您现在的位置是:首页 >技术杂谈 >Go语言并发微服务分布式高可用网站首页技术杂谈
Go语言并发微服务分布式高可用
Go语言并发微服务分布式高可用
Go语言基础
环境安装
命令行输入go,当前操作系统Os环境中依赖于PATH指定的日录们去找命令(可执行文件)windows会优先搜索当前日录,当前日录没有才依赖PATH中指定的日录

环境变量: 操作系统运行环境中提前定义好的变量PATH: 如果你在命令行中输入了一段字符,shell要解析它,被解释为可执行的文件(命令)命令:某些程序员写好的可执行文件
GO运行环境
GOROOT: GO的安装路径 c:/go/1.20.4
GOPATH:
当前用户家目录/qo ~/go SHOME/go,
目前第三方包安装目录
第三方包如果instal1就要编译可执行文件,就放在bin日录中
pkg目录: 缓存 第三方包文件
bin目录: 第三方包通过go install命令下载并编译好的可执行文件的存放处
dlv 调试qo代码
gopls go的自动完成、编辑支持等
go instal1 命令:下载第三方包到SGOPATH/go/下面的缓存包文件们到该目录,编译好可执行文件放到SGOPATH/go/biigo get命令:下载第三方包到SGOPATH/go/下面的缓存包文件们到该目录,以后编程用这些包如何知道该qo install还是 go get,官方文档会告诉你PATH:增加了~/go/bin目录 等价于 GOPATH + bin
必须,go在这里必须,bin? binary 二进制,为了编译好可执行文件放在这里SGOPATH/go/binLinux环境变量 冒号间隔,windows用分号
SGOROOT/bin
GOPROXY: https://mirrors.aliyun.com/goproxy/
手动安装
解川;tar xf xxx.tar.qz -C /usr/local/配置以上4个环境变量
测试> ao version
开发环境
收费Goland
免费 VSCode
Js ES TS第一工具插件
outline map 查阅代码postfix.xxx! 自动补全常用代码Go语言开发命令行菜单打开 view/Termina1开启命令行ctrl + j第一个程序pkgm如何调试代码
l $ go run main.go
2F5
go mod init xxxxx立生一个go.mod自动保存当前文件开始编译调试
install-v github.com/go-delve/delve/cmd/dlv@latestgOaoinstall-v golang.org/x/tools/gopls@latest-v honnef.co/go/tools/cmd/staticcheck@latest 代码检查00install
go命令
go instal1 命令:下载第三方包到GOPATH/go/下面的缓存包文件们到该目录,编译好可执行文件放到SGOPATH/go/bingo get命令:下载第三方包到SGOPATH/go/下南的缓存包文件们到该目录,以后编程用这些包。如果开启了go modales,包依赖记录在go.mod中
go get -u 包
go mod命令: 开启go mudules,启用模块化(包管理),标志go.mod文件
go mod init 名字
go mod tidy 扫描当前项目,从go.mod文件中把不依赖的第三方包移除,也可以把依赖的第三方包加进来
go version 打印版本
go env 打印go环境的环境变量
gobuild 编译
go run 直接进行go build
冯诺依曼体系五大部件
CPU:运算器一般你给的一个任务,CPU要花几个滴管来完成假设3个滴答完成一次计算,请问频率高、低哪个省时间?主频越高越好,但是频率有天花板,所以上多核控制器存储器Memory: 内存,掉电丢失,速度快输入设备Input:数据输入输出设备output:
主板: 类比为骨架和神经系统芯片组:显卡: 数宇信号输入给显卡,显卡输出到显示器总线Bus: 数据总线、控制总线内存
运行内存:f电丢失的芯片内部存储内存: 相当于掉电不丢失的便盘
输入输出设备不跟CPU直接打交道,CPU必须直接和内存进行数据交换。CPU当中没有地方放大量数据CPu
寄存器,寄存器是为了计算所需数据缓存cache
时钟振荡器按照一个频率跑,触发数字电路工作,滴答声越快频率越高,CPU就越快所有的数字设备都要利用产生的脉冲信号工作
CPU运行频频率是最高的 3.xGhz
内存次之 DDR 双边沿触发 运行速度远低于 CPU TB。Redis外设: Io设备,慢设备,慢的要死 PB,大量的数据放在外设存储

