您现在的位置是:首页 >技术交流 >【云原生-K8s-2】kubeadm搭建k8s高可用集群(三主两从一VIP)完整教程网站首页技术交流
【云原生-K8s-2】kubeadm搭建k8s高可用集群(三主两从一VIP)完整教程
?博主简介
?云计算领域优质创作者
?华为云开发者社区专家博主
?阿里云开发者社区专家博主
?交流社区:运维交流社区 欢迎大家的加入!
文章目录
Kubernetes高可用集群部署
准备工作(所有节点都要做同样的操作)
服务器配置
| 高可用集群(三主两从一VIP) | 主机名 | ip地址 | 配置 | 需要用到的服务 |
|---|---|---|---|---|
| 主 | k8s-master1 | 172.16.11.215 | 2C/2G/50G | kubeadm,docker,keepalived,haproxy |
| 主 | k8s-master2 | 172.16.11.216 | 2C/2G/50G | kubeadm,docker,keepalived,haproxy |
| 主 | k8s-master3 | 172.16.11.217 | 2C/2G/50G | kubeadm,docker,keepalived,haproxy |
| 从 | k8s-node1 | 172.16.11.218 | 2C/2G/50G | kubeadm,docker |
| 从 | k8s-node2 | 172.16.11.219 | 2C/2G/50G | kubeadm,docker |
| VIP | k8s-vip | 172.16.11.220 | 2C/1G/50G | 什么都不用装 |
关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
如果在线上服务器之类的不能关闭防火墙,那就需要开启几个端口;(这里说的是k8所用到的端口)
- master节点:
| 规则 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|
| TCP | 6443* | Kubernetes API server | All |
| TCP | 2379-2380 | etcd server client API | kube-apiserver, etcd |
| TCP | 10250 | Kubelet API | Self, Control plane |
| TCP | 10251 | kube-scheduler | Self |
| TCP | 10252 | kube-controller-manager | Self |
- node节点:
| 规则 | 端口范围 | 作用 | 使用者 |
|---|---|---|---|
| TCP | 10252 | Kubelet API | Self, Control plane |
| TCP | 30000-32767 | NodePort Services** | All |
关闭selinux
临时关闭selinux(沙河)如需永久关闭selinux需要修改为sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
#临时关闭selinux
setenforce 0
#永久关闭selinux
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
关闭交换分区
#临时关闭所有的交换分区
swapoff -a
#永久关闭所有的交换分区
sed -i '/swap/s/^(.*)$/#1/g' /etc/fstab
修改六台高可用集群的主机名:(每个主机限一条命令)
[root@k8s-master1 ~]# hostnamectl set-hostname k8s-master1
[root@k8s-master2 ~]# hostnamectl set-hostname k8s-master2
[root@k8s-master3 ~]# hostnamectl set-hostname k8s-master3
[root@k8s-node1 ~]# hostnamectl set-hostname k8s-node1
[root@k8s-node2 ~]# hostnamectl set-hostname k8s-node2
[root@k8s-vip ~]# hostnamectl set-hostname k8s-vip
所有节点都添加集群ip与主机名到hosts中:
cat >> /etc/hosts << EOF
172.16.11.215 k8s-master1
172.16.11.216 k8s-master2
172.16.11.217 k8s-master3
172.16.11.218 k8s-node1
172.16.11.219 k8s-node2
172.16.11.220 k8s-vip
EOF
注意:ip一定要改成自己的ip,不要直接复制粘贴
六台机器进行时间同步
#安裝同步时间命令
yum install ntpdate -y
#同步时间
ntpdate cn.pool.ntp.org
#设置定时任务每五分钟同步一次时间
echo "*/5 * * * * root /usr/sbin/ntpdate cn.pool.ntp.org &>/dev/null" >> /etc/crontab
