您现在的位置是:首页 >技术交流 >ESP32-S3 边缘人工智能|使用加速度计数据和 ESP-DL 识别人体活动网站首页技术交流
ESP32-S3 边缘人工智能|使用加速度计数据和 ESP-DL 识别人体活动
边缘计算是一种分布式计算范例,指在更靠近设备的地方进行数据存储和计算。边缘人工智能(边缘 AI)是边缘计算中一项振奋人心的成果,可以令传统技术更高效地运行,在降低功耗的同时又有更好的性能。训练好的神经网络可以在小型设备上进行推理。边缘 AI 的潜在应用领域包括制造业、医疗保健、零售业、监控、智能家居和金融银行业。
乐鑫提供的 ESP-DL 框架可用于在 ESP32-S3 上部署高性能深度学习模型。
本文将介绍如何读取传感器数据,并使用 ESP-DL 在 ESP32-S3 上部署深度学习模型。
本文分为以下四个部分 :
1. 部署模型
2. 定义模型
3. 运行模型
4. 结论
【ESP-DL 的使用前提】在深入了解 ESP-DL 之前,读者需要:
- 构建和训练神经网络的相关知识(查看深度学习的基础知识)
- ESP-IDF release/v4.4 环境(更多信息,请参考设置 ESP-IDF 环境或 ESP-IDF 工具链)
- 基础的 C 和 C++ 语言应用知识
- 转换成 ESP-DL 格式的模型
1. 部署模型
使用加速度计数据设计卷积神经网络,识别人类活动。
*本文不会重点介绍神经网络的开发和 ESP-DL 格式转换。
1.1 ESP-IDF 项目结构
部署模型的步骤如下:
- 首先,根据 ESP-IDF 标准在 VS Code 中创建一个新项目。有关如何在 VS Code 中创建 ESP32 项目,请参考 ESP-IDF 快速入门。
- 模型转换成 ESP-DL 格式时生成的 .cpp 和 .hpp 文件需放置到当前工作目录中。
- 将所有依赖组件添加到工作目录的 components 文件夹中。
- 添加 ESP-WHO 示例的默认配置 sdkconfig 文件。sdkconfig 文件也可在 GitHub 找到。
项目目录应如下所示:
├── CMakeLists.txt
├── components
│ ├── bus
│ ├── mpu6050
│ └── esp-dl
├── dependencies.lock
├── main
│ ├── app_main.cpp
│ └── CMakeLists.txt
├── model
│ ├── Activity_coefficient.cpp
│ ├── Activity_coefficient.hpp
│ └── model_define.hpp
├── partitions.csv
├── sdkconfig
├── sdkconfig.defaults
├── sdkconfig.defaults.esp32
├── sdkconfig.defaults.esp32s2
└── sdkconfig.defaults.esp32s3
2. 定义模型
按下列步骤和步骤说明在 ‘model_define.hpp’ 中定义模型。在 Netron 中打开模型,会出现图 1 所示内容。
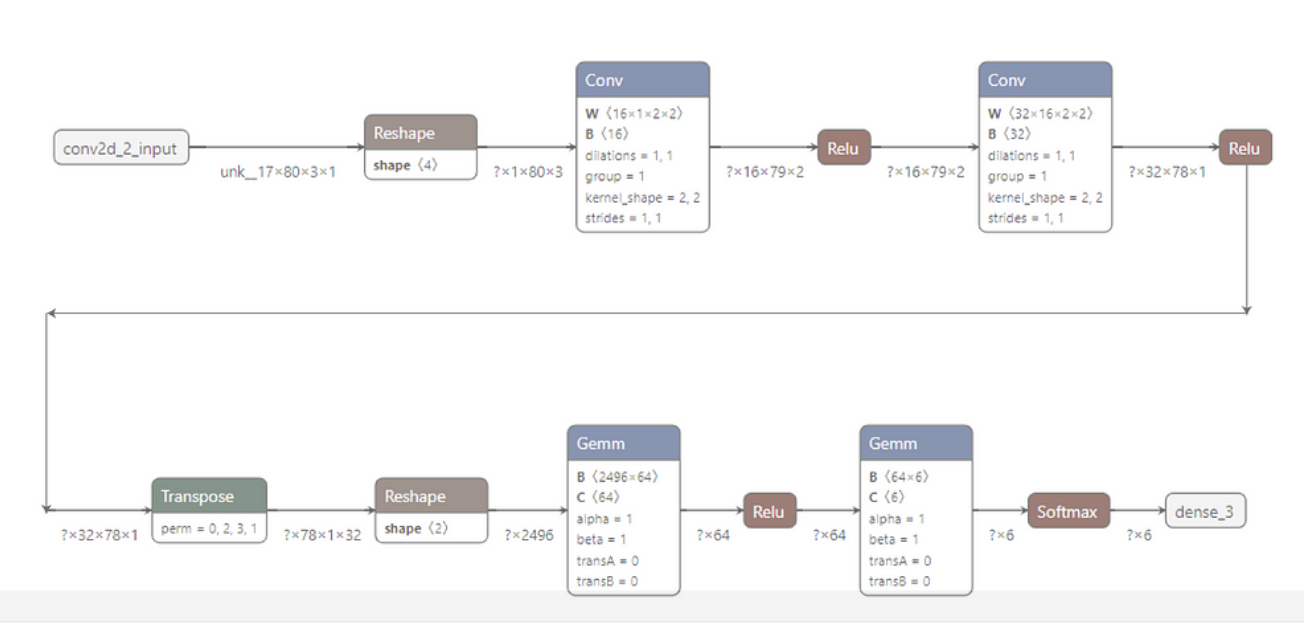
2.1 导入库
#pragma once
#include "dl_layer_model.hpp"
#include "dl_layer_base.hpp"
#include "dl_layer_max_pool2d.hpp"
#include "dl_layer_conv2d.hpp"
#include "dl_layer_concat.hpp"
#include "Activity_coefficient.hpp"
#include "dl_layer_reshape.hpp"
#include "dl_layer_softmax.hpp"
#include <stdint.h>
using namespace dl;
using namespace layer;
using namespace Activity_coefficient; 2.2 声明层
下一步是声明每个层。
- 输入不算是层,因此不在此处定义。
- 除了输出层之外,其他所有层都声明为私有层。
class ACTIVITY : public Model<int16_t>
{
private:
Conv2D<int16_t> l1;
Conv2D<int16_t> l2;
Reshape<int16_t> l3;
Conv2D<int16_t> l4;
Conv2D<int16_t> l5;
public:
Softmax<int16_t> l6; 2.3 初始化层
声明层之后,初始化每个层的权重、偏差、激活函数和形状。
ACTIVITY () :
l1(Conv2D<int16_t>(-13, get_statefulpartitionedcall_sequential_1_conv2d_2_biasadd_filter(), get_statefulpartitionedcall_sequential_1_conv2d_2_biasadd_bias(), get_statefulpartitionedcall_sequential_1_conv2d_2_biasadd_activation(), PADDING_VALID, {}, 1,1, "l1")),
