您现在的位置是:首页 >其他 >RNN、LSTM知识点总结网站首页其他
RNN、LSTM知识点总结
CNN——用于计算机视觉(CV)
RNN——用于自然语言处理(NLP)
理解:其中h0,h1...ht-1是中间结果,x0,x1...x代表时序输入。举例:如I am Chinese,I love China,则x0=‘I’,x1=‘am’...xt=‘China’,但单词不能直接输入网络,所以使用word2vec将单词转换成向量后,即可作为输入。
缺点:RNN会考虑之前的所有结果记录下来,记得太多就会产生错误或误差
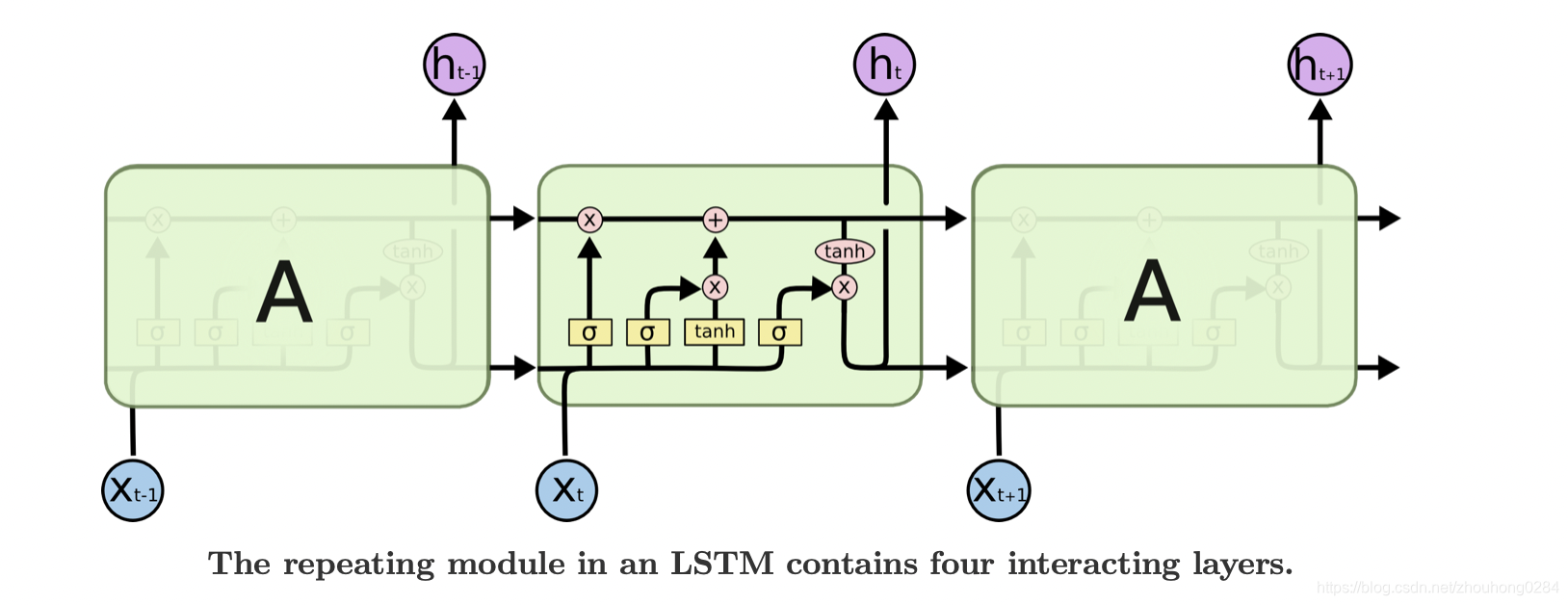
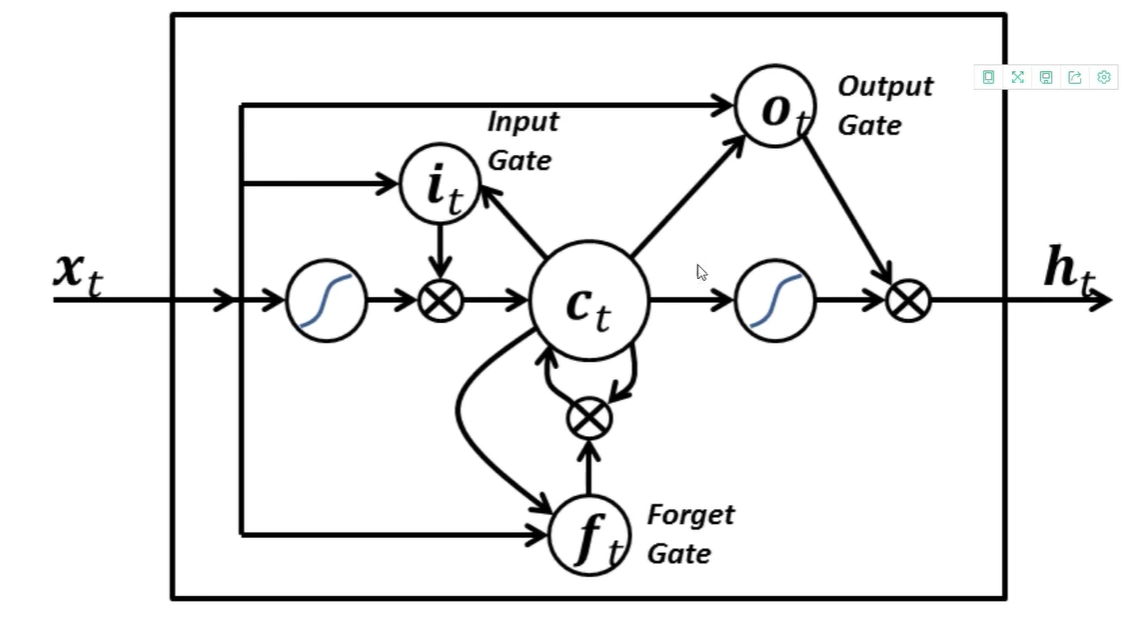
LSTM:针对RNN的缺点,选择性的保留之前的信息
