您现在的位置是:首页 >学无止境 >丰富上下文的超高分辨率分割:一种新的基准网站首页学无止境
丰富上下文的超高分辨率分割:一种新的基准
文章目录
Ultra-High Resolution Segmentation with Ultra-Rich Context: A Novel Benchmark
摘要
数据
随着人们对超高分辨率(UHR)分割方法的兴趣不断增加和快速发展,迫切需要一个覆盖广泛场景并具有全细粒度密集注释的大规模基准来促进该领域的发展。为此,引入了URUR数据集,即具有超丰富上下文的超高分辨率数据集。顾名思义,URUR包含大量分辨率足够高的图像(3008张5120×5120大小的图像)、广泛的复杂场景(来自63个城市)、足够丰富的上下文(100万个实例,8个类别)和细粒度注释(约800亿个手动注释像素),这远远优于包括DeepGlobe、Inria Aerial、UDD,
模型
- 还提出了WSDNet,这是一种更高效、更有效的UHR分割框架,尤其是在超丰富上下文的情况下,
- 多级离散小波变换(DWT)自然地被集成以释放计算负担,同时保留更多的空间细节,以及小波平滑损失(WSL)以利用平滑约束重建原始结构化上下文和纹理。
代码地址

数据集
在数量、上下文丰富度和注释质量方面,所提出的URUR数据集远远优于所有现有的UHR数据集,包括DeepGlobe、Inria Aerial、UDD等。在本节中,我们将说明数据集构建的过程,并通过各种信息统计对其进行分析,并给出保护隐私的详细措施。
Dataset Summary
所提出的URUR数据集包含3008张来自63个城市的5012×5012大小的UHR图像。训练、验证和测试集分别包括2157张、280张和571张UHR图像,近似比例为7:1:2。所有图像都用细粒度的像素级类别进行了详尽的手动注释,包括“建筑”、“农田”、“温室”、“林地”、“荒地”、“水”、“道路”和“其他”8类。
Data Collection and Pre-processing
该数据集由几个高质量的卫星图像数据源收集,供公众使用。这产生了来自63个城市的数据,然后我们根据以下标准在每个城市手动选择大约20个场景:
