
线性判别模型是一种经典的监督学习算法,具有较高的可解释性和可理解性,能够提供直观的结果。
-
线性判别模型具有较快的训练速度和较低的存储成本,适用于处理大型数据集。
-
线性判别模型能够在高维数据中很好地工作,并且在特征选择方面具有很好的性能。
缺点:
-
线性判别模型是一种线性模型,对于非线性分类问题的表现可能较差。
-
线性判别模型对于噪声数据和异常值比较敏感,容易造成误分类。
-
线性判别模型的分类效果受特征之间相关性的影响,如果存在高度相关的特征,分类效果可能较差。
1.2 线性判别模型的应用
线性判别模型广泛应用于数据分类、降维和特征提取等领域,在实际应用中有很多场景,例如:
-
信用评分:根据用户的个人信息和历史数据,对其信用评分进行分类,以决定是否批准贷款。
-
医学诊断:根据患者的生理指标和症状,将其分为健康和患病两类,以进行诊断和治疗。
-
人脸识别:根据人脸图像的特征向量,将其分为不同的人脸类别,以实现人脸识别和身份验证。
-
情感分析:根据文本内容中的关键词和情感指标,将其分为正面、负面和中性等不同的情感类别。
-
图像分类:根据图像的特征向量,将其分为不同的图像类别,以进行图像识别和分类等。
在生信领域还是常用于基因表达数据分析、蛋白结构预测、biomarker鉴定和药物设计,LDA可以用于分析分子结构和描述化学性质,从而优化药物设计和发现。
2 demo数据演示
2.1 导入函数
