您现在的位置是:首页 >其他 >Redis - 缓存雪崩,缓存穿透,缓存击穿网站首页其他
Redis - 缓存雪崩,缓存穿透,缓存击穿
Redis是一个完全开源的,遵守BSD协议的,高性能的key-value的数据存储结构系统,它支持数据持久化,可以将内存中的数据保存在磁盘中。不仅支持简单的key-value类型的数据结构,同事还提供list,zset,hash等数据结构存储。Redis还支持master-slave模式的数据备份。最重要的是Redis读写速度快。在实际应用中,Redis会存在缓存雪崩、缓存穿透、缓存击穿等异常情况。
概述
1、缓存雪崩:redis中大量key集体过期
2、缓存穿透:大量请求根本不存在的key
3、缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)
1、缓存雪崩解决方案
- 进行预先的热门词汇的设置,进行key时长的调整
- 实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
- 使用锁机制
2、缓存穿透解决方案
- 对空值进行缓存
- 设置白名单
- 使用布隆过滤器
- 网警
3、缓存击穿解决方案
- 进行预先的热门词汇的设置,进行key时长的调整
- 实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
- 使用锁机制(只有一个线程可以进行热点数据的重构)
Redis缓存中间件工作原理:
客户端Client发起一个查询请求Request的时候,首先去Redis缓存中查询,如果数据在Redis缓存中存在,则直接将缓存中的数据返回给客户端;如果数据在缓存中不存在,则继续查询数据库DB,如果数据在数据库DB中存在,则将该数据放入Redis缓存中,并返回给客户端Client,如果数据在数据库DB中也不存在,则直接返回null给客户端Client
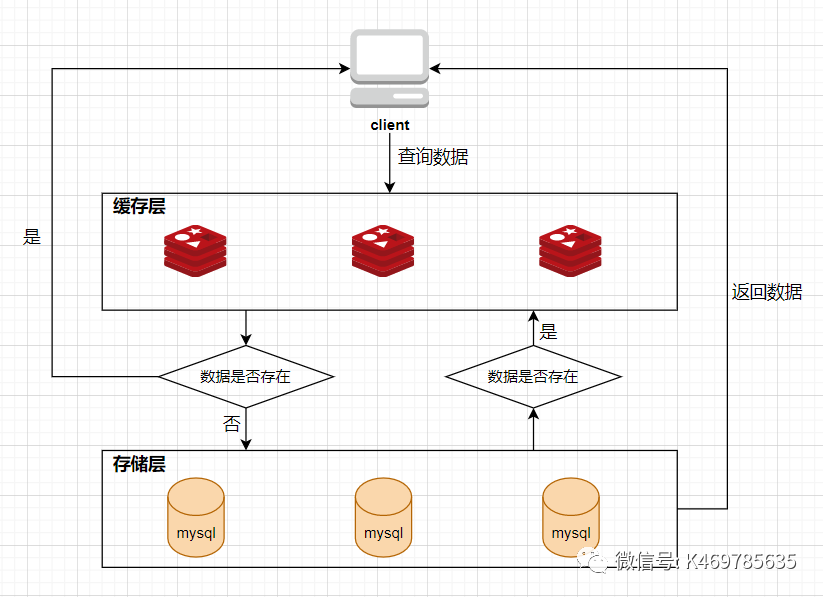
缓存雪崩,缓存穿透,缓存击穿3者出现的根本原因:Redis命中率下降,请求直接打在DB上
正常情况下,大量的资源请求都会被redis响应,在redis得不到响应的小部分请求才会去请求DB,这样DB的压力是非常小的,是可以正常工作的(如下图)

