您现在的位置是:首页 >技术教程 >RPC通用爬虫网站首页技术教程
RPC通用爬虫
简介RPC通用爬虫
RPC通用爬虫
一、项目案例

- 测试网址: aHR0cDovL3d3dy5mYW5nZGkuY29tLmNuL3NlcnZpY2UvYnVsbGV0aW5fbGlzdC5odG1sP3R5cGVhPWI2N2MzYjhhZGJkY2U3NGQ=
二、Rpc原理解析
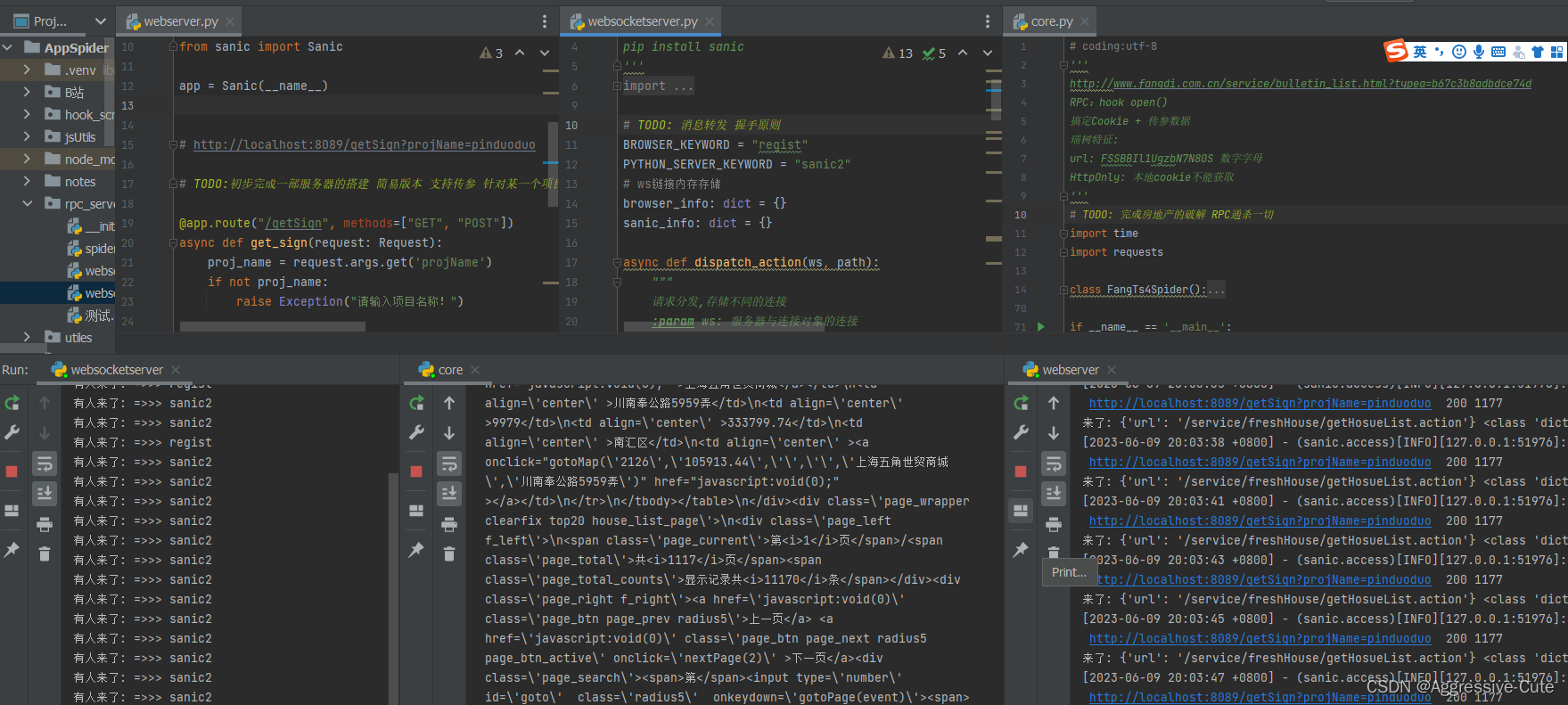
图解关系:
主要包括,爬虫程序、Web服务器、WebScoket服务器、浏览器
核心流程:
爬虫程序调用服务器,可传入参数给服务器,服务器接收到参数后创建一个WS连接,连接到WebSocket服务器;WebSocket服务器其实什么都没有做,就是将消息传递浏览器。因为我们提前替换一些代码,相当于进行hook(找到参数加密解密逻辑,然后利用window定义全局变量),后续传递消息给浏览器,让它帮助我们完成加密解密的工作。将加密参数或是解密参数结果直接返回,发送给WebSocket服务器,最后经过Web服务器返回给我们的爬虫,继续请求服务器获取数据。
启动顺序:
1.WebSocket服务器;
2.断点浏览器,注入JS代码 建立与WS的连接;
3.Web服务器开启等待请求,建立WS连接;
4.Spider调用服务器接口;
三、Rpc代码分享
-
WebSocket服务器
''' 模块依赖 pip install websockets pip install sanic ''' import re import asyncio import websockets # TODO: 消息转发 握手原则 BROWSER_KEYWORD = "regist" PYTHON_SERVER_KEYWORD = "sanic2" # ws链接内存存储 browser_info: dict = {} sanic_info: dict = {} async def dispatch_action(ws, path): """ 请求分发,存储不同的连接 :param ws: 服务器与连接对象的连接 :param path: 请求路径 :return: """ # action_name 标识 连接对象身份 ... re_result = re.compile("/(?P<action_name>.*?)?name=(?P<proj_name>.*)").search(path) action_name: str = re_result.group("action_name") proj_name: str = re_result.group("proj_name") # 连接保存 对应存储连接对象 {} if action_name == PYTHON_SERVER_KEYWORD: # Python sanic_info[action_name] = ws elif action_name == BROWSER_KEYWORD: # browser browser_info[action_name] = ws return action_name async def handler(ws, path): """ 主要处理ws请求 :param ws:服务器与连接对象的连接 :param path: 请求路径 :return: """ action_name = await dispatch_action(ws, path) print("有人来了: =>>>", action_name) # 收到数据,转发数据 可以基于Json async for msg in ws: #msg 参数 或者是 返回值 # 请求控制 if action_name == PYTHON_SERVER_KEYWORD: # 发送给浏览器 连接对象 await browser_info[BROWSER_KEYWORD].send(msg) # 返回加密结果 elif action_name == BROWSER_KEYWORD: # 发送给服务器 连接对象 await sanic_info[PYTHON_SERVER_KEYWORD].send(msg) async def main(): async with websockets.serve(handler, "127.0.0.1", 8868) as rpcfucktheworld: print("webScoketServer start ...") await asyncio.Future() ''' 启动的顺序很重要 1.websocketserver 2.browser 3.webserver 4.spider process: spider <=> webserver <=> websocketserver <=> browser ''' if __name__ == '__main__': asyncio.run(main()) -
Browser浏览器
(function (){ // 建立连接 const socket = new WebSocket('ws://127.0.0.1:8868/regist?name=ooxx'); // 接收到消息时的回调函数 socket.addEventListener('message', function (event) { const obj = JSON.parse(event.data); // obj 所有的参数 console.log("参数来了:", obj) // 植入js代码搞一波.... window.FUCK1(); const result = { // any you want to return value... "MmEwMD":window.FUCK2(obj.url), "cookie": document.cookie, } console.log("数据打包回家:", result) socket.send(JSON.stringify(result)); }); })() -
