您现在的位置是:首页 >技术杂谈 >使用 LabVIEW调用LeNet快速搭建手写数字识别系统(内含源码)网站首页技术杂谈
使用 LabVIEW调用LeNet快速搭建手写数字识别系统(内含源码)
?博客主页: virobotics的CSDN博客:LabVIEW深度学习、人工智能博主
?所属专栏:『LabVIEW深度学习实战』
?上期文章: 【图像分类】基于OpenVINO实现PyTorch ResNet50图像分类
?如觉得博主文章写的不错或对你有所帮助的话,还望大家多多支持呀! 欢迎大家✌关注、?点赞、✌收藏、?订阅专栏
文章目录
前言
之前给大家介绍过使用仪酷AI视觉工具包的DNN模块实现手写数字识别,今天给大家介绍一下在LabVIEW使用ONNX工具包部署LeNet实现手写数字识别
一、LeNet简介
LeNet-5是一种经典的卷积神经网络(Convolutional Neural Network,CNN),一般LeNet即指代LeNet-5,由Yann LeCun等人于1998年提出。LeNet主要用于手写数字识别,是深度学习领域的重要里程碑,也是现代CNN架构的基础。
LeNet的架构包括了两个卷积层,两个池化层和三个全连接层。其中,卷积层和池化层用于提取图像的特征,全连接层用于输出分类结果。LeNet的架构采用了加速学习的方法,即卷积和池化层的交替使用,可以减少参数数量,并提高特征提取的效率,LeNet网络模型框架如下图所示:
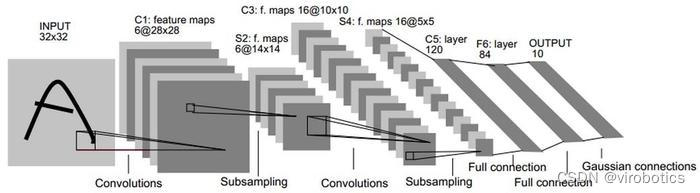
LeNet的输入为32x32的灰度图像,因为在当时的计算能力下,处理更大的图像会很困难。第一个卷积层包含了6个5x5的卷积核,每个卷积核对应了一个输出特征图。第一个池化层是2x2的最大池化,用于减小特征图的大小。第二个卷积层包含了16个5x5的卷积核,同样每个卷积核对应了一个输出特征图。第二个池化层是2x2的最大池化。最后是三个全连接层,用于对特征进行分类。
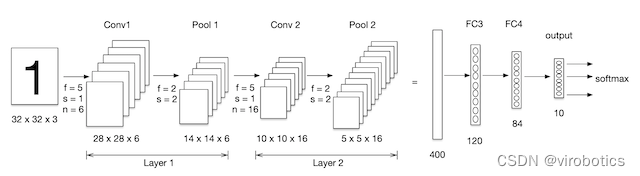
LeNet在MNIST手写数字识别数据集上表现出色,达到了当时最佳的分类准确率。虽然LeNet的架构相对简单,但它奠定了卷积神经网络在计算机视觉领域的地位,并为后来的深度学习研究提供了重要的基础。
二、环境搭建