特殊说明:
如果是克隆虚拟机建议执行rm -rf /etc/udev/* 保证网卡UUID不同
六台都安装需要的一些命令:
- 添加centos源并将下载地址更换为阿里云地址
#添加centos源
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
#将下载地址更换为阿里云地址
sed -i -e '/mirrors.cloud.aliyuncs.com/d' -e '/mirrors.aliyuncs.com/d' /etc/yum.repos.d/CentOS-Base.repo
- 添加epel扩展源
curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
- 清除缓存
yum clean all
- 重新加载源缓存
yum makecache
- 升级yum并安装一些会用到的命令
yum -y update && yum -y install lrzsz wget conntrack ipvsadm ipset jq psmisc sysstat curl iptables net-tools libseccomp gcc gcc-c++ yum-utils device-mapper-persistent-data lvm2 bash-completion sshpass
安装需要一些时间,就等待安装即可;
调整能打开文件数大小
[root@k8s-master1 ~]# ulimit -SHn 65535
[root@k8s-master1 ~]# cat >> /etc/security/limits.conf << EOF
* soft nofile 655360
* hard nofile 131072
* soft nproc 65535
* hard nproc 655350
* soft memlock unlimited
* hard memlock unlimited
EOF
补充说明:
ulimit用于限制shell启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、shell
进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的最大大小、CPU
时间、单个用户的最大线程数、Shell 进程所能使用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
hard:严格的设定,必定不能超过这个设定的数值 soft:警告的设定,可以超过这个设定值,但是若超过则有警告信息 限制资源:
- core – 限制内核文件的大小
- date – 最大数据大小
- fsize – 最大文件大小
- memlock – 最大锁定内存地址空间
- nofile – 打开文件的最大数目
- rss – 最大持久设置大小
- stack – 最大栈大小
- cpu – 以分钟为单位的最多 CPU 时间
- noproc – 进程的最大数目(系统的最大进程数)
- as – 地址空间限制 maxlogins – 此用户允许登录的最大数目
安装配置ipvsadm
#安装所需的命令(上面已经全部安装了,可以不用管)
[root@k8s-master1 ~]# yum -y install ipvsadm ipset sysstat conntrack libseccomp
#加载ipvs相关模块
[root@k8s-master1 ~]# modprobe -- ip_vs
[root@k8s-master1 ~]# modprobe -- ip_vs_rr
[root@k8s-master1 ~]# modprobe -- ip_vs_wrr
[root@k8s-master1 ~]# modprobe -- ip_vs_sh
[root@k8s-master1 ~]# modprobe -- nf_conntrack_ipv4
[root@k8s-master1 ~]# cat > /etc/modules-load.d/ipvs.conf << EOF
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack_ipv4
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF
[root@k8s-master1 ~]# systemctl enable --now systemd-modules-load.service
高可用集群设置免密登录(在 master1 节点上操作)
在
master1节点免密钥登录其他节点,安装过程中生成配置文件和证书均在master1上操作,集群管理也在master11上操作,阿里云或者AWS上需要单独一台kubectl服务器。
#生成密钥
[root@k8s-master1 ~]# ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa &> /dev/null
#循环给高可用集群进行免密设置
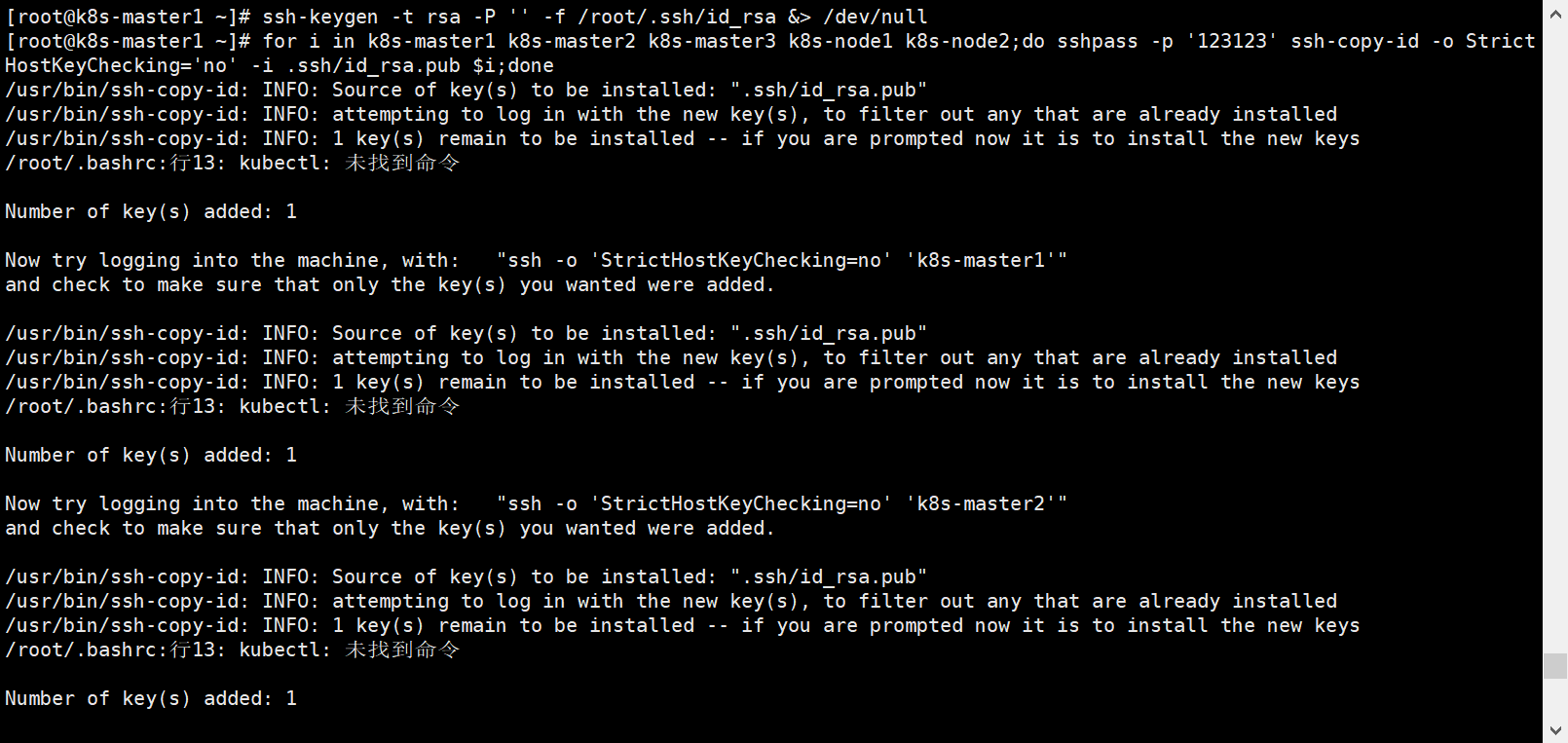