每个黄色方框表示一个神经网络层,由权值,偏置以及激活函数组成;每个粉色圆圈表示元素级别操作;箭头表示向量流向;相交的箭头表示向量的拼接;分叉的箭头表示向量的复制
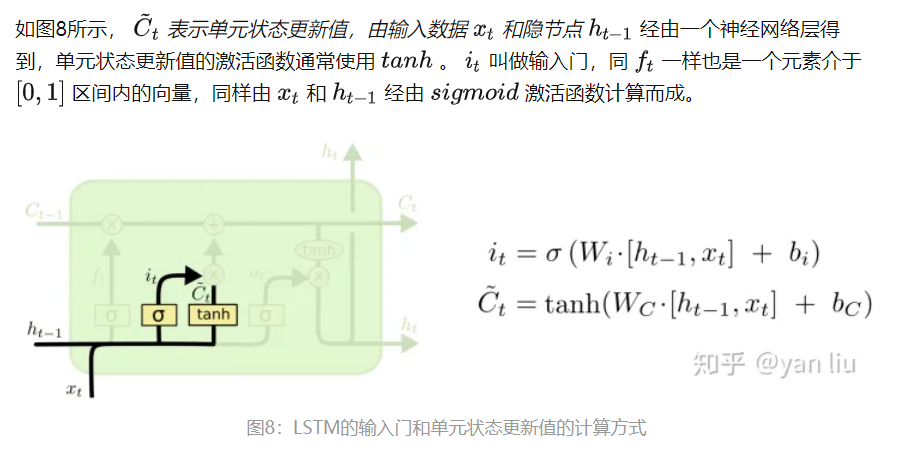
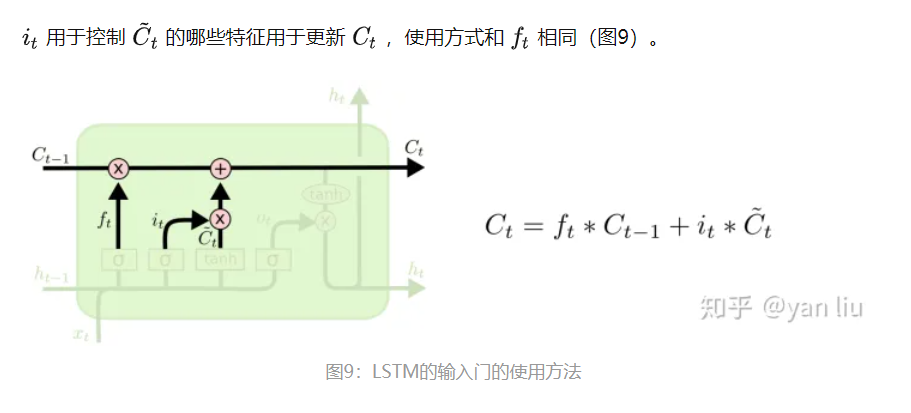
LSTM的核心部分是上图,这一部分一般叫做单元状态(cell state)它自始至终存在于LSTM的整个链式系统中,其中( C:控制参数,决定什么信息保留,什么信息遗忘)
门:让信息选择式通过的方法,由一个sigmoid函数和乘法操作构成。通过使用sigmoid输出0到1之间的数值,用于描述每个部分有多少量可以通过,0代表不允许任何量通过,1代表允许任意量通过。



