您现在的位置是:首页 >其他 >论文笔记与实战:对比学习方法MOCO网站首页其他
论文笔记与实战:对比学习方法MOCO
目录
(好久没更新了~~~准备分享一些paper笔记以及在公司分享的内容)
(还是要记录呀,很多东西过段时间再看都有点想不起来了)
1. 什么是MOCO
MOCO: Momentum Contrast for Unsupervised Visual Representation Learning
MOCO是标题前两个单词的首两个字符缩写组成,翻译过来就是动量对比,是一种无监督(或者说是自监督)的方法。
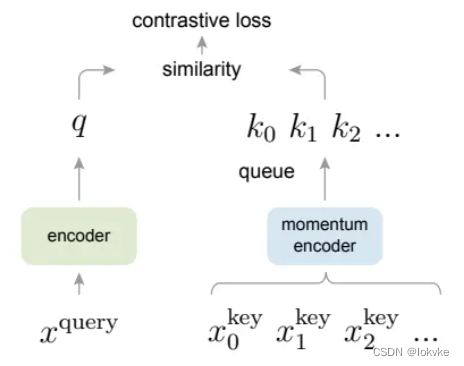
2. MOCO是干吗用的
从标题也可以看出是为了Unsupervised Visual Representation Learning,为了无监督视觉表征学习。即通过MOCO这种方法,学到有用的特征,可用于下游任务的使用。
3. MOCO的工作原理
3.1 一些概念
1. 无监督与有监督的区别
简单来说,有监督就是有标注信息,有X,有Y;对于无监督来说,只有X,没有Y。
2. 什么是对比学习
假设现在有两张dog的图片,一张cat的图片,首先提取图片的特征,利用提取的特征通过对比学习两张dog图片是同一类别,dog和cat的不同类别。
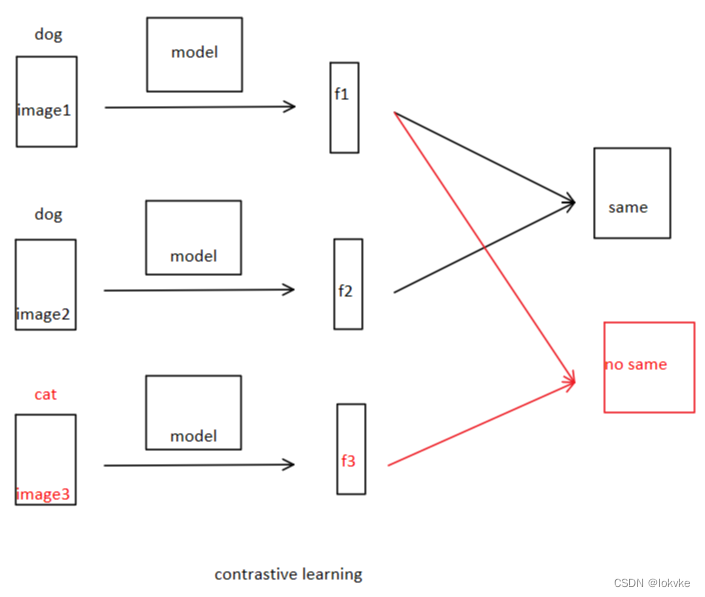
对比学习可以是有label的,如上述我们举的例子;也可以是无label的,如MOCO这篇文章所介绍的方法。
3. 动量是什么
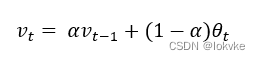
当前时刻的状态,是由上一时刻的状态和当前时刻的更新状态共同得来的。其中α的取值范围是0~1,表示上一时刻的状态和当前时刻的更新状态对当前时刻状态影响的权重。
3.2 MOCO工作原理
1. 字典查找

无监督对比学习可以看成是一种字典查找的方法,通过构建一个字典,当有一个样本query来了,需要到字典里去匹配查找,query应该与匹配到的key相似,与不匹配的key不相似,通过这种对比的学习去最小化损失。
2. 如何构建一个好的字典

-
学习的关键需要构建一个好的字典,好的字典包括两方面特点:
(1)字典足够大
学习到足够的差异性。
(2)保持一致性
字典里的keys(负样本的fetures)应该来自同一个或者相似的编码器。 -
三种方法比较
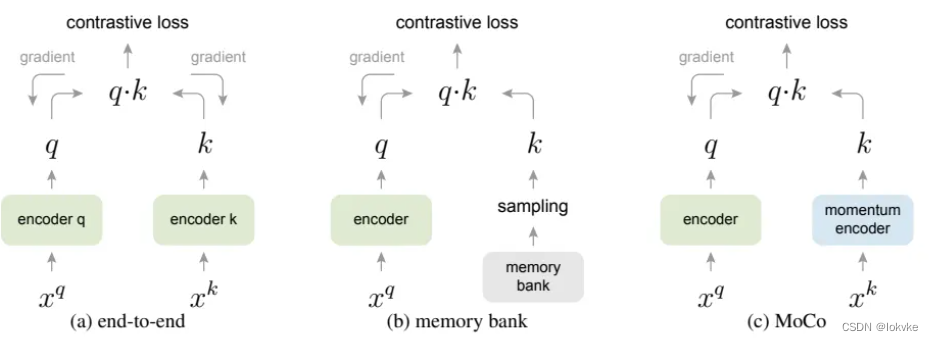
(a)end-to-end
batch_size和字典的大小一样,但是受显存影响,batch_size一般不会设置太大(通常设置为128或256),字典不够大
