您现在的位置是:首页 >学无止境 >机器学习-12 卷积神经网络简介网站首页学无止境
机器学习-12 卷积神经网络简介
卷积神经网络
引言
深度学习发展历程
1.感知机网络(解决线性可分问题,20世纪40年代)
2.BP神经网络(解决线性不可分问题,20世纪80年代)
3.深度神经网络(海量图片分类,2010年左右)
常用的深度神经网络:CNN、RNN、LSTM、GRU、GAN、DBN、RBM…
深度应用领域
1.计算机视觉
2.语音识别
3.自然语言处理
4.人机博弈
深度学习vs传统机器学习
传统机器学习算法流程:
输入——>人工特征提取——>权重学习——>预测结果
深度学习算法流程:
输入—>基础特征提取—>多层复杂特征提取—>权重学习—>预测结果
深度神经网络vs浅层神经网络
深度神经网络
普通网络
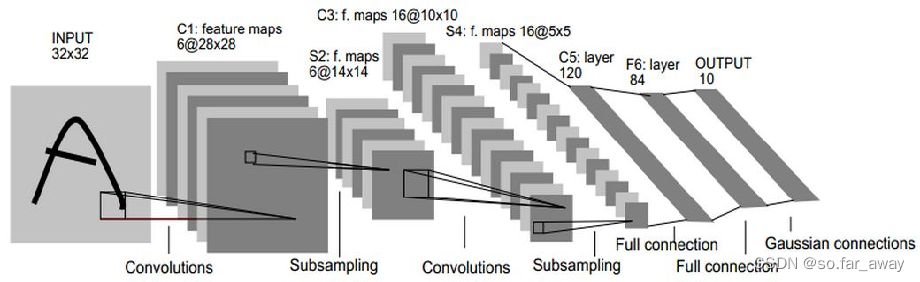
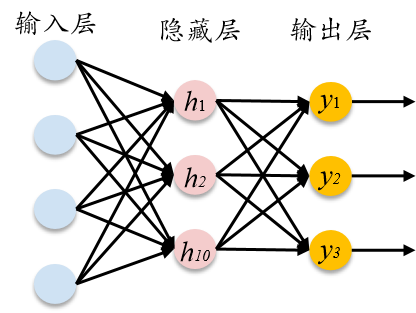
深度学习概述
- 深度学习是一种利用复杂结构的多个处理层来实现对数据进行高层次抽象的算法,是机器学习的一个重要分支。
- 传统的BP算法仅有几层网络,需要手工指定特征且易出现局部最优问题,而深度学习引入了概率生成模型,可自动地从训练集提取特征,解决了手工特征考虑不周的问题,而且初始化了神经网络权重,采用反向传播算法进行训练,与BP算法相比取得了很好的效果。
- 卷积神经网络目前是深度学习领域的热点,尤其是图像识别和模式分类方面,优势在于具有**共享权值的网络结构和局部感知(也称为稀疏连接)**的特点,能够降低神经网络的运算复杂度,因为减少了权值的数量,并可以直接将图像作为输入进行特征提取,避免了对图像的预处理和显式的特征处理。
卷积神经网络CNN
BP神经网络
缺陷:
- 不能移动
- 不能变形
- 运算量大
解决方法:
- 大量物体位于不同位置的数据训练
- 增加网络的隐藏层个数。
- 权值共享(不同位置拥有相同权值)
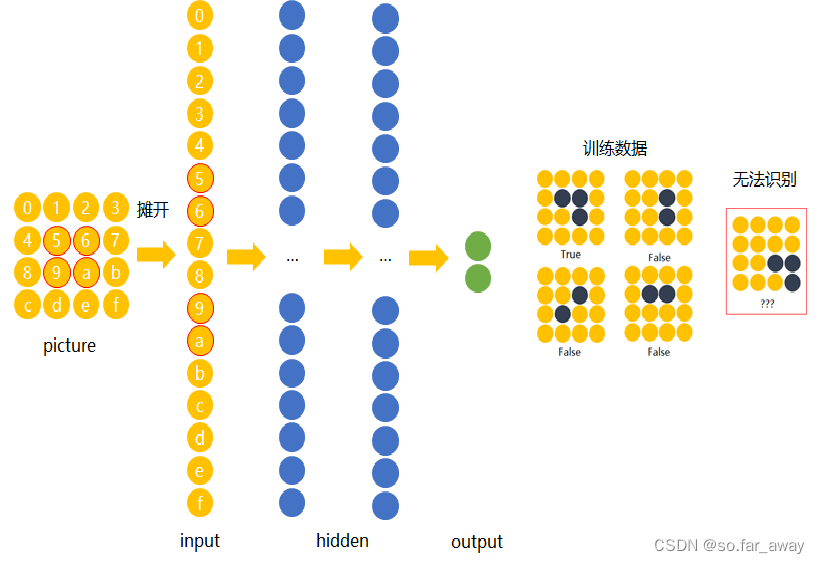
CNN概述
生物神经元所能处理信息的复杂程度被称为神经元的感受野,而神经元对于信息位置与方向变化不敏感的特性被称为平移不变性,卷积神经网络正是根据生物神经网络的这些特性而提出的神经网络模型。
