您现在的位置是:首页 >技术杂谈 >节省90%编译时间,这是字节跳动开源的基于Rust的前端构建工具网站首页技术杂谈
节省90%编译时间,这是字节跳动开源的基于Rust的前端构建工具
Rspack 是一个基于 Rust 的高性能构建引擎,它可以与 Webpack 生态系统交互,并提供更好的构建性能。
在处理具有复杂构建配置的巨石应用时,Rspack 可以提供 5~10 倍的编译性能提升。
字节跳动将 Rspack 开源后,它在 GitHub 上已有 4700+ star。
在 2023 年 5 月 28 日 举行的「GOTC 全球开源技术峰会 - Rust 论坛」上,字节跳动前端工程师何相君介绍了 Rspack 这款新一代的前端构建工具,今天我们就为大家介绍这次分享的内容。
内容纲要:
- Rspack 简介
- 前端工具链 native 化的技术选型
- 遇到问题解决方案
- Rspack 性能收益
- 对 Rspack 的未来展望
Rspack 简介及技术架构
近几年 Web 应用规模变得越来越大,一个中大型项目,可能有几万个模块,使用 Webpack 进行打包的话可能需要 5~10 分钟。
尽管近几年有一些构建工具解决了 Webpack 构建速度慢的问题,比如 esbuild 和 vite,但是依然无法功能性上完全代替 Webpack。
在这样背景下,我们决定使用 Rust 重新移植 Webpack,在尽可能不降低 Webpack 灵活性与丰富的功能的同时,尽可能的提高构建性能。
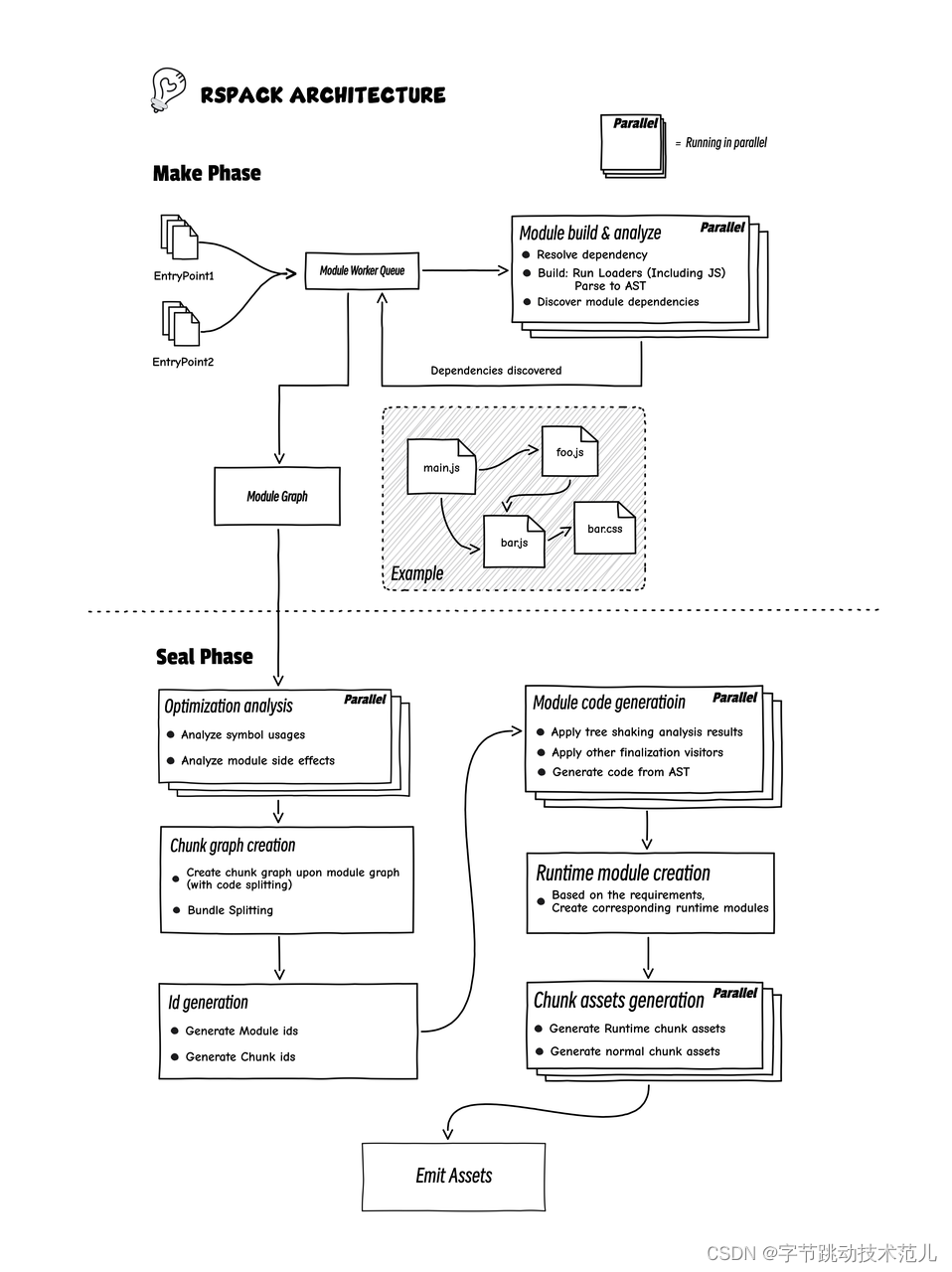
简单介绍一下 Rspack 的架构。Rspack 的架构和 Webpack 比较类似,对很多阶段做了多线程的并行加速。
主要可以分两块,第一个阶段是 make 阶段,主要分析项目依赖,然后生成一个模块依赖图;第二个阶段 seal 阶段,主要是做代码产物优化以及最终产物生成。
产物优化主要包括 tree-shaking 和 bundle-splitting, code-splitting 以及 minify。
tree-shaking 使用类似垃圾回收 mark-sweep 算法,遍历所有可能被执行的代码,将所有不会被执行的代码删除。
code-splitting 通过重新将模块进行组合,使用一些策略将其分割生成若干 chunk,最终达到更快速的浏览器加载,更高的 CDN 缓存命中率。
技术选型
那么,我们是如何为 Rspack 做技术选型的呢?

我们的目标,或者说现在大部分市面上的 native 化的工具,目标可能都只有两点:一是和目标移植工具的Javascript API 保持兼容,二是尽可能提高构建速度。
对目标语言生态做简单的调研后,我们留下了 3 个可选项:
1. Rust
2. Javascript(Node.js)
3. Golang
为什么不用 JavaScript(Node.js) ?