(b)memory bank
将所有的负样本存储在一个memory bank里,字典够大,但是无法保证特征的一致性
(c)moco
利用队列来充当字典,可以保证字典够大;同时利用momentum encoder,保证了特征的一致性
3. 工作流程
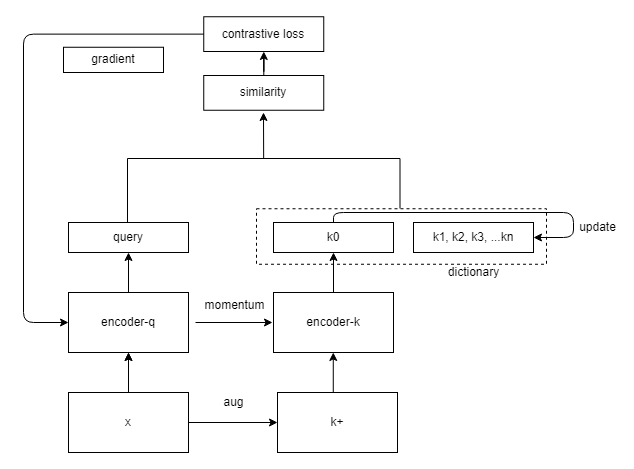
- 首先用encoder-q初始化encoder-k
- 输入图片x,x经过augmentation生成k+,x通过encoder-q生成特征向量query,k+通过encoder-k生成特征向量k0,query和k0构成一个正样本对,query和dictionary里的其他key都是负样本对
- 引入InfoNCE,计算loss,这里相当于对query作n+1分类,n为字典的大小,现在要做的就是把query分为第0类
- 计算梯度去更新encoder-q,用动量更新的方法去更新encoder-k;同时用最新的k0去更新dictionary

3.3 (伪)代码分析

4. 其他一些问题
- 对于negative样本,应该使用哪个编码器?
应该使用和positive一样的编码器,因为positive和negative样本都是相对于anchor而言,为了保持特征的一致性,应该让negative和positive样本使用同一个(或者相似的)编码器 - 为什么要使用队列当作字典?
字典的作用是用来存储负样本,且要求字典要足够大,如果将这么多的负样本都导入计算机中,显存是吃不消的。使用队列当作字典的好处是,可以让字典足够大,且让字典的size和batch_size剥离开。 - 什么是代理任务pretext tasks?
定义规则,规定什么是正样本、负样本。代理任务的作用就是去生成一个自监督的信号,从而去充当ground_truth这个标签信息。 - 选择的损失函数应该满足什么条件?
(1)当选择的q和positive k+相似的时候,loss应该尽可能小
(2)当选择的q和negative k不相似的时候,loss也应该尽可能小 - 什么是noise contrastive estimation
对于对比学习来说,一张图片就是一个类别,当类别很多的时候,没法算softmax(没法算loss),NCE把问题简化为二分类问题,一个是数据类别,一个是噪声类别,每次拿两者做对比就行。estimation的意思是,从负样本中抽样一些数据去做计算(估计),而不是用所有的负样本。抽样的样本越多,与使用整个数据集的结果更相似,所以MOCO强调这个字典要够大。
NCE loss就是把多分类问题变成二分类的问题,这样就可以继续使用softmax去计算。 - 什么是InfoNCE?
