您现在的位置是:首页 >技术交流 >Hbase网站首页技术交流
Hbase
Hbase
思考环节:

1.什么是hbase
1.1简介
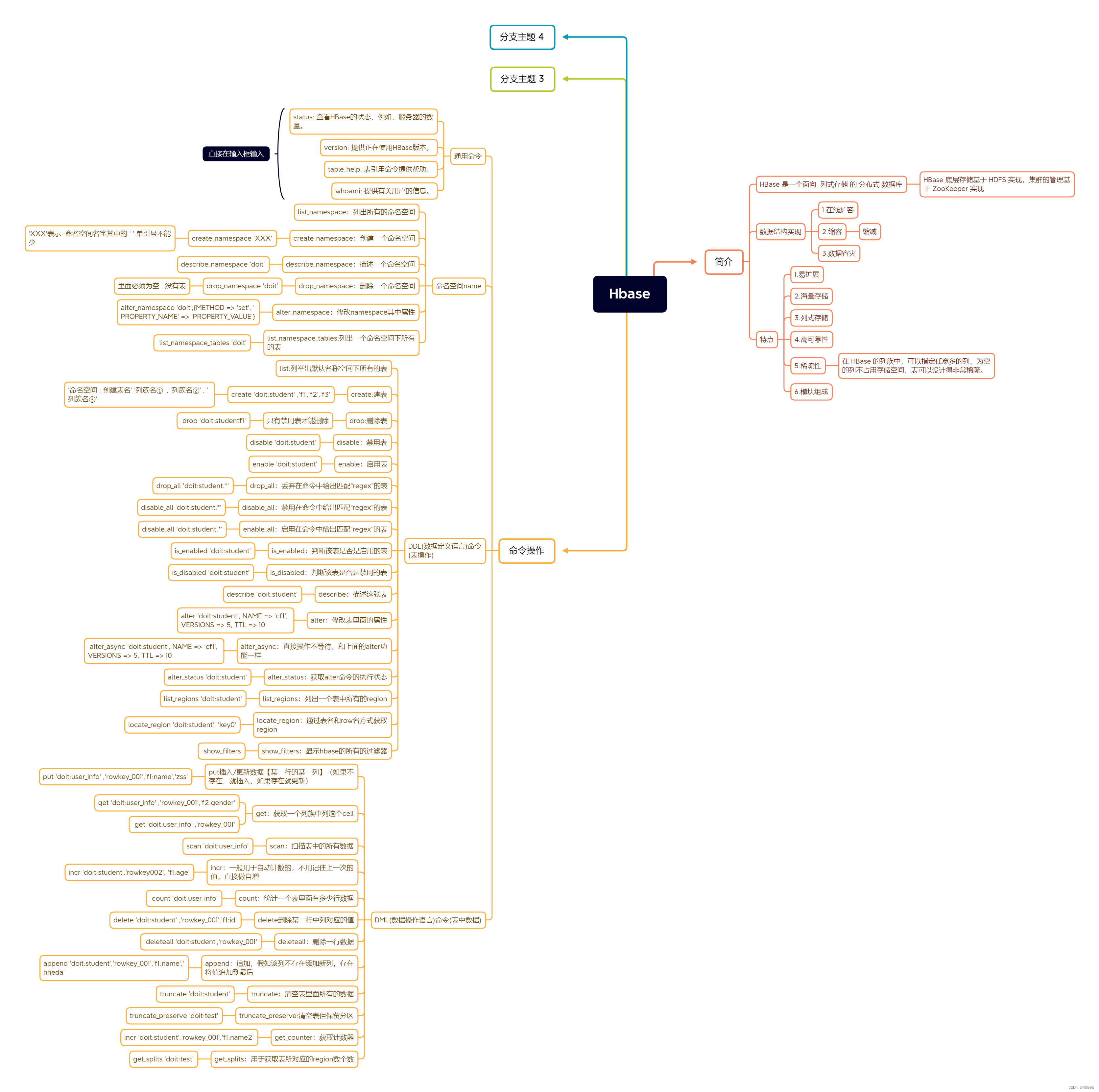
HBase 是一个面向列式存储的分布式数据库,其设计思想来源于 Google 的 BigTable 论文。
HBase 底层存储基于 HDFS 实现,集群的管理基于 ZooKeeper 实现。
HBase 良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中 Key-Value 数据结构存储最常用的数据库方案
1.2.特点
- 易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于运算能力(RegionServer) 的扩展,通过增加 RegionSever 节点的数量,提升 Hbase 上层的处理能力;另一个是基于存储能力的扩展(HDFS),通过增加 DataNode 节点数量对存储层的进行扩容,提升 HBase 的数据存储能力。
- 海量存储
HBase 作为一个开源的分布式 Key-Value 数据库,其主要作用是面向 PB 级别数据的实时入库和快速随机访问。这主要源于上述易扩展的特点,使得 HBase 通过扩展来存储海量的数据。
- 列式存储
Hbase 是根据列族来存储数据的。列族下面可以有非常多的列。列式存储的最大好处就是,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段时,能大大减少读取的数据量。
- 高可靠性
WAL 机制保证了数据写入时不会因集群异常而导致写入数据丢失,Replication 机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且 Hbase 底层使用 HDFS,HDFS 本身也有备份。
- 稀疏性
在 HBase 的列族中,可以指定任意多的列,为空的列不占用存储空间,表可以设计得非常稀疏。
- 模块组成
HBase 可以将数据存储在本地文件系统,也可以存储在 HDFS 文件系统。在生产环境中,HBase 一般运行在HDFS 上,以 HDFS 作为基础的存储设施。HBase 通过 HBase Client 提供的 Java API 来访问 HBase 数据库,以完成数据的写入和读取。HBase 集群主由HMaster、Region Server 和 ZooKeeper 组成。
1.3.使用场景
HBase擅长于存储结构简单的海量数据但索引能力有限,而Oracle,mysql等传统关系型数据库(RDBMS)能够提供丰富的查询能力,但却疲于应对TB级别的海量数据存储,HBase对传统的RDBMS并不是取代关系,而是一种补充。
适合使用 对于关系型数据库的一种补充,而不是替代
- 数据库中的很多列都包含了很多空字段(稀疏数据),在 HBase 中的空字段不会像在关系型数据库中占用空间。
- 需要很高的吞吐量,瞬间写入量很大。
- 数据有很多版本需要维护,HBase 利用时间戳来区分不同版本的数据。
- 具有高可扩展性,能动态地扩展整个存储系统。
比如:用户画像(给用户打标签),搜索引擎应用,存储用户交互数据等
不适合使用
- 需要数据分析,比如报表(rowkey) 对sql支持不好
- 单表数据不超过千万(数据量小)
1.4hbase的架构
HBase 系统遵循 Master/Salve 架构,由三种不同类型的组件组成:
client
- 提供了访问hbase的接口
- 提供cache缓存提高访问hbase的效率 , 比如region的信息
Zookeeper
- 保证任何时候,集群中只有一个 Master;
- 存储所有 Region 的寻址入口;
- 实时监控 Region Server 的状态,将 Region Server 的上线和下线信息实时通知给 Master;
- 存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family 等信息。
Master/master
- 为 Region Server 分配 Region;
- 负责 Region Server 的负载均衡 ;
- 发现失效的 Region Server 并重新分配其上的 Region;
- GFS 上的垃圾文件回收;
- 处理 Schema 的更新请求
Region Server
- Region Server 负责维护 Master 分配给它的 Region ,并处理发送到 Region 上的 IO 请求;
- Region Server 负责切分在运行过程中变得过大的 Region