低歧义:所选场景中的对象在外观上不应该有太多明显的语义歧义。
高度多样性:具有不同类别、实例、时间和天气的场景在我们的任务中应该更合适、更有意义。
隐私保护:场景中的任何信息都不应泄露任何有关隐私的信息,如个人、店铺名称等。
因此,数据集在相机视点、照明和场景类型方面有很大的变化。此外,为了增强数据集的多样性和丰富性,为每个场景设置并收集了多个粒度视角。结果,我们总共收集了752张大小为10240×10240的图像,然后将其划分为3008张大小为5120×5120的图像。
数据标注
与自然图像相比,注释UHR图像总是一项更艰巨的工作,因为要标记的对象随着图像分辨率的增加而呈二次增长。这就是为什么现有的UHR数据集通常利用粗粒度注释或只注释一个主要类别。相反,我们打算对所提出的URUR数据集中的整个类别采用更细粒度的注释。图1显示了直观的比较,有关数据集统计的更多细节将在第3.4节中介绍。可以看出,包括DeepGlobe、Inria Aerial和URUR在内的UHR数据集显然比Pascal VOC和COCO等自然数据集包含更多的对象和实例,而这些对象的规模也较小。此外,一个或多个类对经常在空间上混合在一起,这给在注释过程中仔细区分它们带来了很大的麻烦。相比之下,URUR还包含比其他UHR数据集更多的对象和更丰富的上下文。总之,注释细粒度超高分辨率图像的主要挑战和耗时部分不仅反映在过度超高的图像分辨率导致的待注释对象数量上,还反映在尺度急剧变化的对象之间的超丰富的图像上下文导致的许多链问题上。
为了高效准确地进行标注,首先将每个5120×5120的原始UHR图像均匀地裁剪成1000×1000的多个补丁。我们让注释器分别对这些图像块进行注释,然后对它们的结果进行相应的合并,以获得相对于原始UHR图像的最终注释。通过这种方式,我们确保每个注释器只关注较小的图像补丁,这有助于注释过程并提高注释结果的准确性。
在裁剪过程中,相邻的面片具有120×1000像素的重叠区域,以保证注释结果的一致性,避免边界消失。为了进一步节省人力并加快整个过程,使用早期手动注释的图像来训练ISDNet模型,并用于在剩余图像上生成分割掩模。作为参考,注释器在我们开发的注释工具的帮助下调整掩码。