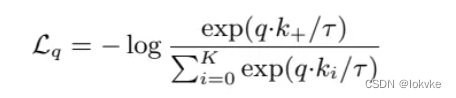
- InfoNCE是NCE的一种变体,InfoNCE还是把问题看成是多分类问题。(实际做的是K+1分类任务)
- 从公式可以看出,InfoNCE loss实际上就是cross entropy loss,不同的是InfoNCE loss中的K是负样本的个数,而cross entropy loss中的K是分类的类别数。
- 公式中的q·k就是logit,公式中的t是一个温度超参数,一般用来控制分布的形状。
- t越大,分布里的值变小,整个分布曲线更加扁平;
- t越小,分布里的值变大,整个分布曲线更加peak;
5. MOCO v2和MOCO v3
5.1 MOCO v2
- MOCO v2在v1的基础上,增加了以下几个措施:

(1)在训练阶段,增加了MLP head;推理阶段去掉。

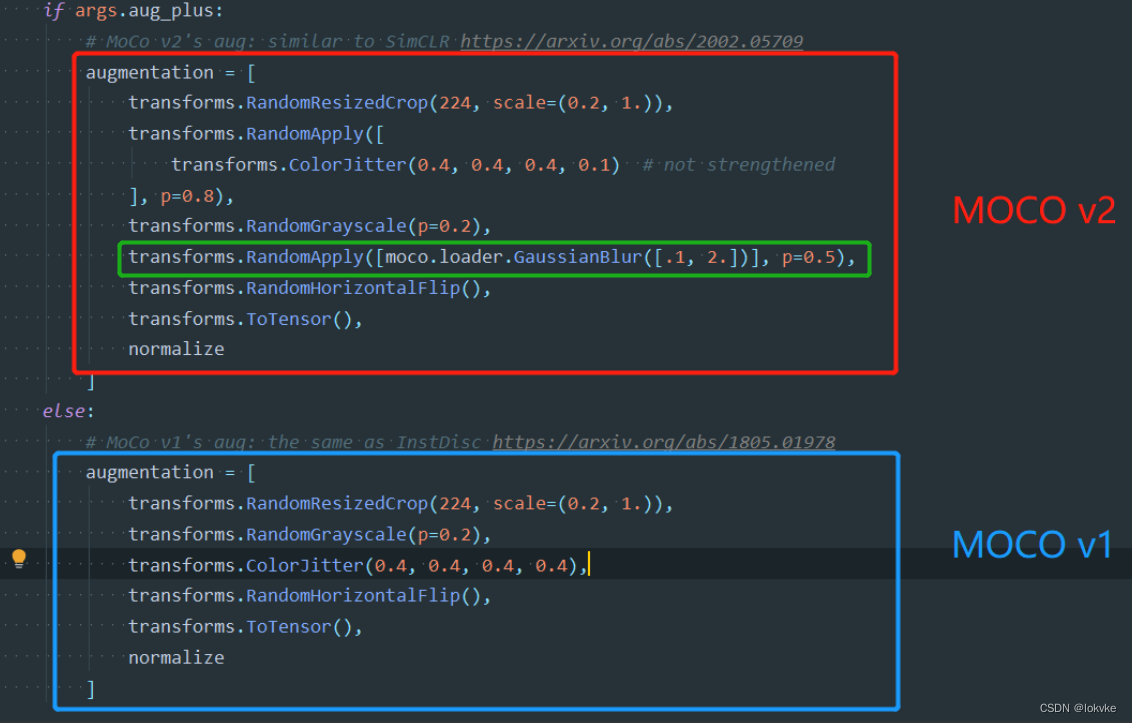
(2) Augmentation
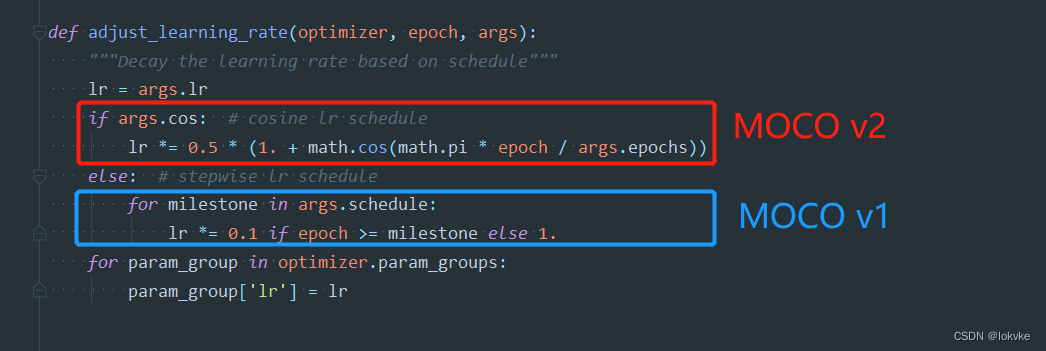
(3)Cosine learning rate schedule
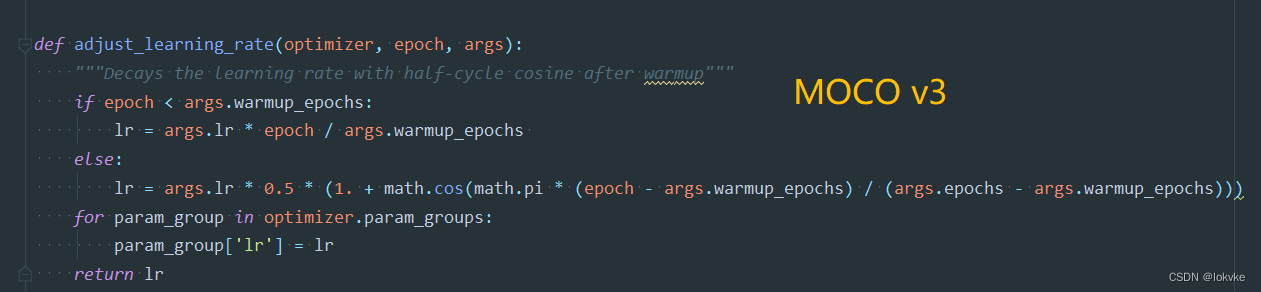
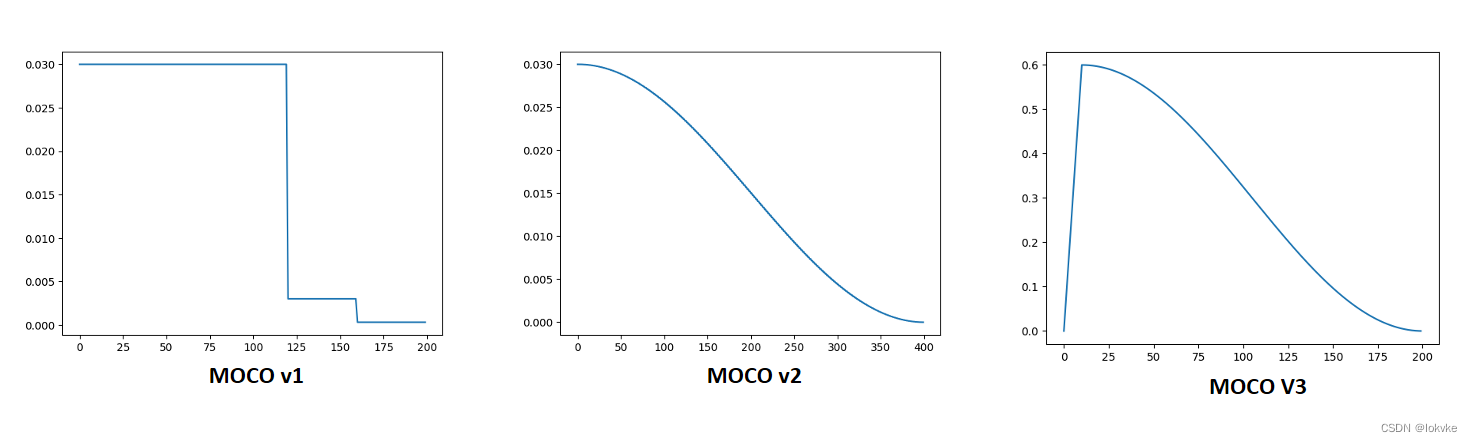
5.2 MOCO v3
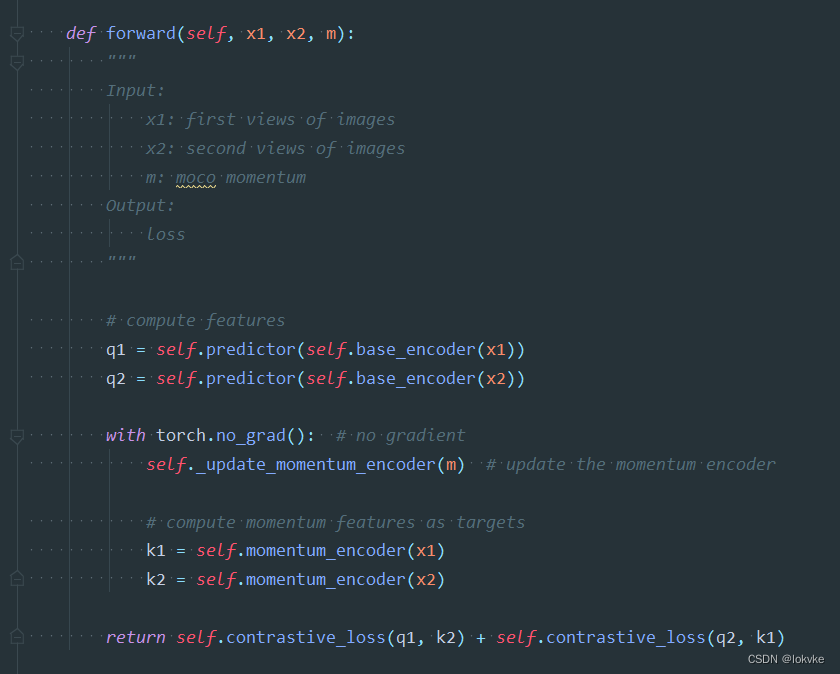
- MOCO v3引入了ViT(Vision Transformer)