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.datasets import make_classification
2.2 训练模型
# 制作四个类别的数据,每个类别100个样本
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0,
n_classes=4, n_informative=2, n_clusters_per_class=1,
class_sep=3, random_state=10)
# 可视化分布
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20,auto_add_to_figure=False)
fig.add_axes(ax)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='o', c=y)
plt.show()
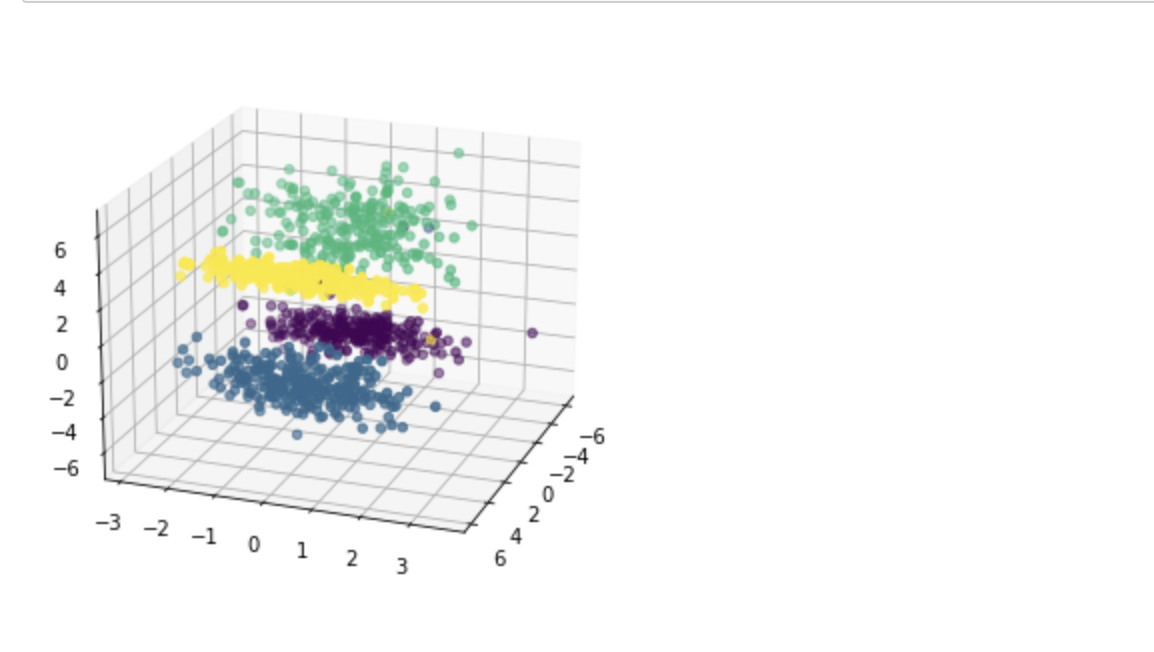
建模
# 建立 LDA 模型
lda = LinearDiscriminantAnalysis()
# 训练模型
lda.fit(X, y)
# 查看 LDA 模型的参数
lda.get_params()

2.3 预测模型
# 进行模型预测
X_new = lda.transform(X)
# 可视化预测数据
plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y)
