您现在的位置是:首页 >技术教程 >Transformer Block运算量网站首页技术教程
Transformer Block运算量
参考:Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili
在看朱毅老师讲解Swin Transformer论文时,里面有一个Transformer Block的计算复杂度的推导计算,感觉清晰明了,这里做一下记录,先说一下结果,一个Transformer Block中的乘法运算次数如下(不包含Layer Norm的运算量):
![]()
备注:上述计算过程不包含Layer Nor和Softmax。
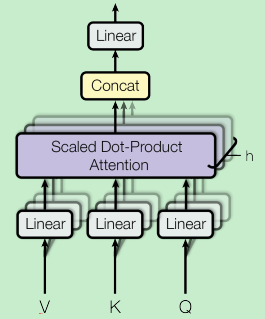
结合朱毅老师手动推导的过程,画一下Transformer Block各个模块的输入、输出,以及计算过程的计算复杂度,如下:
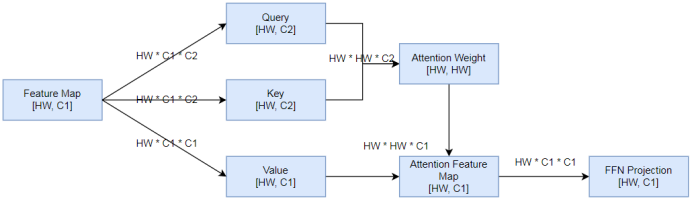
一个Transformer Block中的乘法计算主要来自于下面一些部分,假设Transformer Block的输入数据大小是[HW, C1]:
- Query:对输入序列做一次线性变换(全连接层)得到Query序列
- 输入:[HW, C1]
- 输出:[HW, C2]
- 计算过程:通过一次线性变换得到Query,其实就是使用一个输入维度为C1,输出维度为C2的全连接层,做一次计算的乘法运算量是C1 * C2,总共做HW次
- 乘法运算次数:HW * C1 * C2
备注:C1可以不等于C2
- Key:对输入序列做一次线性变换(全连接层)得到Key序列
- 输入:[HW, C1]
- 输出:[HW, C2]
- 计算过程:同Query一样,通过一次线性变换得到Key,其实就是使用一个输入维度为C1,输出维度为C2的全连接层,做一次计算的乘法运算量是C1 * C2,总共做HW次
- 乘法运算次数:HW * C1 * C2
备注:C1可以不等于C2
- Value:对输入序列做一次线性变换(全连接层)得到Value序列
- 输入:[HW, C1]
- 输出:[HW, C1]
- 计算过程:同Query一样,通过一次线性变换得到Value,其实就是使用一个输入维度为C1,输出维度为C1的全连接层,做一次计算的乘法运算量是C1 * C1,总共做HW次
- 乘法运算次数:HW * C1 * C1
- 计算Attention Weight:使用Query序列的每个时序数据与Key序列的每个时序数据做内积,得到大小为[HW, HW]的注意力权重矩阵
- 输入:Query -> [HW, C2], Key -> [HW, C2]
- 输出:[HW, HW]
- 计算过程:将Query序列中每个维度为C2的向量,分别与Key中HW个维度为C2的向量做内积。内积就是对应位置元素相乘,然后求和,所以一次内积的乘法运算次数是C2次。Query中每个向量要与Key中HW个向量做内积,Query中一共有HW个向量
- 乘法运算次数:HW * HW * C2
- 计算Attention Feature Map:使用Query和Key计算得到的Attention Weight,对Value中的序列数据进行加权
- 输入:Attention Weight -> [HW, HW],Value -> [HW, C1]
- 输出:[HW, C1]
- 计算过程:Attention Weight中每行一共HW个权重元素,分别与Value中的HW个向量相乘,一个数值与维度为C1的向量相乘,乘法运算次数是C1,每行乘HW次,一共HW行,然后将得到的HW个维度为C1的向量相加,得到最终大小为[HW, C1]的结果
- 乘法运算次数:HW * HW * C1
- FFN线性变换:对Attention加权得到的特征做一次线性变换(全连接层)
- 输入:[HW, C1]
- 输出:[HW, C1]
- 计算过程:通过一次线性变换得到输出,其实就是使用一个输入维度为C1,输出维度为C1的全连接层,做一次计算的乘法运算量是C1 * C1,总共做HW次
- 乘法运算次数:HW * C1 * C1
所以,一个Transformer Block中总的乘法运算量是:HW * C1 * C2 + HW * C1 * C2 + HW * C1 * C1 + HW * HW * C2 + HW * HW * C1 + HW * C1 * C1
= 2 * HW * C1 * C2 +2 * HW * C1 * C1 + HW * HW * C2 + HW * HW * C1
为了简单起见,假设C1 = C2 = C,那么总的乘法运算量是:4 * HW * C * C + 2 * HW * HW * C。
问题:
为什么Query和Key的向量维度要相等,但是可以不等于Value的输出维度,也就是C2可以不等于C1?
回答:
- 因为在计算Attention Weight时,使用Query和Key中的向量做内积,所以要保证Query和Key的向量维度要相等。
- Query和Key输出的Attention Weight维度是[HW, HW],消除了C2维度,所以C2可以不等于C1,但是可能会影响性能。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结