您现在的位置是:首页 >其他 >Prompt+低代码开发实战网站首页其他
Prompt+低代码开发实战
近期 AIGC 狂潮席卷,“前端走向穷途”“低代码时代终结”的言论甚嚣尘上。事实上 GPT 不仅不会干掉低代码,反而会大幅度促进低代码相关系统的开发。本文会介绍 GPT Prompt Engineering 的基本原理,以及如何帮助低代码平台相关技术快速开发落地的技术方案。接着往下看吧~
?看目录点收藏,随时涨技术
1 提示工程
1.1 提示工程基本概念
1.2 如何使用 OpenAI/Chatgpt 做提示工程测试
1.3 role & token
1.4 提示工程技巧-少样本提示(few shot)
1.5 提示工程技巧-思维链提示(Chain-of-Thought,CoT)
1.6 提示工程技巧-生成知识(knowledge generation)
1.7 提示工程的总结
1.8 langchain 的介绍
2 低代码技术
2.1 低代码技术介绍
2.2 Hello world:AI2SQL
2.3 接口网关:构建 AI 友好的应用
2.4 低代码搭建:生成知识技术的大规模使用
2.5 低代码搭建:逻辑编排技术与 GPT
2.6 低代码搭建:数据可视化技术与 GPT
2.7 文档系统的 GPT 搭建
2.8 总结
3 GPT 高级使用技巧走马观花与总结
01
提示工程
1.1 提示工程基本概念
提示工程是什么?如图所示。你同大模型的交谈就是所谓的 Prompt, 而如何设计、组织、优化则称为提示工程(Prompt Engineering)。
提示工程是通用技术,适合于几乎所有大语言模型(Large Language Models,简称LLMs)。

在大模型应用的开发过程中,Prompt Engineering 做得好,不仅可以提升回答的质量,也可以限制回答的格式,因此提示工程也能够帮助大模型返回的内容更友好地被解读,这对后续跟其他系统的集成非常重要。
一般来讲提示工程包含如下的信息:

| · 指令 —— 希望模型执行的特定任务或指令,文字描述清楚。 · 上下文 —— 可以包含外部信息或额外的上下文,以引导模型更好地进行响应,在对话类型的 GPT 应用中就是所谓的“聊天记录”。 · 输入数据 —— 用户希望找到响应的输入或问题。 · 输出指示符 —— 指示输出的类型或格式,比如可以要求输出 SQL/JSON。 |
1.2 如何使用 OpenAI/Chatgpt 做提示工程测试
除了直接访问官网之外,各位开发者同时也可以使用 Node.js or Python 直接调用 OpenAI api 。基本思路就是直接引用 OpenAI 的包,然后传入适当的参数即可。例如 :
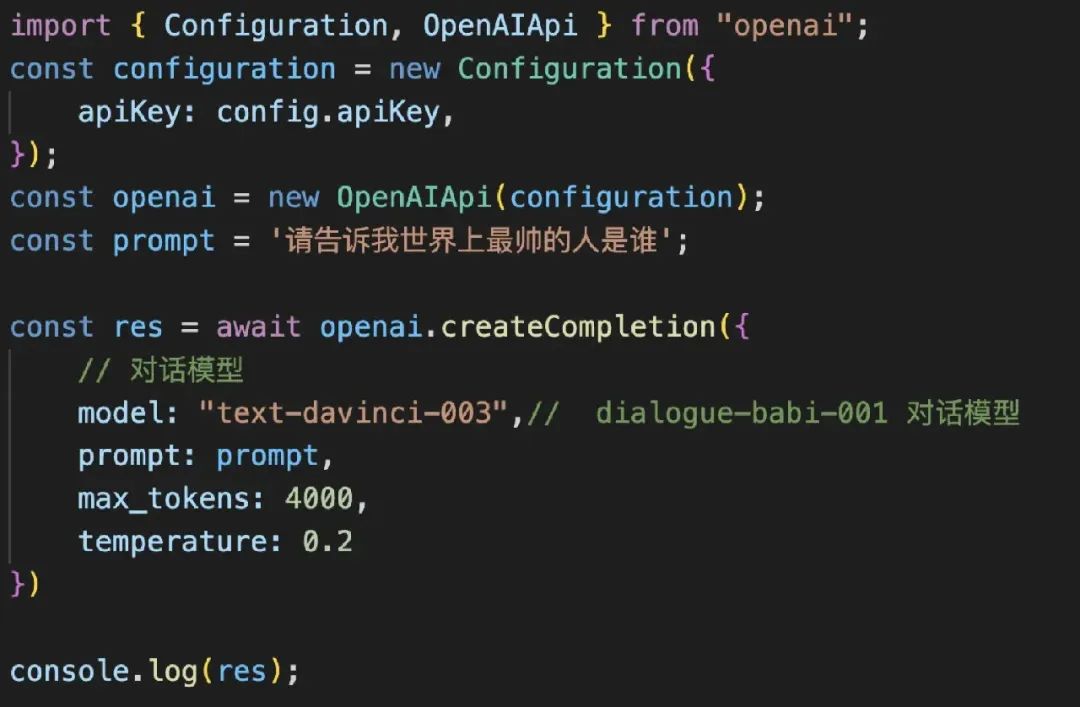
在测试过程中需要关注两个点。首先是参数 temperature 、top_p。
· temperature(温度) —— 简言之,温度越低,结果越具有确定性,因为总是选择概率最高的下一个词。提高温度可能导致更多的随机性,鼓励产生更多样化或富有创意的输出对基于事实的问答任务使用较低的温度值,以鼓励更加准确和简洁地回答。对于诗歌生成或其他创意任务,提高温度值可能会更有益。
· top_p —— 类似的,通过 top_p 调节名为 nucleus sampling 的温度抽样技术,可以控制模型在生成回应时的确定性。如果需要准确和事实性的答案,请保持较低的 top_p 值,如果希望获得更多样化的回应,请增加到较高的 top_p 值。
另外是模型 text-davinci-003 和 gpt-3.5-turbo 的区别。
text-davinci-003 和 gpt-3.5-turbo 都是 OpenAI GPT-3 系列中的两个模型,区别在于性能和价格,此处我们着重讲下性能的对比。
性能:gpt-3.5-turbo 相对于 text-davinci-003 在性能方面有所提高。根据 OpenAI 的说法,gpt-3.5-turbo 在许多任务中的性能与 text-davinci-003 相当或更好。这意味着,与 text-davinci-003 相比,gpt-3.5-turbo 可以在保持相同质量输出的同时更有效地完成任务。
1.3 role & token
在调用 OpenAI 的过程中你会看到,消息会传入一个参数叫做 Role 。

不同 Role 的含义如下:
系统消息(role = system):一般用于定义 GPT 对话的行为,比如:你是一个 SQL 工程师,擅长写 SQL。gpt-3.5-turbo-0301 并不会把这个系统消息做很高的优先度关注。未来的模型将被训练为更加关注系统消息。
用户消息(rule=user):一般是用户自己的输入以及开发者给 GPT 的一些指令。
助手消息(rule=assistant) :可以帮助存 GPT 自己的响应。
当对话场景需要引用之前的消息时,就需要维护好这个 message 数组,这就是所谓 GPT 对话的上下文 or 历史记录。
大模型对过去的请求没有记忆,所以你如果想保持这个上下文,必须维护好这个 message,然后在每次对话过程中,把完整的 message 传过去。因此,如果这些记录超过了模型的 token 限制,就需要以某种方式缩短它。
另外我们经常说的 Token 是什么意思呢?
GPT 家族的大语言模型会使用 Token 作为处理文本的标识,用来标识一段文本中的“词”。大语言模型会理解这些 Token 之间的关系,并能够预测一系列 token 中的下一个。文本占据多少 Token 我们可以通过 https://platform.openai.com/tokenizer or tiktoken 来计算 ,如图:
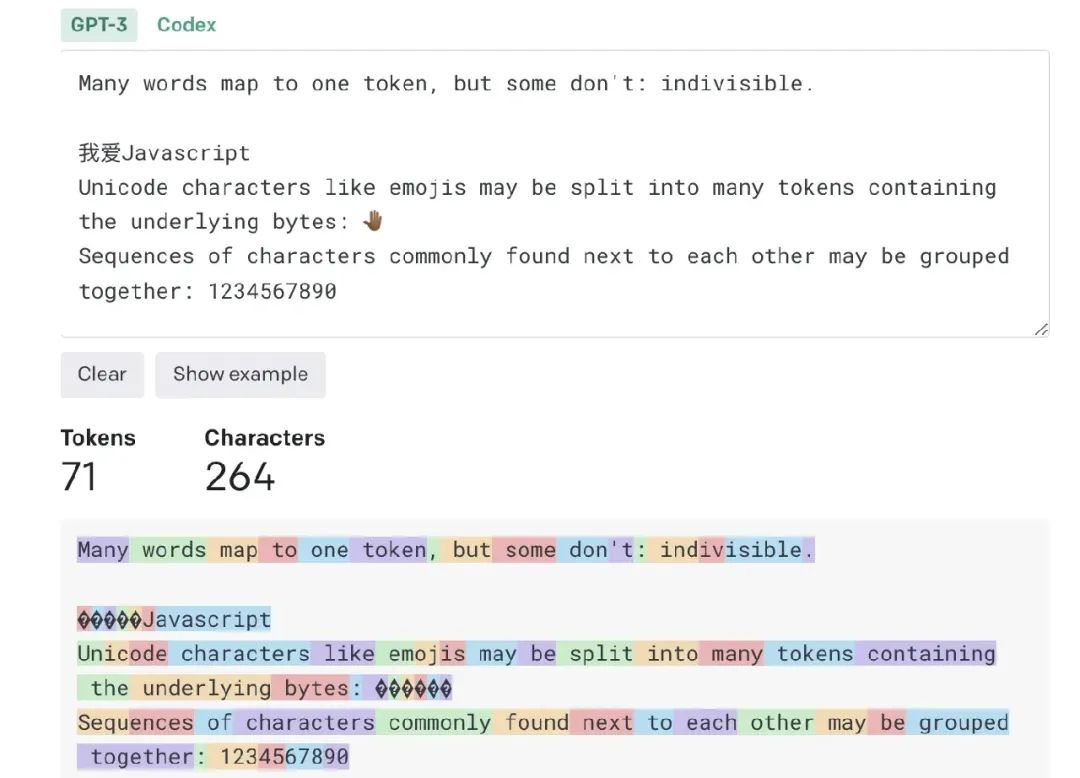

在这里可以很明显地看到,中文占据了大量 Token,同时换行、标点符号等也会占据 Token。根据 OpenAI 的建议,一个 token 能写4个字母,或者0.5个汉字。因此4000个 token 可以写2000字的中文。
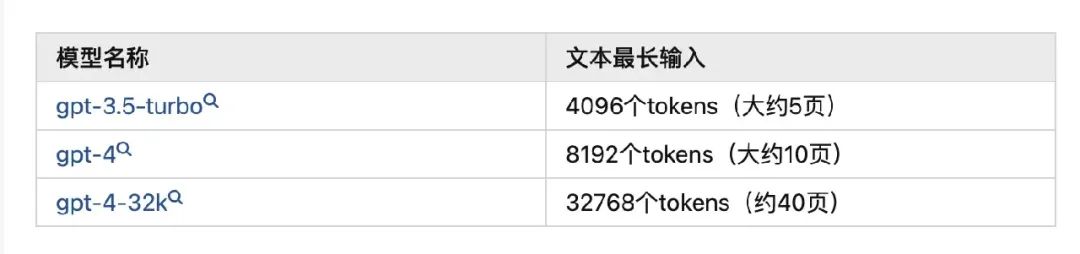
下图是输入和输出都会计算 Token 。比如 API 调用在消息输入中使用了 10 个 Token,而您在消息输出中收到了 20 个 Token,则需要支付 30 个 Token 的费用。如果在调用时候超了,会调用失败。输出的时候超了,会被截断。因此你自己的 GPT 应用, 一定要实现“试算 Token”的功能。不同模型支持的 Token 最大值参考 。
由于 Token 价格昂贵,因此在一段时间之内,“省 Token ”都是 AI 应用需要关注的重要问题。
1.4 提示工程技巧-少样本提示 (few shot)
目前的大语言模型(LLMs)通过大量的数据训练和指令调整,能够在零样本情况下完成任务。