WebServer服务器
''' 第三方模块下载: pip install websockets pip install sanic ''' import json import websockets from sanic.request import Request from sanic.response import text from sanic import Sanic app = Sanic(__name__) # http://localhost:8089/getSign?projName=ooxx # TODO:初步完成一部服务器的搭建 简易版本 支持传参 针对某一个项目 @app.route("/getSign", methods=["GET", "POST"]) async def get_sign(request: Request): proj_name = request.args.get('projName') if not proj_name: raise Exception("请输入项目名称!") proj_params: dict = request.json print("来了:", proj_params, type(proj_params)) async with websockets.connect("ws://127.0.0.1:8868/sanic2?name={}".format(proj_name)) as ws: await ws.send(json.dumps(proj_params)) result = await ws.recv() return text(result) if __name__ == '__main__': app.run(host="127.0.0.1", port=8089, debug=True) # spider view -
Spider爬虫程序
import json import requests import time class PinduoduoSpider(): def __init__(self): self.page = 1 self.url = "https://脱敏处理/spike_list" self.headers = { ...... } def get_anti_content(self): anti_content = requests.get("http://脱敏处理/getSign?projName=脱敏处理").json()["data"] return anti_content def task(self): response = requests.get(self.url, headers=self.headers, params={ "page": self.page, "size": "50", "anti_content": self.get_anti_content() }) print(response.json()) def run(self): while True: self.task() print("当前页码:" + "=" * 20 + '>>>', self.page) self.page += 1 time.sleep(2) if __name__ == '__main__': 脱敏处理().run()
四、自我总结
1、关于爬虫这件事:
通过对RPC框架进行学习,我发现如果我们越了解服务器架构,后端开发,运维开发,就越有认知和思想。
例如:Scrapy分布式 采用Redis作为消息队列,可以开启多个Scrapy爬虫程序对指定网站进行数据抓取。优点:支持断点续爬虫,可以持续不断的采集数据,worker处于阻塞状态,等待任务到来然后执行对应的爬虫逻辑,这为抓取成千上万的数据提供了结实的基础。利用Redis里面的集合,我们可以对数据进行去重,从而保证了数据的唯一性;利用Redis里面的列表,我们可以实现消息队列,对请求对象进行排序,更多精彩部分在下期分享。
2.RPC运用场景:
当你找到了参数加密或解密位置,但是其逻辑非常复杂你就可以使用RPC搭建一套服务器框架,快速远程调用获取想要的参数。
3.RPC优缺点:
RPC优点>: 不用逆向了,直接获取结果,直接拿到结果,逻辑非常简单依赖网络协议,各个程序之间的通信。
RPC缺点>: 采集速度太慢,性能不好,速度不够快,只能暂时解决问题,采集更多的数据有一定的困难;必须开启本地浏览器(or selenium模拟),浪费资源。
列,对请求对象进行排序,更多精彩部分在下期分享。
2.RPC运用场景:
当你找到了参数加密或解密位置,但是其逻辑非常复杂你就可以使用RPC搭建一套服务器框架,快速远程调用获取想要的参数。
3.RPC优缺点:
RPC优点>: 不用逆向了,直接获取结果,直接拿到结果,逻辑非常简单依赖网络协议,各个程序之间的通信。
RPC缺点>: 采集速度太慢,性能不好,速度不够快,只能暂时解决问题,采集更多的数据有一定的困难;必须开启本地浏览器(or selenium模拟),浪费资源。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结