plt.show()
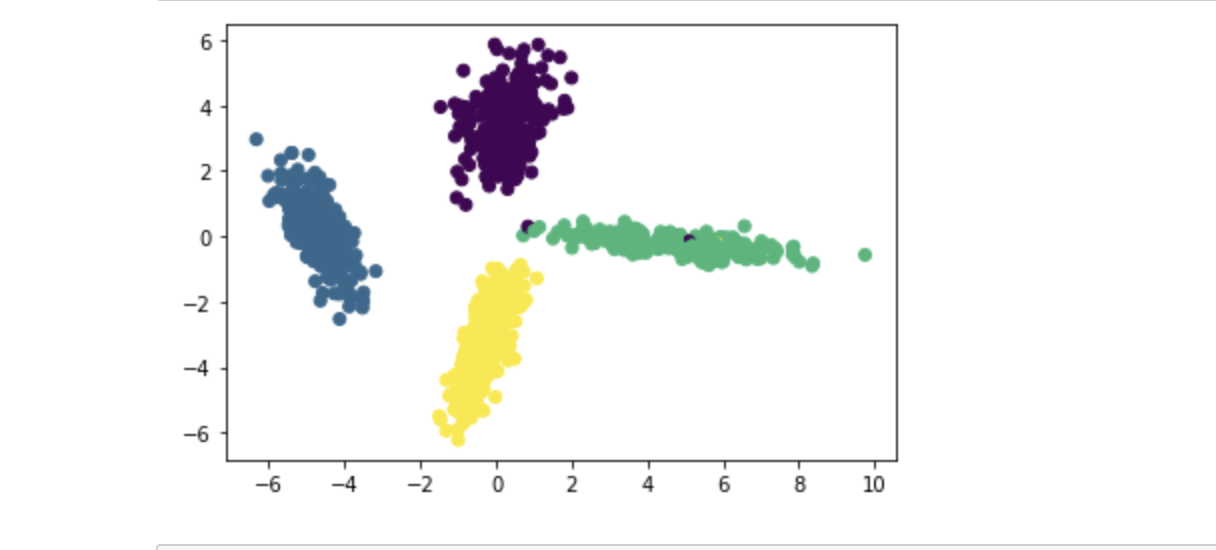
用新数据测试
a = np.array([[-1, 0.1, 0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -100, -91]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -0.1, -0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[0.1, 90.1, 9.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))

3 LDA手写数字数据演示
3.1 导入函数
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib
3.2 导入数据
# 导入MNIST数据集
mnist = load_digits()
# 查看数据集信息
print('The Mnist dataeset:
',mnist)
# 分割数据为训练集和测试集,7/3分
x, test_x, y, test_y = train_test_split(mnist.data, mnist.target, test_size=0.3, random_state=2)
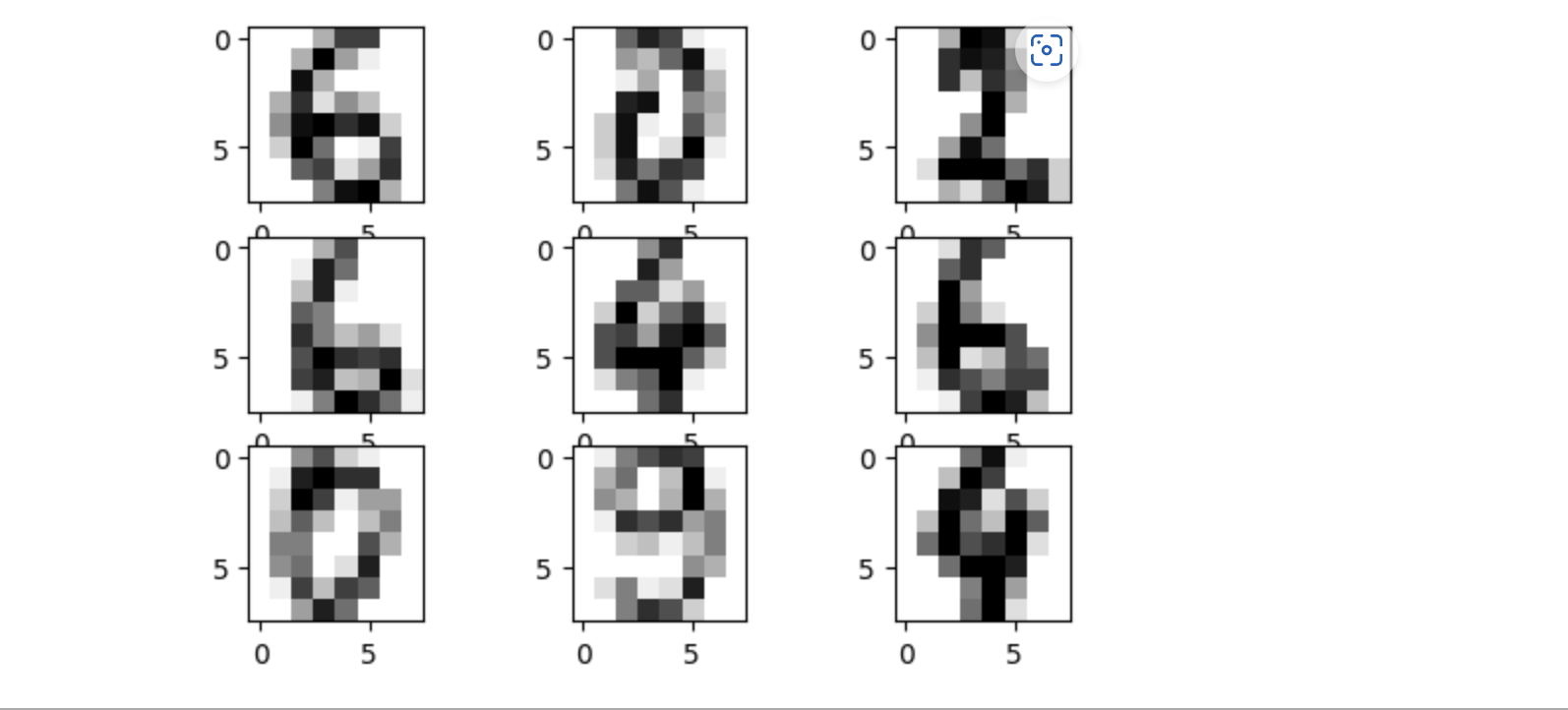