[root@k8s-master1 ~]# for i in k8s-master1 k8s-master2 k8s-master3 k8s-node1 k8s-node2;do sshpass -p '123123' ssh-copy-id -o StrictHostKeyChecking='no' -i .ssh/id_rsa.pub $i;done
#完成之后最好测试以下免密登录
如下图就属于成功;
部署 docker(所有节点都需要部署)
#安装docker所需的依赖包
[root@docker ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
#添加阿里云的docker镜像地址
[root@docker ~]# sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
&&#或者(二选一即可)
[root@docker ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
#更新缓存,只处理新添加的yum源缓存
[root@docker ~]# yum makecache fast
#部署docker,默认安装最新版本
[root@docker ~]# yum install -y docker-ce-20.10.14 docker-ce-cli-20.10.14 containerd.io
#查看安装docker版本
[root@docker ~]# docker --version(或者使用docker version)
Docker version 20.10.14, build a224086
#加载docker配置
[root@docker ~]# systemctl daemon-reload
#启动docker服务并设置开机自启
[root@docker ~]# systemctl start docker && systemctl enable docker
#查看docker可以安装的版本,也可以自己安装指定版本,yum -y install docker-ce-19.03.12.el7
[root@docker ~]# yum list docker-ce --showduplicates | sort -r
给docker添加镜像加速器及cgroup并重启docker服务
[root@docker ~]# mkdir -p /etc/docker
[root@docker ~]# tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://mrlmpasq.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
#由于新版kubelet建议使用systemd,所以可以把docker的CgroupDriver改成systemd
#重新加载docker配置
[root@docker ~]# systemctl daemon-reload
#重新启动docker服务
[root@docker ~]# systemctl restart docker
docker部署完成
部署 kubernetes(所有节点都要部署)
配置相关的内核参数
将桥接的IPv4 流量传递到iptables 的链
cat <<EOF >> /etc/sysctl.d/k8s.conf
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
fs.may_detach_mounts = 1
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.netfilter.nf_conntrack_max=2310720
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl =15
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_max_orphans = 327680
net.ipv4.tcp_orphan_retries = 3
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.ip_conntrack_max = 65536
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_timestamps = 0
net.core.somaxconn = 16384
EOF
#让其生效
sysctl --system
添加 k8s yum源
[root@docker ~]# cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#重新加载缓存
yum makecache fast
安装 kubeadm kubelet kubectl
注:安装这几个版本不要用最新的,容易出问题
yum install -y kubeadm-1.20.0-0 kubelet-1.20.0-0 kubectl-1.20.0-0
#查看kubeadm版本
kubeadm version
- 启动kubelet并设置开机自启
systemctl enable kubelet && systemctl start kubelet
kubernetes强化tab(安装之后会tab可以补全命令及参数)