使用Node.js我们不用担心 API 兼容的问题,但是Node.js 单线程优化的潜力不大,所以尝试使用Node.js 提供的多线程能力提高性能。
我们在实际使用 Node.js 做多线程编程的时候发现有些问题,Node.js 虽然提供了 worker-thread 来提供多线程,但由于它是通过创建新的 V8 实例来模拟多线程,这些 V8 实例是没有办法共享内存的。
如果你想做线程间通信,只能用消息传递。但 worker-thread 消息传递有个问题,所有的消息都需要结构性拷贝,也就是深拷贝,没有办法像 Rust 中,直接将对象移动到另一个线程,这一定程度上增加了通信的开销。
第二个是它的并发编程的生态比较差,它没有像 Rust 社区提供丰富的底层数据结构以及并发原语,比如没有现成的无锁的并发数据结构,只支持几种基本的原子类型等等。
为了给大家更直观的感受,做了一个比较简单的 Benchmark。
简单的多线程基准测试:使用多线程解决一个生产消费者问题
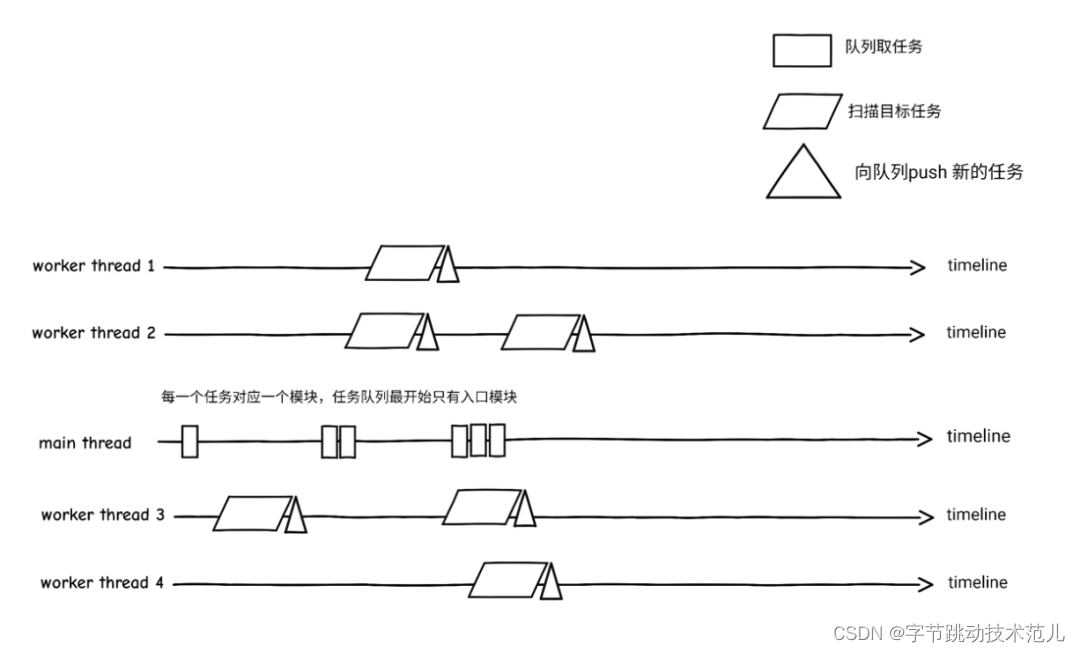
结果:

为什么不用 Golang ?
Golang 本身在性能方面是足够优秀的,但出于以下两个原因我们没有选择它。
1. 由于语言定位和本身生态原因,Golang 对 napi 支持不好。
为什么 napi 对我们这么重要?
因为 Webpack 的插件 API 是非常灵活的,除了字面量和对象类型,它也支持传递函数来做运行时动态配置。
虽然使用传统的 IPC 也可以模拟函数调用,但我们需要在 native 侧调用一个 Javascript 的函数时,把参数先序列化,通过 IPC 传递到 Javascript,然后 Javascript 这边再进行反序列化,最后执行 Javascript 函数再将返回值传输回 native 侧,一次函数调用需要两次跨进程通信。
函数调用次数有可能和模块的数量成正比,当模块数量比较大的时候这些额外消耗就变得无法忽略了。napi 可以将函数指针传递到 native 侧从而降低一些进程间通信的消耗。
2. Golang 自身的前端工具链生态不够成熟和繁荣。
Golang社区提供构建一个前端构建工具的基础设施,比如 Javascript passer、CSS passer,同时也可以做一些简单的分析,但不支持将 ES6 转译到 ES5。我们不得不再找一些其他 transpiler 来做这件事,这无疑又会增加额外消耗 (两次 transpile会严重影响性能)。
为什么转译到低版本的 ES5 对我们很重要?
因为国内平均浏览器版本并不是很高,为了支持一些低版本的用户,我们必须要把代码转译到 ES5。
为什么用 Rust ?