卷积神经网络大致结构
此类网络主要对输入数据进行逐层交替的卷积和池化操作:
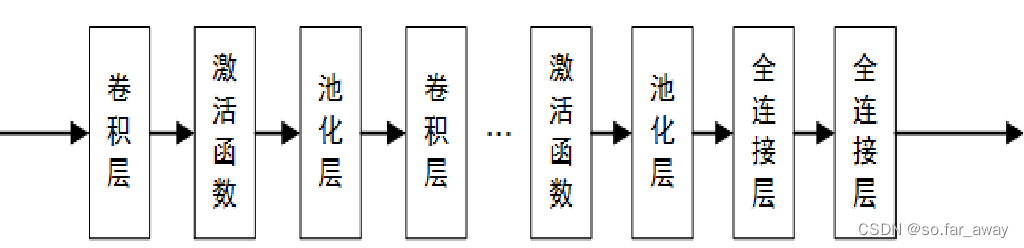
卷积神经网络大致过程
covolutional layer(卷积)、ReLu layer(非线性映射)、pooling layer(池化)、fully connected layer(全连接)、output(输出)的组合。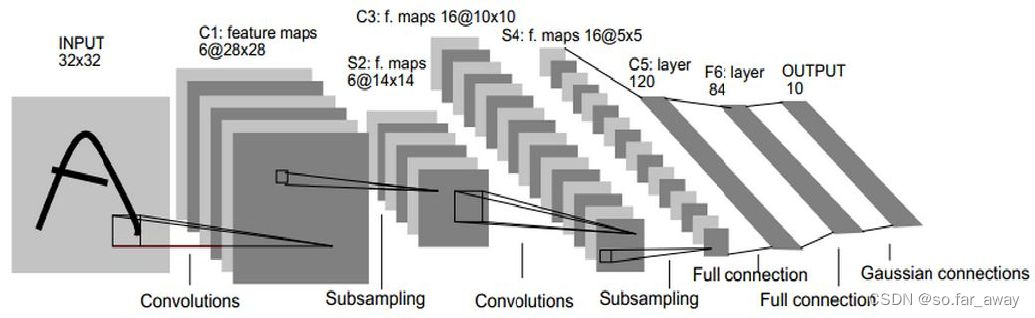
局部连接
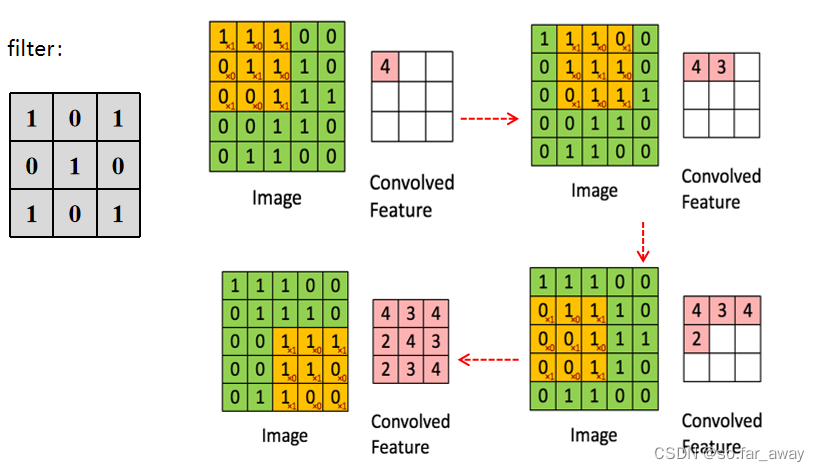
在CNN中,先选择一个局部区域(filter),用这个局部区域去扫描整张图片。
局部区域圈起来的所有节点会被连接到下一层的一个节点上。
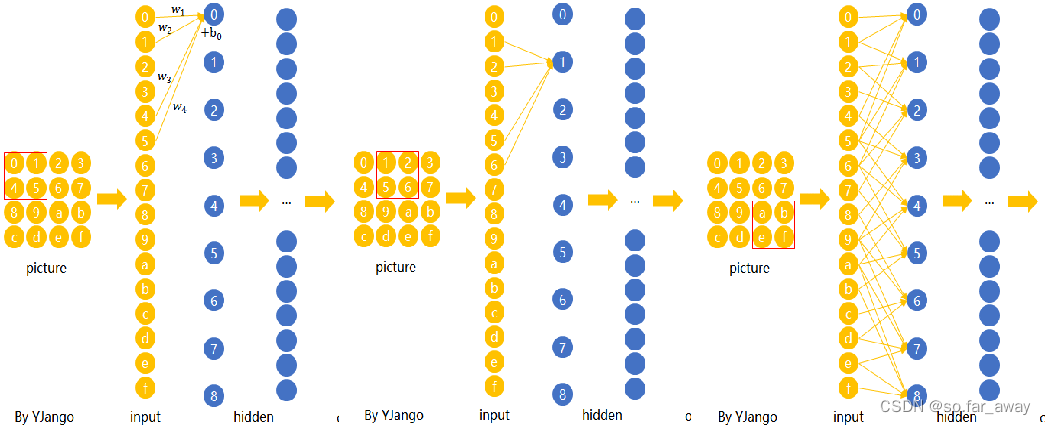
权值共享
卷积层 - CNN权值共享
非线性映射ReLU(Rectified Linear Units)
经过线性组合和偏移后,会加入非线性增强的拟合能力,将卷积所得的Feature Map经过ReLU变换。
ReLU是一个非线性激活函数,在卷积神经网络中,ReLU的作用主要体现在两个方面:
- 加速训练过程:使用ReLU激活函数可以加速模型的训练过程。相比于传统的sigmoid等激活函数,ReLU的导数计算更简单,并且不会出现梯度消失问题,因此可以更快地收敛。
- 提高模型性能:ReLU激活函数具有非线性变换的特点,可以使模型具有更强的表达能力,从而提高模型的性能。实践证明,在深层卷积神经网络中,使用ReLU激活函数可以显著提高模型的准确率和泛化能力。
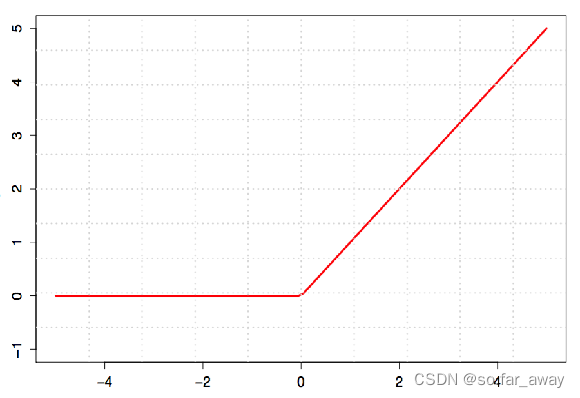
注:卷积操作本身是一种线性变换,它只会将输入数据进行加权求和,而无法处理复杂的非线性关系。通过连接激活函数,卷积层输出的结果可以被映射到一个非线性空间中,这个空间中的每一个点都代表着网络对某些特征的不同程度的响应,从而使得网络可以更好地识别输入图像中的模式和特征。
池化(pooling)
池化层亦称Pooling层,其操作是池化,即下采样。
主要作用是通过去除输入的特征图中不重要的信息,使特征图变小,进行特征压缩,进一步减少参数量,且同时提取其中的有效信息。