- 配置环境
echo 'source <(kubectl completion bash)' >> ~/.bashrc
1、退出连接,重新连接;
2、或者bash更新环境就可以使用了。
部署keepalived、haproxy --> 配置高可用(所有 主节点 部署)
这里使用高可用和负载的组件为haproxy和keepalived,如果kubernets不是高可用架构,可以不做haproxy与keepalived。如果是公有云平台部署可以选择公用云自带的负载均衡来代替haproxy和keepalived,比如阿里云的SLB,或者腾讯云的ELB(
大部分公有云不支持keepalived)。如果使用的是阿里云,kubectl控制端不能放在master节点,因为阿里云SLB有回环问题,也就是说SLB代理的服务器不能反向访问这个问题,但是腾讯云修复了这个问题。
- 安装 keepalived 和 haproxy
yum -y install keepalived haproxy
所有 主节点 修改haproxy配置
最后的
server改为自己的主节点ip
[root@k8s-master1 ~]# cat /etc/haproxy/haproxy.cfg
global
maxconn 2000
ulimit-n 16384
log 127.0.0.1 local0 err
stats timeout 30s
defaults
log global
mode http
option httplog
timeout connect 5000
timeout client 50000
timeout server 50000
timeout http-request 15s
timeout http-keep-alive 15s
frontend monitor-in
bind *:33305
mode http
option httplog
monitor-uri /monitor
frontend k8s-master
bind 0.0.0.0:16443
bind 127.0.0.1:16443
mode tcp
option tcplog
tcp-request inspect-delay 5s
default_backend k8s-master
backend k8s-master
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server k8s-master1 172.16.11.215:6443 check
server k8s-master2 172.16.11.216:6443 check
server k8s-master3 172.16.11.217:6443 check
所有 主节点 配置keepalived (一个一个配置)
- k8s-master1节点配置
[root@k8s-master1 ~]# vim /etc/keepalived/keepalived.conf
[root@k8s-master1 ~]# cat /etc/keepalived/keepalived.conf
需要修改的地方有:(都需要根据自己的实际数值来改)
◎ interface #网卡名称
◎ mcast_src_ip #该节点的ip
◎ virtual_ipaddress #vip地址
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state MASTER #高可用主1
interface eth0 #网卡名称
mcast_src_ip 172.16.11.215 #该节点 IP
virtual_router_id 51
priority 101 #设置最高级优先级
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
172.16.11.220 #vip地址
}
track_script {
chk_apiserver
}
}
- k8s-master2节点配置
[root@k8s-master2 ~]# vim /etc/keepalived/keepalived.conf
[root@k8s-master2 ~]# cat /etc/keepalived/keepalived.conf
需要修改的地方有:(都需要根据自己的实际数值来改)
◎ interface #网卡名称
◎ mcast_src_ip #该节点的ip
◎ virtual_ipaddress #vip地址
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP #高可用从1
interface eth0 #网卡名称
mcast_src_ip 172.16.11.216 #该节点 IP
virtual_router_id 51
priority 100 #设置优先级
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
172.16.11.220 #vip地址
}
track_script {
chk_apiserver
}
}
- k8s-master3节点配置
[root@k8s-master3 ~]# vim /etc/keepalived/keepalived.conf