使用 Rust 的理由就比较简单了,因为前面的问题它都没有(这里不是说rust 是完美的,只是在当前场景下没有前两种选型的问题)。
1. Rust 性能很好,和 C/CPP 一个级别。
2. napi 支持良好,降低了我们在兼容 webpack 复杂 API 时的心智负担,除此之外,因为有宏的支持,我们可以少写很多样板代码。
3. Rust 作为 WASM 的一等公民,WASM 特性支持比较好,对新特性跟进的速度也比较快,更方便我们将现有工具迁移到 web。
4. Rust 生态中的 SWC 提供丰富的 AST 修改 API, 且提供转译到低版本 ES5的支持。
小结
现阶段如果你想通过移植来提高前端工具速度的话,Rust 绝对是非常值得一试。原因如下:
1. 如果你需要支持在Web端体验该工具,Rust 对于 WebAssembly(WASM)有非常出色的支持。结合 wasm-pack ,你可以以较小的成本将工具迁移到Web平台。
2. 由于 Rust社区(napi-rs) 对 napi 有成熟的支持,你可以较轻松地做复杂的 JavaScript API 兼容。
3. 在过去几年中,Rust 社区涌现了许多面向新手友好的教程,使得入门门槛大大降低了。
4. Rust 社区有很多现成的前端工具移植case可以借鉴,相较其他语言的前端工具生态更加繁荣。
性能收益
在我们的实验中,Rspack 的耗时比 Webpack 显著缩短。
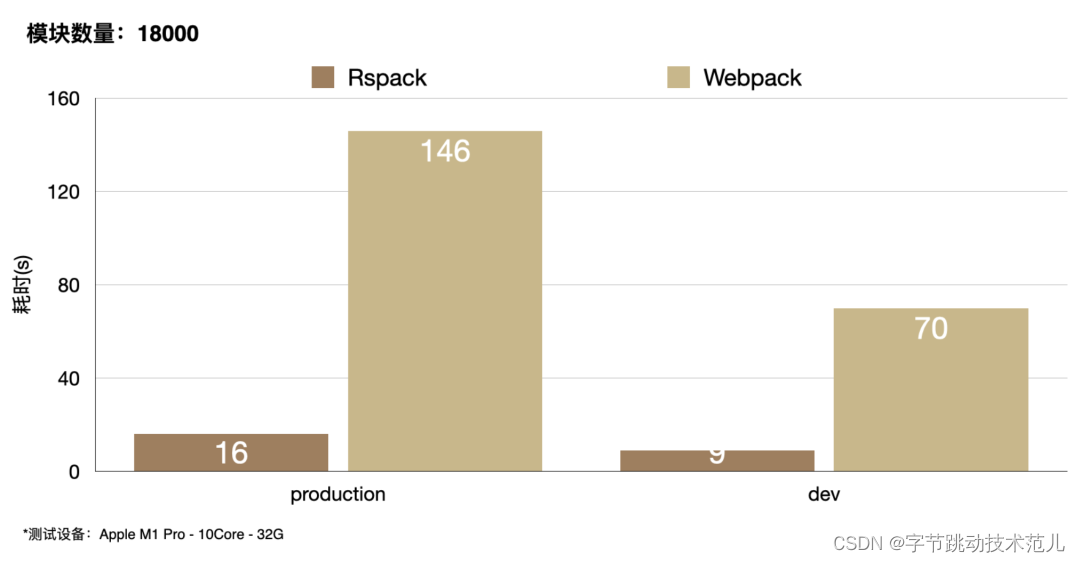