2.1 部署本项目时所用环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- AI视觉工具包:techforce_lib_opencv_cpu-1.0.0.98.vip
2.2 LabVIEW工具包下载及安装网址
- https://www.virobotics.net/
- AI视觉工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/123656523 - AI视觉工具包介绍:
https://blog.csdn.net/virobotics/article/details/123522165 - onnx工具包下载与安装参考:
https://blog.csdn.net/virobotics/article/details/124998746
三、LabVIEW调用LeNet搭建手写数字识别系统
3.1 LeNet的手写数字识别模型
我们已经给大家准备了训练好的手写数字识别模型,可以直接使用~
如果大家想要重新训练手写数字模型并生成该模型的onnx格式,则可以参考以下代码:
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
from torchvision import datasets
from torchvision.transforms import ToTensor
#下载并导入训练和测试数据集,并进行预处理
#https://blog.csdn.net/qimo601/article/details/112526722
train_data = datasets.MNIST(
root = 'data',
train = True,
transform = ToTensor(),
download = True,
)
test_data = datasets.MNIST(
root = 'data',
train = False,
transform = ToTensor()
)
print(train_data)
print(test_data)
print(train_data.data.size())
#import matplotlib.pyplot as plt
#plt.imshow(train_data.data[0], cmap='gray')