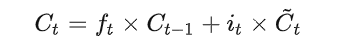





word2Vec:将文本向量化(对顺序敏感,能体现相近意思)
使用-1到1描述一个属性(如一个人性格是内向还是外向),一般用50-300维度的向量
一个50维词向量(表示50个特征)
使用热力图表示(颜色越深表示数值越大,-1.6到1.6之间)
例如我们通过这种方法得到三个词向量,其中man和boy的词向量有很多地方是相近的
如何训练一个词向量(一个词应该用什么向量表示)(前向传播去计算损失函数值,反向传播则通过损失函数值去更新权值参数)
随机赋值创建一个词库表1),然后输入一句话的前俩个词,根据输入的俩个词从词库表中找出这俩个词的向量,然后输入网络,最终得到一个分类结果,然后将结果与真实结果比对后得到损失值,然后反向传播更新网络权值和词库表 ,当训练到一定程度后即可得到所有词的词向量了
训练的数据从哪来?合乎语言逻辑的文本都可以
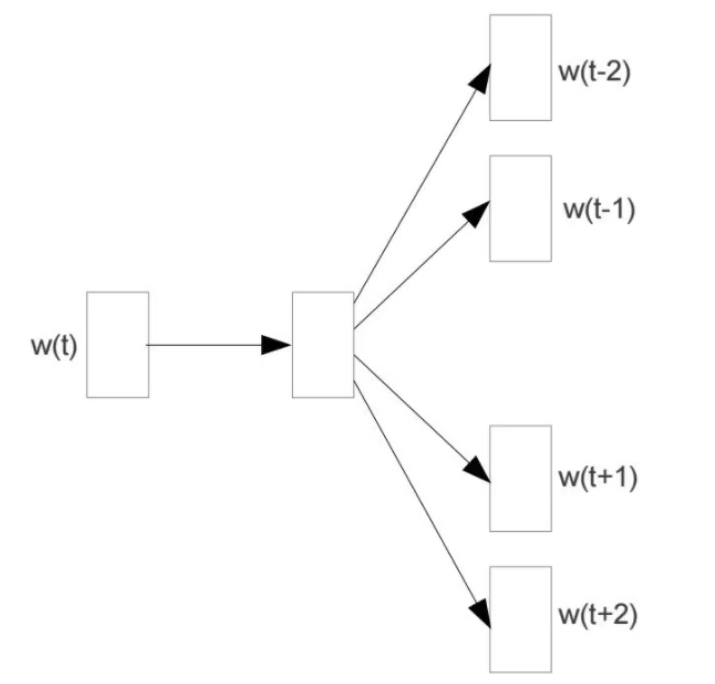
构建训练数据:通过一个滑动串口来选取
不同的选取模型
CBOW
Skipgram












给定一个点序列(图像和sinx函数相似),然后我们选择一个一个合适的滑动块模式(如50个数一组),然后输入到RNN中(如图) (备注:xi可以输入1维数,可以输入多维向量)

网络结构图:
(None,49,1)代表有49个输入节点(滑动块规模),每个输入为1维的数字
然后第一个LSTM,将1维数转换成50维的向量了
然后第二个LSTM,将50维转换成100维的向量了 ,并且只去了最终结果ht,前面的结果丢掉了(None,100)(dropout略)
然后全连接层将100维转为1维数,这个数就是最终的结果(输入x0,x1,x2,x3,...x49后预测得到的值)
首先读csv文件(5000个数据),将数据集切分为测试集和训练集,然后构建模型(根据上图设计即可,再指定以下损失函数MSE,优化器ADMA),然后画结构图,
有4000-50个序列, 然后从csv中获取0到50的数据,然后取前49个数据作为训练集xi,最后一个最为预测值y,然后从1到51开始以此类推获取
最终得到:x=》(3950,49,1)y=》(3950,1)(当我们拿到陌生代码时应习惯打印shape,通过数据维度来理解代码)
然后用x和y去训练
EarlyStopping:监视损失函数值是否已经收敛,收敛则会停止训练
ModelCheckPoint:保存训练权值,方便接续前一次继续训练
测试














站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结