在 production 模式中从 146 秒缩到 16 秒,耗时缩短将近九成。
在 development 模式中,耗时缩短 87%。
遇到的问题 & 解决方案
下面我们针对两个问题来介绍一些性能优化的技巧。
多线程优化(举解决 SWC 并发解析性能差的例子)
- Development 模式下不会做过多的优化,parsing 是阶段的主要瓶颈
- 通过 profiler 发现 parsing 的时候有大量锁的系统调用
- 最后发现是 swc 使用了一个 string-intern 库 string-cache 导致的
简单介绍 string cache
在许多编程语言中,字符串常量(literal)通常是不可变的,这意味着如果在程序中使用相同的字符串常量多次,每个实例都会在内存中创建一个新的对象。这样做会占用大量内存,并可能降低程序的性能。
为了避免这个问题,一些编程语言提供了字符串池(string pool)或字符串缓存(string cache)机制。字符串池是一个存储字符串常量的地方,它会在程序运行时自动维护,并且保证每个字符串常量只有一个实例。这样,如果在程序中使用相同的字符串常量多次,每个实例都会指向池中的同一对象,从而节省内存并提高程序性能。
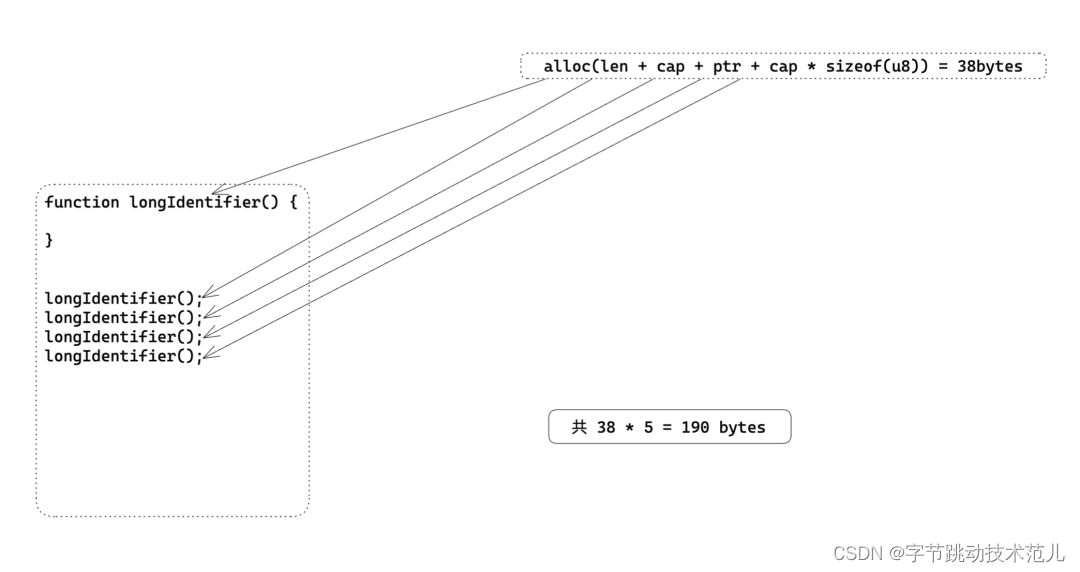

简单介绍下 string-cache
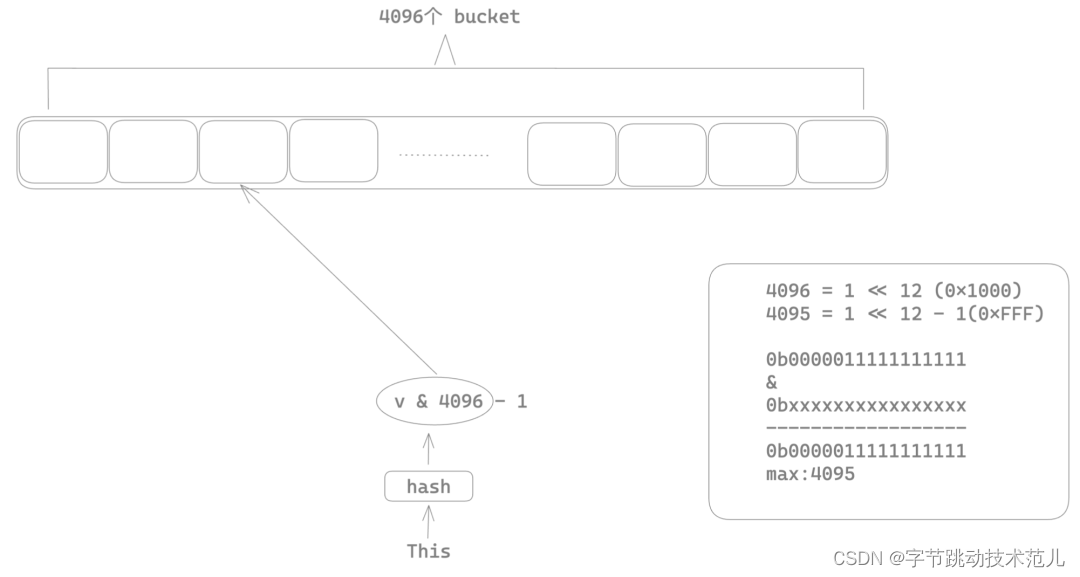
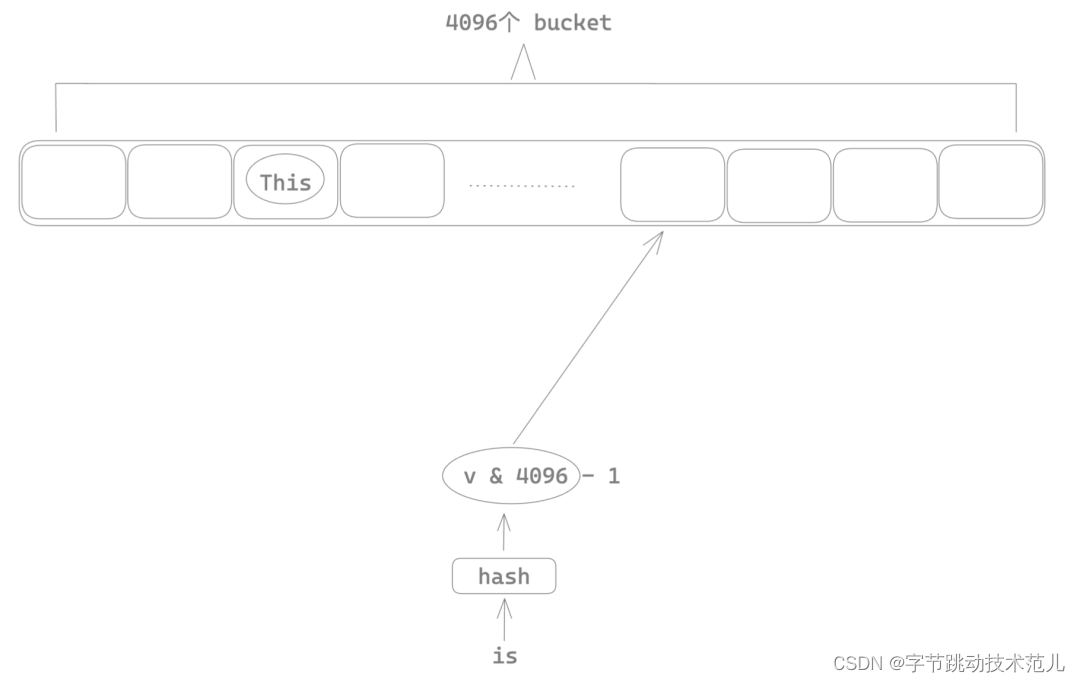