#plt.title('%i' % train_data.targets[0])
#plt.show()
#把数据集分为训练集和测试集
from torch.utils.data import DataLoader
loaders = {
'train' : torch.utils.data.DataLoader(train_data,
batch_size=512,
shuffle=True,
num_workers=0),
'test' : torch.utils.data.DataLoader(test_data,
batch_size=512,
shuffle=True,
num_workers=0),
}
loaders
import torch.nn as nn
#定义网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
#定义第一层卷积的Sequential函数(包含卷积、激活函数、池化)
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
#定义第二层卷积的Sequential函数
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2),
)
# fully connected layer, output 10 classes(全连接层)
self.out = nn.Linear(32 * 7 * 7, 10)
def forward(self, x):
#调用第一层卷积函数
x = self.conv1(x)
#调用第二层卷积函数
x = self.conv2(x)
# flatten the output of conv2 to (batch_size, 32 * 7 * 7)
x = x.view(x.size(0), -1)
#调用全连接层
output = self.out(x)
return output, x # return x for visualization
cnn = CNN().to(device)
#定义网络训练时用的损失函数
loss_func = nn.CrossEntropyLoss()
from torch import optim
optimizer = optim.Adam(cnn.parameters(), lr = 0.01)
from torch.autograd import Variable
num_epochs = 10
def train(num_epochs, cnn, loaders):
cnn.train()
# Train the model
total_step = len(loaders['train'])
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(loaders['train']):
images, labels = images.to(device),labels.to(device)
# gives batch data, normalize x when iterate train_loader
b_x = Variable(images) # batch x
b_y = Variable(labels) # batch y
output = cnn(b_x)[0]
loss = loss_func(output, b_y)
# clear gradients for this training step
optimizer.zero_grad()
# backpropagation, compute gradients
loss.backward()
# apply gradients
optimizer.step()
if (i+1) % 100 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch + 1, num_epochs, i + 1, total_step, loss.item()))
else:
pass
pass
pass
train(num_epochs, cnn, loaders)
def test():
# Test the model
cnn.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in loaders['test']:
images, labels = images.to(device),labels.to(device)
test_output, last_layer = cnn(images)