3.3 输出图像
images = range(0,9)
plt.figure(dpi=100)
for i in images:
plt.subplot(330 + 1 + i)
plt.imshow(x[i].reshape(8, 8), cmap = matplotlib.cm.binary,interpolation="nearest")
# show the plot
plt.show()
3.4 建立模型
# 建立 LDA 模型
m_lda = LinearDiscriminantAnalysis()
# 训练模型
m_lda.fit(x, y)
# 进行模型预测
x_new = m_lda.transform(x)
# 可视化预测数据
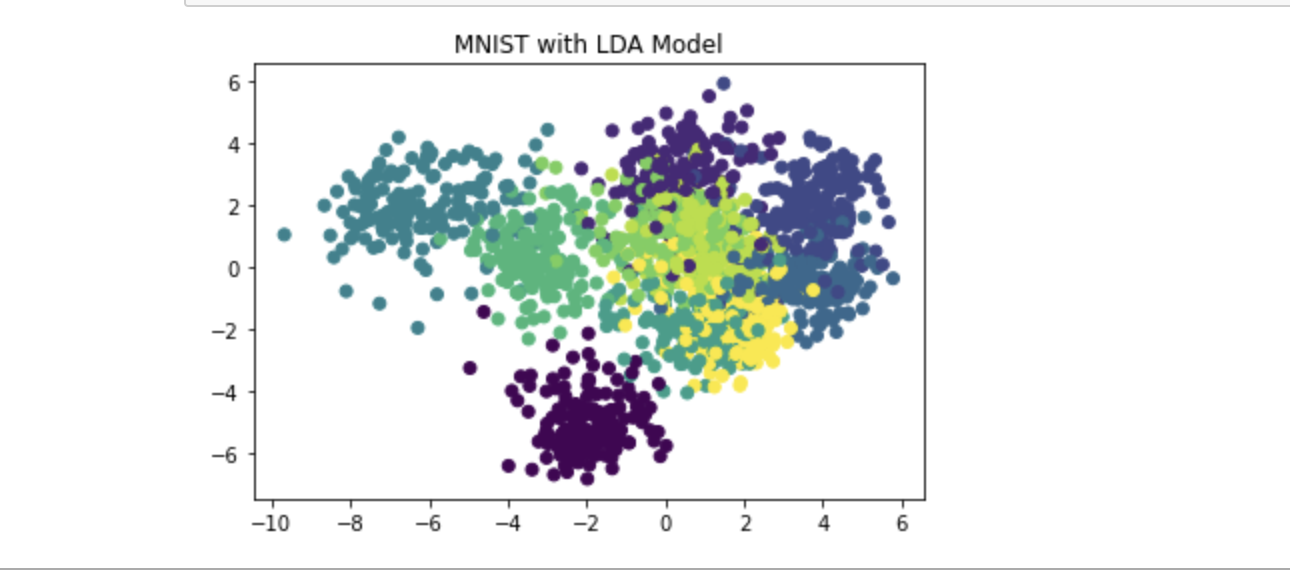
plt.scatter(x_new[:, 0], x_new[:, 1], marker='o', c=y)
plt.title('MNIST with LDA Model')
plt.show()
3.5 预测模型
y_test_pred = m_lda.predict(test_x)
print("测试集的真实标签:
", test_y)
print("测试集的预测标签:
", y_test_pred)

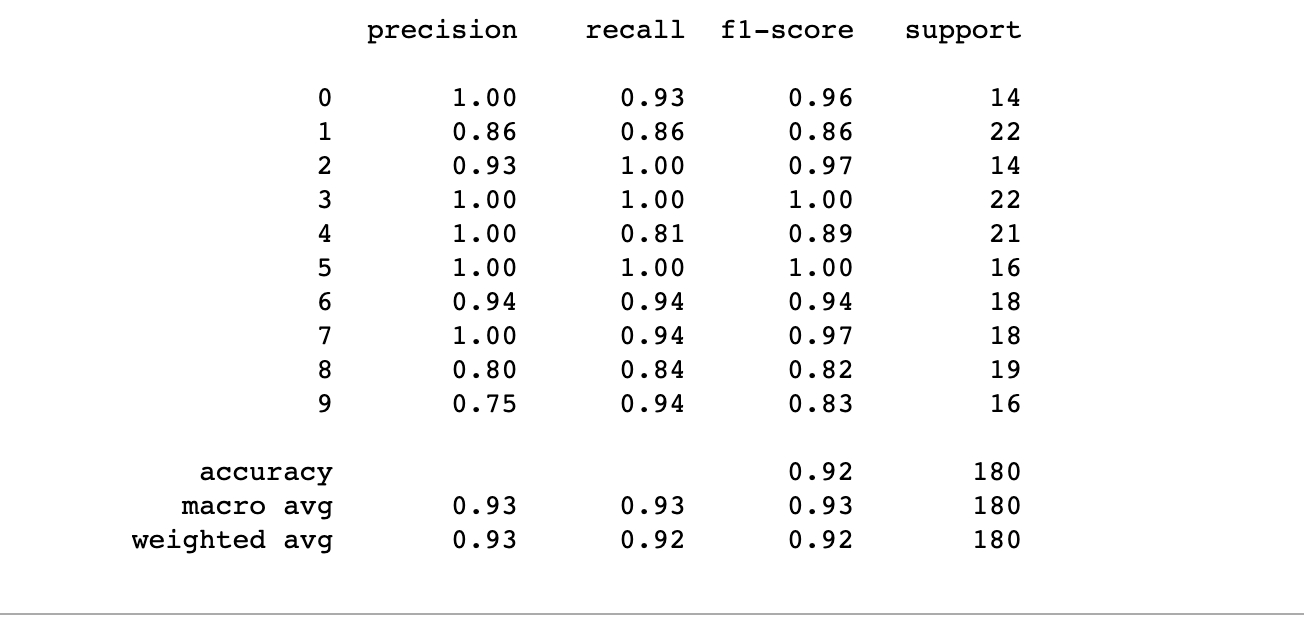
# 统计结果指标
print(classification_report(test_y, y_test_pred))