池化的结果是特征减少、参数减少,一定程度上可以避免过拟合。
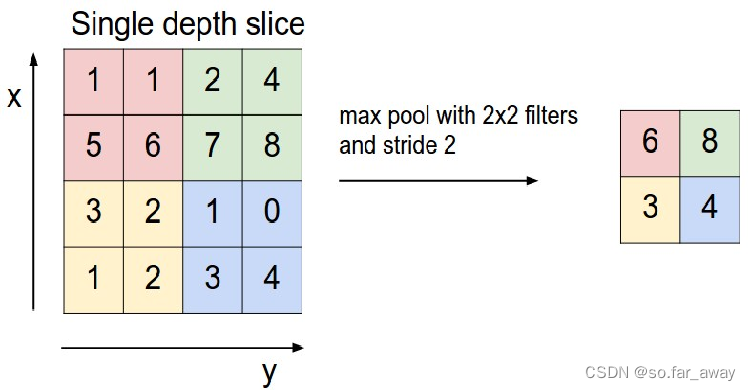
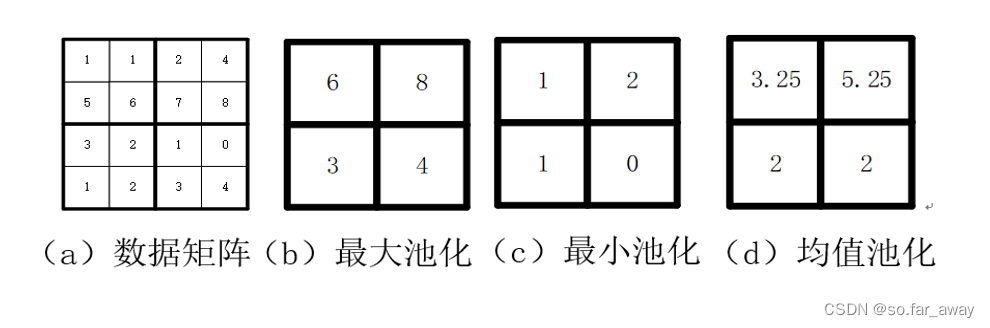
池化的具体操作是定义池化窗口的大小。
通常情况下,从某个池化窗口内进行采样的规则主要有取最大值、取最小值和取平均值三种,所对应的池化操作分别称之为最大池化、最小池化和均值池化。
全连接层
- 当抓取到足以用来识别图片的特征后,接下来的就是如何进行分类。
- 全连接层(也叫前馈层)就可以用来将最后的输出映射到线性可分的空间。
- 卷积网络的最后会在末端得到一个长长的向量,并送入全连接层配合输出层进行分类。
一个完整的CNN
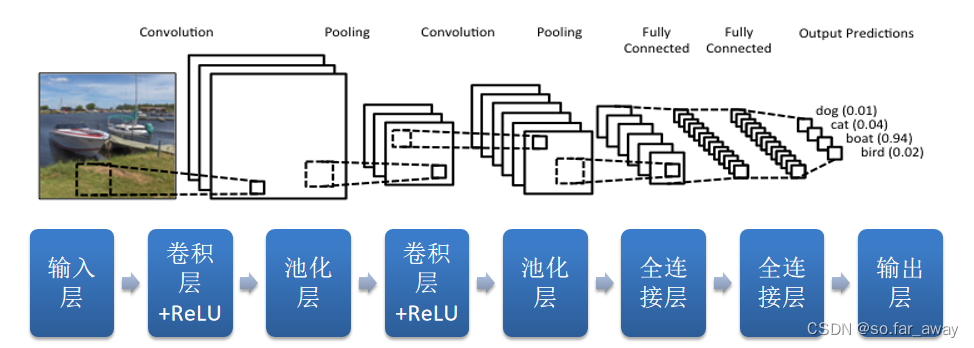
卷积神经网络主要执行了四个操作:
- 卷积
- 非线性(ReLU)
- 池化或下采样
- 分类(全连接层)
基于CNN网络的手写字体识别
#cnn卷积神经网络
#广泛应用在图片识别上
%matplotlib inline
import torch
import torch.nn as nn
import torchvision
import torch.utils.data as Data
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
EPOCH=1
BATCH_SIZE=50
LR=0.005
DOWNLOAD_MNIST=False
#1.生成数据集
train_data=torchvision.datasets.MNIST(
root='./mnist',
train=True,
transform=torchvision.transforms.ToTensor(),#将像素值从(0,255)区间压缩到(0,1)
download=DOWNLOAD_MNIST
)#数字0-9的图像
#plot one example
'''
print(train_data.data.size())#(60000,28,28)
print(train_data.targets.size())#(60000)
