您现在的位置是:首页 >其他 >MySQL8.0数据库开窗函数网站首页其他
MySQL8.0数据库开窗函数

简介
数据库开窗函数是一种在SQL中使用的函数,它可以用来对结果集中的数据进行分组和排序,以便更好地分析和处理数据。开窗函数与聚合函数不同,它不会将多行数据聚合成一行,而是保留每一行数据,并对其进行分组和排序。
常见的开窗函数包括ROW_NUMBER()、RANK()、DENSE_RANK()、NTILE()、LAG()、LEAD()等。这些函数可以帮助用户在结果集中生成分组和排序的结果,以便更好地理解和分析数据。
例如,使用ROW_NUMBER()函数可以根据一个或多个字段对结果集进行分组,并在每个分组内生成一个行号,以便用户可以轻松地跟踪数据。使用LAG()和LEAD()函数可以在结果集中的每一行之前和之后提取数据,以便用户可以查看当前行之前或之后的数据。
开窗函数是SQL中非常有用的工具,可以帮助用户对结果集中的数据进行分组和排序,以便更好地分析和处理数据。
MySQL 官方文档: https://dev.mysql.com/doc/refman/8.0/en/window-functions.html
注意: 官方解释 开窗函数只有MySQL8.0版本之后才有哦。
一、开窗函数 与 聚合函数 有什么区别?
- 数据处理范围:聚合函数只能对整个数据表或者数据集进行操作,计算结果为单一值。而开窗函数则可以对每个行进行操作,计算结果会在每个行上显示。
- 计算结果:聚合函数的计算结果只有一个,通常用于执行诸如求和、取平均值、计算最大值/最小值等的操作。而开窗函数的计算结果可以有多个,它提供给查询结果集中每一行的附加列。
- 语法:聚合函数通常用于SELECT语句中的SELECT子句和HAVING子句,而开窗函数通常在OVER关键字后使用。
二、官方解释的开窗函数

- 翻译
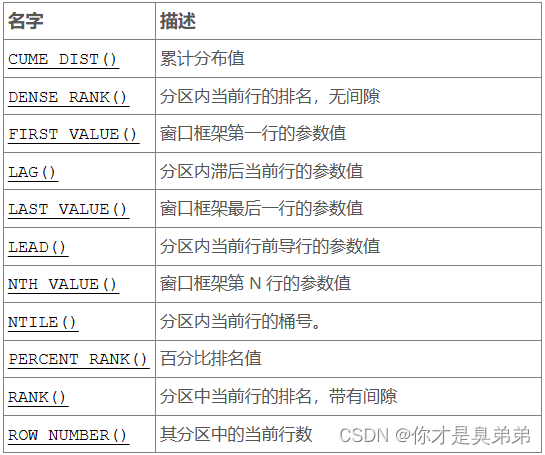
官方说的很官方,稍有点难以理解还是。
三、开窗函数细分
3.1、序号
- ROW_NUMBER():该函数可以根据一个或多个字段对结果集进行分组,并在每个分组内生成一个行号,以便用户可以轻松地跟踪数据。
- RANK():该函数可以根据一个或多个字段对结果集进行排序,并在每个排序中生成一个排名,以便用户可以了解数据的大小和顺序。
- DENSE_RANK():该函数可以根据一个或多个字段对结果集进行排序,并在每个排序中生成一个排名,但跳过的位次比RANK()函数少一位。
3.2、分布
- PERCENT RANK():函数用于计算数据集中每个值的百分比排名。
- CUME_DIST():函数用于计算数据集中每个值的累积密度排名。
3.3、前后
- LAG():该函数可以在结果集中的每一行之前提取数据,以便用户可以查看当前行之前的数据。
- LEAD():该函数可以在结果集中的每一行之后提取数据,以便用户可以查看当前行之后的数据。
3.4、首尾
- FIRST_VALUE():函数返回结果集的有序分区中的第一个值。
- LAST_VALUE():函数返回结果集的有序分区中的最后一个值。
3.5、其它
- NTILE():该函数可以根据一个或多个字段对结果集进行分组,并将每个分组分配到指定数量的桶中,以便用户可以更好地分析和分组数据。
- NTH_VALUE():函数返回结果集的有序分区中第n行的值。
四、语法使用
4.1、语法结构
<窗口函数> OVER ([PARTITION BY <分组列>] [ORDER BY <排序列> {ASC|DESC}] [<行窗口>|<范围窗口>] [<开始位置>|<结束位置>|<长度>])- <窗口函数>表示要执行的聚合函数,如SUM、AVG、MAX、MIN、COUNT等;