[root@k8s-master3 ~]# cat /etc/keepalived/keepalived.conf
需要修改的地方有:(都需要根据自己的实际数值来改)
◎ interface #网卡名称
◎ mcast_src_ip #该节点的ip
◎ virtual_ipaddress #vip地址
! Configuration File for keepalived
global_defs {
router_id LVS_DEVEL
script_user root
enable_script_security
}
vrrp_script chk_apiserver {
script "/etc/keepalived/check_apiserver.sh"
interval 5
weight -5
fall 2
rise 1
}
vrrp_instance VI_1 {
state BACKUP #高可用从2
interface ens33 #网卡名称
mcast_src_ip 172.16.11.217 #该节点 IP
virtual_router_id 51
priority 99 #设置优先级
advert_int 2
authentication {
auth_type PASS
auth_pass K8SHA_KA_AUTH
}
virtual_ipaddress {
172.16.11.220 #vip地址
}
track_script {
chk_apiserver
}
}
所有 主节点 编写健康检测脚本
[root@k8s-master1 ~]# vim /etc/keepalived/check_apiserver.sh
[root@k8s-master1 ~]# cat /etc/keepalived/check_apiserver.sh
#!/bin/bash
err=0
for k in $(seq 1 3);do
check_code=$(pgrep haproxy)
if [[ $check_code == "" ]]; then
err=$(expr $err + 1)
sleep 1
continue
else
err=0
break
fi
done
if [[ $err != "0" ]]; then
echo "systemctl stop keepalived"
/usr/bin/systemctl stop keepalived
exit 1
else
exit 0
fi
#给监测脚本添加执行权限
[root@k8s-master1 ~]# chmod +x /etc/keepalived/check_apiserver.sh
所有 主节点 启动 keepalived 与 haproxy
#生效配置文件
[root@k8s-master1 ~]# systemctl daemon-reload
#启动并设置开机自启haproxy
[root@k8s-master1 ~]# systemctl enable --now haproxy
Created symlink from /etc/systemd/system/multi-user.target.wants/haproxy.service to /usr/lib/systemd/system/haproxy.service.
#启动并设置开机自启keepalived
[root@k8s-master1 ~]# systemctl enable --now keepalived
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
k8s-master1主节点查看VIP
#查看IP与vip的IP
[root@k8s-master1 ~]# hostname -I
172.16.11.215 172.16.11.220 172.17.0.1
#测试vip的16443端口是否通
[root@k8s-master1 ~]# telnet 172.16.11.220 16443
Trying 172.16.11.220...
Connected to 172.16.11.220.
Escape character is '^]'.
Connection closed by foreign host.
master节点初始化(所有 master节点 操作,有单独在 master1节点 操作的则在master1节点操作即可)
k8s-master1节点创建kubeadm-config.yaml配置文件如下:当然,也可以利用命令kubeadm config print init-defaults生成配置文件模板,然后进行修改:
需要自行修改的有:
◎ advertiseAddress #自己的master1节点IP
◎ name #自己的master1节点的名称
◎ certSANs #vip地址
◎ controlPlaneEndpoint #vip地址
◎ kubernetesVersion #kubernets版本
◎ podSubnet #pod网段
◎ serviceSubnet #service网段
[root@k8s-master1 ~]# vim kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: 7t2weq.bjbawausm0jaxury #初始化集群使用的token
ttl: 24h0m0s #token有效期