数据统计
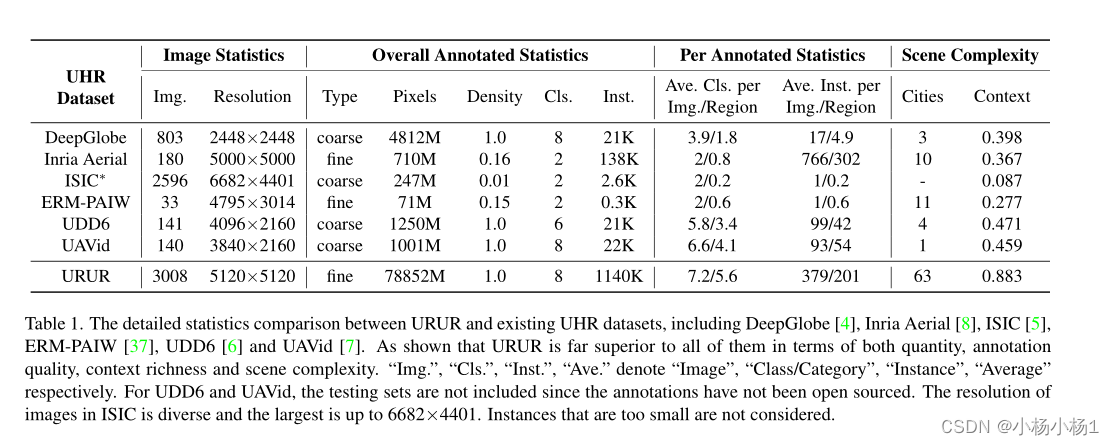
表1显示了所提出的URUR数据集与现有的几个主要UHR数据集之间的详细统计比较,包括DeepGlobe[4]、Inria Aerial[5]、ISIC[5]、ERM-PAIM[37]、UDD[6]和UA Vid[7]。首先,对于最基本的图像统计,URUR由3008张大小为5120×5120的图像组成,在图像数量和分辨率方面都优于所有其他数据集。具体来说,除ISIC和DeepGlobe外,其他所有数据集的图像数量都在200以下。DeepGlobe包含803张图像,但分辨率仅为2448×2448(5.9M),甚至没有达到UHR介质的最小阈值(8.3M)(如第1节所示)。
WSDNet
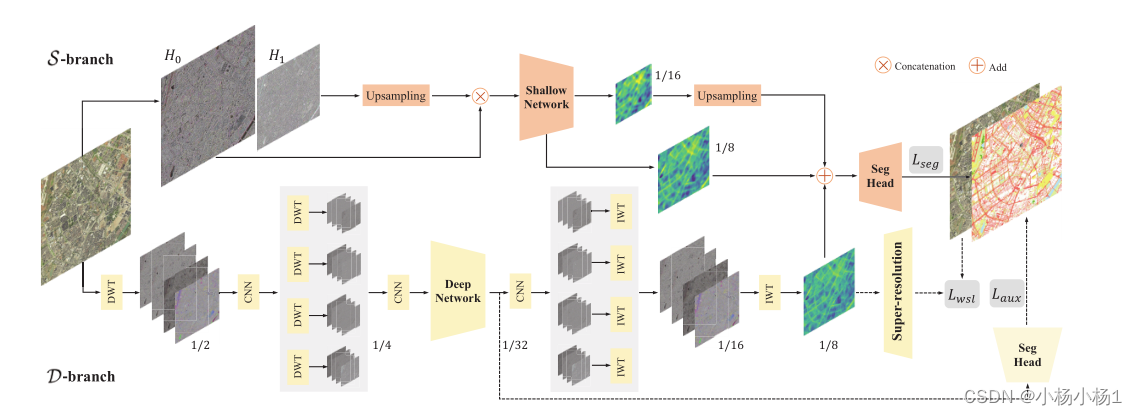
WSDNet:
由深分支D(下分支)和浅分支S(上分支)组成
在S中,使用拉普拉斯金字塔将输入图像分解为两个子带,然后将其连接并馈送到浅层网络中,以提取全尺寸的空间细节
在D中,使用两级离散小波变换(DWT)对输入图像进行下采样,然后将其输入到深度网络中,以获取高级类别上下文。
接下来,利用两级反相离散小波变换(IWT)将原始输入的尺度为1/32的输出上采样到1/8。最后,将这两个分支与多尺度特征融合,并使用基本交叉熵损失Lseg、辅助损失Laux以及小波平滑损失(WSL)进行优化,以在超分辨率头的帮助下重建原始输入。点线内的模块在推理过程中被移除。
小波平滑损失函数:
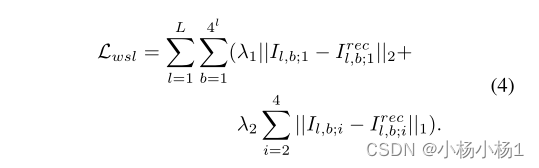
总损失
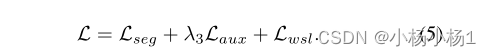
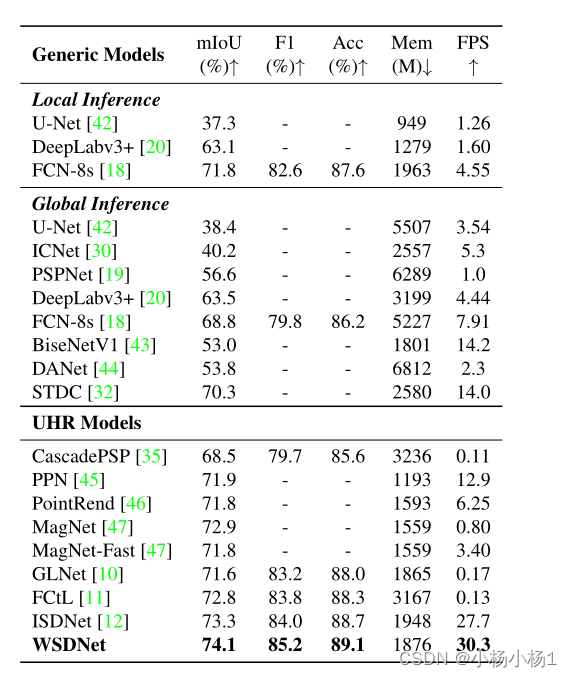
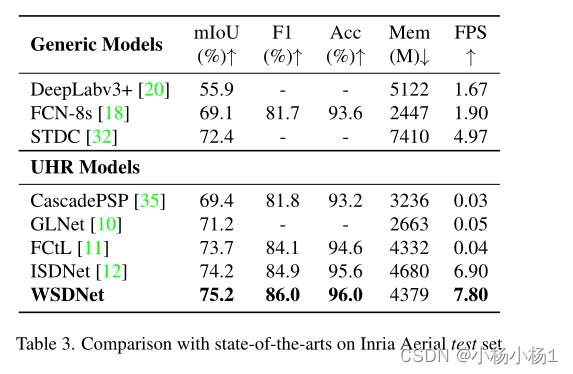
实验结果







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结