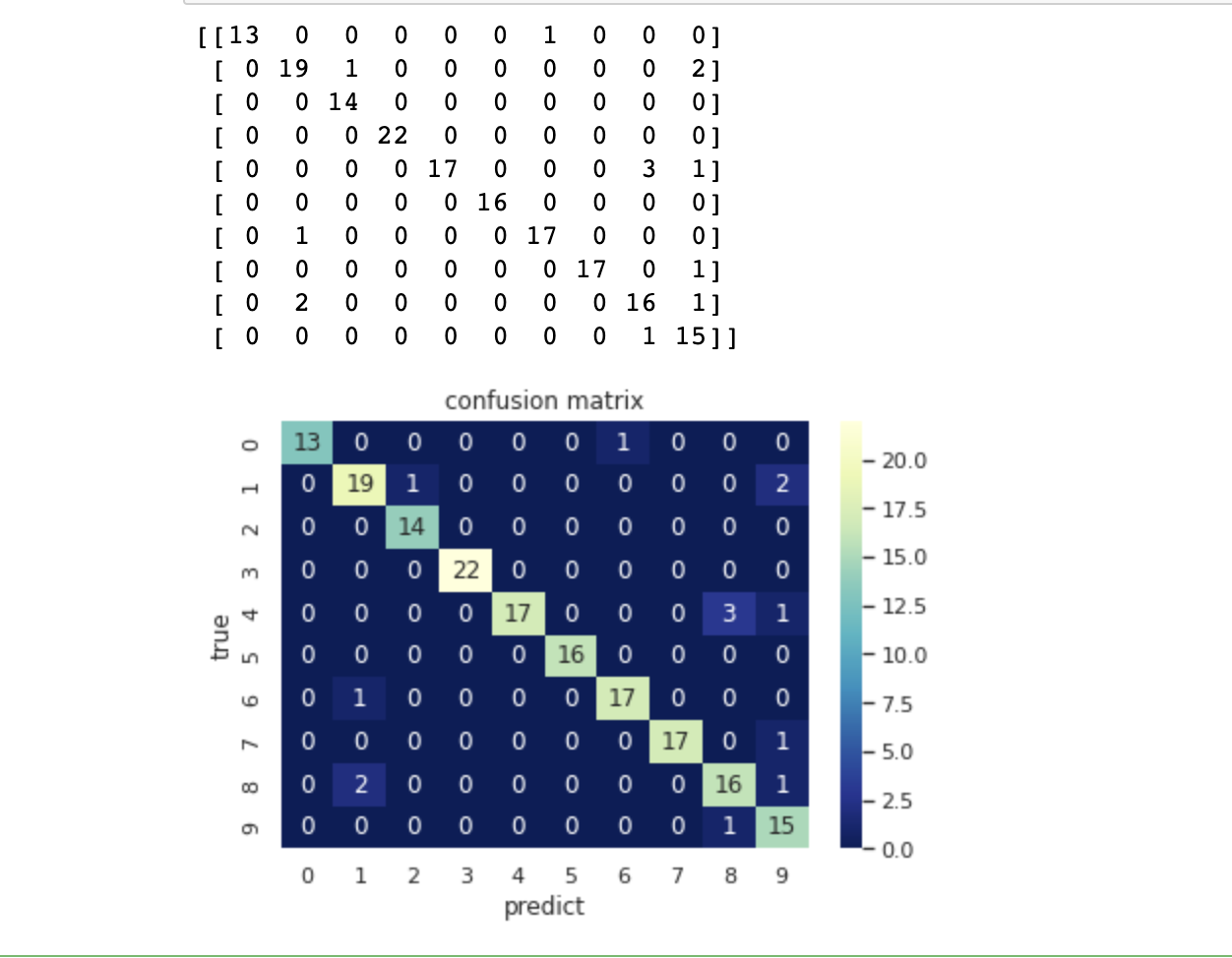
# 计算混淆矩阵
C2 = confusion_matrix(test_y, y_test_pred)
# 打混淆矩阵
print(C2)
# 将混淆矩阵以热力图的防线显示
sns.set()
f, ax = plt.subplots()
# 画热力图
sns.heatmap(C2, cmap="YlGnBu_r", annot=True, ax=ax)
# 标题
ax.set_title('confusion matrix')
# x轴为预测类别
ax.set_xlabel('predict')
# y轴实际类别
ax.set_ylabel('true')
plt.show()
4 讨论
LDA模型还是比较简明扼要的,主要是针对于线性可分数据,判别目的就是使同类别的距离相近,使不同类别的距离隔远。对于非线性可分数据需要特别留意实际情况。
LDA是一种监督学习的降维技术,且每个样本都是区分类别输出的;区别于PCA,PCA是不考虑样本类别的无监督降维技术,但是目的是一样的,都可以理解为将同类别的数据。相比于后者,LDA我认为最大的优势就是基于监督可以参考类别的先验经验,即可以不断“叠加”;然鹅很硬性的一个缺点就是不适合对非高斯分布样本进行降维,这个问题PCA也存在。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结