您现在的位置是:首页 >技术教程 >k8s集群部署网站首页技术教程
k8s集群部署
文章目录
前言
k8s 自动化部署尝鲜,作为一个后端开发,还是多少要掌握一些运维知识的,但是不用掌握这么多~~
前置知识
- Linux系统命令知识
- Docker技术
k8s安装部署
环境准备
每台机器都配置
ip配置
三台Ubuntu18.04虚拟机:
192.168.163.128 master1
192.168.163.129 node1
192.168.163.131 node2
每个节点都需要具有可以通讯的唯一的静态 IP 地址,以便其他节点和控制平面能够正常与其通信,静态 IP 地址还是实现负载均衡和服务发现的重要条件。
为了避免DNS解析出现问题,通常会将上述ip和主机名写入每个节点的/etc/hosts文件中。
关闭swap分区和防火墙
# 关闭防火墙和防火墙开机自启
ufw disable
systemctl stop ufw
systemctl disable ufw
#关闭swap分区(一次有效)
sudo swapoff -a
#永久关闭swap分区(推荐)注释fstab文件中swap那一行
vim /etc/fstab
# /swapfile none swap sw 0 0
安装docker
每台机器上都需要安装
安装步骤
#1.更新apt软件包列表
apt update
#2.安装依赖项
# apt-transport-https 提供使用https协议进行apt软件仓库访问支持
# ca-certificates 保证与网络服务器之间的通信是安全和可靠的
# curl 用来下载文件密钥
# software-properties-common 管理第三方软件源
# openssh-server 允许用户从远程计算机连接到本地主机
apt install apt-transport-https ca-certificates curl software-properties-common openssh-server
#3.下载Docker在Ubuntu系统上的apt-key公钥,并将其添加到本地系统
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
#4.在Ubuntu操作系统中添加Docker软件包安装源(repository)并更新apt
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
apt update
#5.显示Docker软件包的安装状态和可用版本
apt-cache policy docker-ce
#6.在Ubuntu操作系统中安装指定版本的Docker软件包
apt install docker-ce=5:20.10.10~3-0~ubuntu-bionic
#7.查看状态
systemctl status docker
修改cgroup驱动
安装之后修改docker的cgroup驱动为systemd,否则执行kubeadm init和kubeadm join时会出现[WARNING IsDockerSystemdCheck]: detected “cgroupfs” as the Docker cgroup driver. The recommended driver is “systemd”.警告
vim /lib/systemd/system/docker.service
# 找到文件中下面位置
···
[Service]
Type=notify
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
···
# 修改第三行,指定cgroup驱动
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --exec-opt native.cgroupdriver=systemd
# 重启docker
systemctl daemon-reload
systemctl restart docker
# 查看cgroup驱动和docker服务状态
docker info | grep -i cgroup
systemctl status docker
#结果
root@master1:/# docker info | grep -i cgroup
WARNING: No swap limit support
Cgroup Driver: systemd
Cgroup Version: 1
root@master1:/# systemctl status docker
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset:
Active: active (running) since Tue 2023-05-23 08:55:38 CST; 3 days ago
Docs: https://docs.docker.com
Main PID: 2096 (dockerd)
Tasks: 26
CGroup: /system.slice/docker.service
└─2096 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/contai
······
安装k8s
每台机器都需要安装
# 下载 Kubernetes APT 软件源的 GPG 密钥
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
# 然后在/etc/apt/sources.list.d下新建文件kubernetes.list,添加一个 Kubernetes 的软件源并更新apt
vim /etc/apt/sources.list.d/kubernetes.list
写入 deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
apt update
#下载安装组件
apt-get install -y kubelet=1.23.2-00 kubeadm=1.23.2-00 kubectl=1.23.2-00
组件介绍:
- kubelet
核心组件之一,它负责监视该节点上的所有容器,并确保它们能够正常运行。会定期向 Kubernetes API Server 发送查询请求,以获取容器的期望状态,并根据需要启动、停止或重启容器。 - kubeadm