l2(Conv2D<int16_t>(-13, get_statefulpartitionedcall_sequential_1_conv2d_3_biasadd_filter(), get_statefulpartitionedcall_sequential_1_conv2d_3_biasadd_bias(), get_statefulpartitionedcall_sequential_1_conv2d_3_biasadd_activation(), PADDING_VALID, {}, 1,1, "l2")),
l3(Reshape<int16_t>({1,1,2496},"l2_reshape")),
l4(Conv2D<int16_t>(-11, get_fused_gemm_0_filter(), get_fused_gemm_0_bias(), get_fused_gemm_0_activation(), PADDING_VALID, {}, 1, 1, "l3")),
l5(Conv2D<int16_t>(-9, get_fused_gemm_1_filter(), get_fused_gemm_1_bias(), NULL, PADDING_VALID,{}, 1,1, "l4")),
l6(Softmax<int16_t>(-14,"l5")){} 2.4 构建层
下一步是构建每个层。有关构建层的更多信息,请查看每个层的构建函数。
void build(Tensor<int16_t> &input)
{
this->l1.build(input);
this->l2.build(this->l1.get_output());
this->l3.build(this->l2.get_output());
this->l4.build(this->l3.get_output());
this->l5.build(this->l4.get_output());
this->l6.build(this->l5.get_output());
} 2.5 调用层
最后,将层连接起来,通过调用函数一一调用。有关调用层的更多信息,请查看每个层调用函数。
void call(Tensor<int16_t> &input)
{
this->l1.call(input);
input.free_element();
this->l2.call(this->l1.get_output());
this->l1.get_output().free_element();
this->l3.call(this->l2.get_output());
this->l2.get_output().free_element();
this->l4.call(this->l3.get_output());
this->l3.get_output().free_element();
this->l5.call(this->l4.get_output());
this->l4.get_output().free_element();
this->l6.call(this->l5.get_output());
this->l5.get_output().free_element();
}
}; 3. 运行模型
构建好模型后,在 ‘app_main.cpp’ 文件中声明模型输入,并在 ESP32-S3 上运行模型。
3.1 导入库
#include <stdio.h>
#include <stdlib.h>
#include "esp_system.h"
#include "freertos/FreeRTOS.h"
#include "freertos/task.h"
#include "dl_tool.hpp"
#include "model_define.hpp"
#include "i2c_bus.h"
#include "mpu6050.h"
#include "driver/i2c.h"
#include "esp_log.h" 3.2 声明输入
神经网络的输入来自 MPU6050 加速度传感器。读取实时的传感器数据需使用乐鑫的 MPU6050 驱动。每四秒钟,传感器数据便会存储在一个数组中,输入到神经网络中进行预测。
int input_height = 80;
int input_width = 3;
int input_channel = 1;
int input_exponent = -13;
float acc_xyz[240] = {0};
int index_acc=0;
#define I2C_MASTER_SCL_IO 16 /*!< gpio number for I2C master clock */
#define I2C_MASTER_SDA_IO 17 /*!< gpio number for I2C master data */
#define I2C_MASTER_NUM I2C_NUM_0 /*!< I2C port number for master dev */
#define I2C_MASTER_FREQ_HZ 400000 /*!< I2C master clock frequency */
static i2c_bus_handle_t i2c_bus = NULL;
static mpu6050_handle_t mpu6050 = NULL;
extern "C" void app_main(void)
{