pred_y = torch.max(test_output, 1)[1].data.squeeze()
accuracy = (pred_y == labels).sum().item() / float(labels.size(0))
print('Test Accuracy of the model on the 10000 test images: %.2f' % accuracy)
test()
sample = next(iter(loaders['test']))
imgs, lbls = sample
actual_number = lbls[:10].numpy()
x=imgs[:10].to(device)
test_output, last_layer = cnn(x)
pred_y = torch.max(test_output, 1)[1].data.cpu().numpy().squeeze()
print(f'Prediction number: {pred_y}')
print(f'Actual number: {actual_number}')
# 转onnx代码
#第一步:先要定义一个或多个随机的tensor,作为onnx文件的输入口
#该tensor的大小要和pytorch模型的输入大小一致(mnist为1*1*28*28)
#第一个1:batchsize,代表输入的图片为1张,也可以为多张
#第二个1:图片的通道数为1,即为灰度图
#28*28:图片的高度和宽度
a=torch.rand(1, 1, 28, 28)
#第二步:需要讲模型回落到cpu上
cnn2=cnn.to("cpu")
#第三步:生成onnx模型
torch.onnx.export(
cnn2,
a,
"model.onnx",
input_names=["input"],verbose=False,opset_version=11
)
3.2 查看模型输出输出
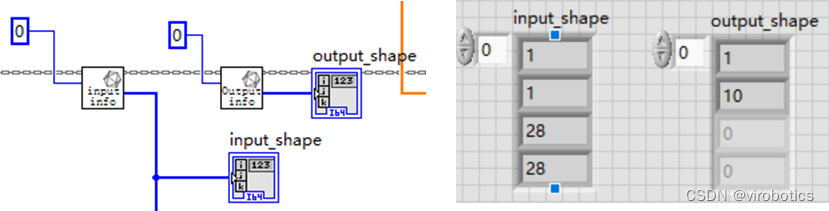
打开http://netron.app,载入本地onnx模型,我们可以看到模型的输入输出
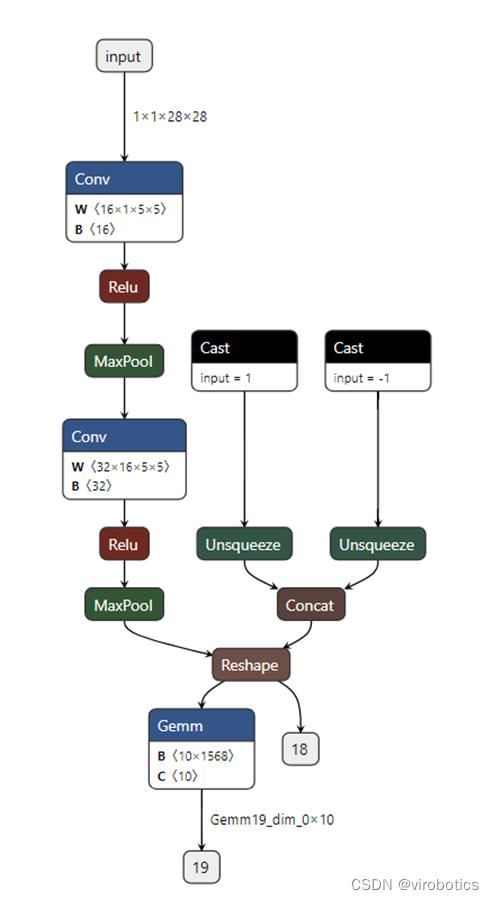