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 172.16.11.215
bindPort: 6443
nodeRegistration: #集群节点的信息
criSocket: /var/run/dockershim.sock
name: k8s-master1
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
---
apiServer:
certSANs:
- 172.16.11.220
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: 172.16.11.220:16443 #连接apiserver的地址
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.cn-hangzhou.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: v1.20.0 #与kubernets版本对应
networking:
dnsDomain: cluster.local
podSubnet: 172.16.10.1/18
serviceSubnet: 172.17.0.1/16 #pod,service与宿主机都不在同一个网段
scheduler: {}
更新配置文件
kubeadm config migrate --old-config kubeadm-config.yaml --new-config new.yaml
将new.yaml文件复制到其他master节点,之后所有Master节点提前下载镜像,可以节省初始化时间
scp new.yaml 172.16.11.216:/root/
scp new.yaml 172.16.11.217:/root/
查看需要的镜像文件
kubeadm config images list --config /root/new.yaml
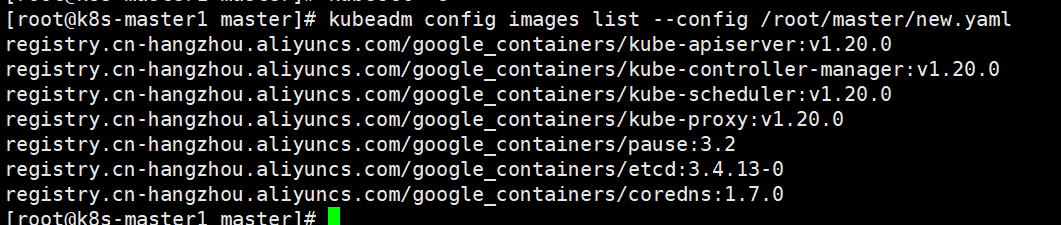
所有master节点启动
kubeadm config images pull --config /root/new.yaml
master1节点 初始化,初始化后生成对应的证书
kubeadm init --config /root/new.yaml --upload-certs

说明:生成的token有效期为2个小时,如果token过期后,可以采用一下方案解决;
Token过期后生成新的token:
kubeadm token create --print-join-command
Master需要生成–certificate-key
kubeadm init phase upload-certs --upload-certs
master1节点 配置环境变量,用于访问Kubernetes集群
cat <<EOF >> /root/.bashrc
export KUBECONFIG=/etc/kubernetes/admin.conf
EOF
#让其生效
source /root/.bashrc
在 master1节点 查看集群节点状态
kubectl get nodes

采用初始化安装方式,所有的系统组件均以容器的方式运行并且在kube-system命名空间内,此时可以查看Pod状态:
kubectl get pods -n kube-system -o wide

可以看到有两个READY的状态是0/1,这个不用担心,后面节点加入之后就好了。
他是执行的时候有一个告警:Warning FailedScheduling 7s (x3 over 2m7s) default-scheduler 0/1 nodes are available: 1 node(s) had taint {node.kubernetes.io/not-ready: }, that the pod didn't tolerate。
其他master节点加入集群(master2 和 master3 节点操作)
[root@k8s-master2 ~]# kubeadm join 172.16.11.220:16443 --token 7t2weq.bjbawausm0jaxury
--discovery-token-ca-cert-hash sha256:f370e43a5b3218b7b6094980edd4fac3b6104a272e465767d3c78dfad8c62066
--control-plane --certificate-key 26270907ae9b940062bd9f5e4daad59e2804a4a5bdbfb61c7ebb0e6d2f5e5839
[root@k8s-master3 ~]# kubeadm join 172.16.11.220:16443 --token 7t2weq.bjbawausm0jaxury
--discovery-token-ca-cert-hash sha256:f370e43a5b3218b7b6094980edd4fac3b6104a272e465767d3c78dfad8c62066
--control-plane --certificate-key 26270907ae9b940062bd9f5e4daad59e2804a4a5bdbfb61c7ebb0e6d2f5e5839