- (伪)代码分析

- 计算过程参考CLIP论文所示:
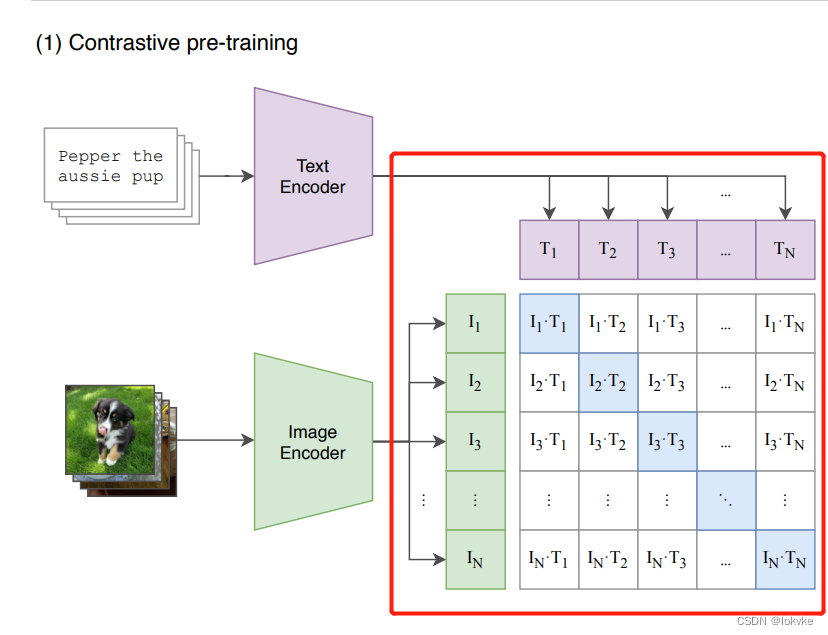
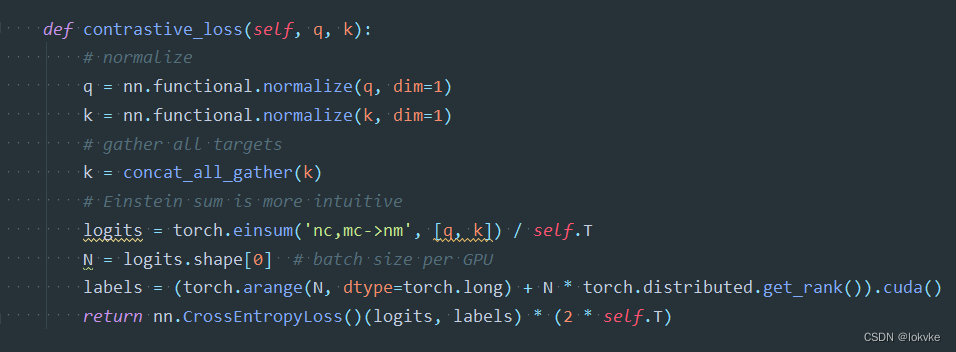
6. 实战部分
- 为了验证使用MOCO学习得来的特征是否更好,设计了一个4分类的图像分类实验(不是那么严谨),具体实验设置与结果如下所示:
6.1 数据
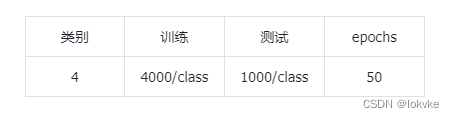
6.2 模型与参数设置
设置了4个模型,分别为resent、moco_resnet、vit、moco_vit,训练50个epochs
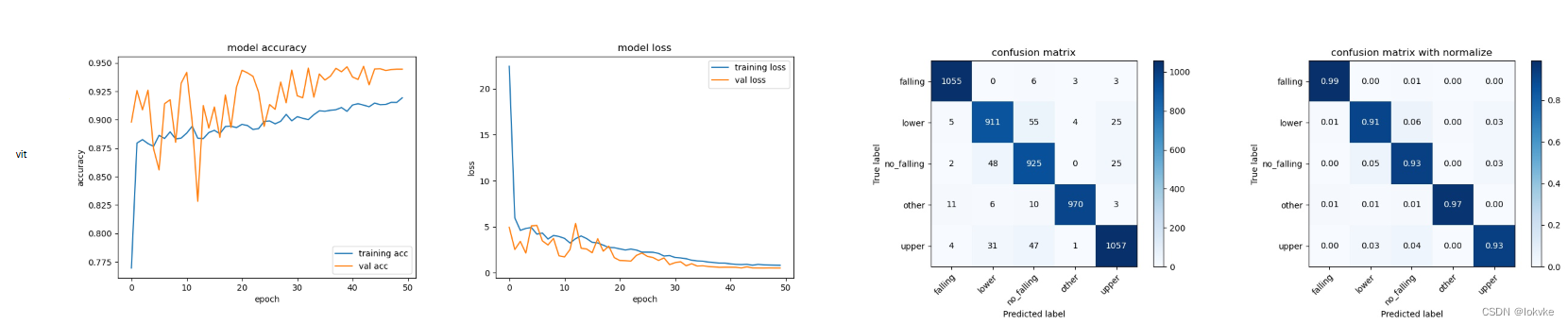