是 Kubernetes 的部署工具,可以帮助管理员快速地部署一个 Kubernetes 集群。它负责安装和配置 Kubernetes 控制平面组件(如 apiserver、controller-manager、scheduler 等),并将工作节点加入到集群中。 - kubectl
kubectl 是 Kubernetes 的命令行工具,用户可以使用它与 Kubernetes API 交互,并执行各种管理操作,如创建、删除、调整副本数等。通过 kubectl 命令行工具,用户可以方便地对 Kubernetes 集群进行管理和操作。 - kubernetes-cni
Kubernetes 的插件,主要用于实现容器网络。它会在容器创建时自动为其分配 IP 地址、创建网络空间,并建立网络连接关系。可以不手动安装 kubernetes-cni,而是通过安装相应的 CNI 插件来完成网络的配置和部署,本篇使用的是flannel组件。
部署k8s
master节点初始化启动k8s控制平台(master节点操作)
# 可以查看初始化平台需要的镜像列表:
kubeadm config images list
# 使用kubeadm控制平台初始化
kubeadm init
--image-repository=registry.aliyuncs.com/google_containers #指定容器镜像的仓库地址
--pod-network-cidr=10.244.0.0/16 #指定容器网络的 IP 地址段(CIDR),默认为 10.244.0.0/16
--kubernetes-version=v1.23.2 #指定k8s版本,不指定默认为最新版,最好与组件版本一致
--control-plane-endpoint=192.168.163.128:6443 #指定 Kubernetes 控制平面组件的访问地址,默认为 API Server 的地址
--apiserver-advertise-address=192.168.163.128 # 指定 Kubernetes API Server 的 IP 地址或主机名,默认为当前节点的 IP 地址
# 初始化完成之后会输出如下命令,可以在node节点运行加入集群。
kubeadm join 192.168.163.128:6443 --token xzerjg.uynhtwz5og88szo0
--discovery-token-ca-cert-hash sha256:f4b3a0f29f8f7fa1c9c1dacfa68124f0395ccba8a1e9dfc3dae98b836292e795
# 设置 KUBECONFIG 环境变量的值,以便让 Kubernetes 命令行工具(kubectl)知道如何连接 Kubernetes 集群
#非root用户执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# root用户执行:
export KUBECONFIG=/etc/kubernetes/admin.conf(仅本次有效)
# 或永久设置:
vim /etc/profile
#文件末尾添加
export KUBECONFIG=/etc/kubernetes/admin.conf
# 启动kubelet 设置为开机自启动
systemctl enable kubelet
# 启动k8s服务程序
systemctl start kubelet
# 启动完成后查看节点(未设置KUBECONFIG则运行不了kubectl)
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 NotReady control-plane,master 10m v1.23.2
# 查看组件状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true","reason":""}
上述查询组件状态中scheduler和controller-manager状态为unhealthy,可以注释掉/etc/kubernetes/manifests下的kube-controller-manager.yaml和kube-scheduler.yaml的- --port=0解决。
node节点加入控制平台(node节点操作)
# 启动kubelet 设置为开机自启动
systemctl enable kubelet
# 执行平台初始化时输出的命令即可
kubeadm join 192.168.163.128:6443 --token xzerjg.uynhtwz5og88szo0
--discovery-token-ca-cert-hash sha256:f4b3a0f29f8f7fa1c9c1dacfa68124f0395ccba8a1e9dfc3dae98b836292e795
#若上述命令失效,可以在master节点上执行下述命令重新输出
kubeadm token create --print-join-command --ttl 24h
# 加入后在master查看节点
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 UnReady control-plane,master 32m v1.23.2
node1 UnReady <none> 23m v1.23.2
node2 UnReady <none> 21m v1.23.2
安装flannel插件(master节点操作)
# 由于直接下载会被墙,所以先在/etc/hosts文件添加一条
199.232.68.133 raw.githubusercontent.com
# 然后通过wget下载fannel配置文件
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
#下载完之后执行
kubectl apply -f kube-flannel.yml
# 等待创建完之后查看节点可以看到状态都变为ready
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready control-plane,master 37m v1.23.2
node1 Ready <none> 28m v1.23.2
node2 Ready <none> 26m v1.23.2
ok,k8s一主两从部署完成!