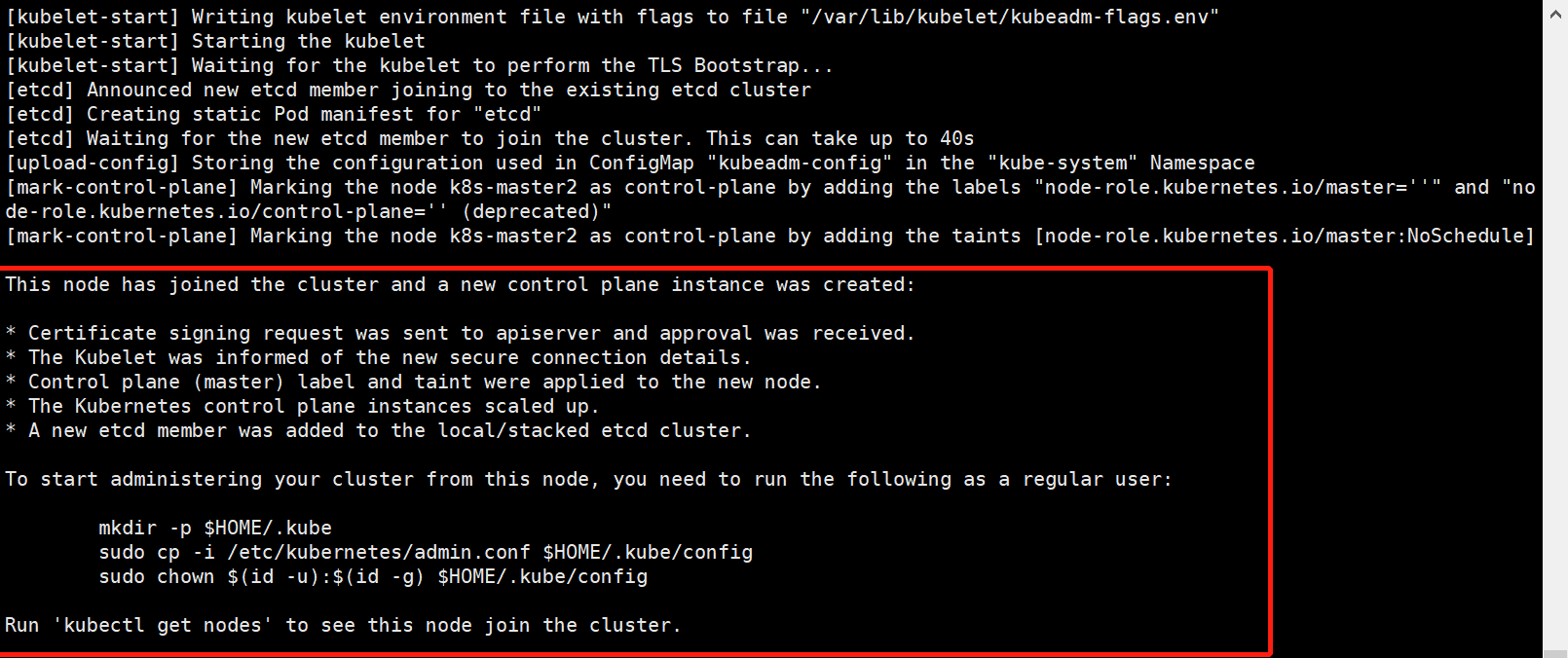
加入成功,可以在master1上使用kubectl get nods来查看。
Node节点配置(node1 和 node2 节点操作)
Node节点上主要部署公司的一些业务应用,生产环境中不建议Master节点部署系统组件之外的其他Pod,测试环境可以允许Master节点部署Pod以节省系统资源。
- 将node节点添加到集群
[root@k8s-node1 ~]# kubeadm join 172.16.11.220:16443 --token 7t2weq.bjbawausm0jaxury
--discovery-token-ca-cert-hash sha256:f370e43a5b3218b7b6094980edd4fac3b6104a272e465767d3c78dfad8c62066
[root@k8s-node2 ~]# kubeadm join 172.16.11.220:16443 --token 7t2weq.bjbawausm0jaxury
--discovery-token-ca-cert-hash sha256:f370e43a5b3218b7b6094980edd4fac3b6104a272e465767d3c78dfad8c62066
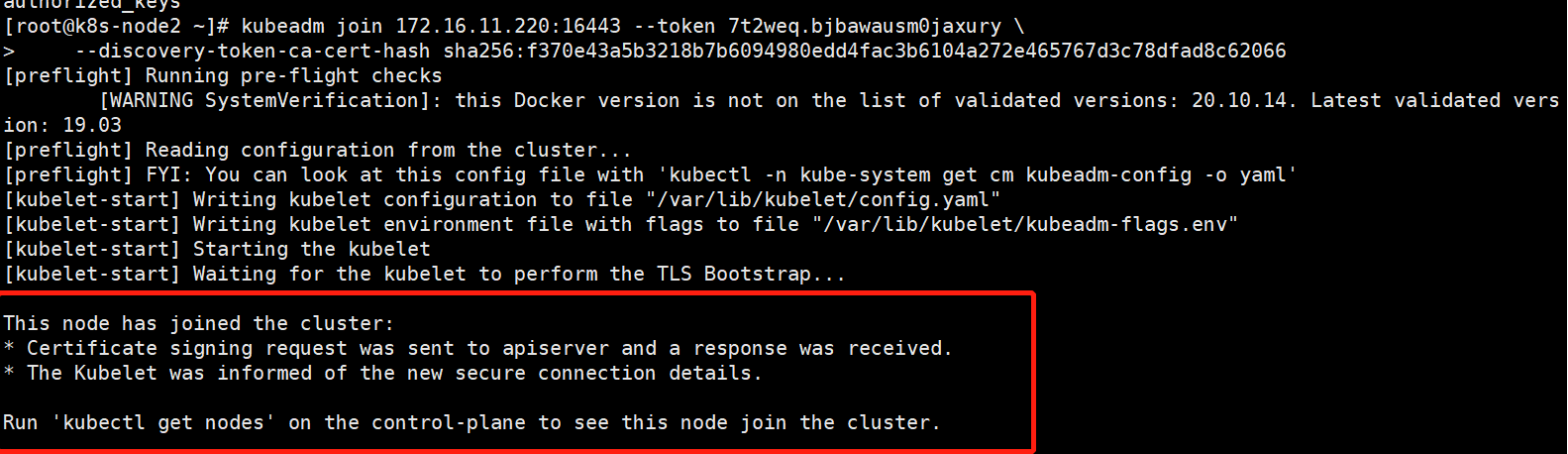
加入成功,可以在master1上使用kubectl get nods来查看。
- master1查看所有节点
[root@k8s-master1 ~]# kubectl get nodes
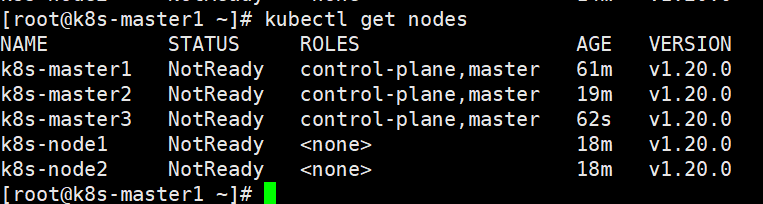
现在的集群状态都是NotReady表示不可达;这是因为还没有安装网络插件,下面我们来安装一下网络插件(caclico)
Calico组件(只在 master1节点 操作)【网络插件,用于连接其他节点】
Calico是一个纯三层的协议,为OpenStack虚拟机和Docker容器提供多主机间通信。Calico不使用重叠网络比如flannel和libnetwork重叠网络驱动,它是一个纯三层的方法,使用虚拟路由代替虚拟交换,每一台虚拟路由通过BGP协议传播可达信息(路由)到剩余数据中心。
拉取安装包(安装包内包含:Calico组件、Metrics组件、Dashboard组件)
git clone https://github.com/dotbalo/k8s-ha-install.git
如果拉取不下来,可以参考该地址下载:
#拉取完成进入该目录
cd k8s-ha-install
#切换到manual-installation-v1.20.x分支
[root@k8s-master1 k8s-ha-install]# git checkout manual-installation-v1.20.x
修改相关的配置文件
#进入calico目录
[root@k8s-master1 k8s-ha-install]# cd calico/
注意事项:
◎ 需要改的就只要第一行的ip
#将要修改的ip改为自己的ip,按照master节点顺序的改成自己的节点ip
[root@k8s-master1 calico]# sed -i 's#etcd_endpoints: "http://<ETCD_IP>:<ETCD_PORT>"#etcd_endpoints: "https://172.16.11.215:2379,https://172.16.11.216:2379,https://172.16.11.217:2379"#g' calico-etcd.yaml
#设置临时环境变量ETCD_CA查看ca.crt文件并转化为base64格式取消换行符
[root@k8s-master1 calico]# ETCD_CA=`cat /etc/kubernetes/pki/etcd/ca.crt | base64 | tr -d '
'`
#设置临时环境变量ETCD_CERT查看server.crt文件并转化为base64格式取消换行符
[root@k8s-master1 calico]# ETCD_CERT=`cat /etc/kubernetes/pki/etcd/server.crt | base64 | tr -d '
'`
#设置临时环境变量ETCD_KEY查看server.key文件并转化为base64格式取消换行符
[root@k8s-master1 calico]# ETCD_KEY=`cat /etc/kubernetes/pki/etcd/server.key | base64 | tr -d '
'`
#更换calico-etcd.yaml文件中的# etcd-key: null、# etcd-cert: null、# etcd-ca: null为指定值,临时的环境变量这这用。
[root@k8s-master1 calico]# sed -i "s/# etcd-key: null/etcd-key: ${ETCD_KEY}/g; s/# etcd-cert: null/etcd-cert: ${ETCD_CERT}/g; s/# etcd-ca: null/etcd-ca: ${ETCD_CA}/g" calico-etcd.yaml