i2c_config_t conf = {
.mode = I2C_MODE_MASTER,
.sda_io_num = I2C_MASTER_SDA_IO,
.scl_io_num = I2C_MASTER_SCL_IO,
.sda_pullup_en = GPIO_PULLUP_ENABLE,
.scl_pullup_en = GPIO_PULLUP_ENABLE,
.clk_flags = 0,
};
conf.master.clk_speed = I2C_MASTER_FREQ_HZ;
i2c_bus = i2c_bus_create(I2C_MASTER_NUM, &conf);
mpu6050 = mpu6050_create(i2c_bus, MPU6050_I2C_ADDRESS);
uint8_t mpu6050_deviceid;
mpu6050_acce_value_t acce;
mpu6050_get_deviceid(mpu6050, &mpu6050_deviceid);
printf("mpu6050 device ID is: 0x%02x
", mpu6050_deviceid);
mpu6050_set_acce_fs(mpu6050, ACCE_FS_4G);
while(1){
for (int i=0 ;i<80; i++)
{
mpu6050_get_acce(mpu6050, &acce);
acc_xyz[index_acc]=acce.acce_x;
index_acc=index_acc+1;
acc_xyz[index_acc]=acce.acce_y;
index_acc=index_acc+1;
acc_xyz[index_acc]=acce.acce_z;
index_acc=index_acc+1;
vTaskDelay(50 / portTICK_RATE_MS);
}
index_acc=0;
int16_t *model_input = (int16_t *)dl::tool::malloc_aligned_prefer(input_height*input_width*input_channel, sizeof(int16_t *));
for(int i=0 ;i<input_height*input_width*input_channel; i++){
float normalized_input = acc_xyz[i] / 1.0; //normalization
model_input[i] = (int16_t)DL_CLIP(normalized_input * (1 << -input_exponent), -32768, 32767);
} 3.3 设置输入形状
设置张量中的数据,输入到神经网络。
Tensor<int16_t> input;
input.set_element((int16_t *) model_input).set_exponent(input_exponent).set_shape({input_height,input_width,input_channel}).set_auto_free(false); 3.4 调用模型
通过调用 forward 方法、传递输入调用模型。使用延迟来计算ESP32-S3 运行神经网络所需的时间。
ACTIVITY model;
dl::tool::Latency latency;
latency.start();
model.forward(input);
latency.end();
latency.print("
Activity model", "forward");3. Future Directions 3.5 监控输出
输出来自公共层,即 l6。结果可以在终端中打印出来。
float *score = model.l6.get_output().get_element_ptr();
float max_score = score[0];
int max_index = 0;
for (size_t i = 0; i < 6; i++)
{
printf("%f, ", score[i]*100);
if (score[i] > max_score)
{
max_score = score[i];
max_index = i;
}
}
printf("
");
switch (max_index)
{
case 0:
printf("0: Downstairs");
break;
case 1:
printf("1: Jogging");
break;
case 2:
printf("2: Sitting");
break;
case 3:
printf("3: Standing");
break;
case 4:
printf("4: Upstairs");
break;
case 5:
printf("5: Walking");
break;
default:
printf("No result");
}
printf("
");
}
} 4. 结论
总之,这个项目可以给各种应用带更多可能,比如在工业领域开展预测性维护,在运动领域使用加速度计识别拳击中的出拳,在医疗保健领域进行跌倒检测。这只是一部分可以进一步探索的领域。如果想查看源代码,可前往 GitHub 仓库。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结