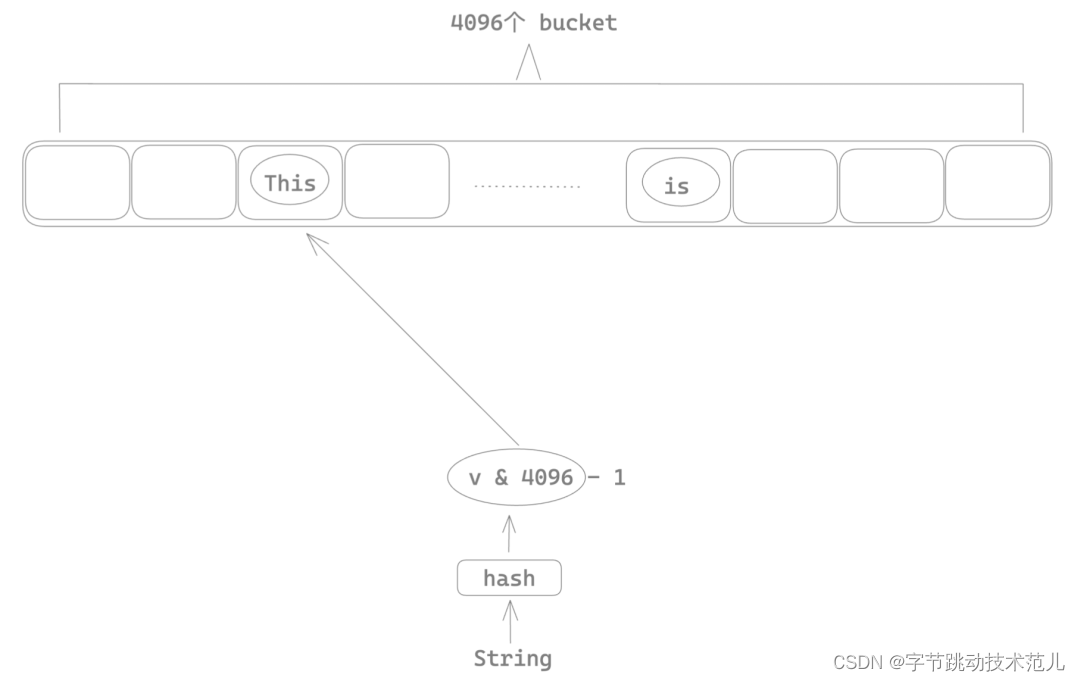
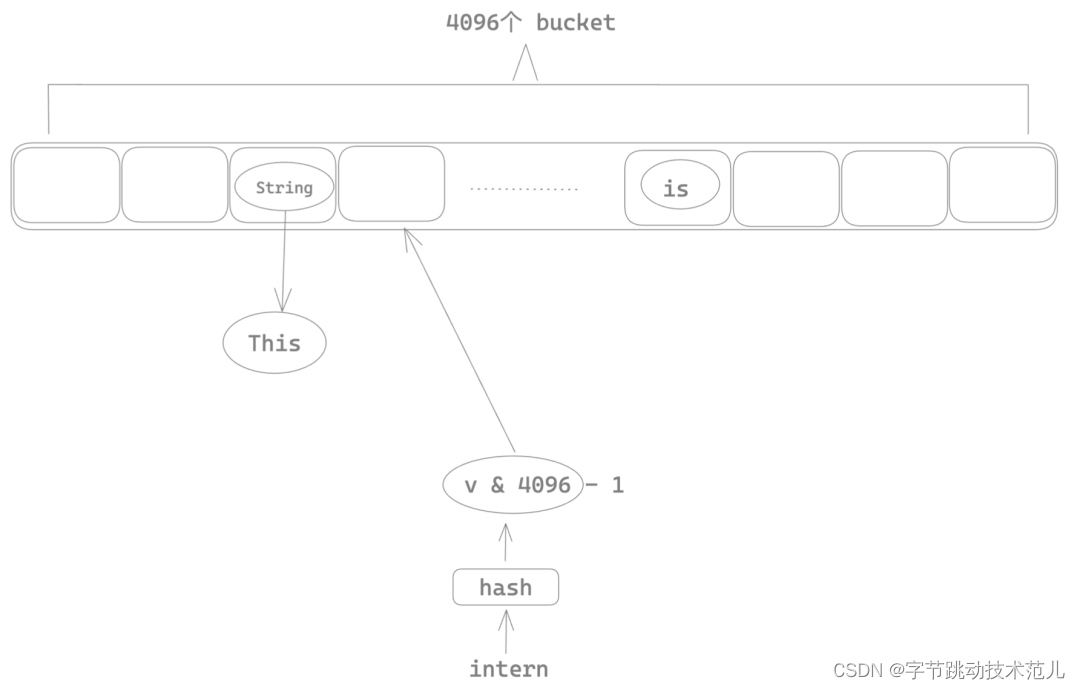
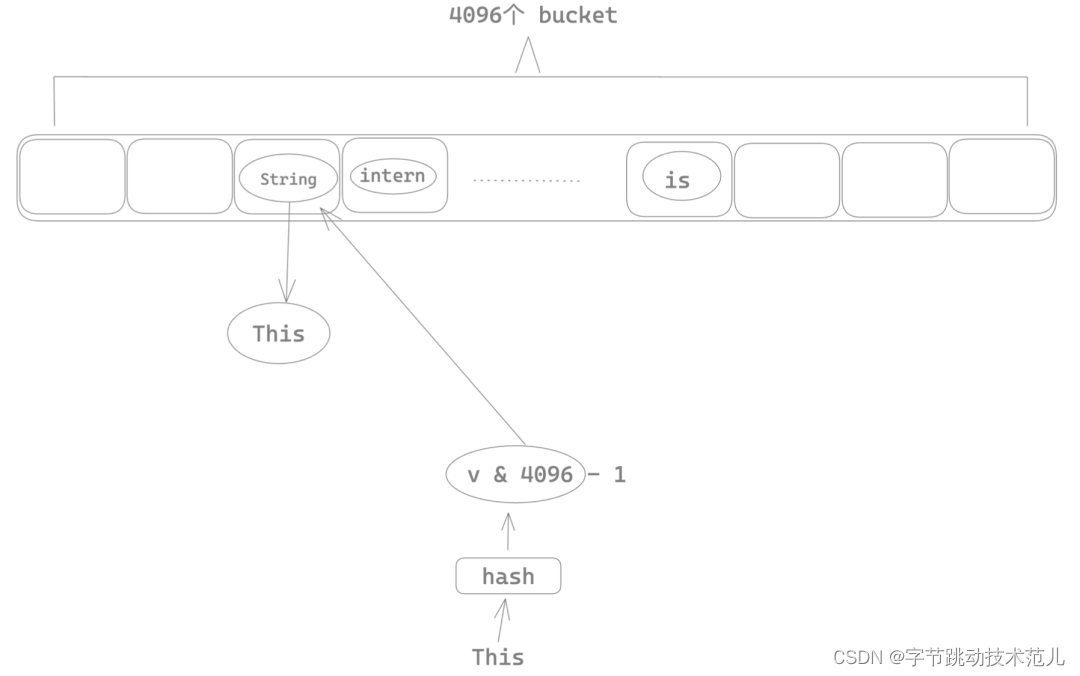
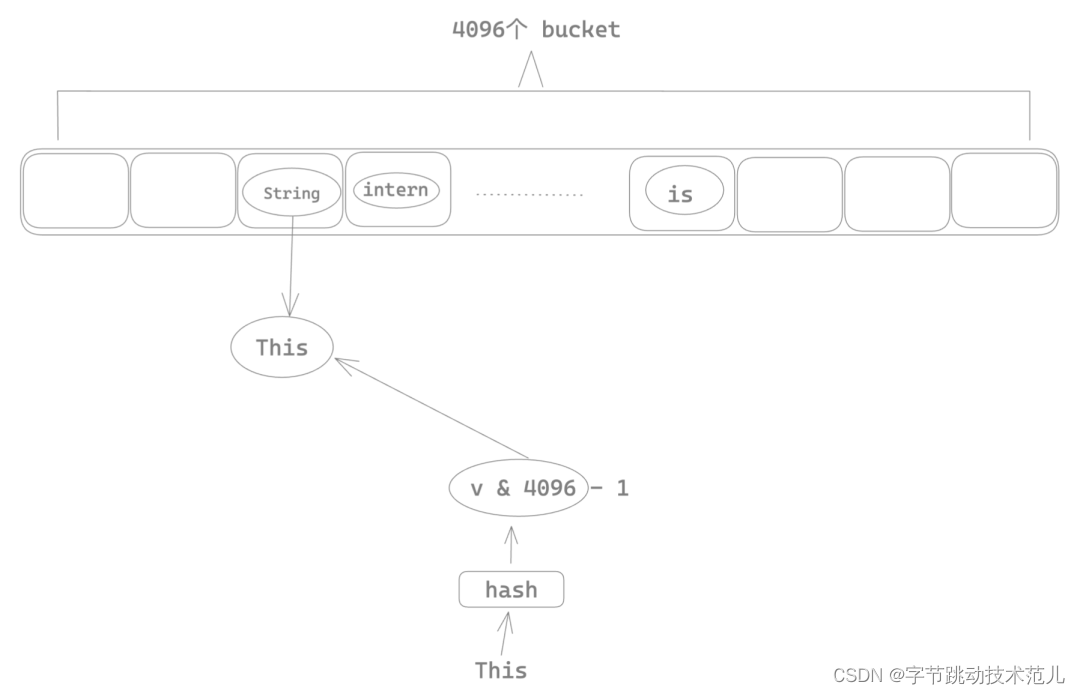
String cache 的性能瓶颈
使用 Mutux 将整个 string intern 的insert 操作加锁,导致多线程场景下任意时刻只有一个线程可以进行 string intern,其他线程只能等待,这也就是为什么前面 parsing 过程会有很多锁的系统调用。
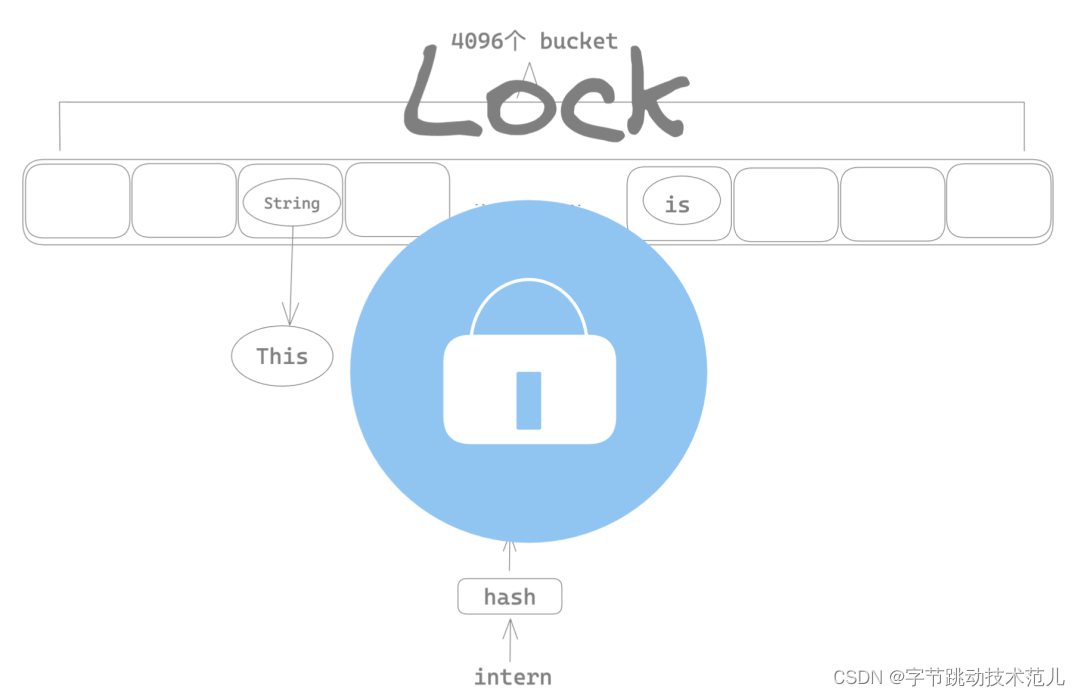
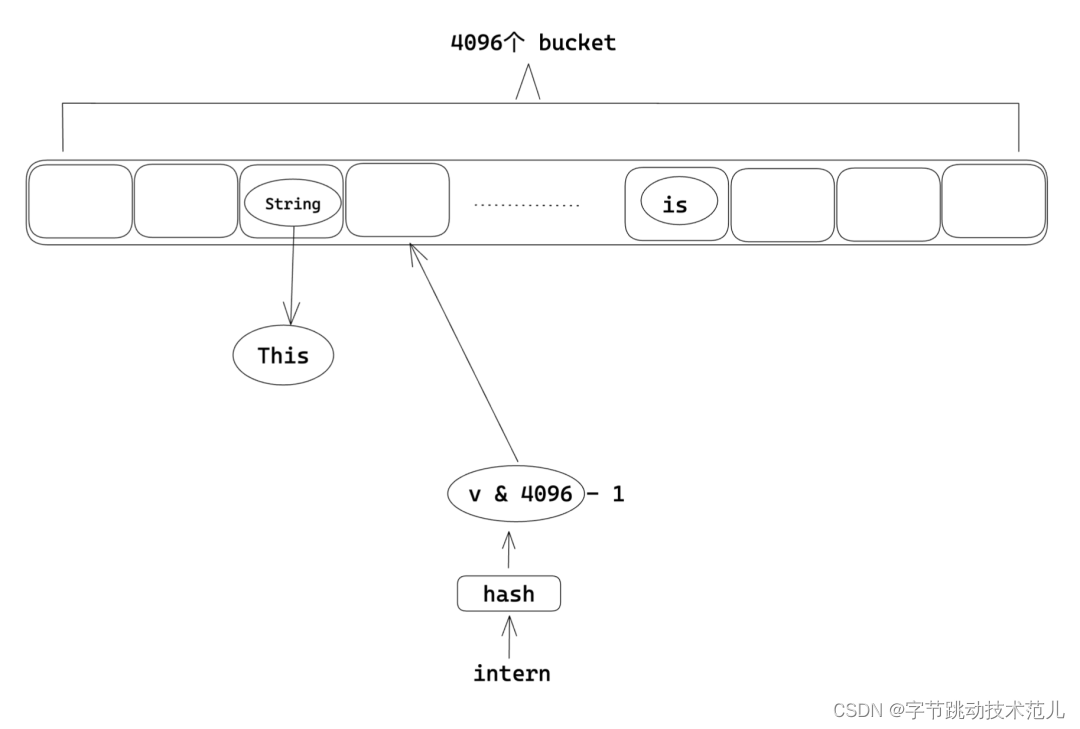
性能优化方法:将 insert 级别的大锁移动到 bucket 上,这样只有命中相同的桶序号的两个 string 会互斥,不同bucket index 的 string 在 intern 的时候可以并行。
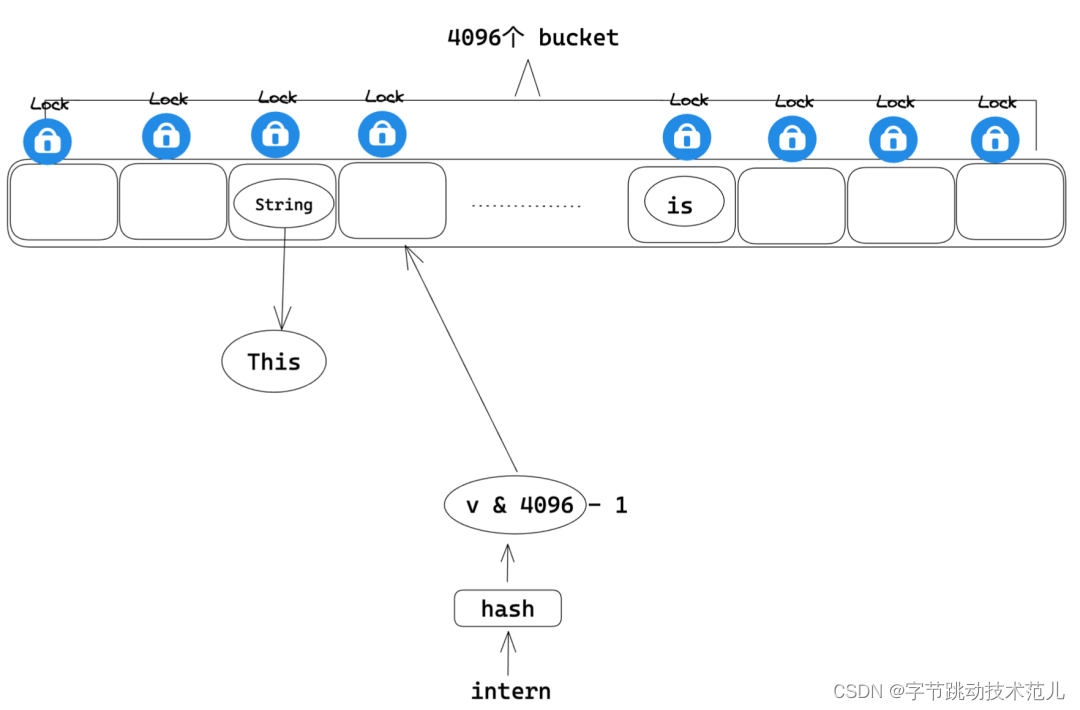
string-cache 优化结果对比:
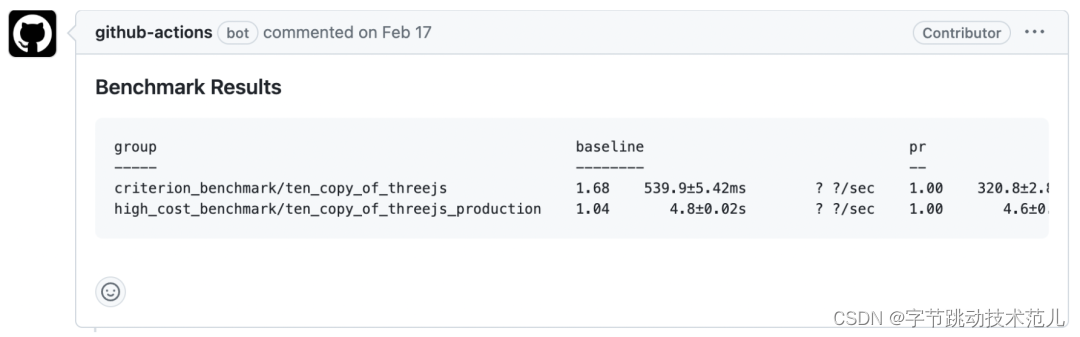
Development 模式有 41% 的提升,production 模式有 4% 的提升。
总结
