您现在的位置是:首页 >学无止境 >Hadoop Distributed System (HDFS) 写入和读取流程网站首页学无止境
Hadoop Distributed System (HDFS) 写入和读取流程
一、HDFS
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
目前HDFS支持的使用接口除了Java的还有,Thrift、C、FUSE、WebDAV、HTTP等。HDFS是以block-sized chunk组织其文件内容的,默认的block大小为64MB,对于不足64MB的文件,其会占用一个block,但实际上不用占用实际硬盘上的 64MB,这可以说是HDFS是在文件系统之上架设的一个中间层。之所以将默认的block大小设置为64MB这么大,是因为block-sized对于 文件定位很有帮助,同时大文件更使传输的时间远大于文件寻找的时间,这样可以最大化地减少文件定位的时间在整个文件获取总时间中的比例 。
二、HDFS的体系结构
构成HDFS主要是Namenode(master)和一系列的Datanode(workers)。Namenode是管理HDFS的目录树和相 关的文件元数据,这些信息是以"namespace image"和"edit log"两个文件形式存放在本地磁盘,但是这些文件是在HDFS每次重启的时候重新构造出来的。Datanode则是存取文件实际内容的节 点,Datanodes会定时地将block的列表汇报给Namenode。
由于Namenode是元数据存放的节点,如果Namenode挂了那么HDFS就没法正常运行,因此一般使用将元数据持久存储在本地或远程的机器 上,或者使用secondary namenode来定期同步Namenode的元数据信息,secondary namenode有点类似于MySQL的Master/Salves中的Slave,"edit log"就类似"bin log"。如果Namenode出现了故障,一般会将原Namenode中持久化的元数据拷贝到secondary namenode中,使secondary namenode作为新的Namenode运行起来。
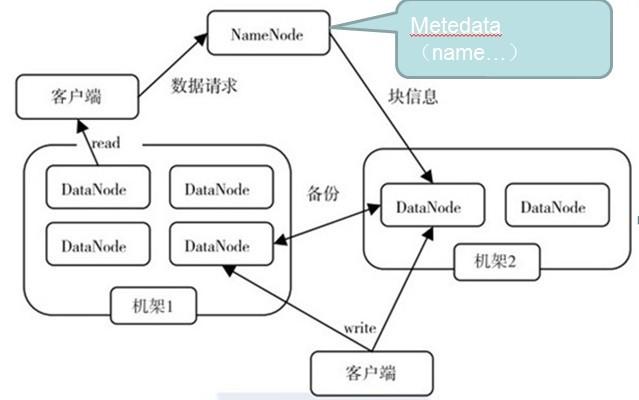
三、读写流程
GFS论文提到的文件读取简单流程:
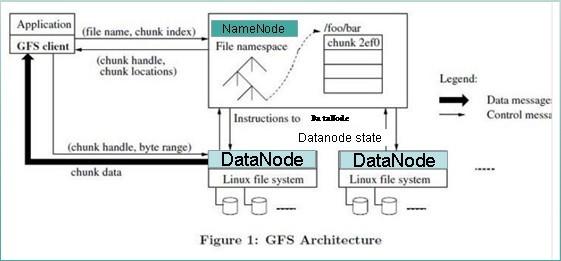
详细流程:

文件读取的过程如下:
-
使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
-
Namenode会视情况返回文件的部分或者全部block列表,对于每个block,Namenode都会返回有该block拷贝的DataNode地址;
-
客户端开发库Client会选取离客户端最接近的DataNode来读取block;如果客户端本身就是DataNode,那么将从本地直接获取数据.
-
读取完当前block的数据后,关闭与当前的DataNode连接,并为读取下一个block寻找最佳的DataNode;
-
当读完列表的block后,且文件读取还没有结束,客户端开发库会继续向Namenode获取下一批的block列表。
-
读取完一个block都会进行checksum验证,如果读取datanode时出现错误,客户端会通知Namenode,然后再从下一个拥有该block拷贝的datanode继续读。
GFS论文提到的写入文件简单流程:
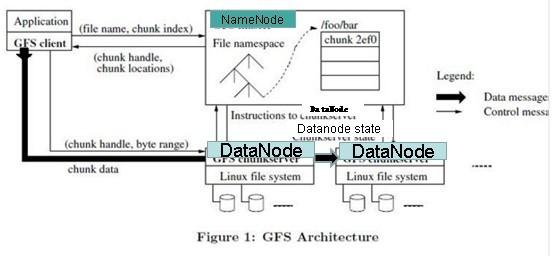
详细流程:
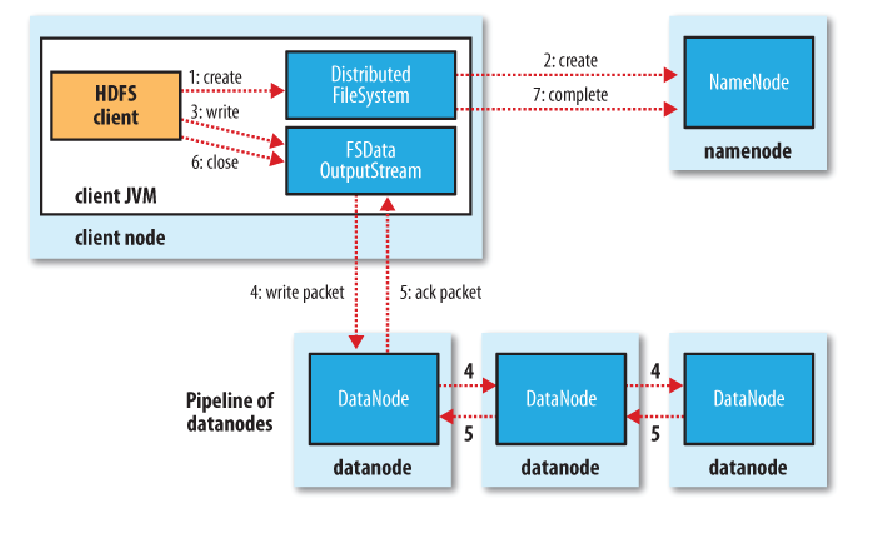
写入文件的过程比读取较为复杂:
-
使用HDFS提供的客户端开发库Client,向远程的Namenode发起RPC请求;
-
Namenode会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会为文件创建一个记录,否则会让客户端抛出异常;
-
当 客户端开始写入文件的时候,开发库会将文件切分成多个packets,并在内部以数据队列"data queue"的形式管理这些packets,并向Namenode申请新的blocks,获取用来存储replicas的合适的datanodes列表, 列表的大小根据在Namenode中对replication的设置而定。
-
开始以pipeline(管道)的形式将packet写入所 有的replicas中。开发库把packet以流的方式写入第一个datanode,该datanode把该packet存储之后,再将其传递给在此 pipeline中的下一个datanode,直到最后一个datanode,这种写数据的方式呈流水线的形式。
-
最后一个datanode成功存储之后会返回一个ack packet,在pipeline里传递至客户端,在客户端的开发库内部维护着"ack queue",成功收到datanode返回的ack packet后会从"ack queue"移除相应的packet。
-
如 果传输过程中,有某个datanode出现了故障,那么当前的pipeline会被关闭,出现故障的datanode会从当前的pipeline中移除, 剩余的block会继续剩下的datanode中继续以pipeline的形式传输,同时Namenode会分配一个新的datanode,保持 replicas设定的数量。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结