我们查看模型的输入shape,是因为推理过程我们需要输入shape,不过我么也可以使用GetInputInfo.vi来直接获取模型输入的shape
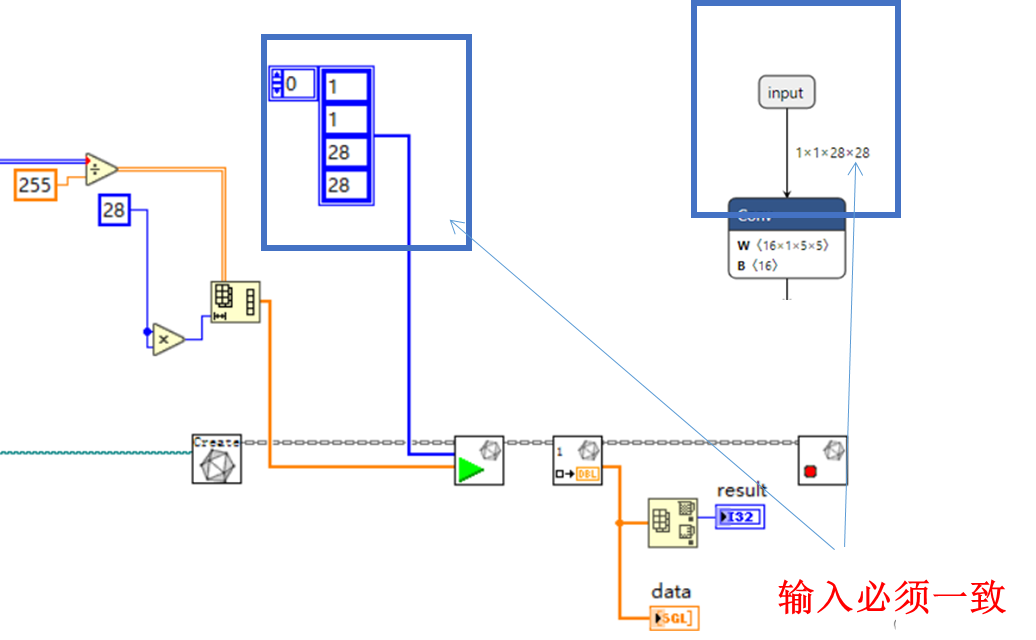
3.3 实现手写数字识别(mnist_pytorch_onnx.vi)
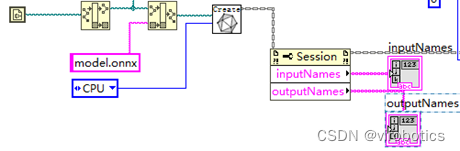
- 读取onnx模型并选择推理加速引擎,使用属性节点获取输入输出名字
- 获取取神经网络模型输入输出shape备用
- 从二进制文件里读取某一幅图并显示出来
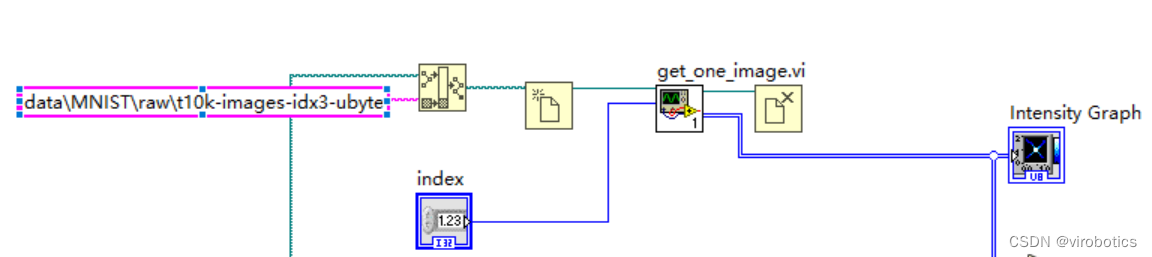
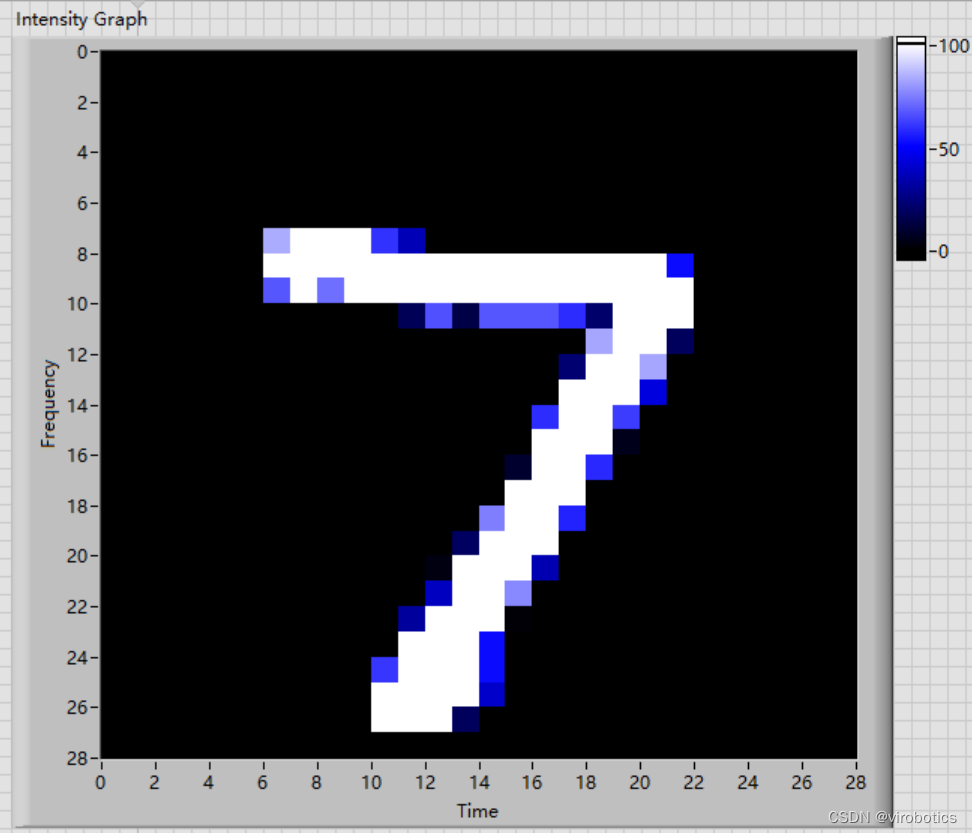
get_one_image.vi主要是用来获取一张图片
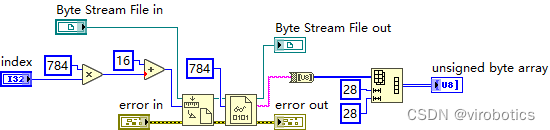
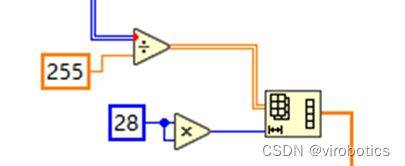
4. 对进入神经网络的图像进行预处理
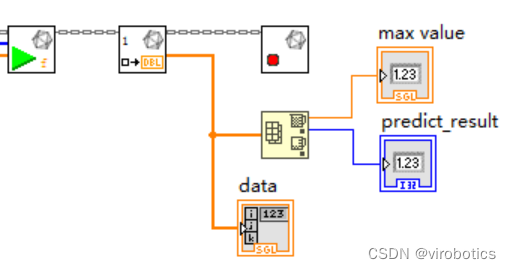
5. 将处理后的结果送入神经网络进行推理,并获取结果
-
最终实现完整程序如下:
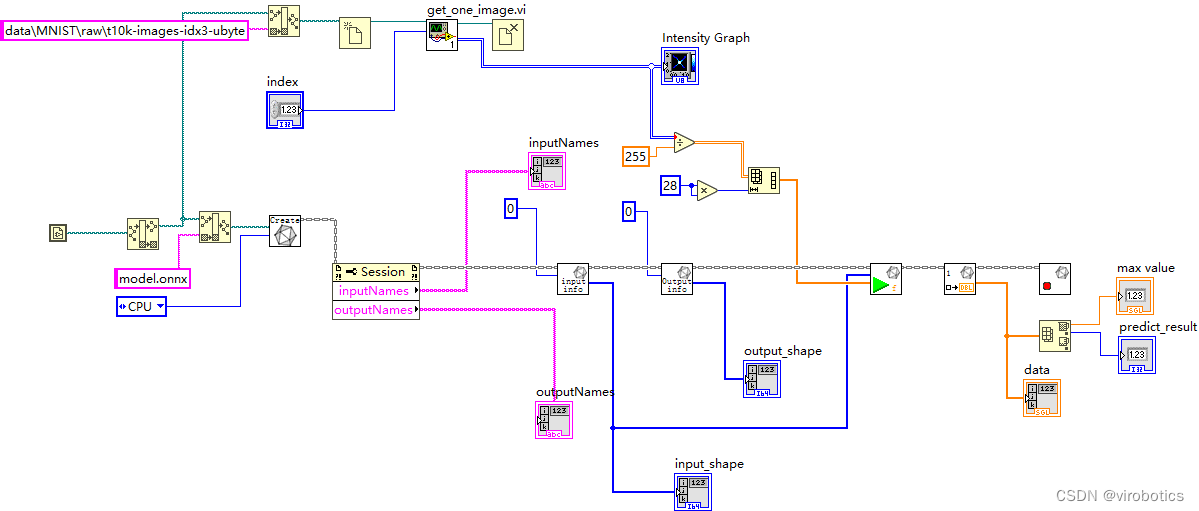
-
运行结果如下,可以修改index,来识别其他数字。
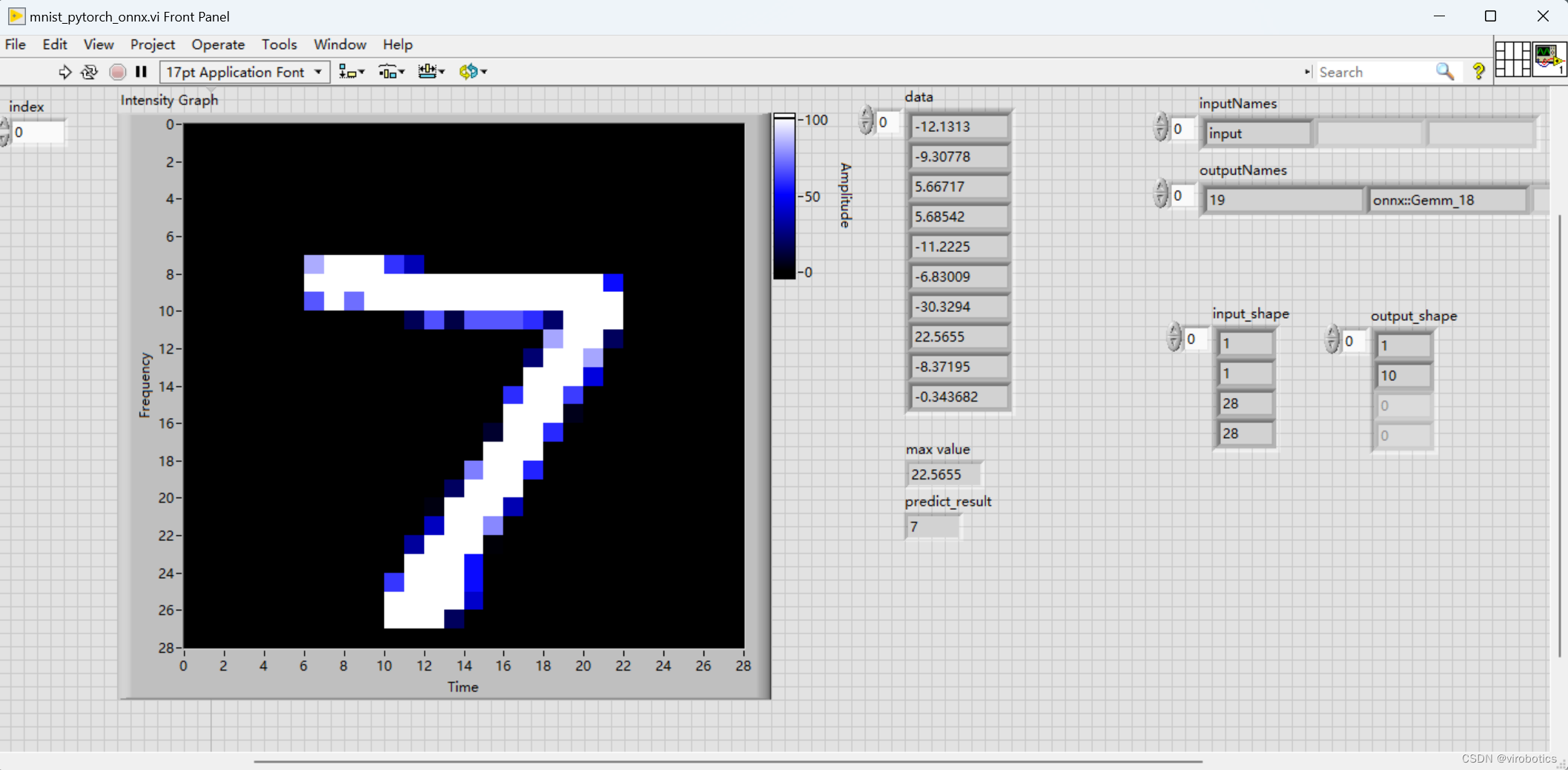
四、项目源码
码字不易,如需LabVIEW源码,请一键三连并订阅本专栏后评论区留下邮箱
总结
以上就是今天要给大家分享的内容,希望对大家有用。我们下篇文章见~
创作不易,如果文章对你有帮助,欢迎✌关注、?点赞、✌收藏、?订阅专栏
推荐阅读
LabVIEW图形化的AI视觉开发平台(非NI Vision),大幅降低人工智能开发门槛
LabVIEW图形化的AI视觉开发平台(非NI Vision)VI简介
LabVIEW AI视觉工具包OpenCV Mat基本用法和属性
手把手教你使用LabVIEW人工智能视觉工具包快速实现图像读取与采集
?技术交流 · 一起学习 · 咨询分享,请联系?






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结