#更换calico-etcd.yaml文件中的etcd_ca: ""#、etcd_cert: ""、etcd_key: "" 为指定值
[root@k8s-master1 calico]# sed -i 's#etcd_ca: ""#etcd_ca: "/calico-secrets/etcd-ca"#g; s#etcd_cert: ""#etcd_cert: "/calico-secrets/etcd-cert"#g; s#etcd_key: "" #etcd_key: "/calico-secrets/etcd-key" #g' calico-etcd.yaml
#设置临时环境变量POD_SUBNET从kubernetes配置文件中查找自己的网关
[root@k8s-master1 calico]# POD_SUBNET=`cat /etc/kubernetes/manifests/kube-controller-manager.yaml | grep cluster-cidr= | awk -F= '{print $NF}'`
#注意下面的这个步骤是把calico-etcd.yaml文件里面的CALICO_IPV4POOL_CIDR下的网段改成自己的Pod网段,并打开注释,不用手动改,会用到上面的环境变量;
[root@k8s-master1 calico]# sed -i 's@# - name: CALICO_IPV4POOL_CIDR@- name: CALICO_IPV4POOL_CIDR@g; s@# value: "192.168.0.0/16"@ value: '"${POD_SUBNET}"'@g' calico-etcd.yaml
创建运行并查看容器状态
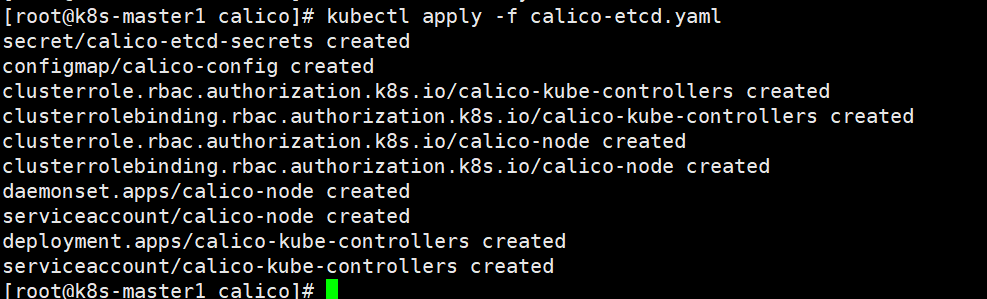
- 创建并运行yaml文件
[root@k8s-maste1 calico]# kubectl apply -f calico-etcd.yaml
- 查看创建的容器状态
[root@k8s-master1 calico]# kubectl get pods -n kube-system
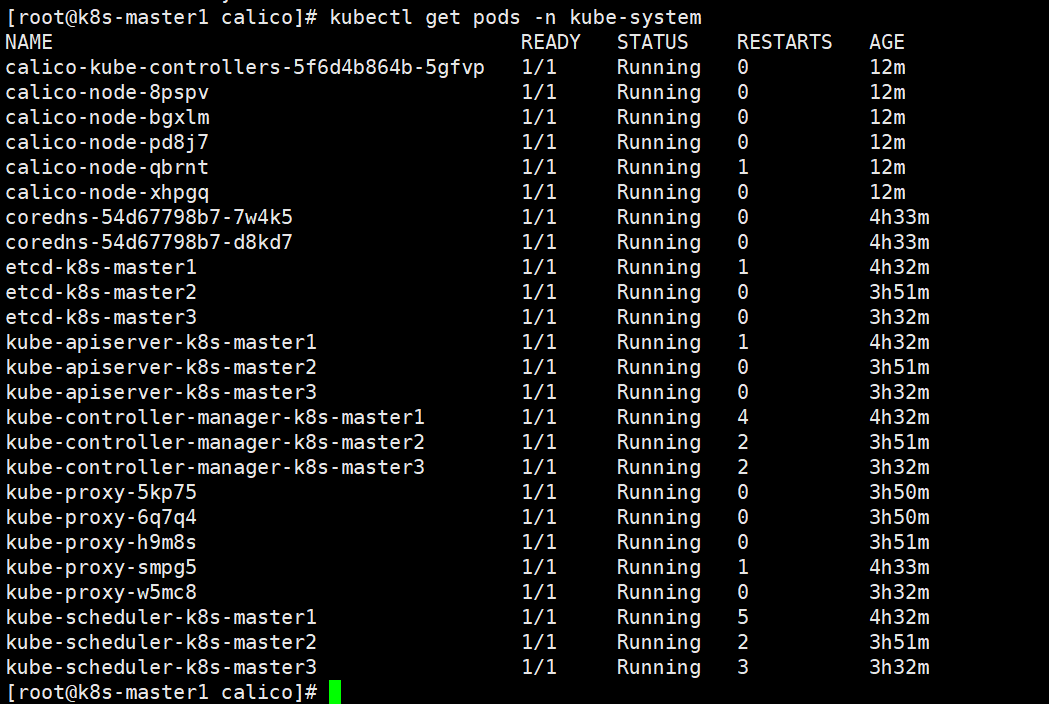
同时,上面提到的两个coredns-54d67798b7-7w4k5容器没有运行起来的问题也成功的运行起来了。目标为:在 master1节点 查看集群节点状态标题。
网络组件安装完成,可以再次查看一下节点网络连接状态了。
查看节点网络连接状态
[root@k8s-master1 calico]# kubectl get nodes
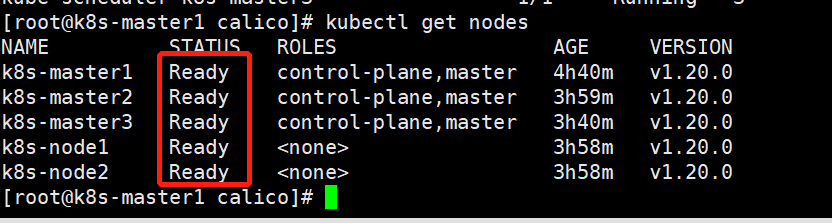
可以看到都连接成功了。
Metrics部署(只在 master1节点 操作)【用于查看其他节点的资源使用率】
在新版的Kubernetes中系统资源的采集均使用Metrics-server,可以通过Metrics采集节点和Pod的内存、磁盘、CPU和网络的使用率。
将Master1节点的front-proxy-ca.crt复制到所有Node节点
- 复制到node1节点上
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node1:/etc/kubernetes/pki/front-proxy-ca.crt
- 复制到node2节点上
[root@k8s-master1 ~]# scp /etc/kubernetes/pki/front-proxy-ca.crt k8s-node2:/etc/kubernetes/pki/front-proxy-ca.crt

安装metrics server
同时也可以参考:【云原生-k8s】kubectl top pod 报错:error: Metrics API not available
该篇文章。
#进入上一步拉取的k8s-ha-install/metrics-server-0.4.x-kubeadm/目录
[root@k8s-master1 ~]# cd /root/k8s-ha-install/metrics-server-0.4.x-kubeadm/
#根据该目录下的yaml文件创建容器
[root@k8s-master1 metrics-server-0.4.x-kubeadm]# kubectl apply -f comp.yaml
查看节点状态
[root@k8s-master1 metrics-server-0.4.x-kubeadm]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 258m 12% 1125Mi 65%
k8s-master2 224m 11% 1083Mi 62%
k8s-master3 114m 5% 1047Mi 60%
k8s-node1 61m 3% 860Mi 50%
k8s-node2 62m 3% 889Mi 51%
如果还是top查看不到,可以查看一下metrics-server有没有起来,kubectl get pods -n kube-system | grep metrics,有问题排查之后就可以了。
部署成功!






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结