如果大量的请求在redis上得不到响应,那么就会导致这些请求会直接去访问DB,导致DB的压力瞬间变大而卡死或者宕机
1、大量的高并发的请求打在redis上
2、这些请求发现redis上并没有需要请求的资源,redis命中率降低
3、因此这些大量的高并发请求转向DB(数据库服务器)请求对应的资源
4、DB压力瞬间增大,直接将DB打垮,进而引发一系列“灾害”
| 现象 | 缓存雪崩 | 缓存穿透 | 缓存击穿 |
| 资源是否存在DB数据库服务器中 | ✅ | ❎ | ✅ |
| 资源是否存在Redis中 | ❎ | ❎ | ❎ |
| redis没有对应资源的原因 | 大部分key集体过期 | 根本不存在该资源(DB也没有) | 某个热点key过期 |
| 根本原因 | 大量的高并发的请求打在Redis上,但是发现Redis中并没有请求的数据,redis的命令率降低,所以这些请求就只能直接打在DB(数据库服务器)上,在大量的高并发的请求下就会导致DB直接卡死、宕机 | ||
一、缓存雪崩
缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者Redis直接宕机了,导致大量的查询请求全部到达数据库,造成数据库查询压力骤增,甚至直接挂掉,从而导致整个系统崩溃,引发雪崩一样的连锁效应
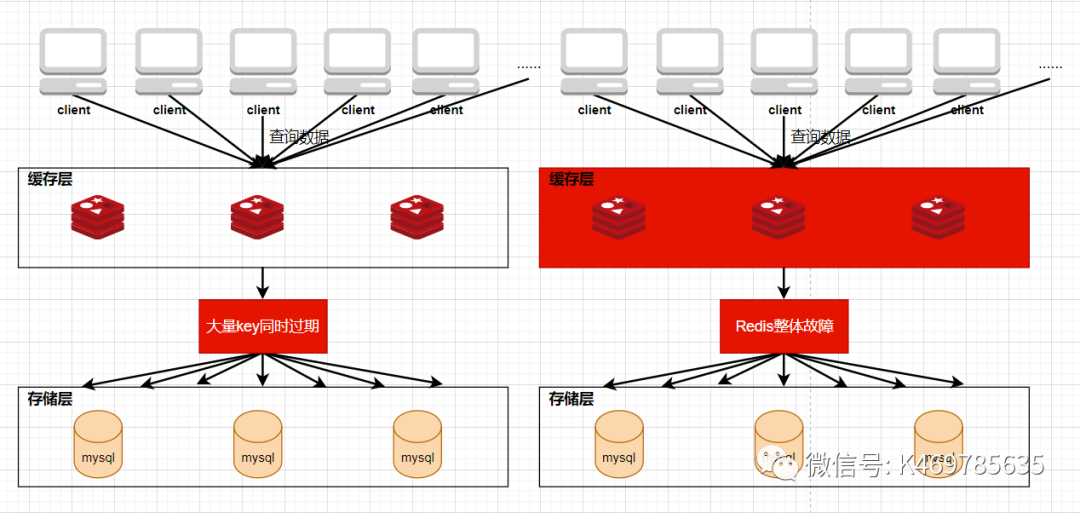
问题原因
1、大量缓存数据同时过期,导致本应请求到缓存的需重新从数据库中获取数据
2、 Redis本身出现故障,无法处理请求,那自然会再请求到数据库那里
解决方案
1、针对大量key同时过期
【1】将失效时间分散开;通过使用自动生成随机数、微调、均匀设置等方式使得key的过期时间是随机的,防止集体过期
【2】使用多级架构;使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强
【3】设置缓存标记;记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去跟新实际的key(采用定时任务或者消息队列的方式进行redis缓存更新或移除等)
【4】添加互斥锁;使得构建缓存的操作不会在同一时间进行