核心, 降低锁的使用, 最大化 CPU 利用率, 以下是一些常见的策略:
- 使用无锁的数据结构 (crossbeam等)
- rayon (iter -> par_iter)。拆分 mutable 和 immutable 代码,尽可能使用 rayon 去并行你的代码。
- 降低锁的粒度, 减少不必要的临界区
算法的优化:不慎引入O(n^2)算法导致性能问题
背景
业务方反馈,开启 source-map 和不开启在生产环境有很大性能差异。
性能优化之前,需要挑选一个趁手的 profile 工具:
- Instruments
- Samply
- tracing (tokio tracing + perfetto / chrome-tracing)
- Perf
- flamegraph
使用 samply 生成 profile:
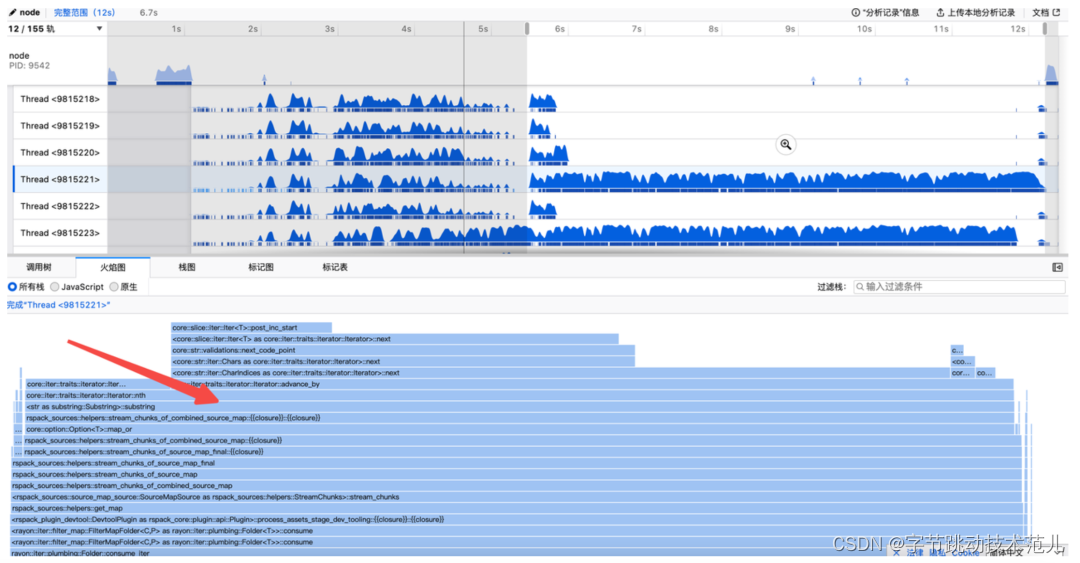
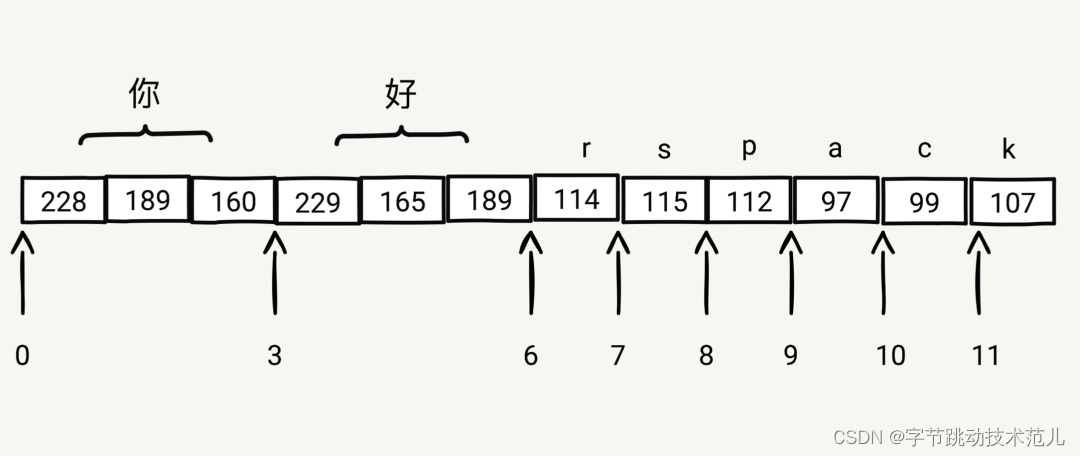
String 在 Rust 中的存储形式:
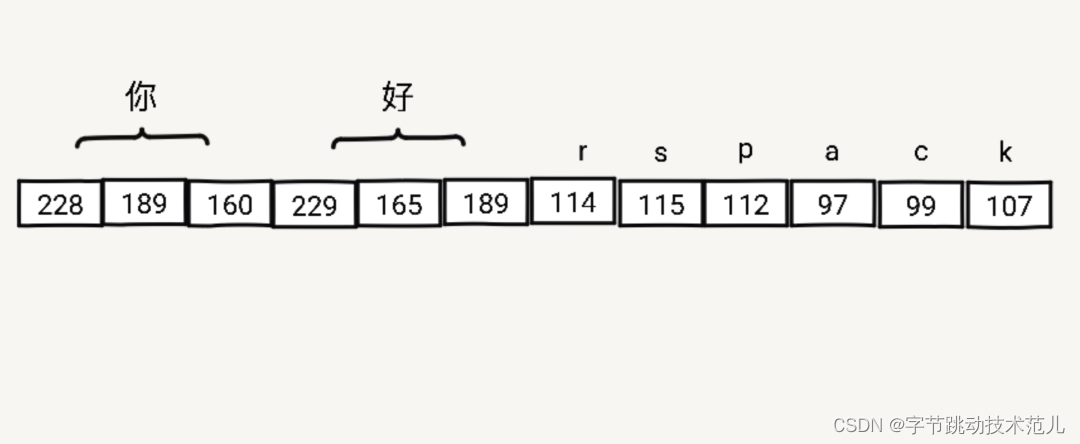
以"好rspac"为例:
- 获取到"好"byte offset
- "你".len_utf8()=3
- 获取到"k"byte offset
- ['你','好','r','s','p','a','c'l.iter().map(|ch| ch.len_utf8()).sum()= 11