- <分组列>表示要进行分组的列;
- <排序列>表示按照哪个列进行排序,可以指定多个排序列,用逗号分隔;
- <行窗口>和<范围窗口>分别表示行级窗口和范围级窗口;
- <开始位置>、<结束位置>和<长度>表示窗口的起始位置、结束位置和长度。
在 MySQL 8.0 中,行窗口是指一组连续的行,这些行被视为一个整体,并且可以用于窗口函数的计算。
行窗口由以下关键字指定:
- ROWS:表示行窗口。
- BETWEEN:用于指定行窗口的起始位置和结束位置。
- PRECEDING:表示行窗口的起始位置。
- FOLLOWING:表示行窗口的结束位置。
常用的行窗口指定方式:
- ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:表示从结果集的第一个行到当前行,包括当前行。
- ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING:表示从当前行到结果集的最后一个行,包括当前行。
- ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING:表示包含当前行在内的前后各一行。
说明: 行窗口可以用于计算每组的总和、平均值、计数等聚合操作,也可以用于计算每个行的排名、累积和等操作。
4.2、普通聚合函数做开窗函数
- 普通聚合函数只能对整个数据表或者数据集进行操作,计算结果为单一值。而开窗函数可以针对每个行进行操作,计算结果会在每个行上显示。
4.2.1、表结构
DROP TABLE IF EXISTS `order_for_goods`;
CREATE TABLE `order_for_goods` (
`order_id` int(0) NOT NULL AUTO_INCREMENT,
`user_id` int(0) NULL DEFAULT NULL,
`money` decimal(10, 2) NULL DEFAULT NULL,
`quantity` int(0) NULL DEFAULT NULL,
`join_time` datetime(0) NULL DEFAULT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 12 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;4.2.2、表数据
INSERT INTO order_for_goods (user_id, money, quantity, join_time )
VALUES
( 1001, 1800.90, 1, '2023-06-07'),
( 1001, 3600.89, 5, '2023-05-02'),
( 1001, 1000.10, 6, '2023-01-08'),
( 1002, 1100.90, 9, '2023-04-07'),
( 1002, 4500.99, 1, '2023-03-14'),
( 1003, 2500.10, 3, '2023-02-14'),
( 1002, 2500.90, 1, '2023-03-14'),
( 1003, 2500.90, 1, '2022-12-12'),
( 1003, 2500.90, 2, '2022-09-08'),
( 1003, 6000.90, 8, '2023-01-10');4.2.3、普通函数做开窗函数
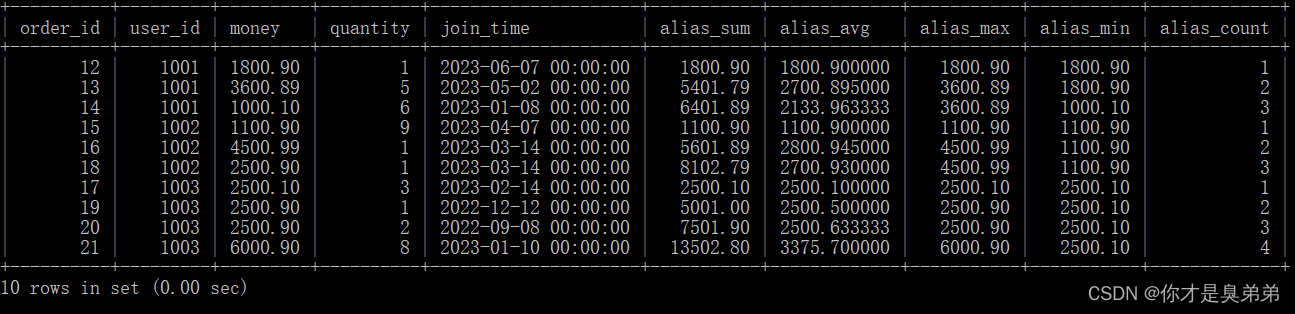
1、语句如下
select
*,