可视化工具kubenetes dashboard部署(master节点)
#下载dashboard的yaml文件
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.4.0/aio/deploy/recommended.yaml
#修改yaml
# type 被设置为 NodePort 类型,表示这个 Service 将会使用 NodePort 的方式对外暴露服务,可以从外部访问
# nodePort 属性用于指定 Service 暴露的 NodePort 端口号,它允许外部网络从集群节点的 IP 地址和该端口号来访问这个 Service
vim recommended.yaml
---------------
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30001
type: NodePort
selector:
k8s-app: kubernetes-dashboard
-------------------
#使用kubectl进行创建
kubectl apply -f recommended.yaml
#使用kubectl查看dashboard的pod和serviced状态
kubectl get pods -n kubernetes-dashboard
kubectl get pods,svc -n kubernetes-dashboard
# 创建用户
kubectl create serviceaccount dashboard-admin -n kube-system
# 用户授权
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
# 获取用户Token
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
#打开web: 可以通过上面的token登录
https://192.168.163.128:30001
k8s使用
前置知识
k8s介绍
kubernetes,是一个全新的基于容器技术的分布式架构领先方案,本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
● 自我修复:一旦某一个容器崩溃,能够迅速启动新的容器
● 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
● 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
● 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
● 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
● 存储编排:可以根据容器自身的需求自动创建存储卷
k8s组件
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
Etcd :负责存储集群中各种资源对象的信息
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
KubeProxy : 负责提供集群内部的服务发现和负载均衡
Docker : 负责节点上容器的各种操作
k8s资源模型和概念
对k8s的操作主要就是对k8s对各种资源模型的配置
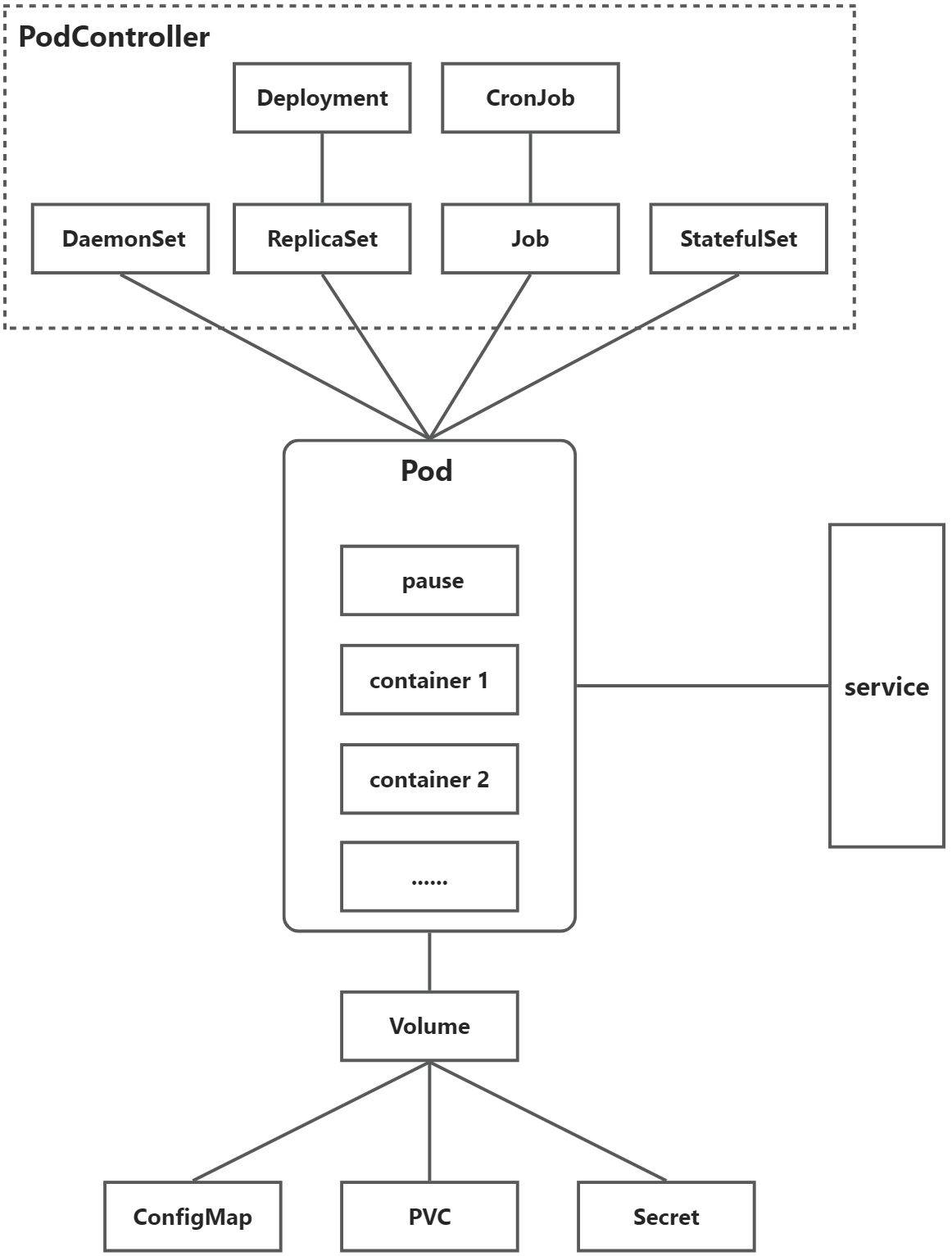
- namespace是一种用于组织和隔离资源的机制。它将集群中的资源对象划分为不同的命名空间,以防止资源名称冲突,并实现资源的逻辑隔离和限制。
命名空间中可以包含各种 Kubernetes 资源对象,如 Pod、Service、ConfigMap、Secret 等。 - podcontroller是k8s里的一种资源控制器,用于管理和控制pod,Pod Controller 通过监视资源对象的状态并采取相应的操作来实现资源的自动化管理和调整。分为以下几种:
- ReplicaSetReplicaSet 用于控制多个 Pod 副本的数量和状态。如果某个 Pod 发生故障或终止,它将自动启动一个新的 Pod 副本来替代它,从而保证所需的 Pod 数量保持恒定。
- DeploymentDeployment 是比 ReplicaSet 更高级别的 Pod Controller。它允许用户指定 Pod 副本数量、更新策略、滚动更新等参数,可以实现容器应用程序的流畅升级和回滚,,创建deployment后会自动创建replicaSet。
- DaemonSetDaemonSet 是一种 Pod Controller,它确保所有的节点都运行一个 Pod 的副本。当新增节点时,DaemonSet 会自动在该节点上启动一个 Pod 副本;当节点被删除时,相应的 Pod 也会被回收。
- StatefulSetStatefulSet 用于管理有状态的应用程序(如数据库、消息队列),它确保 Pod 按照严格的顺序启动和终止,保证每个 Pod 有唯一的标识符和网络标识,并可靠地存储和恢复应用程序状态。