UserName大驼峰,首字母大写大驼峰
userName小驼峰
user name snake 它形命
100 a指代100,a就是指代100的一个名称,标识符a=100 是数字,常量,不可变的值,宁面常量100 + 1 = 101,100还是那个100,1还是那个1, 101就是101
100 +2
100 +3
0
8X2
384
a = 200 说明 a的指代可以变化,a变心了,可以变化指代值的标识符,称为 恋量标识符如果说a的指代一旦关联,不可变,a这个标识符指代的值不能改变了,称为 常量标识符
1.25
true
false iota
nil
"ab"0= "abc"
变量名var
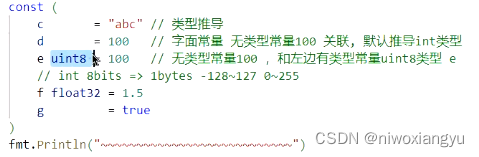

总结: iota是在成批定义和序列有关的常量定义
其他语言中const a = [1, 2]a = [1] // 不可以
go语言中,常量不可以用数组
"abc”赋值语句,名称是a,被赋值,a是一个指代,指向某个值
=
1
100
如果可以,再次可以赋值,a称为变量,a的指代可以发生变化
如果不以
a有类型要求,不可以改变类型,同类型可以再次赋值,a是变景 (a=100不可以,a="aaa"可以)a就是不可以再被赋值,a和第一个赋给它的值之间的联系不可改变,a称为常量标识符
标识符的指向的值一旦建立,不可改变,要求定义是必须建立关联常量:变量:标识符的指向的值建立后,可以改变1类型也可以变,往往动态语言JS、Python,举例 a = 100,a="abc",a=[1,2,3]2同类型可以变
const a ="abc"赋值语句,右边是无类型常量,它的缺省类型是string,左边a没有指定类型,a会进行类型推导,会依赖右边的类型,所以,a被推测为string类型类型推导可以用在常量、变量定义,包括批量定义时
var a int,b strinq // 不支持,批量定义 var ()var a int,b int // 不可以var a,b int // 可以,如果要写在一行,必须同类型,只需要在最后指定类型就行。该例子用零值var c,d int = 100,200 // 如果要写在一行,必须同类型,只需要在最后指定类型就行。可以赋值,但要全部对应给出值
变量的短格式b // 不是短格式,什么都不是,不是赋值语句,也没有const、vara := 100 // 赋值语句,短格式变量定义语句,定义变量。定义了变量标识符a,右边可以用来推导a的类刑为int
var a int //零值0// a := 200 // 重复定义ab := 123,"abcd"// 党然可以? 在这里a不能重新定义为新类型,a被检测到了,go语言上只能迁就你了,但是要求a同类型,b是新定义的
TODovar int32 = 123 // 正确,指定了类型,也赋值。不会不用类型推导 TODO,隐式类型转换// const // 个局常量var (// 全局变量,顶层代码
a=100b = "abc"
标识符写源代码时候,用来指代某个值的。编译后还有变量、常量标识符吗?没有了,因为数据在内存中,内存访间靠什么? 地址,标识符编详后就没有了就换成了地址了
源代们本质是文本文件编详 ,源代码编程成一进制可执行文件运行这个赚盘上的二进制可执行文件,运行在当前8上,变成进程,进程要不要占内存空问,要的吗?李量、常量、值在这块内存中放者

bool在go中不是int类型,也不是其他整数类型。在go中,bool就是布尔型,和整型没有关系,就是完全不同的类型GO是对类型近乎苛刻的语言
int、uint、int64、uint64,这四个都是完全不同的类型,不能瓦操作
计算机世界这有二进制数据,每一个位bit表示0或者1,最多表达2种可能性
有符号、无符号类型
u unsigned 无符号,以int8、uint88bits,总共能够表达256种状态int8,1 byte,8 bits,表示正负数将最高位留出来不能表示数据状态,用0表示负,用1表示正,剩余7位表示数宁能够表示多少个不同的数字呢? 256种状态
uint8,1字节,8位,不能表示负数,所有的8位都用来表示数字能够表示多少个不同的数字呢? 256和状态