2、针对redis发生故障
【1】在预防层面,通过主从节点方式构建高可用集群,实现主Redis挂掉后,其他从库快速切换为主库,继续提供服务
【2】为了防止数据库被大量请求搞崩溃,可以采用服务熔断或者请求限流方式。服务熔断相对粗暴一些,停止服务直到Redis服务恢复,请求限流相对温和一些,保证一些请求可以处理。
二、缓存穿透
缓存穿透是指数据既不在Redis缓存中,也不在DB数据库中,这样导致每次请求过来时,在Redis缓存中找不到对应的key后,每次都要去DB数据库中再查询一次,发现DB数据库中也不存在,相当于进行2次无效的查询。
这样请求就可以绕过Redis缓存直接查询DB数据库,如果这事有黑客恶意攻击系统,就可以使用空值或者其他不存在的值进行频繁请求,就会对数据库造成较大压力,甚至挂掉

解决方案
1、缓存空值或者默认值
如果从Redis缓存中取不到数据,在DB数据库中也没有取到,仍把结果进行缓存,同时设置一个较短的过期时间
2、非法请求限制
参数校验,鉴权校验,一开始把大量的非法请求拦截在外,不允许这些请求到达Redis、DB上
3、布隆过滤器
布隆过滤器,就是一种数据结构,它是由一个长度为m bit的位数组与n个hash函数组成的数据结构,位数组中每个元素的初始值都是0。在初始化布隆过滤器时,会先将所有key进行n次hash运算,这样就可以得到n个位置,然后将这n个位置上的元素改为1。这样,就相当于把所有的key保存到了布隆过滤器中了。
举个例子,比如我们一共有3个key,我们对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,结果如下图:

这样,当客户端查询时,也对查询的key做3次hash运算得到3个位置,然后看布隆过滤器中对应位置元素的值是否为1,如果所有对应位置元素的值都为1,就证明key在库中存在,则继续向下查询;如果3个位置中有任意一个位置的值不为1,那么就证明key在库中不存在,直接返回客户端空即可。如下图:
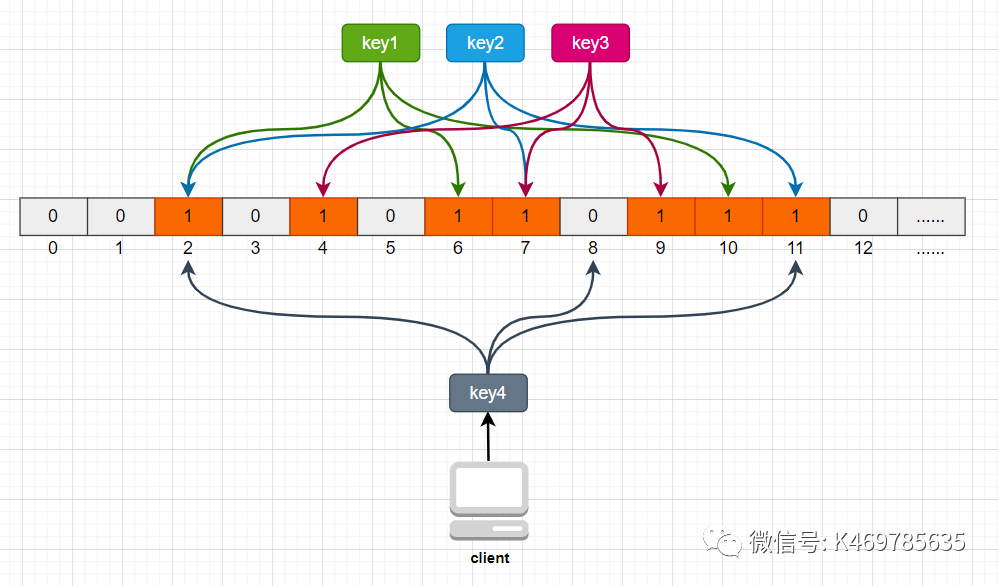
当客户端查询key4时,key4的3次hash运算中,有一个位置8的值为0,就说明key4在库中不存在,直接返回客户端空即可。