- JobJob 控制器用于运行一次性任务或批处理作业,它创建一个或多个 Pod,并保证这些 Pod 成功完成任务后自动终止。
- CronJobCronJob 控制器基于 Linux 的 crontab 定时调度机制,可用于定期运行作业或命令。CronJob 创建一个或多个 Pod,并按照用户指定的时间表启动和终止这些 Pod。
- podPod 是最小的可部署和可调度的单位,它可以包含一个或多个容器,并共享同一个网络和存储空间,通常用于管理容器化应用程序的生命周期;
在 Pod 中,每个容器都有其独立的文件系统和进程空间,而pause根容器(也称为主容器)则扮演着一个重要的角色根容器通常是 Pod 中的第一个启动的容器,它负责启动和运行其他容器,并监控整个 Pod 生命期内的各种状态变化。在根容器中,用户可以通过预定义的命令、脚本或程序实现各种功能,如初始化环境变量、拉取镜像、创建卷等。 - service
- Service 基本概念Service 是 Kubernetes 集群中的一个重要组件,用于管理和暴露 Pod 中的应用程序,提供了一种内部负载均衡和服务发现的机制,使得应用程序可以更加灵活和可扩展。Service 可以有多种类型,如 ClusterIP、NodePort、LoadBalancer、ExternalName 等。
- Service 的使用使用 Service 可以将一组 Pod 暴露成为一个网络服务,并为这个服务分配一个稳定的 IP 地址和 DNS 名称,使得其他的 Pod 或外部应用程序可以通过该地址来访问该服务。用户需要创建一个 Service 对象,并指定要暴露的 Pod 的标签选择器,Kubernetes 会自动将符合条件的 Pod 关联到该 Service 上。
- Service 的类型Kubernetes 支持多种类型的 Service,用户可以根据需要选择不同的类型。其中,ClusterIP 类型是最基础的类型,提供了一个虚拟 IP 地址,只能在集群内部进行访问;NodePort 类型则将 Service 暴露到每个节点上的一个端口上,可以从集群外部访问;LoadBalancer 类型可以自动创建一个负载均衡器,并为 Service 分配一个公开的 IP 地址,可以根据需要进行外部流量的负载均衡;ExternalName 类型则允许将 Service 映射到一个外部的 DNS 名称上。
- Service 的负载均衡和服务发现Service 提供了一种内部负载均衡和服务发现的机制,使得应用程序可以更加灵活和可扩展。当 Pod 的数量发生变化时,Service 会自动更新关联的 Pod 列表,并将请求分配到不同的 Pod 上,从而实现负载均衡和高可用。
- volumeVolume是用于容器存储的抽象概念,它为Pod中的容器提供了持久化存储空间,一般有以下几种:
- EmptyDir Volume空目录Volume,它是一个临时目录,可被Pod中的所有容器共享使用。
- HostPath Volume主机路径Volume,将主机文件系统中的目录或文件挂载到Pod中的容器中,可以在容器中读取和写入这些文件。
- ConfigMap Volume配置映射Volume,将ConfigMap对象中的数据作为文件挂载到Pod中的容器中,用于存储配置文件。
- Secret Volume密钥映射Volume,将Secret对象中的数据作为文件挂载到Pod中的容器中,用于存储敏感信息。
- PersistentVolumeClaim (PVC) Volume持久卷Volume,使用PersistentVolumeClaim(PVC)请求动态或静态分配的持久化卷(PV),并将其挂载到Pod中的容器中,用于持久化存储数据。
- Persistent Volume(PV是一种可以独立于 Pod 而存在的存储卷,它提供了一种抽象的存储层,使得 Pod 可以通过声明 PV (PVC)来请求所需的持久化存储,并将 PV 挂载到容器中,从而实现数据的持久化;
与上面的资源不同,PV在k8s中是共享的,不是属于特定的namespace的,当有PVC创建的时候,k8s会选择集群中合适的PV与PVC进行绑定。 - label标签是k8s中的一个重要概念,它的作用就是在资源上添加标识,用来对它们进行区分和选择;
一个Label会以key/value键值对的形式附加到各种对象上,如Node、Pod、Service等等;一个资源对象可以定义任意数量的Label ,同一个Label也可以被添加到任意数量的资源对象上去;Label通常在资源对象定义时确定,当然也可以在对象创建后动态添加或者删除。
k8s部署Java应用
思路概述:准备了一个简单的springboot项目,不连数据库;
k8s作为一个容器编排方案,应用程序在其中是作为一个容器进行的,而容器需要存放在pod中受k8s的调度和控制,所以需要将项目打包成镜像便于创建pod时指定;
创建和管理pod需要pod控制器,所以选择创建一个pod控制器,我的springboot项目作为一个无状态的应用程序,最好使用Deployment控制器来创建pod;