强制类型转换:显式 指明 类型转换,有可能失败fmt .Println(a + int (m)) // int (m)
string(整数值看做是ascii或unicode码) 去查编码表
var c rune = 300 // type rune = int32 类型 别名,type定义时使用了 =你等于我,你就是我
type myint int32 // 特别注意这里没有等号=,这不是别名
fmt.Println Print line 输出到控制台换行
fmt.Printf("%[2]T 号[IJdn",rune(m),string(m)) 值从1开始编 index1? 下一个如果没有指定索引,索引默认是indext1
fmt.Printf("%T T %T 8T n", a, b,c, a t b + c) // format
Printf 往控制台打印,f是format
% 占位符,和后面的值依次对应
%T 表示type,取值的类型
%d digital 数值形式,往往用于整数
b用string类型的值带字符串类型引号的s,quote引号A



0o101 => 0b 001 000 001 => 0b0100 0001 => 0x41 => 65单引号留给了表示字符,字面量表达,本质上是int32 (rune) 或byte (uint8)双引号和反引号用来表示字符串字面量。反引号
其中使用双引号、单引号多行
主要用途: 结构体tag使用
字符串或字符中,占用的字节数(因为我们要关心内存占用和磁盘占用),显示中在不同的显示设备中展示的显示宽度tab对应的显示宽度可以调整12345678
y
和
Xyz
XXXxXx
XXXXXXXX
"x y
iz' nnx y
"izI

*int 指向int类型数据的指针0xc000018088 表示门牌号码门里面房间里面住着数据
赋值在Go中,往往是建立副本
if 后必须是boolswitch 后面是什么类型? 写什么类就是什么类型。 如果switch后面不写,默认为hool
循环
fori=orissfmt.Println(il
1、i:=0 init 初始化,在循环开始之前,只能执行-
2、i< 5 bool,中间部分只能是bool值,bool值是true才能执行后面花括宁里面的语句一如果要执行第二趟,需要再次test检验这个表达式的值是否是true,虾梁是true,继续3、i++,循环体如果执行过一次的结尾时执行
如果是false终止循环是false终止循环
continue
break
for range 容器类型,容器内所有元素遍历遍历
按照某种顺序输出(线性化) ,不重复的把所有元素输出出来对容器里面元素是否有序没有要求
xyz测试 字符串utf-8编码
0123 6
fmt
Print*
Scan*
双层循环
线性数据结构
抽象概念
线性表,表,有序序列,放元素,是一种有序的放元素的容器,抽象概念数学概念物理实现:内存中怎么表达该序列。内存是线性编址的,内部把存储单元小格子编了号顺序表:使用连续的内存单元存储该序列的所有元系,内存的顺序就是数据顺序排好的队伍,数组Array
C
0
D
R
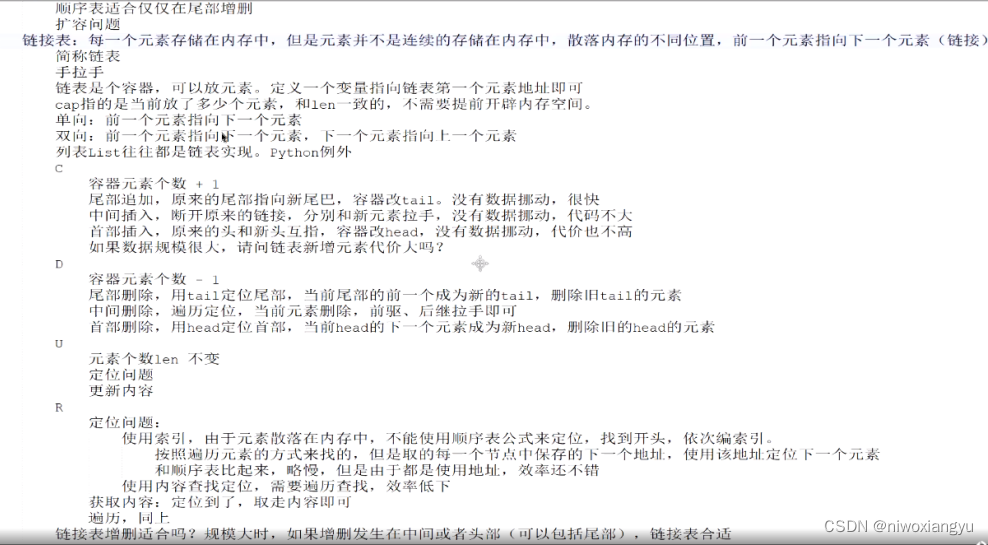
链接表:每一个元素存储在内存巾,但是元素并不是连续的存储在内存巾,散落内存的不同位置,前一个元素指向下一个元素(链接
简称链表
手拉手
单向:前一个元素指向下一个元素双向: 前一个元素指向下一个元素,下一个
素指向上
列表List往往都是链表实现。Python例外
个元素
0
6
R
可变
元素可恋容器可变
CRUD 遍历,create增,Read 读取,Update 改,Delete删