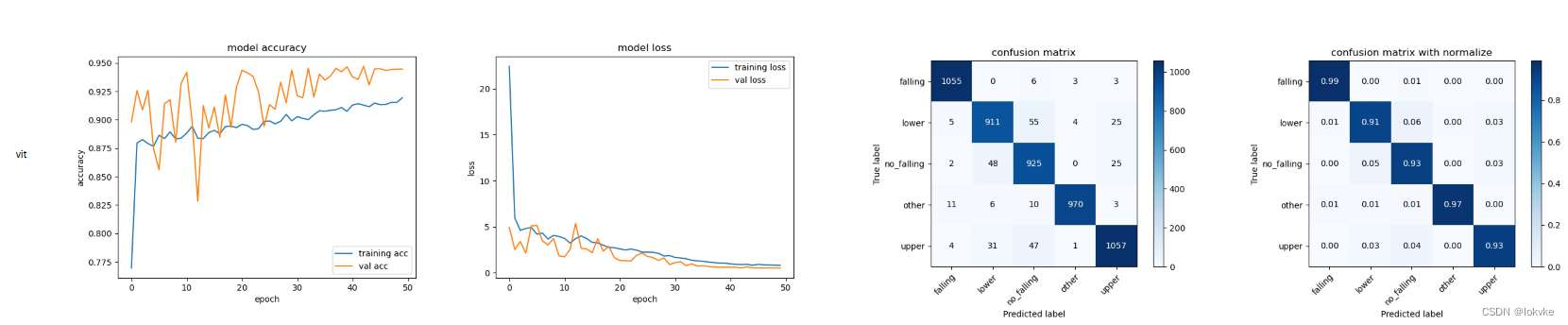
6.3 实验结果
- resnet和moco_resnet


- vit和moco_vit

- 实验小结
- 准确率:resnet > moco_resnet50; vit < moco_vit
- resnet和vit训练曲线振荡的比较厉害;而基于moco的预训练模型,训练曲线更加平滑
- 该实验只是个初步实验,所用数据较少,且训练的epochs较少,只能用于简单参考
- 可以看到,基于MOCO对比学习得到预训练模型,在下游分类任务中有一定优势
结束。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结