sum(money) over(partition by user_id order by order_id) as alias_sum,
avg(money) over(partition by user_id order by order_id) as alias_avg,
max(money) over(partition by user_id order by order_id) as alias_max,
min(money) over(partition by user_id order by order_id) as alias_min,
count(money) over(partition by user_id order by order_id) as alias_count
from order_for_goods;- 从 order_for_goods 表中选择了所有的列,并计算了每个用户在每个订单中的总金额、平均金额、最大金额、最小金额和计数。
- 这个查询使用了 sum()、avg()、max()、min() 和 count() 函数来计算每个订单的总金额、平均金额、最大金额、最小金额和计数。这些函数后面跟着 over() 子句,用于指定计算的窗口。在这个例子中,窗口是按照 user_id 分区,按照 order_id 排序的。
2、查询结果返回了选择的列和计算出的别名列如下
4.3、序号函数
4.3.1、ROW_NUMBER()函数
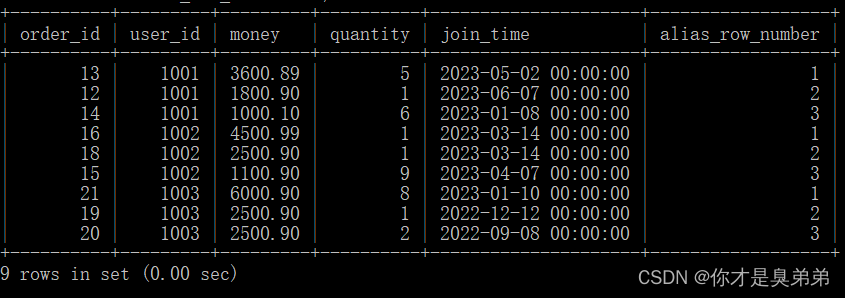
1、执行语句
select *
from (
select *,row_number() over(partition by user_id order by money desc) as alias_row_number
from order_for_goods) t
where alias_row_number<=3;- 以上SQL语句使用了窗口函数 row_number() 来为每个分区内的行分配序号。然后,外部查询从这些序号中选择前三个最高的行。
- 内部查询从 order_for_goods 表中选择了所有的列,并使用 row_number() 函数为每个分区内的行分配序号。在这个例子中,子查询将数据是按照 user_id 列进行分区 ,按照 money 列的降序排列的。
- 外部查询从内部查询的结果中选择了序号小于等于 3 的行,这些行对应于分区内前三高的行。
2、执行结果
3、执行语句
select *
from (
select *,row_number() over(partition by user_id order by money desc) as alias_row_number
from order_for_goods) t
where alias_row_number<=1;- 以上这个查询语句与上一个查询语句类似,只不过 alias_row_number<=3 改成了 alias_row_number<=1,因此结果将只返回分区内最高的一行。
4、执行结果

总结: 可以发散思维想一想,举个栗子: 比如统计各个商品领域销量排行前三。使用开窗是不是可以解决很多问题,也避免了大量难以维护且看不懂的sql逻辑。
4.3.2、RANK()函数
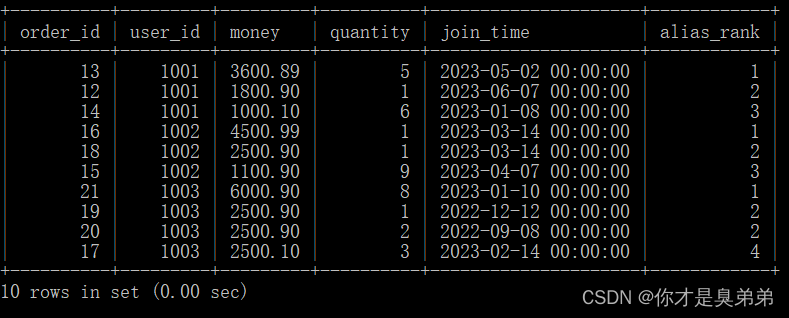
1、执行语句
select
*,
rank() over(partition by user_id order by money desc) as alias_rank
from order_for_goods;- 以上SQL语句使用了窗口函数 rank() 来为每个用户计算一个别名排名(alias_rank)。