2.安装
| 因为hbase需要依赖zookeeper和hdfs,所以在安装hbase集群之前需要确保zookeeper和hdfs的环境是ok的哦!!! |
2.1时间同步
由于HBase默认的容忍间隔是30s,超过这个阈值,就会报“Master rejected startup because clock is out of sync”异常,所以三台机器的时间 间隔不能超过30s
解决方案:
- 手动的设置时间 date -s "2023-05-07 00:00:00"
- 修改属性
| XML |
- 向时间服务器自动同步时间
| 如何时间同步?? |
2.2下载上传解压
2.3hbase配置
- 在conf目录下找到hbase-env.sh
| Shell |
- 在 conf目录下找到hbase-site.xml
| XML |
- regionservers 配置 启动集群中的Regionserver机器
| Shell |
2.4集群分发
| Shell |
2.5启动
单节点启动:
| Shell |
| 提示:如果regionserver无法启动,请先检查下集群之间的节点时间是否同步 |
一键启动:
| Shell |
2.6页面访问
验证启动是否成功
- jps查看
| Shell |
- 通过"linux01:16010"的方式来访问HBase管理页面,进得去代表启动成功

help命令及其运用
Hbase 的一些命令
COMMAND GROUPS:
Group name: general 常规
Commands: 命令,指令
processlist, 进程列表,正在运行中的服务列表
status, 状态
table_help, 表帮助
version, 版本
whoami 显示本用户信息Group name: ddl 数据定义语言
Commands:
alter, alter_async, alter_status, clone_table_schema, create,
describe, disable, disable_all, drop, drop_all, enable, enable_all,
exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filtersGroup name: namespace 命名空间
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tablesGroup name: dml 数据操作语言
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserveGroup name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled,
catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run,
cleaner_chore_switch, clear_block_cache, clear_compaction_queues, clear_deadservers,
close_region, compact, compact_rs, compaction_state, compaction_switch, decommission_regionservers,
flush, hbck_chore_run, is_in_maintenance_mode, list_deadservers, list_decommissioned_regionservers,
major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch,
recommission_regionserver, regioninfo, rit, split, splitormerge_enabled, splitormerge_switch,
stop_master, stop_regionserver, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_exclude_namespaces, append_peer_exclude_tableCFs,
append_peer_namespaces, append_peer_tableCFs, disable_peer, disable_table_replication,
enable_peer, enable_table_replication, get_peer_config, list_peer_configs, list_peers,
list_replicated_tables, remove_peer, remove_peer_exclude_namespaces, remove_peer_exclude_tableCFs,
remove_peer_namespaces, remove_peer_tableCFs, set_peer_bandwidth, set_peer_exclude_namespaces,
set_peer_exclude_tableCFs, set_peer_namespaces, set_peer_replicate_all, set_peer_serial,
set_peer_tableCFs, show_peer_tableCFs, update_peer_configGroup name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, delete_table_snapshots,
list_snapshots, list_table_snapshots, restore_snapshot, snapshotGroup name: configuration
Commands: update_all_config, update_configGroup name: quotas
Commands: disable_exceed_throttle_quota, disable_rpc_throttle, enable_exceed_throttle_quota,
enable_rpc_throttle, list_quota_snapshots, list_quota_table_sizes, list_quotas, list_snapshot_sizes, set_quotaGroup name: security
Commands: grant, list_security_capabilities, revoke, user_permissionGroup name: procedures
Commands: list_locks, list_proceduresGroup name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibilityGroup name: rsgroup
Commands: add_rsgroup, balance_rsgroup, get_rsgroup, get_server_rsgroup, get_table_rsgroup,
list_rsgroups, move_namespaces_rsgroup, move_servers_namespaces_rsgroup, move_servers_rsgroup,
move_servers_tables_rsgroup, move_tables_rsgroup, remove_rsgroup, remove_servers_rsgroup, rename_rsgroup






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结