程序运行起来之后肯定需要集群外部进行访问,所以需要往外暴露接口,这时候就需要创建service来将应用端口暴露给外部便于访问。
制作镜像
# master节点创建目录存储jar包
root@master1:/home/master1/javapj# ls
javaproject.jar
# 在该目录下创建Dockerfile文件,内容如下
FROM openjdk:8-jdk-alpine
VOLUME /tmp
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
ADD javaproject.jar javaproject.jar
ENTRYPOINT ["java","-jar","/javaproject.jar", "&"]
#执行build命令打包镜像
docker build -t javademo:v1 .
# 查看镜像
root@master1:/home/master1/javapj# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
javademo v1 3d10dac890bc 56 seconds ago 122MB
部署文件
- 新建一个namespace:javademo
apiVersion: v1
kind: Namespace
metadata:
name: javademo
labels:
app: javademo
- 在命名空间里创建deployment
创建deployment之后会自动创建replicaSet管理pod
apiVersion: apps/v1
kind: Deployment
metadata:
name: javademo1
namespace: javademo #指定命名空间
labels:
app: javademo1
spec:
replicas: 1 #指定副本数量
template:
metadata:
name: javademo1
labels:
app: javademo1
spec:
containers:
- name: javademo1
image: javademo:v1 #指定镜像
imagePullPolicy: Never #重启镜像拉取策略,由于是自己打包的镜像,所以就不拉取了
ports:
- containerPort: 8111 #容器暴露的端口
restartPolicy: Always #重启pod的策略,只要低于指定的数量就会重启
selector:
matchLabels:
app: javademo1
3.创建service去暴露端口
apiVersion: v1
kind: Service
metadata:
name: javademo1-svc
namespace: javademo
spec:
selector:
app: javademo1
ports:
- port: 8111
targetPort: 8111
nodePort: 30033 #通过30033端口被外部访问
type: NodePort #NodePort可以被外部访问
三个port的区别:
nodeNort是服务对象公开的端口号,可以从群集外部访问该端口。当服务对象暴露了 Node Port 时,Kubernetes 将自动分配一个高位端口,并将其映射到集群中的每个节点上。然后,可以通过任何节点的 IP 地址和分配的 Node Port 访问该服务。
port是容器内部使用的端口号,是应用程序绑定的端口。该端口只存在于容器内部,外部无法直接访问该端口。当容器暴露了该端口时,可以通过服务对象让集群内的其他组件访问该端口。
targetPort是服务对象与 Pod 通信时使用的端口号。当服务对象与 Pod 通过选择器匹配关联时,服务对象将流量转发到 Pod 的 Target Port 上,而非容器的端口。Pod 可以选择任何可用端口作为 Target Port,但通常情况下都会选择与容器端口相同的端口号。
启动应用
创建资源的方式有两种:
- 使用kubectl命令行进行创建时,把上述配置作为.yaml文件保存在master节点自定义的目录下,然后使用**kubectl apply -f .yaml **依次创建资源即可,创建之后k8s会自动创建pod和容器并运行应用。
- 使用kubernetes-dashboard可视化工具进行创建。

访问应用
部署好之后,通过http://192.168.163.128:30033/、http://192.168.163.128:30033、http://192.168.163.128:30033/均可访问该服务。
k8s资源限制
节点级别的资源限制
节点级别的资源限制:通过 Node 上的配置文件或者命令行参数,可以对节点上运行的所有 Pod 进行资源限制。例如,使用 kubelet 在启动每个节点时添加 --cpu-manager-policy=static 参数,即可限制该节点上所有 Pod 的 CPU 使用量。
命名空间级别的资源限制
可以通过 LimitRange 和 ResourceQuota 两个对象来限制命名空间级别的cpu,内存,存储,显卡等资源:
#使用LimitRange限制每个容器的最大和最小占用资源
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-mem-limit-range
namespace: namespace-name
spec:
limits:
- type: Container
max:
cpu: "500m"
memory: "128Mi"
min:
cpu: "100m"
memory: "64Mi"
#使用ResourceQuota限制整个命名空间下所有pod和容器的资源总量
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-mem-quota
namespace: namespace-name
spec:
hard:
requests.cpu: "2"
requests.memory: "512Mi"
#使用LimitRange 对象将一个命名空间中所有容器的存储资源限制为 1GB
apiVersion: v1
kind: LimitRange
metadata:
name: storage-limit-range
namespace: namespace-name
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: "1Gi"
#使用ResourceQuota对象将一个命名空间中所有Pod和容器的存储资源使用限制为总共不超过 5GB:
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-quota
spec:
hard:
requests.storage: "5Gi"
#在 Kubernetes 1.19 版本及以上,可以使用 DeviceTopology API 来限制一个 Namespace 中
#所有 Pod 和容器的显卡资源使用。例如,以下 YAML 文件中的 LimitRange 对象将一个命名空间
#中所有容器的显卡资源限制为最多只能绑定 2 个报文设备(RDMA)和 1 个 NVIDIA GPU 设备
apiVersion: v1
kind: LimitRange
metadata:
name: gpu-limit-range
spec:
limits:
- type: nvidia.com/gpu
max:
nvidia.com/gpu: "1"
- type: "openshift.io/network"
max:
"rdma/ib": "2"
#注意,上述显卡资源限制需要基于支持 DeviceTopology API 的 CRI 实现,
#例如 cri-o、containerd 等。如果使用的是 Docker CRI 实现,则需要额外
#安装 nvidia-docker2 插件来实现显卡资源限制
Pod和容器级别的资源限制
# 在Deployment中的spec.container[].resources中限制每个容器的cpu和内存
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
namespace: namespace-name
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: nginx
resources:
limits:
cpu: "0.5"
memory: "128Mi"
requests:
cpu: "0.25"
memory: "64Mi"
#或者直接限制一个pod中所有容器能使用的资源
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment
namespace: namespace-name
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: container-1
image: nginx
- name: container-2
image: redis
resources:
requests:
cpu: "1"
memory: "1Gi"
limits:
cpu: "2"
memory: "2Gi"
#也可以在k8s集群中安装DevicePlugins 插件用来暴露设备资源,
#暴露之后就可以在spec.container[].resources中定义容器的资源请求和限制,包括显卡资源
#比如下面为容器请求一个 NVIDIA GPU 资源,并限制其最大使用数量为 1
apiVersion: v1
kind: Pod
metadata:
name: my-pod
namespace: namespace-name
spec:
containers:
- name: my-container
image: my-image
resources:
limits:
nvidia.com/gpu: 1
总结
感谢小胡同学的细心整理~~





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结