- rank() 函数会为每个分区内的连续排名计算一个排名值,因此这个语句会为每个用户计算一个别名排名。
- 注意语句没有指定任何条件,因此它会返回 order_for_goods 表中的所有行和列。如果需要查询特定的行或列,可以在 select 子句中指定相应的条件或列名。
2、执行结果
4.3.3、DENSE_RANK()函数
1、执行语句
select
*,
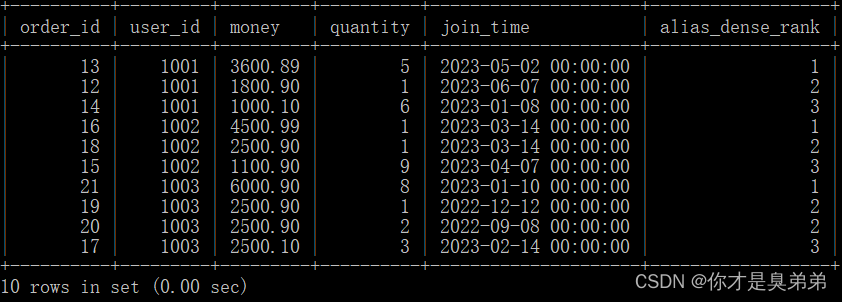
dense_rank() over(partition by user_id order by money desc) as alias_dense_rank
from order_for_goods;- 以上SQL语句使用了窗口函数 dense_rank() 来为每个用户计算一个别名密集排名(alias_dense_rank)。
- dense_rank() 函数会为每个分区内的排名计算一个排名值,对于相邻排名值相同的行,排名值会连续分配。因此,这个语句会为每个用户计算一个别名密集排名。
- 注意语句没有指定任何条件,因此它会返回 order_for_goods 表中的所有行和列。如果需要查询特定的行或列,可以在 select 子句中指定相应的条件或列名。
2、执行结果
4.3.4、上述三种序号函数对比
1、执行语句
select
*,
row_number() over(partition by user_id order by money desc) as alias_row_number,
rank() over(partition by user_id order by money desc) as alias_rank,
dense_rank() over(partition by user_id order by money desc) as alias_dense_rank
from order_for_goods;- 从 order_for_goods 表中选择了所有的列,并计算了每个用户在每个订单中的总金额,以及计算了每个用户在每个订单中的序号、排名和稠密排名。
- 这个查询使用了 row_number()、rank() 和 dense_rank() 函数来计算每个分区内的行的序号、排名和稠密排名。这些函数后面跟着 over() 子句,用于指定计算的窗口。在这个例子中,窗口是按照 user_id 分区,按照 money 列的降序排列的。
2、执行结果

4.4、分布函数
4.4.1、PERCENT RANK()函数
1、执行语句
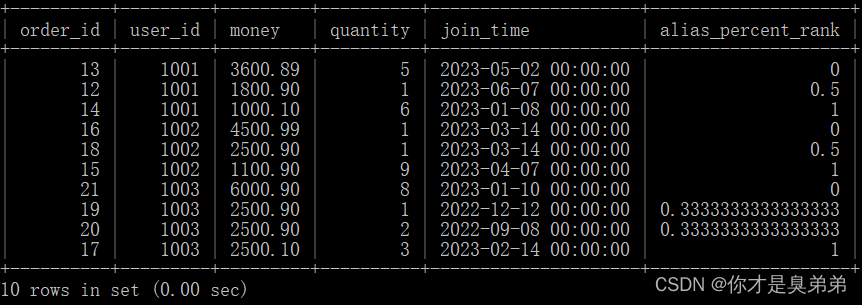
select
*,
percent_rank() over(partition by user_id order by money desc) as alias_percent_rank
from order_for_goods;- 从 order_for_goods 表中选择了所有的列,并计算了每个用户在每个订单中的总金额,以及计算了每个用户在每个订单中的百分比排名。
- 这个查询使用了 percent_rank() 函数来计算每个分区内的行的百分比排名。这个函数后面跟着 over() 子句,用于指定计算的窗口。在这个例子中,窗口是按照 user_id 分区,按照 money 列的降序排列的。
2、执行结果
4.4.2、CUME_DIST()函数
1、执行语句
select
*,
cume_dist() over(partition by user_id order by money desc) as alias_percent_rank