plt.imshow(train_data.data[0].numpy(),cmap='gray')
plt.title('%i' % train_data.targets[0])
'''
#2.读取数据,批处理
train_loader=Data.DataLoader(
dataset=train_data,
batch_size=BATCH_SIZE,
shuffle=True,
#num_workers=2
)
test_data=torchvision.datasets.MNIST(root='./mnist/',train=False)#train等于False说明提取出的是测试数据,而不是训练数据
test_x=torch.unsqueeze(test_data.data,dim=1).type(torch.FloatTensor)[:2000]/255.#手动压缩
test_y=test_data.targets[:2000]
#3.定义cnn神经模型
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1=nn.Sequential(#建立卷积层1,所谓卷积层就是一个过滤器
nn.Conv2d(#(1,28,28) 二维卷积
in_channels=1,#有多少层,例如rgb图片有三个通道也就是三个层,灰度图片只有一个层
out_channels=16,#16个卷积核同时对图片的同一个区域进行卷积
kernel_size=5,#filter的宽高都是5个像素
stride=1,#步长,filter在扫描时的跳步 每隔多少步跳一下
padding=2,#如果filter跳步之后超出图片范围,那么这个padding会给图片加一圈0,0对应的颜色就是黑色,padding如果非零会改变原始图片
#if stride=1 padding=(kernel_size-1)/2=(5-1)/2
),#->(16,28,28)
nn.ReLU(),#->(16,28,28)
nn.MaxPool2d(kernel_size=2),#池化层 往下筛选重要的部分 ->(16,14,14)
)
self.conv2=nn.Sequential(#(16,14,14)
nn.Conv2d(16,32,5,1,2),#->(32,14,14)
nn.ReLU(),#->(32,14,14)
nn.MaxPool2d(2),#->(32,7,7)
)
self.out=nn.Linear(32*7*7,10)#0-9一共10个分类
def forward(self,x):
x=self.conv1(x)
x=self.conv2(x) #(batch,32,7,7)
x=x.view(x.size(0),-1)#(batch,32*7*7)
output=self.out(x)
return output
cnn=CNN()
#4.优化器和损失函数
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
#5.训练模型
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 分配 batch data, normalize x when iterate train_loader
output = cnn(b_x) # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
if step%50==0:
test_output=cnn(test_x)
pred_y=torch.max(test_output,1)[1].data.squeeze()
accuracy=sum(pred_y==test_y)/test_y.size(0)
print('Epoch: ',epoch,'| train loss: %.4f'%loss.data,'| test accuracy: %.4f'%accuracy)
#print 10 predictions from test data
test_output=cnn(test_x[:10])
pred_y=torch.max(test_output,1)[1].data.numpy().squeeze()
print(pred_y,'prediction number')
print(test_y[:10].numpy(),'real number')






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结