所以,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。如下图:
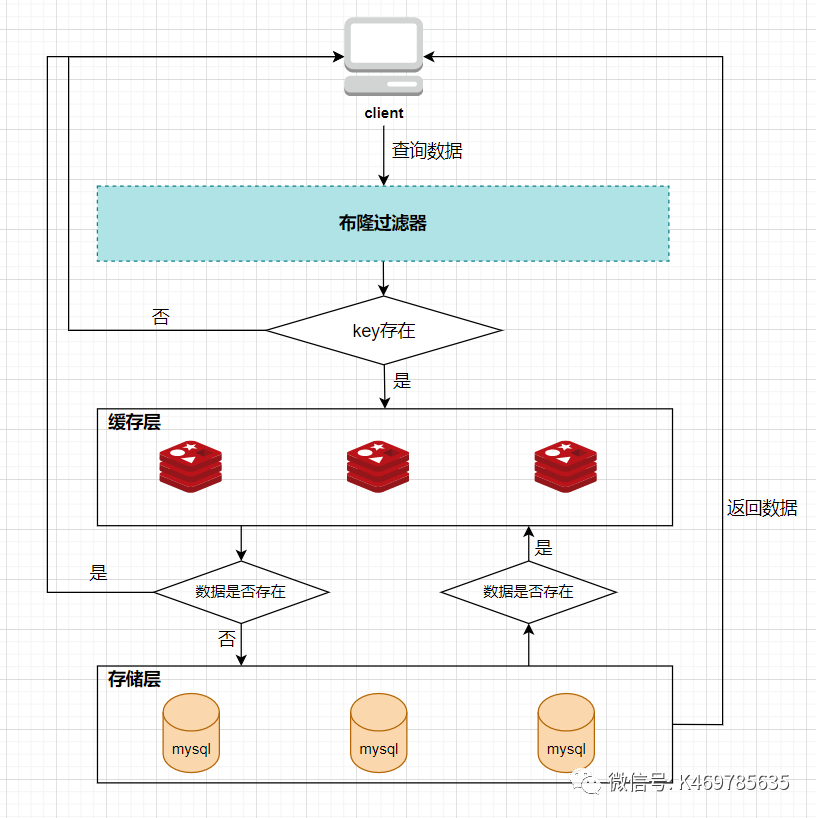
布隆过滤器的好处就是解决了第一种缓存空值的不足,但布隆过滤器也存在缺陷,首先,它有误判的可能,比如在上面客户端查询key4的图中,假如key4经过3次hash运算得到的位置分别是2/4/6,由于这3个位置的值都是1,所以,布隆过滤器就认为key4在库中存在,进而继续向下查询了。所以,布隆过滤器判断存在的key实际上可能是不存在的,但布隆过滤器判断不存在的key是一定不存在的。它的第二个缺点就是删除元素比较难,比如现在要删除key2这个元素,那么需要将2/7/11三个位置的元素值改为0,但这样就会影响到key1和key3的判断
三、缓存击穿
缓存击穿是指当缓存中某个热点数据过期了,在该热点数据重新载入缓存之前,有大量的查询请求穿过缓存,直接查询数据库。这种情况会导致数据库压力瞬间骤增,造成大量请求阻塞,甚至直接挂掉
缓存击穿一般出现在高并发系统中,是大量用户同时请求到Redis缓存中没有但DB数据库中有的数据。也就是同时读缓存没读到数据,又同时取DB数据库中取数据,引起数据库压力瞬间增大
缓存雪崩 和 缓存击穿区别
缓存击穿是指同一条数据,缓存雪崩是不同数据都过期了,很多数据都查询数据库
解决方案
1、设置热点key的时候,不给key设置过期时间
在设置热点key的时候,不给key设置过期时间即可。不过还有另外一种方式也可以达到key不过期的目的,就是正常给key设置过期时间,不过在后台同时启一个定时任务去定时地更新这个缓存

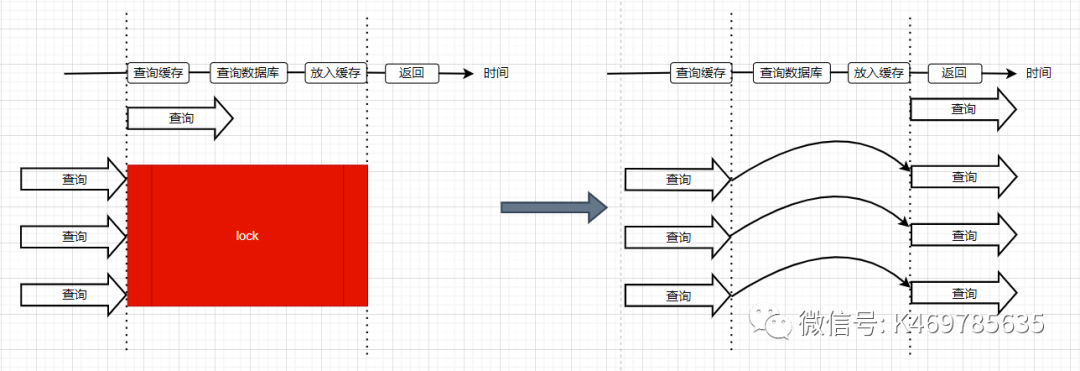
2、使用分布式锁,保证同一时刻只能有一个查询请求重新加载热点数据到缓存中
使用了加锁的方式,锁的对象就是key,这样,当大量查询同一个key的请求并发进来时,只能有一个请求获取到锁,然后获取到锁的线程查询数据库,然后将结果放入到缓存中,然后释放锁,此时,其他处于锁等待的请求即可继续执行,由于此时缓存中已经有了数据,所以直接从缓存中获取到数据返回,并不会查询数据库

总结







站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结