顺序sequence不是排序sort
o
容器元素个数 + 1
append如同排队,在队尾后增加即可insert插队队最尾巴后插队,就是append中间插队,占用当前位置,把当前位置与其后所有数据后移队首插队,所有元素统统后移挪动数据是要耗时间的,挪动的元素越多(规模越大),代价越大
容器元素个数 - 1
pop队尾元素移除,影响最小
remove如果是队尾,就是pop
中间离队,后面数据统统前移队首离队,后面数据统统前移
挪动数据是要耗时间的
w
元素个数len 不变定位问题
更新内容
8
定位问题:
使用索引,首地址 + 该类型的宁节数 偏移,所以,定位要用索引计算得到元素的内存地址,不用遍历,效率极高。顺序表不管有多少个元素,都是一个四则元泰公式直接推出来如果使用内容定位,内容比较,遍历的方式挨个比较内容,效率低下。最不幸,遍历完了,才知道没有
获取内容:使用索引直接定位该位置,拿走内容遍历:容器中的元素,不管有没有顺序,我们都要不重复的将所有元素挨个揽一遍。首地址开始始,挨个偏移取内容前提: 要数据规模,如果数据规模小,随便你玩。数据规模人,都是事顺序表适合仅仅在尾部增删扩客问题
链接表:每一个元素存储在内存中,但是元泰并不是连续的存储在内存中,做落内存的不同位置,前一个元素指向下一个元素(链接)
简称链表

 可变
可变
元素可变容器可变。Go中数组是容器不可变的
CRUD 遍历,Create增,Read 读取,Update 改,Delete删
二分法查找有一个前提,就是已经为元素排过顺序了,而排序非常非常耗时,非必要不要做排序sort容器的元素个数不能变了。数组必须给出长度,以后数组这个容器不能增删元素了,不能扩容了。长度是死的,必须定义时给出容器不可变,[...Jintf)[常量]int早面有元素,元素的内容可变顺序表实现
数组
可以索引
值类型?
索引: 0到len(array)-1, 使用索引是最快定位方式了内存结构
数组地址就是数组第一个元素的地址 (c语言 )每个元素占用空间看元素类型,int动态类型,当前机器上是8完节一个元素占用几个字节和类型有关,第一个元素的存储单元后面一定是第二个元素的存储单元,顺序表
宁符串字面常量,一旦定义不可改变,不同的字符串长度不一,数组采用string为元素,间隔怎么办?测试后发现元素存储空间间隔一样,都是16宁节,说明字符串比你想象的复杂一些。16个字节里面放了一个指针,指向字符串的内存位置
切片
容量可变,所以长度不能定死

长度可变,元素个数可变
底层必须使用数组引用类型,和值类型有区别
切片一定要关注len和cap
内存模型
组合结构
1 底层数组,数组容量不可变,元素内容能变2 slice header标头值或slice descriptor描述符
type slice struct f
array unsafe.Pointer // 指针,指向底层数组的首地址int // 表示当前切片的元素个数lenint // 表示当前切片可以最多放几个元素
cap
注意上面三个结构体的属性都是小写,所以包外不可见。len函数取就是len属性,cap函数取cap属性。指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
组合结构
1 底层数组,数组容量不可变,元素内容能变2 slice header标头值或slice descriptor描述符
type slice struct {array unsafe.Pointer // 指针,指向底层数组的首地址int // 表示当前切片的元素个数lenint // 表示当前切片可以最多放几个元素
cap
注意上面三个结构体的属性都是小写,所以包外不可见。len函数取就是len属性,cap函数取cap属性。指针可以通过取底层数组的第一个元素的地址,即切片第一个元素的地址
var al = make([lint,1,5)切片长度len为1,容量cap为5,本质上数据的存储利用底层数组,素是存储在底层数组中,打印[0)var a0 = []int[10, 1l, 12]
[]int 切片类型
元素有3个,len为3;容量cap为3打F[10 11 121&a0表示切片的地址,header这个结构体的地址&a0[0] 第一个元素的地址,由于第一个元素存在底层数组中,数组的第一个元素地址就是数组的地址
append(切片,1) append(切片,1,11,111)






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结