from order_for_goods;- 从 order_for_goods 表中选择了所有的列,并计算了每个用户在每个订单中的总金额,以及计算了每个用户在每个订单中的累积百分比。
- 这个查询使用了 cume_dist() 函数来计算每个分区内的行的累积百分比。这个函数后面跟着 over() 子句,用于指定计算的窗口。在这个例子中,窗口是按照 user_id 分区,按照 money 列的降序排列的。
2、执行结果

4.5、前后函数
4.5.1、LAG()函数
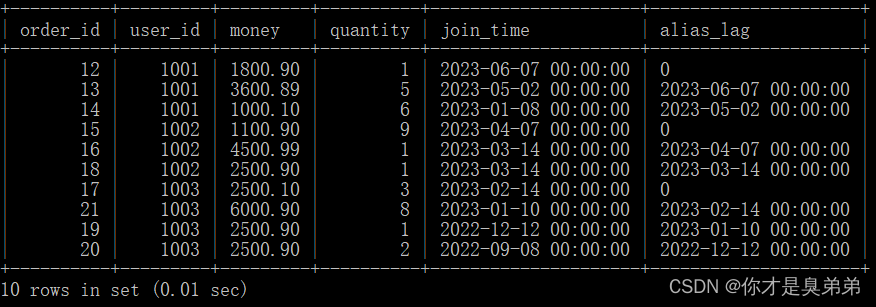
1、语法说明
- LAG()函数是用于在时间序列中向前移动指定周期的函数。
LAG(expression, offset, default_value)- expression:要取值的列
- offset:向前数第几行的值
- default_value:如果没有值,可设置默认值
2、执行语句
select
*,
lag(join_time, 1, 0) over(partition by user_id order by join_time desc) as alias_lag
from order_for_goods;3、执行结果
4.5.2、LEAD()函数
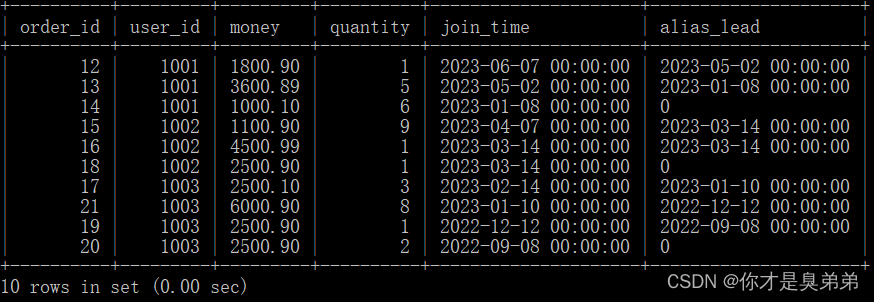
1、语法说明
- LEAD()函数是用于在时间序列中向后移动指定周期的函数。
LAG(expression, offset, default_value)- expression:要取值的列
- offset:向后数第几行的值
- default_value:如果没有值,可设置默认值
2、执行语句
select
*,
lead(join_time, 1, 0) over(partition by user_id order by join_time desc) as alias_lead
from order_for_goods;3、执行结果
4.6、收尾函数
4.6.1、FIRST_VALUE()函数
1、语法说明
- FIRST_VALUE:取窗口第一行的值
FIRST_VALUE(expression)- expression:一个表达式,用于指定要获取第一行值的列或计算结果。
2、执行语法
select
*,
first_value(money) over(partition by user_id order by join_time desc) as alias_first_value
from order_for_goods;- 注意,如果某个用户在指定时间范围内没有数据,则 LAST_VALUE() 函数将返回默认值 NULL。
3、执行结果
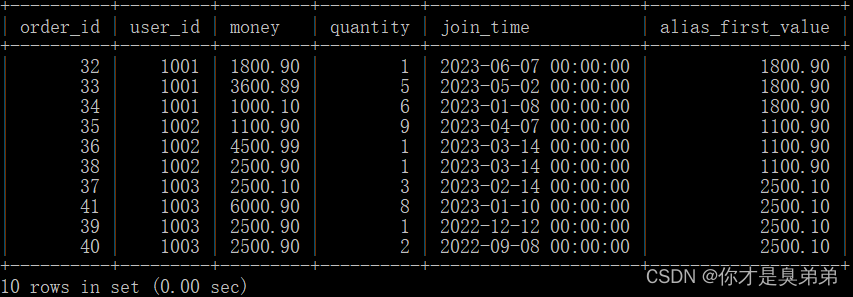
4.6.2、LAST_VALUE()函数
1、语法说明
- LAST_VALUE:取窗口最后一行的值。
LAST_VALUE(expression)- expression:一个表达式,用于指定要获取最后一行值的列或计算结果。
2、执行语法
select
*,
last_value(money) over(partition by user_id order by join_time) as alias_last_value
from order_for_goods;- 注意,如果某个用户在指定时间范围内没有数据,则 LAST_VALUE() 函数将返回默认值 NULL。
2、执行结果

3、解释
- 你可能会发现LAST_VALUE() 不是取窗口的最后一个值,窗口按照 user_id 分区,按照 join_time 列排序,按道理是返回1001分区中money为1800.90才对啊? 为什么? 为什么?