- 使用 range 3..11获取 string slice
简单介绍 substring::Substring
fn substring(&self, start_index: usize, end_index: usize) -> &str {
if end_index <= start_index {
return "";
}
let mut indices = self.char_indices();
let obtain_index = |(index, _char)| index;
let str_len = self.len();
unsafe {
// SAFETY: Since `indices` iterates over the `CharIndices` of `self`, we can guarantee
// that the indices obtained from it will always be within the bounds of `self` and they
// will always lie on UTF-8 sequence boundaries.
self.slice_unchecked(
indices.nth(start_index).map_or(str_len, &obtain_index),
indices
.nth(end_index - start_index - 1)
.map_or(str_len, &obtain_index),
)
}
} 性能瓶颈产生的原因:
1. substring 被调用的是次数和 mapping 数量成正比
2. 通常 mapping 数量比较,所以在大部分情况下,该实现没有性能问题
3. 在 minify 场景下,因为除了第一行的代码,剩余代码的位置都讲发生变化,mapping 数量级与压缩产物大小只差常数倍数(在计算时间复杂度的时候会被忽略)
4. 该过程的时间复杂度约为 O(n^2),n为压缩后产物大小
性能优化:
使用前缀和数组提前计算好每一个 char offset 到 byte offset映射关系。
看一下优化收益:
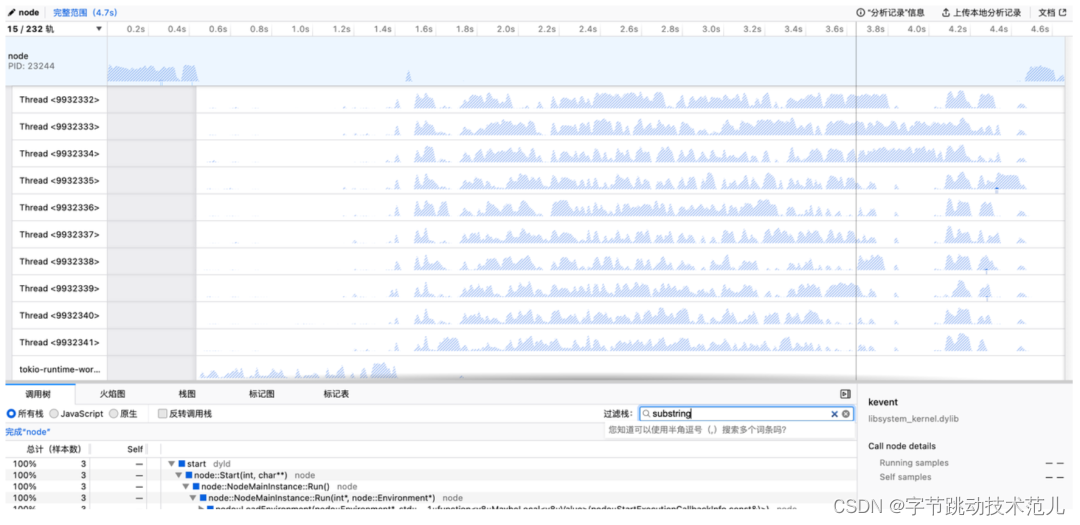
针对不同大小的产物有 30%~1000% 的提升。
总结:
- 好的profile工具能让你事半功倍
- 任何时间复杂度的算法在的数据规模小的时候差距都不大
- 做算法时间复杂度分析时不能只统计可见的代码,需要统计函数数以及库
未来展望
对于 Rspack,我们未来计划做三个方面的工作:
1. 使用 io-uring 加速 IO 部分
2. 借鉴 salsa-rs 进一步优化增量构建性能
3. 探索使用原生语言写高性能插件
以上就是今天的分享,谢谢大家。
GitHub:
https://github.com/web-infra-dev/rspack
官网:
https://www.rspack.dev/zh/






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结