以上例子中我们直接向大模型提问,并没有添加任何需要示范的例子,就可以得到很好的回复,这便是零样本能力。但事实上很多场景零样本是无法得到我们想要的结果的:

这时候我们就可以通过少样本提示技术,给 GPT 举几个例子,帮助它学习思考:

这样看,效果就好很多了。这个例子也体现了大模型强大的学习能力。在我们后续要讲的低代码开发中,few shot 技术是非常常用的,如图:

我们通过 few shot,让 GPT 学会了我们自己定义的图表 DSL 。但零样本提示是万能的吗?比如我们看以下例子。零样本提示:
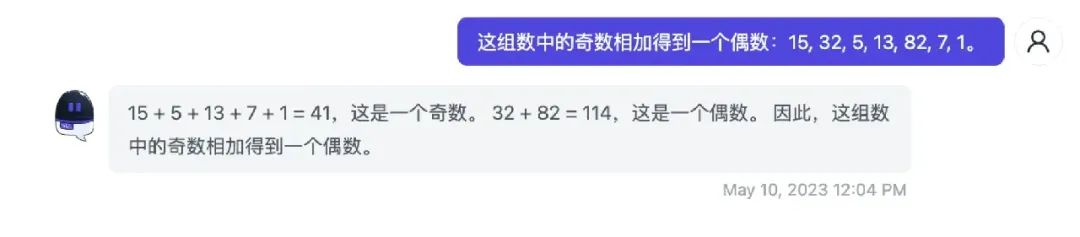
这明显是错误的,我们使用 few shot 技术:

可以看出来还是错误的。因此 few shot 技术,并不能解决一些数学和推理场景。
1.5 提示工程技巧-思维链提示(Chain-of-Thought,CoT)
思维链提示(Chain-of-Thought,CoT)是一种用于提高大语言模型推理能力的技术,通过提示模型生成一系列推理步骤来解决多步骤的问题。研究表明,这种技术可以显著提高模型在数学、常识、推理等方面的准确性。该技术的应用使得模型能够将多步骤的问题分解成中间步骤,从而更好地理解和解决问题。
比如一个简单的例子 :
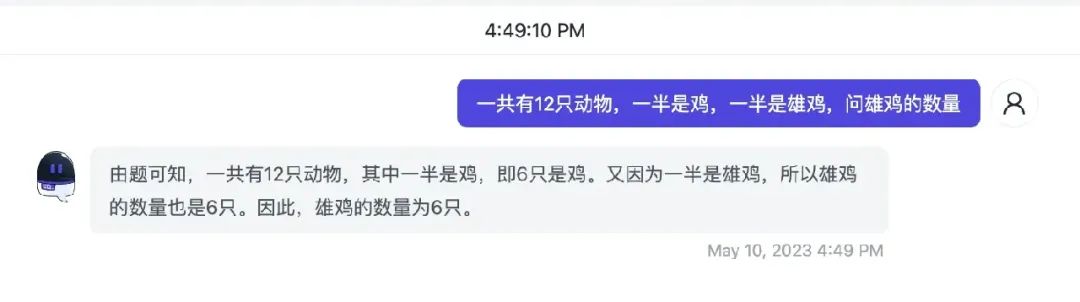
我们发现 GPT 已经完全懵了。但如果我们加入一句“请一步步思考下”,引导 GPT 按照步骤思考呢?

效果非常惊人。同样我们在之前的例子中使用魔法咒语:

效果也非常好。事实上思维链的“触发”方式,就是在原始提示中添加“逐步思考”"请一步步思考问题",但它能够起到非常惊人的效果。在去年 google io 中还专门演示了这个技术 。

事实上,思维链远远不止“让我们逐步思考”这一魔法咒语,它可以仅仅通过 Prompt 就可以让 GPT 完成非常复杂的任务。下面我们来举个例子:
假设今天我需要送给一个朋友礼物,希望有一个机器人能告诉你。如果我们考虑下自己的思考过程,可能会这么想:
| · 我这个朋友是男生。 · 男生可能会喜欢一些高达、手办、相机等等。 · 那我就在其中选择一个。 |
可以看出,人们在得到一个问题的最终答案前,通常是会有若干个「中间步骤(intermediate steps)」的。因此我们可以把这些“中间步骤”明确出来,引导 GPT 进行思考,prompt 设计如下:

这个 Prompt 中,首先我提供了两个工具,告诉这两个工具可以帮助 GPT 获得答案。之后特别指出,GPT 每次思考都要返回 Thought、Action、Action Input,它要先去我的工具库中寻找工具,调用适合的工具,并返回答案,同时要一直不停地做,直到得到答案。那我们看下实际使用时,GPT 是如何思考的:

可以看到 GPT 像人一样,一步步地思考问题,它首先理解了这个问题,并从工具库中取出了性别判断工具,进行判断后,它又在工具库中取出了礼物推荐工具,并进一步得到结论。其实这个思路就是非常流行的 Reasoning + Acting :ReAct 技术,每次让 LLM 输出一个当前的【思考】和【要做的动作】,这个动作并不只限于检索信息,可以是调用任何工具,类似 ChatGPT plugin。LLM 通过 few shot 的例子和工具自带的描述,还有它自己学到的常识来决定何时调用工具以及如何调用工具。
这样 ReAct 引入了外部工具的概念,让 LLM 能够通过这种步进式的方式逐步思考并调用外部工具,根据结果进一步思考循环。同时也可以仅仅是输出一步思考,并继续下去,类似 CoT。在流行的开发框架 Langchain 中就封装了帮助实现这个思路的一系列工具。
1.6 提示工程技巧-生成知识(knowledge generation)
生成知识提示是一种利用语言模型自动生成知识并整合到常识推理中的方法。这种方法利用了大语言模型的优势,将其作为改进常识推理的、灵活的外部知识来源。通过使用通用的提示格式直接从语言模型中生成知识陈述,然后选择与给定任务相关的知识,可以提高常识推理的准确性。这种方法在语言生成、自然语言推理和问答系统等领域具有广泛的应用前景。

举例来讲:

事实上高尔夫球应该是总分越低越好,GPT 对高尔夫球的理解一知半解。但我们在 prompt 的时候传入高尔夫球知识呢?

可以看到回答就很准确了。因此生成知识可以帮助 GPT 掌握并加深已有知识的理解。同样我们从低代码角度来考虑一下这个问题。

在这个 prompt 中,我们要求 GPT 给我们一个流程描述的 DSL,GPT 给了,事实上这也是一种常用的 DSL 叫做 mermaid 。

当我们有自己的 DSL 想让 GPT 返回,这样就可以借助生成知识+ few shot 技术:
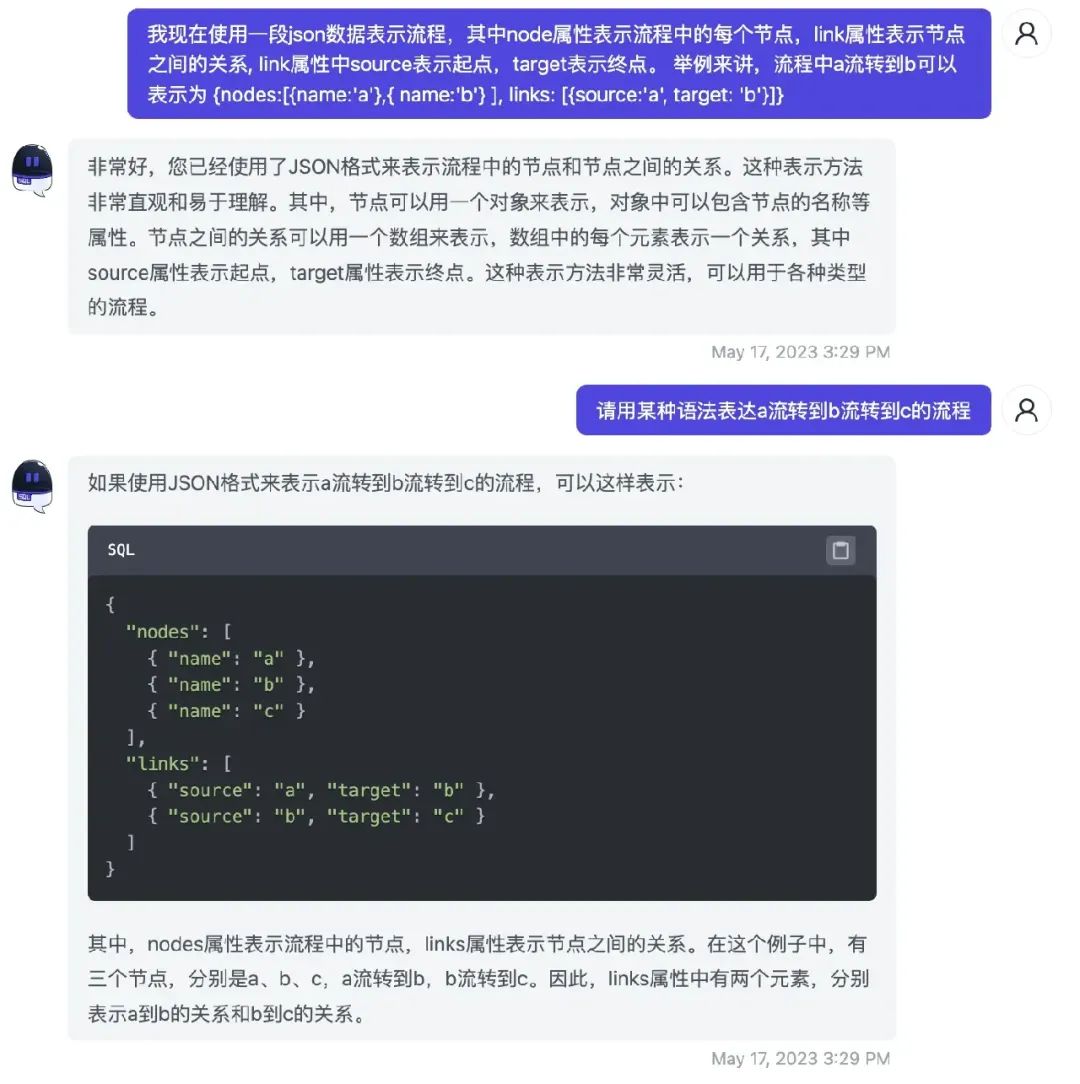
可以看到 GPT 返回了我们想要的逻辑编排的 DSL。因此生成知识技术结合 few shot 是很多 AI +低代码技术的基石。后续我们的文章也会大面积地使用生成知识技术。
1.7 提示工程的总结
基本原则:
| · 从最基本,最原子的任务做起,将大任务分解成多个子任务。 · 提示内容最好包含:指令、上下文、输入、输出格式。 · 对于希望模型执行的指令和任务要非常具体。提示越具有描述性和详细性,结果越好。最好带上例子。 · 不要写太多没有意义的话。尽量精炼,不要带前后矛盾的提示。 |
同样我们也可以使用以下的高级技巧:
| · 少样本提示(Few-Shot Learners)。给出一些样例,引导模型按照样例回答。 · 思维链(Chain-of-Thought(CoT)prompting)。通过提供推理步骤,让大语言模型具备分析能力。过程中也提到了(Zero-Shot CoT),引导模型在回答的时候,给出推理步骤,会更容易获得理想的结果。 · 生成知识(Generated Knowledge Prompting)。对于一些大模型不掌握的知识。我们可以通过提示的形式输入进去,从而获得更准确的答案。 |
1.8 langchain 的介绍
langchain 是一个非常好用的框架,能够帮助我们快速构建基于大模型的应用程序。它提供了很多工具、组件和接口。对于前端来讲甚至可以把它类比成 lodash/jquery 一样的基础库。

langchain 的模块大致如上所示,简单介绍一下就是:
| · 针对各种 LLM 调用的封装和缓存。 · 基于文本的处理,包括各种文档的加载方式(本地/云),文档的处理方式,以及各类向量数据库的连接工具。 · 提示词 prompt 管理,其实可以理解为一个模板引擎,可以方便地管理我们的各种提示词模板、few shot的例子等等,也可以帮助解析 OpenAI 返回的内容。 · Chains 是 LangChain 中最重要的概念,其实可以理解为一个个有明确输入/输出的独立任务,可以使用 Chain 构建完成某个特定任务的应用程序。例如,我们可以创建一个链,它接收用户输入,使用 Prompts 相关组件格式化输入,然后将格式化后的结果传递给 LLM,然后将 LLM 的输出传递给后端组件或者其他链。我们也可以通过将多个链组合在一起,或将链与其他组件组合来构建更复杂的链。LangChain 实现了很多现成的链,比如用于对文章进行总结的 Summarization 链,用于对指定文本进行问答的 Question Answering/Question Answering with Sources 链,用于对指定知识库问答的 Retrieval Question Answering/Retrieval Question Answering with Sources 链,用于获取并解析网页的 LLMRequestsChain 链,用于操作关系型数据库的 SQLDatabaseChain 链等。 |
我们可以看下如何使用 langchain 快速搭建一个基于 GPT 的爬虫应用:

结果如下:

可以看到,我们结合 langchain + 简单的 prompt 就完成了一个爬虫的编写。
02
低代码技术
2.1 低代码技术介绍
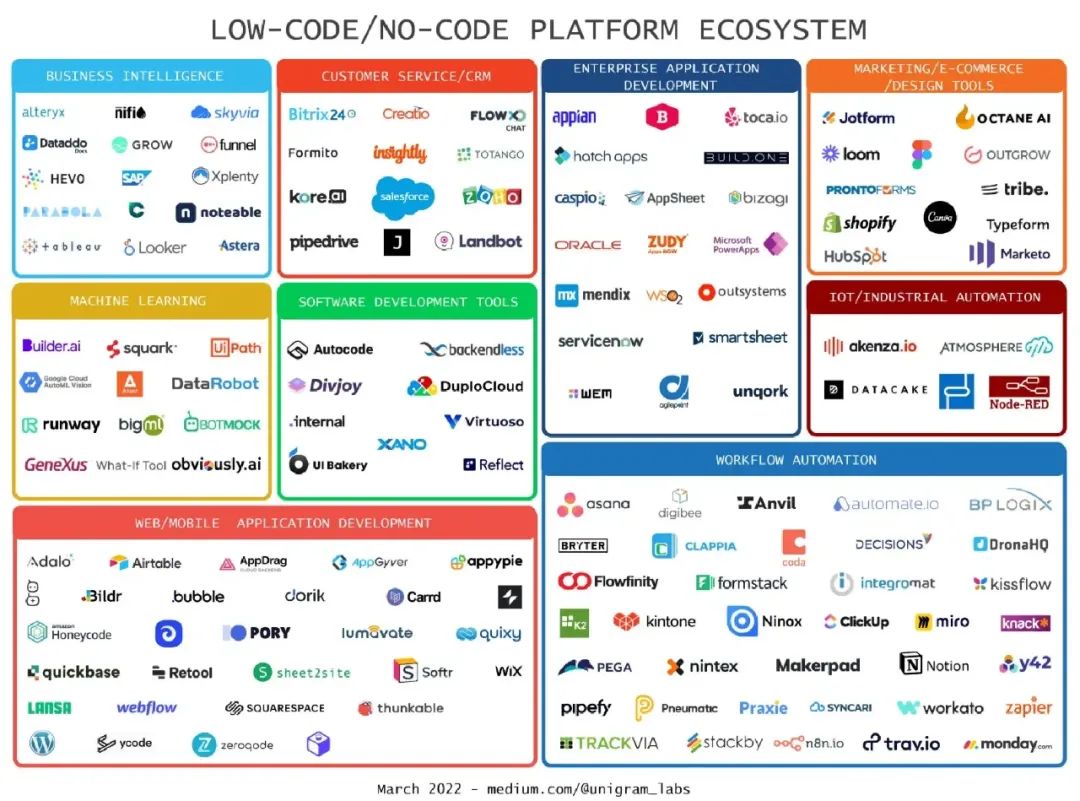
近年来,低代码开发热潮又一次袭来,业界对“降本、增效、提质”的声音越来越强。腾讯的微搭等大量低代码产品相继而至,在业界引发关注。目前的低代码产品,大部分偏重于 “UI 界面可视化编排”,但低代码这个概念其实涵盖范围非常广。如图所示,在国外,低代码类产品矩阵非常庞大。某站点将低代码类产品按照功能分为以下几类:
| · BI 数据可视化图表搭建 · CRM 类应用搭建 · 机器学习类应用搭建 · 企业应用搭建 · 店铺装修工具 · 物联网、IOT 构建工具 · Web、Mobile 应用开发 · 工作流系统 |
同时对于一个完整的 web 应用来讲,它会经过用户界面-接口服务-数据服务等多个模块,因此这次的低代码与 GPT 结合,我们也会在整个链路上进行尝试:

我们的思路简单拆解就分为以下三步:

2.2 Hello world:AI2SQL
写 SQL 是接口/数据工程师极其头疼的问题,以这个为开场的原因是 AI2SQL 的场景足够明确,Prompt 也比较好设计。
分解任务:
| · 目标:希望能够根据需求自动生成 SQL。 · 我需要获取目前的库表信息,之后根据 SQL 知识构建 SQL。 |
构造 prompt:
| · 指令 —— 希望模型输出 SQL · 上下文 —— 当前在哪个库,哪个表 · 输入数据 —— 表结构 - DDL · 输出指示符 —— 我希望输出纯正 sql,不想解析一堆内容 |
于是我们就有如下构造方式:
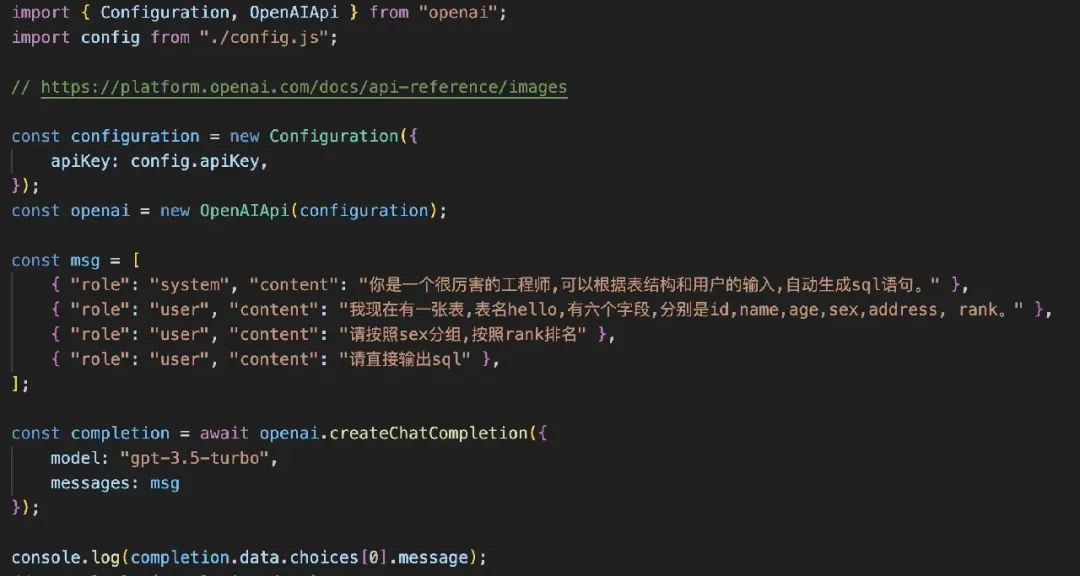
其思路就是把表结构和用户输入传给 GPT 由 GPT 去编写。我们目前的可能产品形态如下:
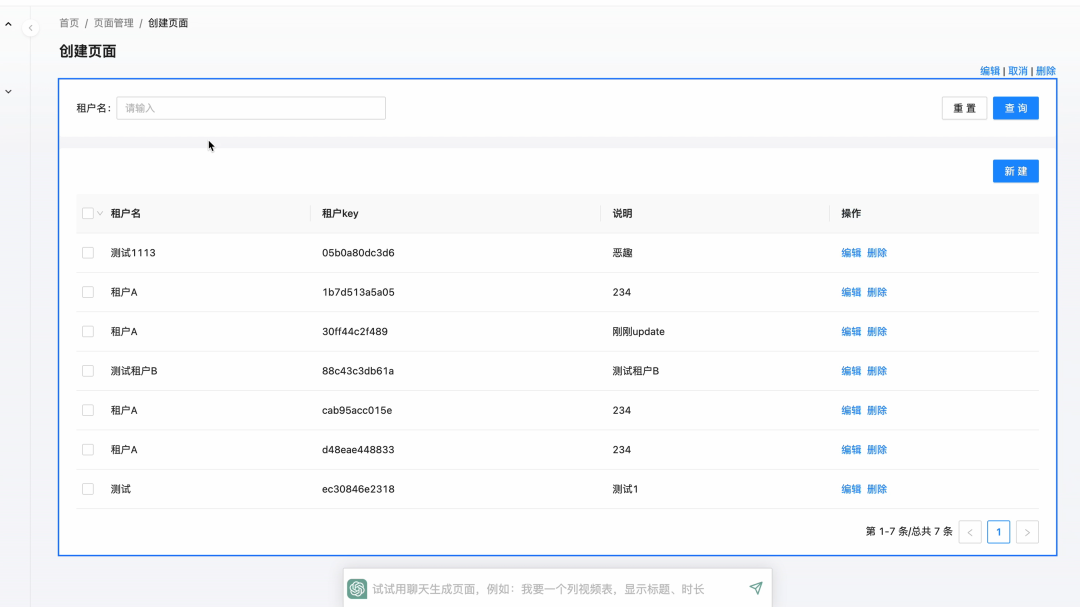
用户输入复杂的描述,其中甚至带有很多对 SQL 语法的要求,GPT 也能快速准确地返回。
在这个例子中,我们发现构建 GPT 产品时,主要的工作都在组织 prompt 上,因此对 prompt 进行设计可以有效达到目的。同时 SQL 是 GPT 非常擅长编写的语言。注意我在这里特别强调了“非常擅长”,后面还会讲这个的重要性。最后为了让 GPT 感知到我们的表结构,我们利用生成知识(Generated Knowledge Prompting) 这一技巧,让 GPT 掌握了它不知道的东西。
AI2SQL 这一类系统的架构设计如下:
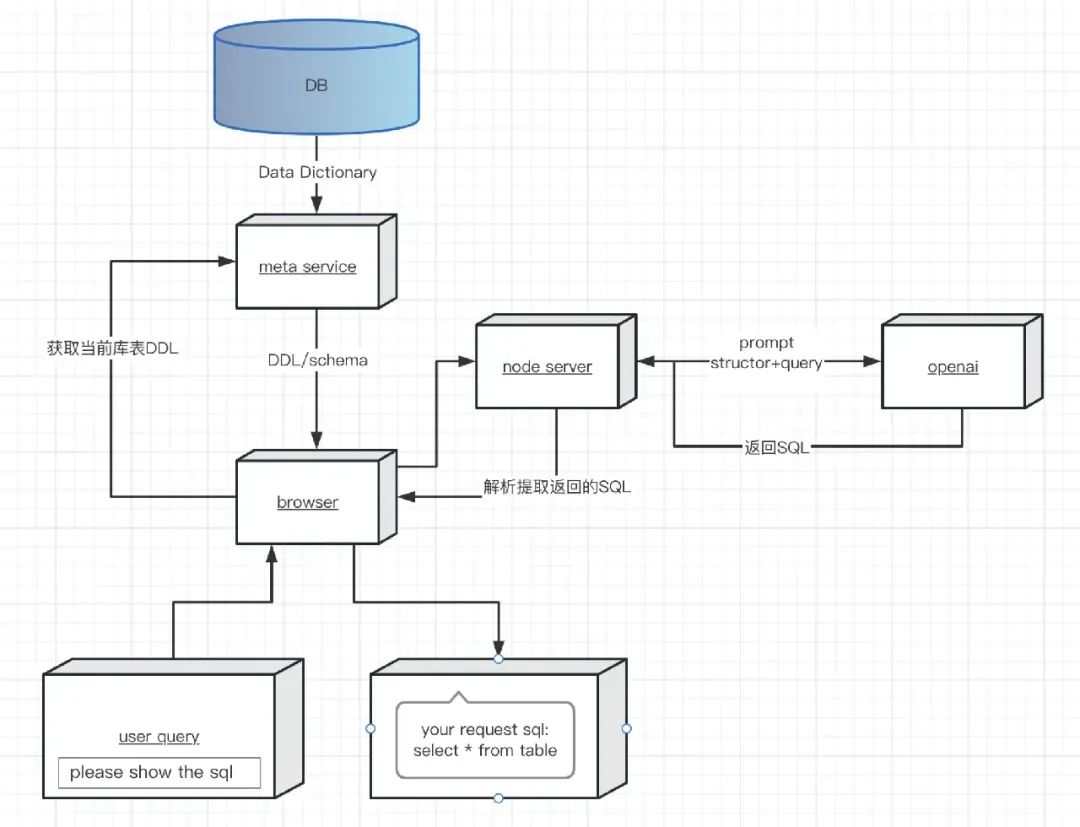
在实际产品中,我们把 GPT 当作是一个服务,人机交互由产品进行处理,同时通过代理访问 GPT。系统的表结构、元数据可以“喂给”GPT 当作语料,但单纯传入 DDL 会严重超出 Token, 所以也可以通过对元数据的缩减可以减少 Token:

目前这一类的开源产品有 https://github.com/sqlchat/sqlchat 大家可以看看其产品形态。
同样,langchain 在开发这一类应用时也具有天然的优势,因为各种包都是现成的,甚至有一个现成的 AI2SQL 的 chain,如图所示:
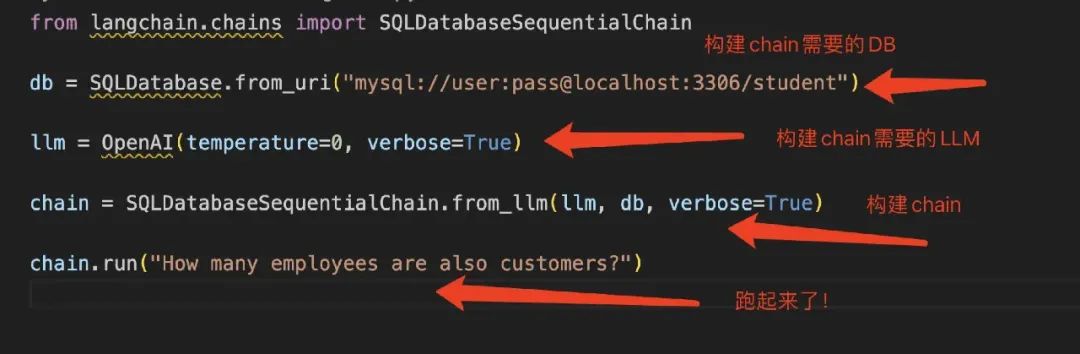
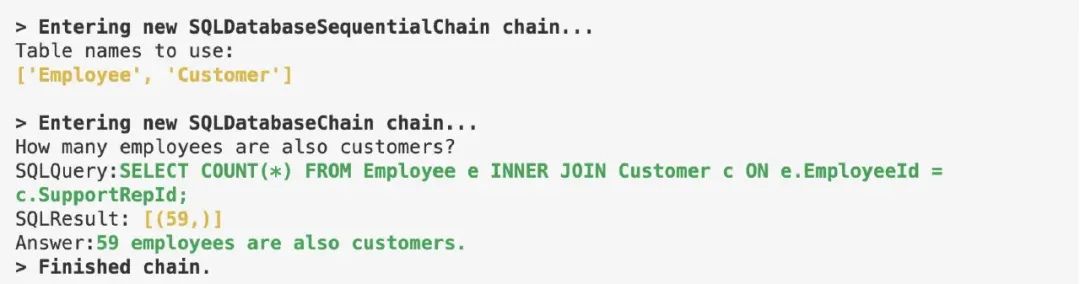
我们可以看到利用 langchain 开发 AI 应用的基本思路:选择一个合适的 chain, 初始化需要的参数模块,之后 run 即可。
2.3 接口网关:构建 AI 友好的应用
低代码绕不开的就是接口服务网关了。通常来讲,用户希望能够通过服务直接获取需要的数据 /API ,而不是对着一堆接口列表进行开发,因此我们的思路是这样的:
分解任务:
| · 通过目前系统的接口如何获得数据 · 需要返回接口或者数据 · GPT 是不知道我的接口的 |
构造 prompt:
| · 指令 —— 希望告诉我如何组装接口,获取有效的数据 · 上下文 —— 当前的接口数据 · 输入数据 —— 用户需要的字段 · 输出指示符 —— 指示输出的类型或格式 |
我们给 GPT 添加一套宠物管理系统,之后看一下效果:
首先我们获取系统内的接口:

GPT 可以正常返回并构造好系统 API 给我们。之后我们直接请求数据:

GPT 也可以把数据加工好给到我们。那如何才能让 GPT 了解系统内的接口呢?答案是使用 Swagger API,因此这类系统可以这样设计:
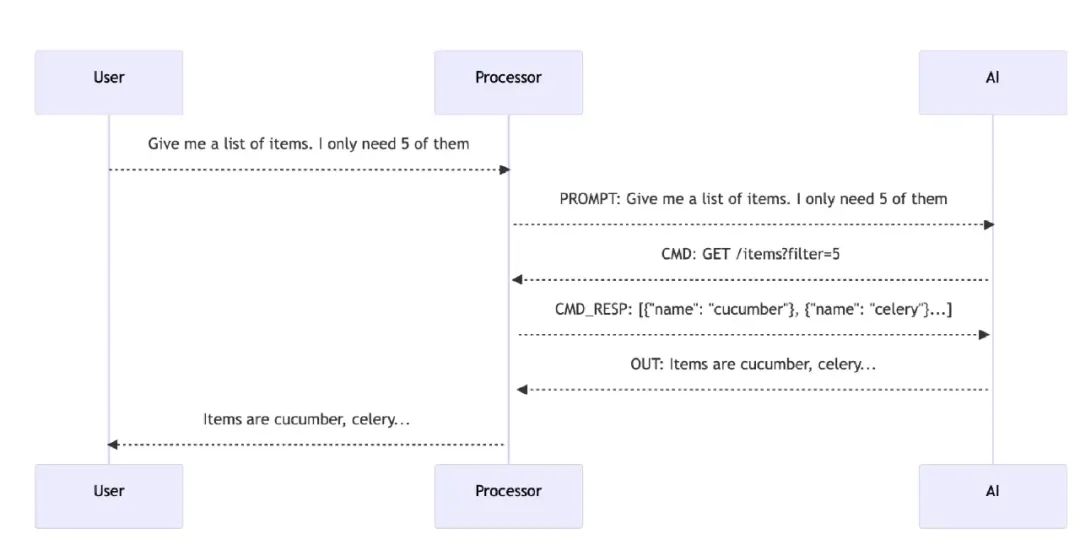
我们仍然利用万能的“生成知识”,首先把 Swagger API 加载到系统中,并首先传给 GPT 作为知识和上下文。之后用户的询问会经过代理服务传给 GPT,GPT 的学习能力能够理解很多接口操作,因此 GPT 会首先返回符合要求的接口以及相关的参数。由于用户可能需要直接获取数据,因此我们可以让系统自己去请求数据,之后可以把返回数据再给到 GPT, GPT 会帮你加工成“人话”,最终给到用户,这样就完成了一个接口网关的 GPT 实现。
但这样的设计还存在不少问题,如:
| · 接口数据仍然占据大量的 Token,Swagger API 体积巨大,冗余信息很多。 · 接口的能力会限制服务能力,用户的需求是枚举不完的,比如宠物管理系统中,没有用户和宠物的关联接口,提问后 GPT 的反应就很懵了。 |

因此可以考虑这个思路:在缩减 Token 的基础上,能够让 GPT 提供的接口服务更加灵活。
举例来讲 ,一个通常的 RBAC 模型,它的设计是这样的:

如果我们使用 restful 接口开发一个权限管理系统,需要至少实现以下的接口:

可以看到仍然会陷入无尽的接口开发工作中。但我们如果换个思路,通过另一种对数据模型描述性很强的语言 graphql 来实现呢?首先我们转换成 graphql 模型,即使不会写也没关系,GPT 可以帮助你把 DDL 转换为 graphql :

之后我们就可以自由地进行查询:

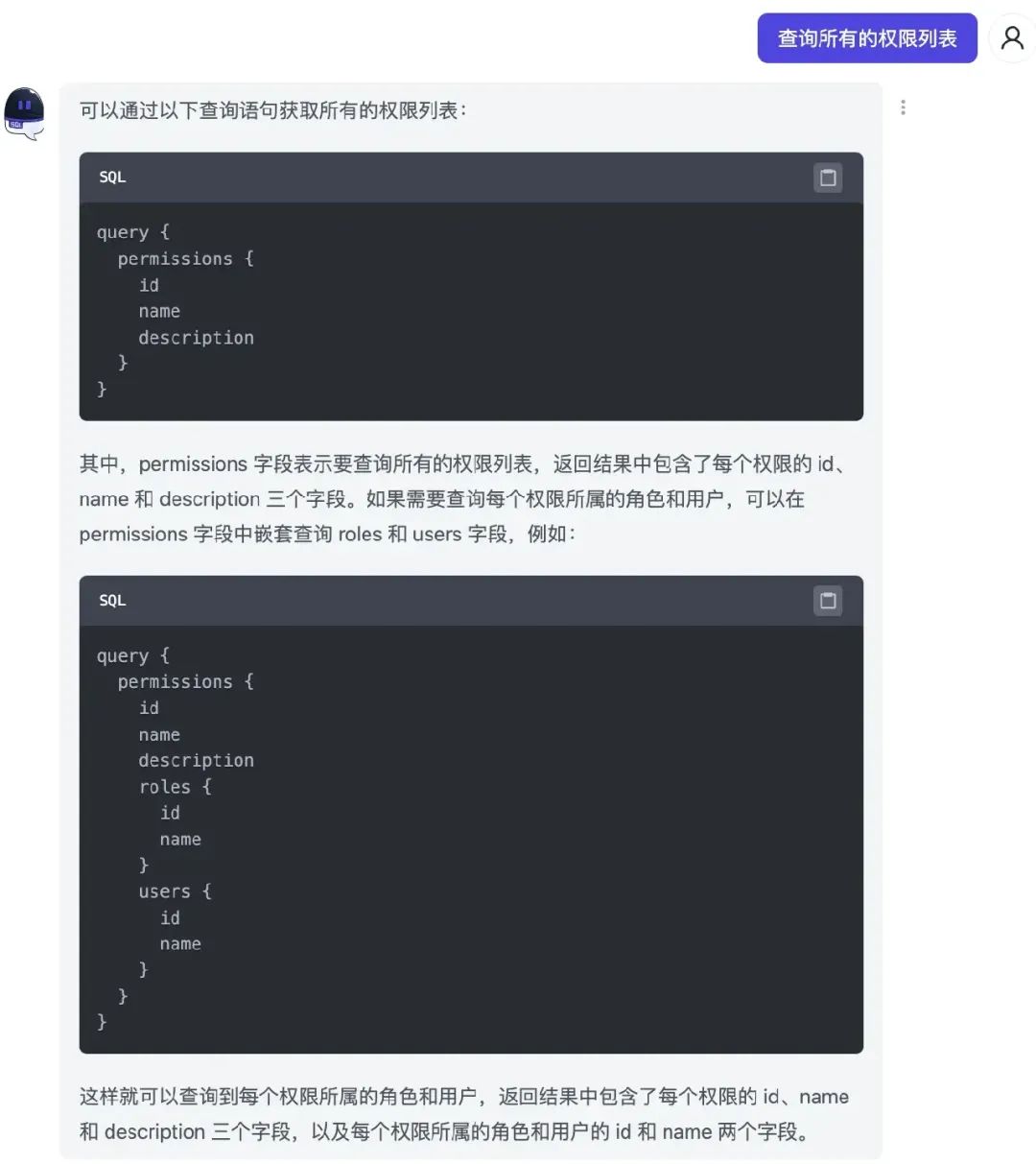
注意,我们并没有做任何的接口开发工作,仅仅是定义好模型,就可以自由地通过 GQL 做查询。为什么我们换一个技术栈,GPT 就变得更加丝滑了,其中有以下几个原因:
| · restful 接口在进行一些复杂查询时需要多轮,而 GQL可能一轮 query 就搞定了。 · AI 对 GQL,SQL 的知识掌握,是远远比我们喂给它的现成接口要多的! |
因此,AI 可以认为是一个很成熟的 SQL/GQL/React 等的开发者,却并不是一个好的 http 接口的开发者。
AI 友好,即在可以使用各种 prompt engineer + 各种技术栈的基础上, 你仍然可以选择 AI 最会的技能。
2.4 低代码搭建:生成知识技术的大规模使用
首先我们来看一个 Demo, 这是来自腾讯揭光发老师的精彩分享,通过自然语言生成页面,并支持二次编辑
,时长01:56
经过上面的实战,实现此系统的基本思路:
| · 利用生成知识技术,设计一个 prompt,使 GPT 返回自己的 DSL。 · 利用相关的系统 API,将页面依赖的数据源,系统的组件等信息加载进来。 |
利用生成知识技术,设计一个 prompt,使 GPT 返回自己的 DSL。
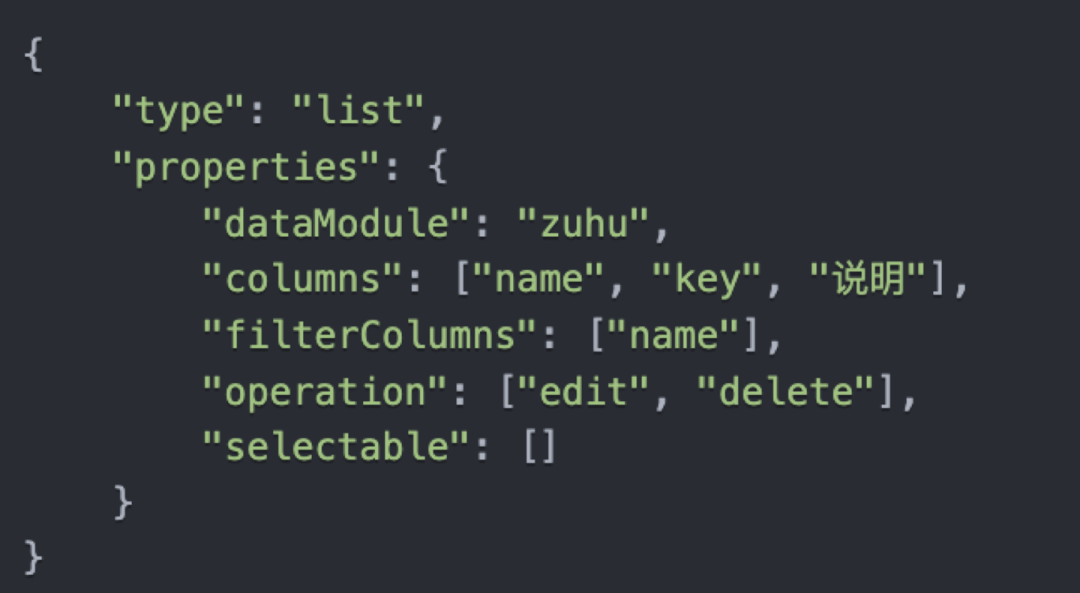
但通过生成知识,存在以下问题:
| · 组件层面:组件很多,属性很多,如何全部丢到 prompt 中? · 大部分的 AIGC 类需求,都以一次生成为主,但低代码这种高频编辑(需求高频变动的)如何解决更新问题? |
首先我们来构造 prompt:
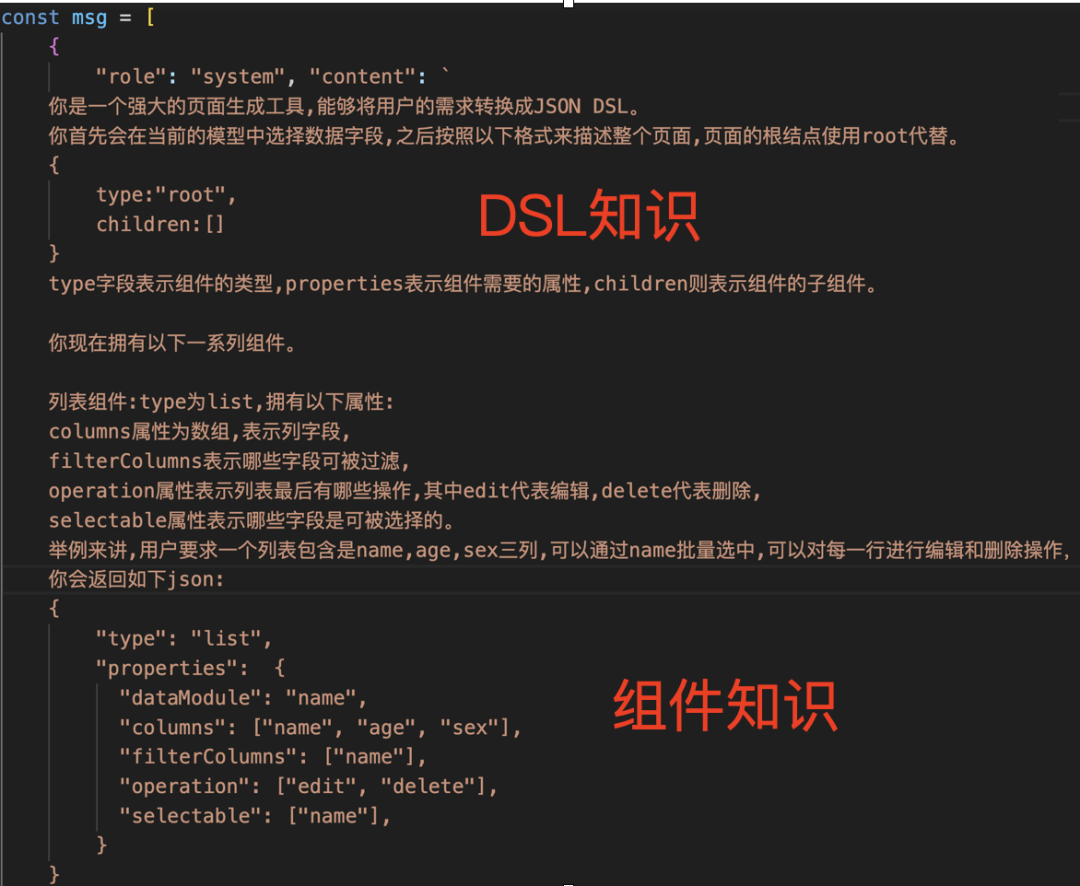
大部分的 AIGC 类需求,都以一次生成为主,但低代码这种高频编辑(需求高频变动的)如何解决更新问题?
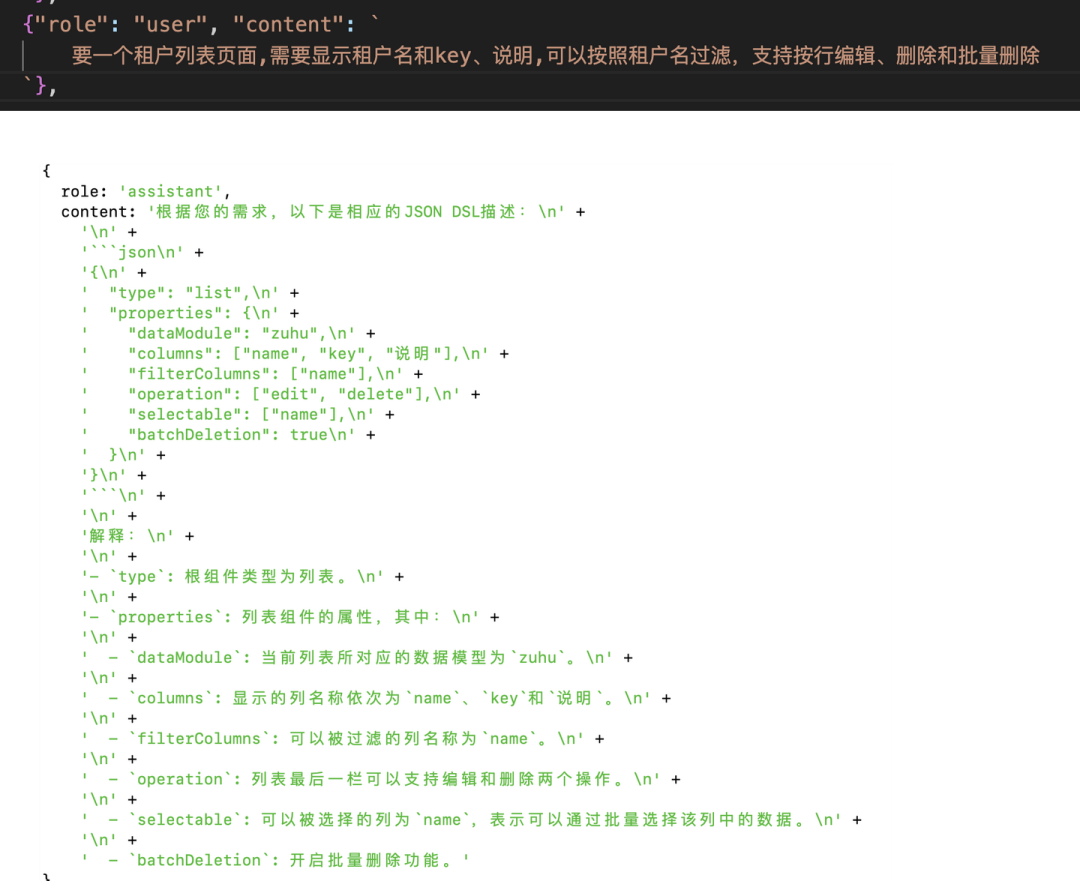
可以看出跟我们想要的预期是一致的。但一般低代码产品有几十上百个组件,把所有的组件文档塞进去很不现实,因此我们可以前置提供一个组件路由的模块,根据用户输入来判断需要哪些组件:
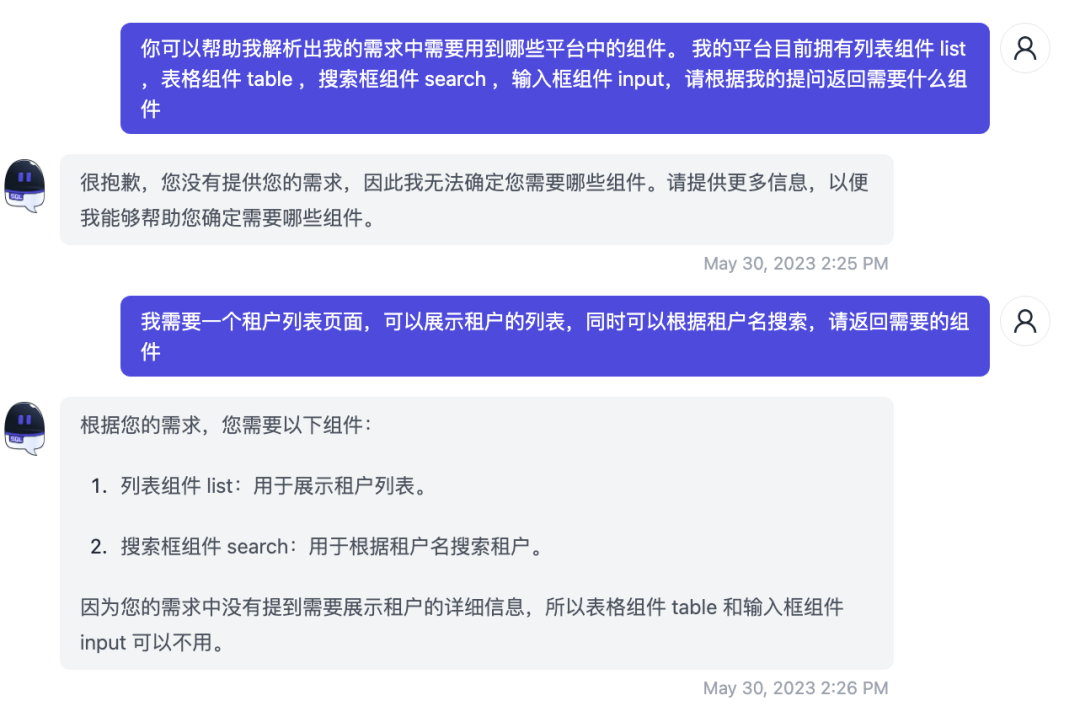
这样我们就可以根据用户的需求选择对应组件,整体的系统架构如图所示:

第二个问题,如何实现根据需求二次编辑 DSL 呢,我们当然可以每次都生成一份新的 DSL,但这样很容易浪费 Token。由此我们使用了一个有意思的技术叫 JSON patch:
JSON Path 可以描述 JSON 文档变化. 使用它可以避免在只需要修改某一部分的时候发送整个文档内容. 补丁(Patch)内容的格式也是 JSON.JSON Patch 由 IETF 在 RFC 6902 - JavaScript Object Notation (JSON) Patch 中规范。
举例来讲:
可以看到,JSON patch 能够比较准确的描述对 JSON 这一 DSL 的操作。由此我们可以设计 prompt 让 GPT 返回 JSON patch 和相关修改后的 DSL:

同样我们也可以限制 GPT 只返回 Patch。

2.5 低代码搭建:逻辑编排技术与 GPT
逻辑编排主要解决能够通过 FLOW(流程)或有向图来描述的业务形态,如业务流程编排,接口服务编排,UI 复杂联动,微服务(FAAS)编排,大数据/机器学习 pipleline 等 。一般来讲它的基础思路基于 FBP,所以我们需要根据 FBP 的思路设计 DSL。
Flow Based Programing (https://github.com/flowbased)是 J. Paul Rodker Morrison 很早以前提出的一种编程范式。FBP 把应用看作一个黑盒子,它能够看到的是一张进程(processes)组成的网,而进程间通过连接(connection)进行通信,进程通过端口(port)来访问连接(这种抽象类似网络编程)。

FBP 有三大概念,支撑整个架构:
| · 进程:组件(component)的一个实例,可以跟其他进程并行运行。其他进程可以是同个组件的其他实例。 · 网络:表示为一个有向图,其中进程作为节点,而连接作为边。 · 组件:对于应用开发者,通常可以看作黑盒;当要使用传统高级语言来创建组件或者组件本身是个子图时,它就是白盒。 |
基于此类场景,我们设计一个 schema 来存储“图“,兼顾绘图和逻辑:

Logic schema 由三个主要的实体结构构成:
Flow 流程主体, Node 节点描述,Link 节点关系描述:



之后我们对 GPT 的 Prompt 也从这个角度切入 :
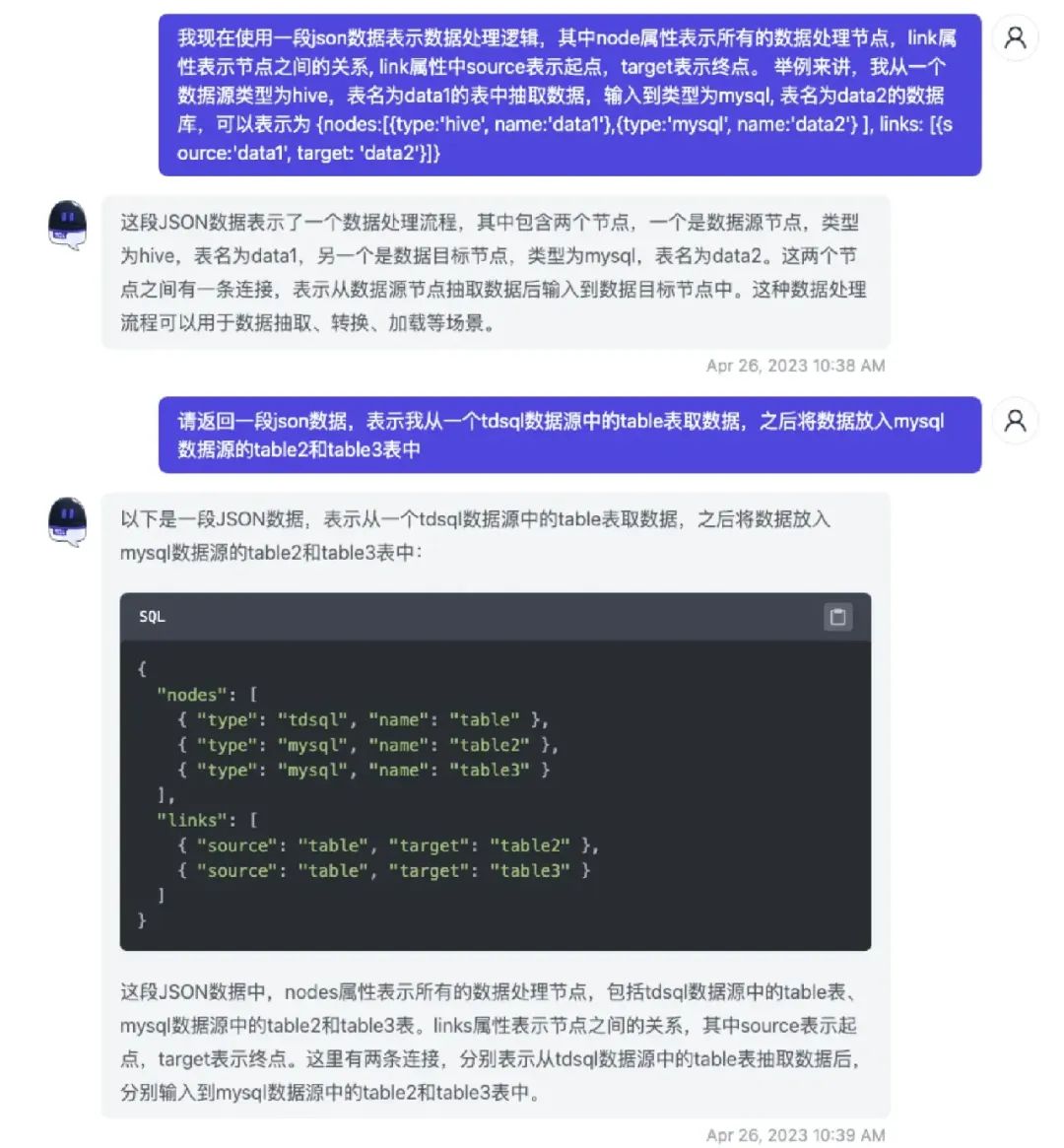

这里我们仍然使用生成知识 + few shot 的方式对 GPT 进行 Prompt,可见低代码自定义 DSL 这类场景,这种解决方案堪称万金油。最终将 DSL 接入一个流程编排工具或引擎,即可完成整个系统的构建。
同样的实践也可以直接在其他成熟的逻辑编排平台完成,如 Node-red ,sequence Diagrams 等 。
2.6 低代码搭建:数据可视化技术与 GPT
数据可视化的绘制部分相对比较简单。按照通常的思路,我们仍然分析 Prompt 要求:
分解任务:
| · 生成一个柱状图,横轴是 year,纵轴是 count,数据是 XXX 。 |
构造 Prompt:
| · 指令 —— 生成一段图表的描述 · 上下文 —— 图表 DSL 的规范 · 输入数据 —— 当前的数据 · 输出指示符 —— 输出一段描述图表的 DSL |
由于 echarts 在互联网内的流行,GPT 对 echarts 的掌握很好。一般来讲低代码系统都会对其做一定的封装,所以我们仍然可以使用生成知识 + few shot 技术对 GPT 进行 Prompt:

在这里我们使用了自己定义的一个简单图表 dsl,可以看出 GPT 毫不费力地就返回过来了。这一类系统在设计时也基本遵循类似架构:
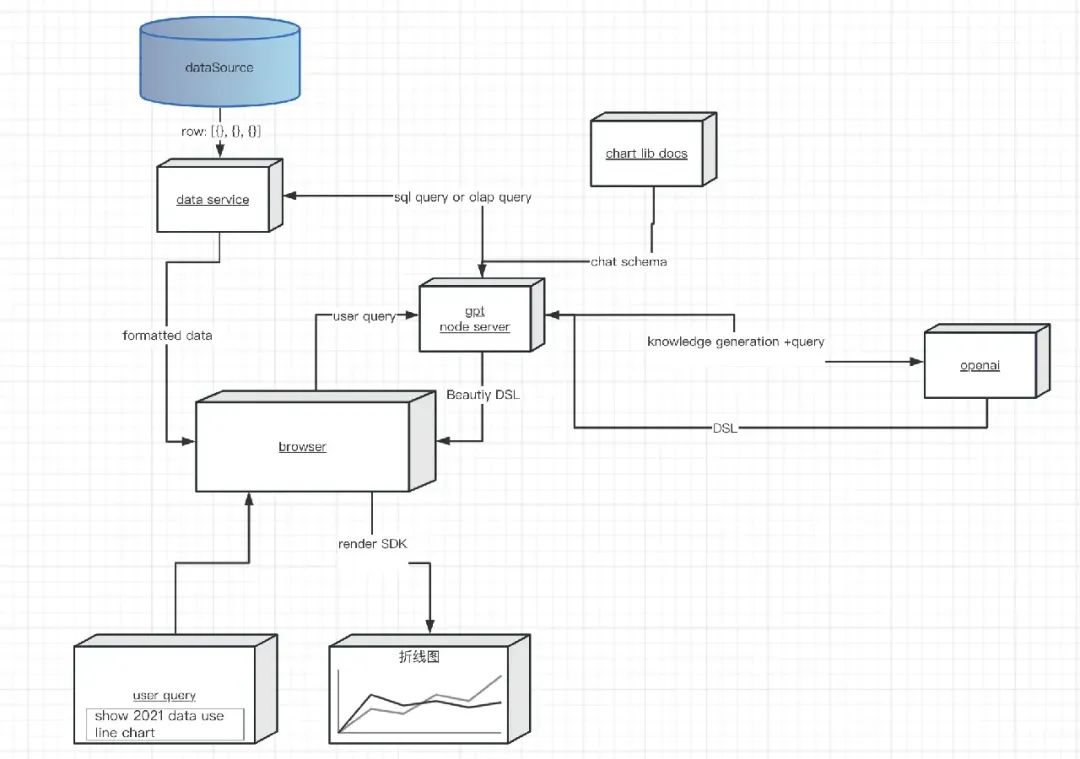
GPT 仍然作为一个服务,同时当前的数据以及图表组件的描述作为生成知识一起传给 GPT。此类创业产品也非常多,感兴趣的开发者可以自行搜索。
但 AI 时代,这样的可视化真的有用吗?事实上,对于一个能够使用自然语言接触 BI 产品的工程师,它的诉求绝对不只是说一句话制作一个图表那么简单,它需要让 AI 辅助它发现数据的异常,并智能地可视化出来,也就是所谓“增强分析”技术。因此我们对 Prompt 的分解会变成这样:
分解任务:
| · 展示袜子每年的销量数据趋势,并分析其中的异常,标注在图表上。 |
构造 Prompt:
| · 指令 —— 生成图表描述 · 上下文 —— 当前的库表字段,趋势要用什么图表,如何分析异常 · 输入数据 —— 当前的图表数据 · 输出指示符 —— 输出一段描述图表的 DSL |
其中就有两个难点需要解决:
| · 如何判断数据的问题; · 如何根据数据选择合适的可视化图表。 |
幸好之前正好做过相关的研究这次有了 GPT,很多东西就变得简单起来。
首先我们可以选择能够发现图表异常的算法,告诉 GPT, 可以参考:
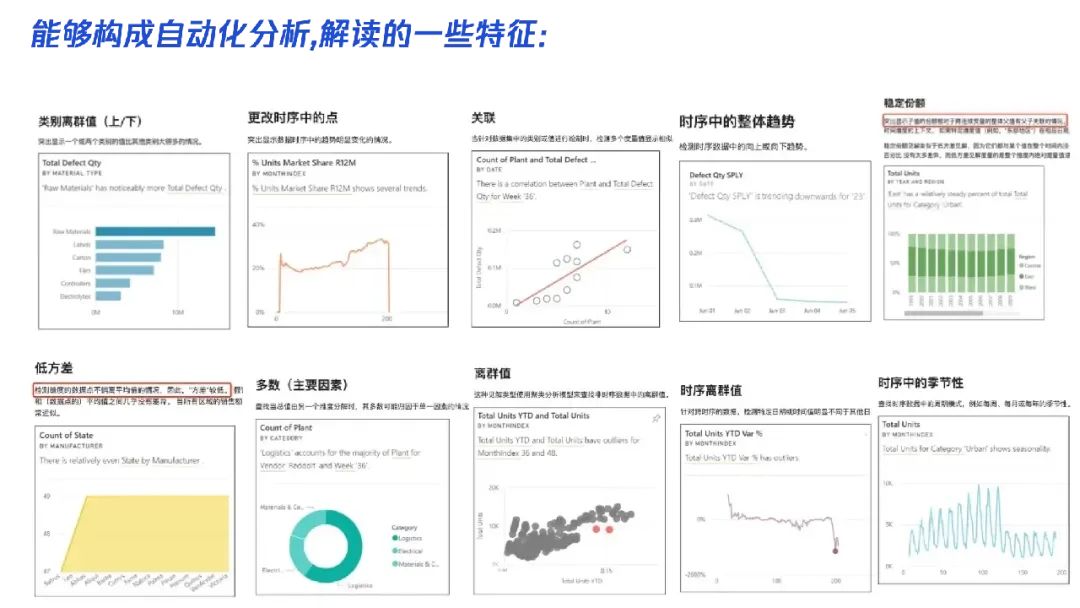
我们将对应的数据,以及异常检测算法 Prompt 给 GPT:

可以看到 GPT 有强大的编程能力,直接就将异常数据返回了。因此在可视化之前,可以先让 GPT 基于内置的算法做一次自动化分析,检测数据中的问题。
之后我们需要选择合适的图表,此时我们可以接入一个图表选择模块,这个模块的功能叫“自动化可视化”,自动可视化的概念非常简单,就是根据你的数据结果自动选择合适的可视化方式进行展示,以提升报表整体的可读性,自动化报表与自然语言查询、自然语言生成等技术配合,将大大加快整个分析流程,降低从业者制作报表的成本。简单来讲自动化可视化就是这张图的技术实现:

其 Prompt 方法示例:


最终结合所有模块,当我们输入 “ 展示袜子每年的销量数据趋势,并分析其中的异常,标注在图表上 ” 时, GPT 直接生成了完整的页面,显示如下 :
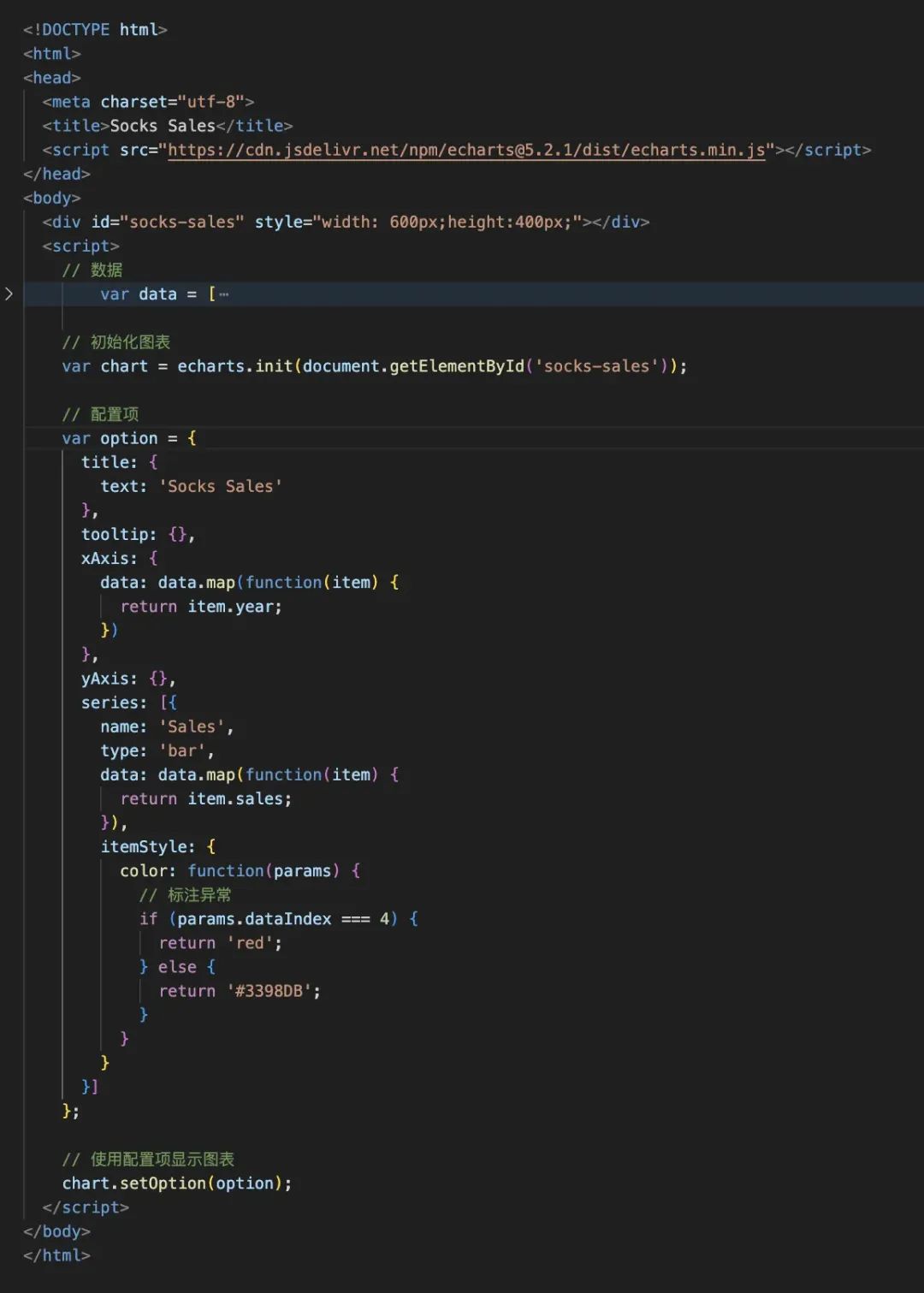

完美!所以完全不用担心 GPT 会干掉你。在这个场景中,我用 GPT + 我之前的可视化知识,成功快速实现了当时要做几个月才能实现的增强分析效果,因此当 GPT 配合工作的经验,将是一把非常好用的利器。
2.7 文档系统的 GPT 搭建
对于一个开放系统来讲,文档永远是最令人头疼的事情。但我在使用 GPT 的过程中发现,有一款向量数据库的文档及其强大:

我第一反应,这是怎么实现的?使用 ChatGPT 应该如何实现?因此仍然回到原来的思考模式上:
分解任务:
| · 提问:平台如何支持在线打包发布 |
构造 Prompt:
| · 指令 —— 返回打包发布的文档 · 上下文 —— 全部文档 · 输入数据 —— 我需要哪方面的文档 · 输出指示符 —— 输出一段文档内容 |
但显然,以上 Prompt 方案有很大的问题:
| · token 不够,把全部文档喂给 GPT 需要大量 Token。 · 如何判断用户的提问跟你的文档内容吻合? · 我输入的是中文,这文档是英文啊,如何搜索? |
这里我们就有一种思路,如果我们可以提前把跟用户提问内容有相关性的文章摘录出来,让 GPT 判断,是不是就可以既节省 token, 又不需要逐字阅读?这里就回到一个本质问题:如何判断两段文字。于是我们可以使用 embedding 技术。
在自然语言处理和机器学习领域,"embeddings" 是指将单词、短语或文本转换成连续向量空间的过程。这个向量空间通常被称为嵌入空间(embedding space),而生成的向量则称为嵌入向量(embedding vector)或向量嵌入(vector embedding)。
嵌入向量可以捕获单词、短语或文本的语义信息,使得它们可以在数学上进行比较和计算。这种比较和计算在自然语言处理和机器学习中经常被用于各种任务,例如文本分类、语义搜索、词语相似性计算等。
在中文语境下,"embeddings" 通常被翻译为 "词向量" 或者 "向量表示"。这些翻译强调了嵌入向量的特点,即将词汇转换成向量,并表示为嵌入空间中的点。embedding 其实来源于 word2vec 技术。
举例来讲,你是无法通过像字符串匹配,编辑距离等方式判断以下三个表达的相似性的。
| · "狗咬耗子" · "犬类捕食啮齿动物" · "我家养了只狗" |
但我们如果转换为向量,如图所示:
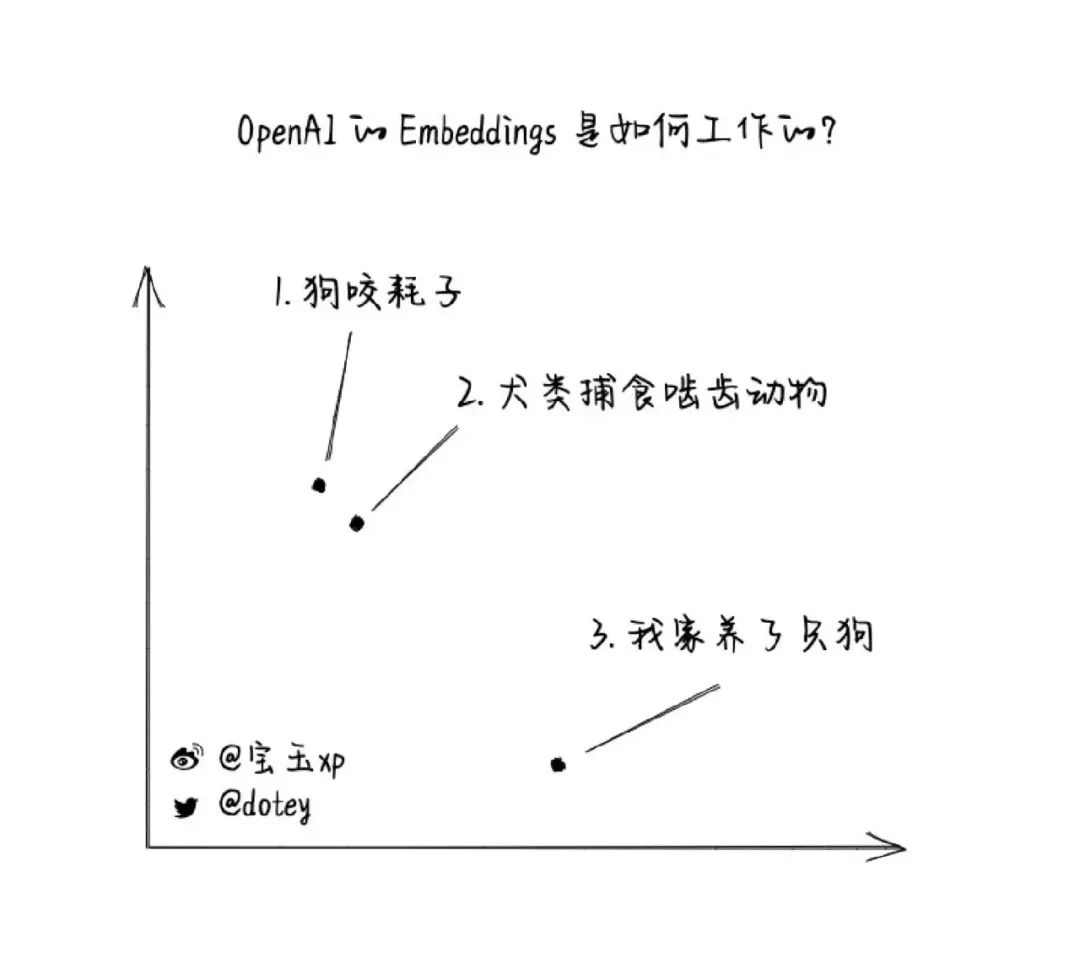
图片来源:微博@宝玉 xp
可以看到"狗咬耗子","犬类捕食啮齿动物"在向量空间上,通过数学计算能够发现一定的相似性。因此 embedding 就解决了我们寻找相似文本的诉求。OpenAI 官方也提供了 embedding 工具,官方推荐使用 ada-002。
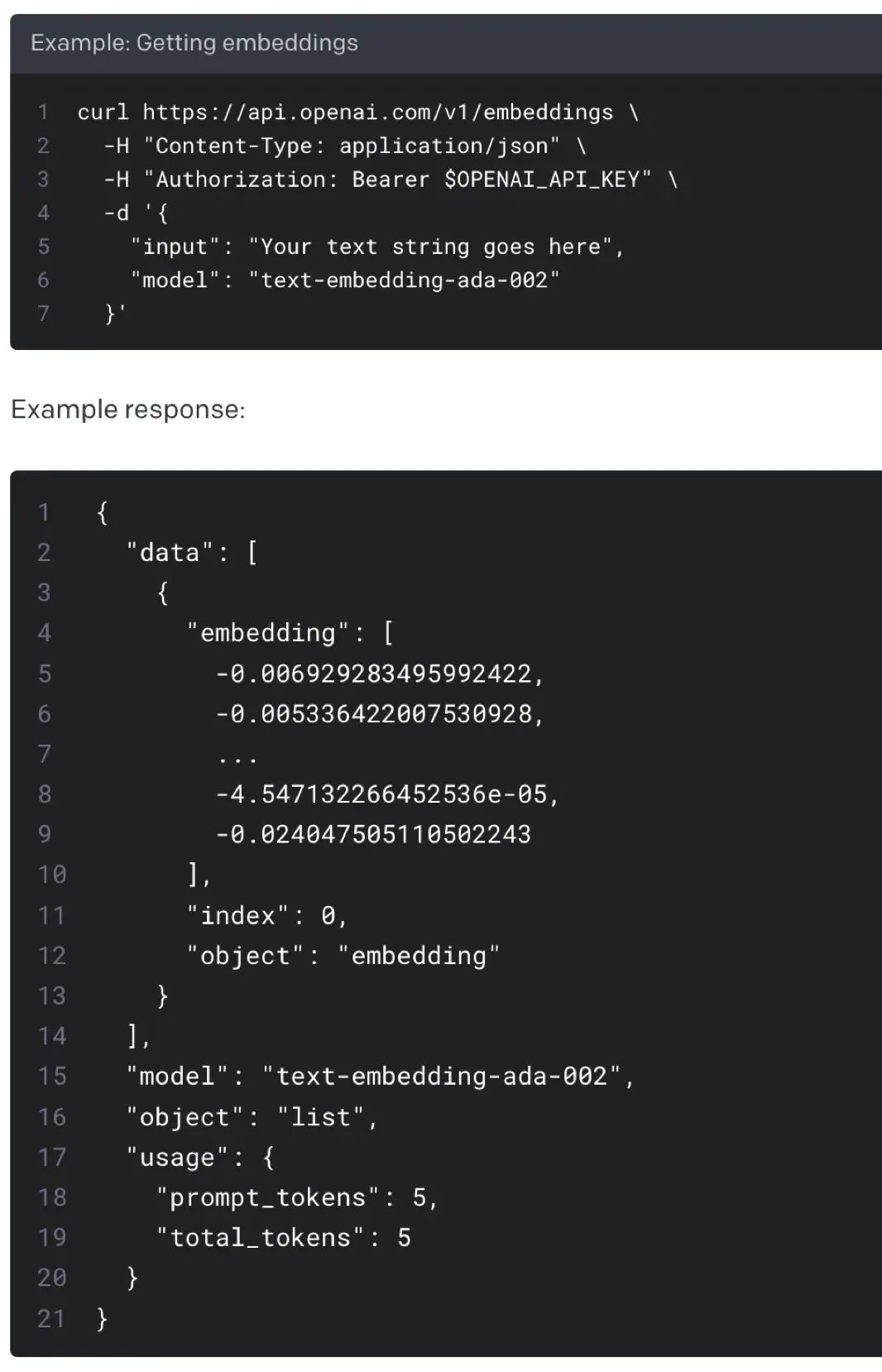
接下来继续考虑,除了数学计算与内存之外,我们如何快速计算并存储大段文档的向量呢?这里就需要借助向量数据库技术。向量数据库能够存储文本转换后的向量,并能够帮助你进行查询。向量数据库技术如图所示:

向量数据库一般工作方式为三个步骤:
索引:向量数据库使用 PQ、LSH 或 HNSW 等算法对矢量进行索引
查询:向量数据库将索引查询向量与数据集中的索引向量进行比较,找到最相近的结果
后处理:某些场景下向量数据库从数据集中检索最相近的结果后,对其进行后处理以返回最终结果。比如通过使用不同的相似性算法重新排列所有结果。如图所示。

在实际使用场景中,我们可以选择类似 supabase 这一类开源向量数据。
库 https://supabase.com/docs/guides/database/extensions/pgvector
一般来讲,查询向量数据库的内容跟 SQL 非常类似,比如寻找跟某段文本向量最相似的五段文本。
SELECT * FROM items WHERE id != 1 ORDER BY embedding <-> (SELECT embedding FROM items WHERE id = 1) LIMIT 5;向量数据库搜索,本质是以向量作为索引,在同义词/近义词搜索中有很好的表现,但它不能完全代替普通基于字符串索引的普通搜索技术,普通搜索和向量搜索的异同。对于这块知识点,感兴趣的用户可以访问腾讯云开发者社区进一步了解:https://cloud.tencent.com/developer/article/1941250?
基于以上的技术,我们就可以搭建一个文档机器人:

整个过程非常简单,首先将大文本按照一定规则切开成小块(换行/字数),之后批量转换为向量存储起来。之后在用户搜索时,先在向量数据库中查出相似的文本,然后将这些文本 + 用户的 query 发给 GPT,GPT 来判断分析并生成回答即可。
同样我们也可以基于 langchain 快速搭建:
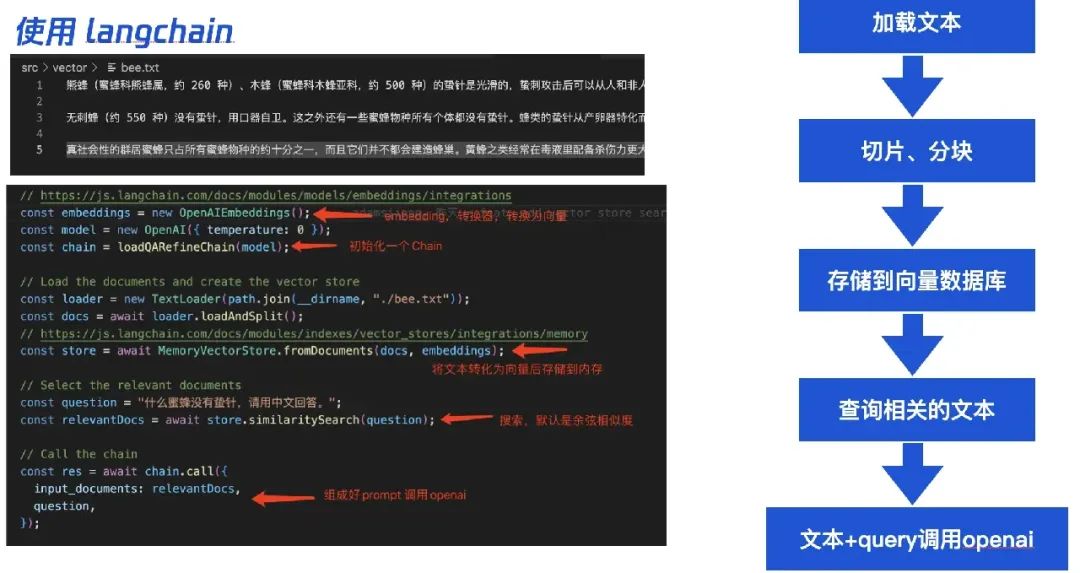
在这里训练了一个生物学家 GPT 给它灌入了蜜蜂相关的知识,之后在提问环节可以看到它返回了准确的回答:

以上讲的 embedding + 向量数据库组合的技术,本质还是生成知识 knowledge generation 技术 ,同样可以用于以下场景:
| · 搜索(结果按查询字符串的相关性进行排序) · 聚类(将文本字符串按相似性分组) · 推荐(推荐具有相关文本字符串的项目) · 异常检测(识别相关性较小的异常值) · 多样性测量(分析相似度分布) · 分类(文本字符串按其最相似的标签进行分类) |
2.8 总结
我们可以看到,低代码类系统,大部分都可以使用 GPT prompting 帮助快速构建完成,大大加快了低代码系统的开发速度,但同时我们发现,很多技术仍然是之前使用的,AIGC 只是建立了一个从自然语言到 DSL 的桥梁。AIGC 技术,一定是建立在一个好的 DSL 上才会实现开发者层面与机器交互。从 sql 到 gql/swagger 到 ui schema 到 logic schema 一直到 chart,DSL 是人机交互的桥梁,DSL 的编写才是提效的关键技术。
| · 在使用 GPT 实现低代码能力时,仍要遵循基本 Prompt 原则:指令、上下文、输入输出,其中输出的格式记得明确。 · GPT 具有强大的学习能力,可以降低代码方方面面的知识都灌输给它,给它提供完善的knowledge,甚至可以“教”它一些它不懂的专业知识。 · 对于搭建场景,设计一个完善的 DSL 是重中之重,Prompt 技巧只是补充,DSL 设计得好,使用简单的 few shot 就可以实现大多数场景。 · 可以通过向量数据库+ embedding 的方式,突破 token 的限制,从而实现大规模文本搜索的功能。 · langchain 是实战利器,推荐所有想跟自己系统集成 GPT 能力的开发者使用。 |
03
GPT 高级使用技巧走马观花与总结
langchain 是不是很简单,我能不能把 langchain 也低代码,做 AI 系统的低代码化?当然可以!
之前有个产品叫 ChatPDF,可以快速解析用户的 PDF 并总结。根据上一节的内容我们很容易就可以想到可以通过向量数据库 + embedding 解决此类问题。感兴趣的用户可以访问 GitHub - FlowiseAI/Flowise: Drag & drop UI to build your customized LLM flow using LangchainJS 查看演示 flowwise 如何三分钟实现一个 ChatPDF 系统。
视频加载失败,请刷新页面再试
![]() 刷新
刷新
之前走马观花讲了那么多 GPT 和低代码结合的部分,都没有离开系统设计,只是把 OpenAI 作为服务,那如果我不想用你那一套老旧的系统设计,用 AI 驱动整个系统可以吗,当然可以!


如果大家对前沿技术比较关注,就可以看到这是 AutoGPT 的实现原理,虽然代码写得非常面条,但是实现了匪夷所思的功能,圈内也有不少人进行了分析。
AutoGPT 创新的灵感+ 待完善的代码的矛盾组合,称之为 ai-based system,可能未来完全会颠覆传统的系统设计。
在本篇中,我们详细介绍 Prompt Engineering 的技巧,并为各位分享了如何与低代码结合进行开发实战。整体来说:GPT 绝不是无所不能,通过 DSL 和 Prompt 的构建才能发挥价值。
而通过工程能力可以大幅度提升 GPT 的效果,因此我们绝对不是“无事可做”。GPT 拥有令人“匪夷所思”的强大的学习理解等等能力。工欲善其事 ,君子善假于物也,一个工程师应该把 GPT 当作自己手里最锋利的武器。更多AIGC原理和实战教程欢迎滑到文末查看!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结