- 原因是LAST_VALUE()默认统计范围是 rows between unbounded preceding and current row

3、验证
select
*,
last_value(money) over(partition by user_id order by join_time) as alias_last_value1,
last_value(money) over(partition by user_id order by join_time rows between unbounded preceding and current row) as alias_last_value2,
last_value(money) over(partition by user_id order by join_time rows between unbounded preceding and unbounded following) as alias_last_value3
from order_for_goods;- 可以看到别名 alias_last_value2 验证了LAST_VALUE()默认统计范围就是 rows between unbounded preceding and current row(表示从当前行开始向前没有边界地进行计算,即计算当前行之前的所有行的结果。)
- 可以看到别名 alias_last_value3 在指定 rows between unbounded preceding and unbounded following(表示从当前行开始向前和向后都没有边界地进行计算,即计算整个分区的结果。)全部统计情况下可以得到,user_id 分区,join_time 列排序,返回1001分区中字段money最后一笔交易金额为1800.90。
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
| order_id | user_id | money | quantity | join_time | alias_last_value | alias_last_value | alias_last_value |
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
| 34 | 1001 | 1000.10 | 6 | 2023-01-08 00:00:00 | 1000.10 | 1000.10 | 1800.90 |
| 33 | 1001 | 3600.89 | 5 | 2023-05-02 00:00:00 | 3600.89 | 3600.89 | 1800.90 |
| 32 | 1001 | 1800.90 | 1 | 2023-06-07 00:00:00 | 1800.90 | 1800.90 | 1800.90 |
| 36 | 1002 | 4500.99 | 1 | 2023-03-14 00:00:00 | 2500.90 | 4500.99 | 1100.90 |
| 38 | 1002 | 2500.90 | 1 | 2023-03-14 00:00:00 | 2500.90 | 2500.90 | 1100.90 |
| 35 | 1002 | 1100.90 | 9 | 2023-04-07 00:00:00 | 1100.90 | 1100.90 | 1100.90 |
| 40 | 1003 | 2500.90 | 2 | 2022-09-08 00:00:00 | 2500.90 | 2500.90 | 2500.10 |
| 39 | 1003 | 2500.90 | 1 | 2022-12-12 00:00:00 | 2500.90 | 2500.90 | 2500.10 |
| 41 | 1003 | 6000.90 | 8 | 2023-01-10 00:00:00 | 6000.90 | 6000.90 | 2500.10 |
| 37 | 1003 | 2500.10 | 3 | 2023-02-14 00:00:00 | 2500.10 | 2500.10 | 2500.10 |
+----------+---------+---------+----------+---------------------+------------------+------------------+------------------+
10 rows in set (0.00 sec)4.7、其它函数
4.7.1、NTILE()函数
1、语法说明
- NTILE() 用于将一个查询结果集划分成指定数量的桶,并根据桶的大小将数据分配到各个桶中。
NTILE(bucket_size)- bucket_size:一个整数参数,表示要将结果集划分成的桶的数量。
2、执行语句
select
*,
ntile(1) over(partition by user_id order by join_time desc) as alias_ntile1,
ntile(2) over(partition by user_id order by join_time desc) as alias_ntile2,
ntile(3) over(partition by user_id order by join_time desc) as alias_ntile3
from order_for_goods;- 查询使用窗口函数 NTILE(),它可以将数据集合平均分配到指定的数量的桶中,并返回每个行所属的桶号。
- 以别名 "alias_ntile3" 举例,该查询中ntile(3) 表示将每个用户分为三个组,partition by user_id 表示按照 user_id 分组,order by join_time desc 表示按照 join_time 降序排序。
- 如果是ntile(2)就表示分两个组ntile(1)就表示分一个组。
3、执行结果

说明: NTILE()函数,可以将有序的数据集合平均分配到指定的数量的桶中,将桶号分配给每一行。如果不能平均分配,则较小桶号的桶分配额外的行,并且各个桶中能放的行数最多相差1。
4.7.2、NTH_VALUE()函数
1、语法说明
- NTH_VALUE() 函数是 SQL 中用于计算一个有序数据集合中指定位置的值的窗口函数。
NTH_VALUE(expression, nth_parameter)- expression:要计算其值的表达式,其求值为单个值。
- nth_parameter:是一个整数参数,表示要计算的值的序号。
2、执行语句
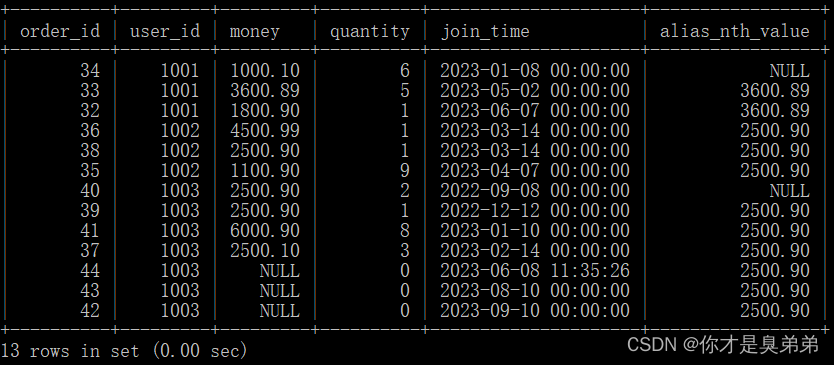
select
*,
nth_value(money, 2) over(partition by user_id order by join_time ) as alias_nth_value
from order_for_goods;- 注意,如果某个用户在指定时间范围内没有数据,则 NTH_VALUE()函数将返回默认值 NULL。
3、执行结果





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结